【Java 快速复习】 Java 内存模型 & 并发问题本质
在 Java 领域,我们经常会说两个名词大家要有所区分:
- JVM 内存模型:这个所说的是 JVM 内存的划分规则,如 堆、栈、元空间等
- Java 内存模型:这个所说的是线程和主内存之间,以及 CPU 高速缓存和内存之间的抽象关系,,这种抽象关系带来的就是 Java 并发问题,Java 内存模型规范了 JVM 如何提供按需禁用缓存和编译优化的方法。具体来说,这些方法包括 volatile、synchronized 和 final 三个关键字
并发问题源头
主要是三个问题:
- 缓存带来的可见性问题。
- 编译优化带来的有序性问题。
- 线程切换带来的原子性问题 (Java 语言分解成 CPU 指令操作并不是原子)。
可见性
多核 CPU 缓存(寄存器) 和 内存间存在可见性问题
A 线程 使用 CPU-1 读取内存中变量 X = 1 ;
B 线程 使用 CPU-2 读取内存中变量 X = 1;
A B 线程操作变量都是在本核 CPU 缓存中执行操作,最后写回。这个操作过程对于 A B 两线程是不可见的。
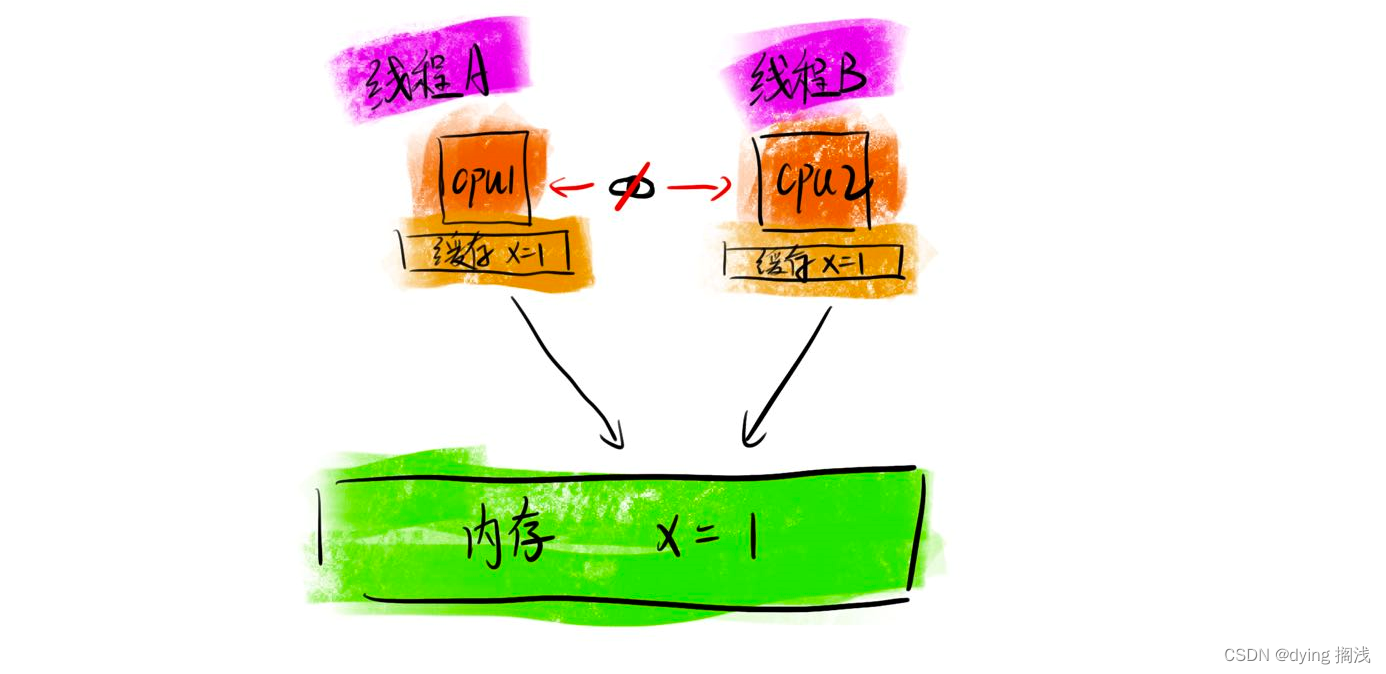
这就是可见性问题,解决该问题即,禁用 CPU 缓存,Java 中 volatile 关键字
有序性
Java 程序在编译过程中为了优化性能,有时会改变程序中语句的先后顺序
int a = 1;
int b = 2;
优化后可能为
int b = 2;
int a = 1;
这类优化调整了语句的顺序但不影响程序的最终结果。
其实我们在聊有序性的时候,最有可能遇到的问题是单例初始化时的双重检查。下面是一个比较常见的双重检查获取单例对象的代码
public class Singleton {
static Singleton instance;
static Singleton getInstance(){
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null)
instance = new Singleton();
}
}
return instance;
}
}
这个 getInstance() 方法看上去没有什么问题,但在指令重排后就有可能引发并发问题。
我们认为的 instance 赋值过程是
- 划分一块内存 M
- 在 M 中初始化 Singleton 对象
- 将 M 内存地址赋值给 instance 变量
而实际指令重排后
- 划分一块内存 M
- 将 M 内存地址赋值给 instance 变量
- 在 M 中初始化 Singleton 对象
这会导致在第二步的时候 instance 变量就不为 null 了,但此时对象还未初始化,如果多线程调用就可能返回一个未初始化的对象,从而导致程序错误。
同样的解决该问题的方法就是禁用指令重排,在 Java 中使用 volatile 关键字
原子性
CPU 能够保证的原子操作是 CPU 指令级别的,而一个 Java 语句可能会对应多个 CPU 指令,这就导致 Java 的单个语句可能并不是原子的,在线程切换的时候就可能出现并发问题,所以需要我们在 Java 语言的级别保证某些操作的原子性。
比如执行一个 +1 的操作
int count = 0;
void addOne(){
count++;
}
如果有多个线程同时调用 addOne() 方法,这个最终的总数是不准确的。
对于 ++ 操作拆解成 CPU 指令至少需要三条:
- 将 count 变量加载到 CPU 寄存器
- 在寄存器中执行 +1 操作
- 将结果写回内存
在这个流程中多个线程同时调用 addOne 方法,线程 A 读取 count 值为 0,线程 B 读取 count 值也是 0
线程 A 执行完毕写回内存 count 值为 1,线程 B 执行完毕写回内存 count 值也为 1。我们期望这个值应该为 2 。
看上去似乎是可见性的问题 volatile 关键字修饰后能否解决这个问题。
其实是不能的,volatile 能解决一部分问题,它解决不了线程切换的问题。需要通过互斥锁来解决,在 Java 中即 synchronized





![[附源码]计算机毕业设计常见Web漏洞对应PC应用系统Springboot程序](https://img-blog.csdnimg.cn/dd5be5cf2f784ed7ae4a5023f7aa6eb5.png)


![[附源码]计算机毕业设计贷款申请审核管理系统论文Springboot程序](https://img-blog.csdnimg.cn/f0a73885fe66475ba826e0f6c8ac4f3a.png)