目录
一、JVM内存区域划分
1. 什么是内存区域划分以及为啥要进行区域划分
2. JVM内存区域划分详解
3. 堆区详解:
4. 给一段代码,问某个变量是在那个区域上?
二、JVM类加载机制
1.类加载的过程
2. 类加载的时机
3. 双亲委派模型(经典面试)
三、JVM垃圾回收机制(GC)
1. 为什么要有GC
2. GC针对哪些内存区域进行释放
3. 如何进行垃圾回收
4. GC时机工作过程
(1)判定垃圾
(2)具体如何知道对象是否有引用指向
引用计数:
引用计数的缺点:
可达性分析(Java的做法)
可达性分析的缺点
5. 如何清理垃圾
6. 分代回收
分代回收如何分?
7. GC中典型的垃圾回收器
前言
当前用的最主流的JVM是HotSpot VM,Oracle官方jdk和开源的open jdk都是使用这个JVM。
一、JVM内存区域划分
1. 什么是内存区域划分以及为啥要进行区域划分
整个一个大块的内存,不是很好用,但是如果把整个内存空间隔成了很多个区域,然后每个区域都有不同的作用,此时这块很大的内存就显得很有条理性,并且在每个内存的区域使用的时候是不会相互干扰的。所以针对不同的业务需要和功能就对内存划分出了不同区域的内存空间。
JVM也就是启动的时候会申请一整个很大的内存区域,JVM是一个应用程序,当JVM运行在操作系统上的时候,也是要从操作系统中申请内存的,然后JVM就要根据把整个空间,分成几个部分,每个部分各自有不同的功能作用。
2. JVM内存区域划分详解
如下图:
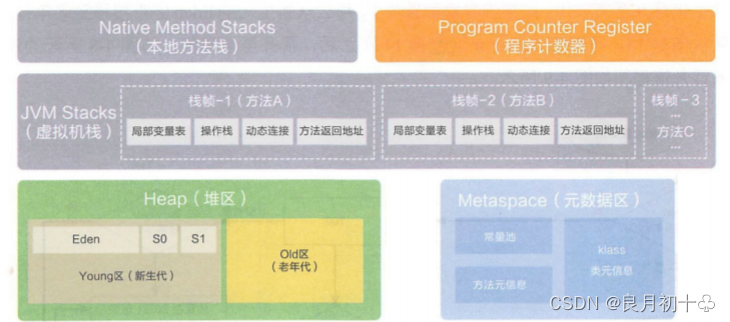
| (1)本地方法栈(Native Method Stacks) | native就表示JVM内部的C++代码,就是给调用JVM内部的方法准备的栈空间(存储的是native方法之间的调用关系) |
| (2)虚拟机栈(JVM Stacks) | 给Java代码使用的栈(此处的栈是JVM中的一个特定空间),对于JVM虚拟机栈,这里存储的是方法之间的调用关系。(整个栈空间内部,可以认为是包含很多个元素,每个元素表示一个方法),把这个里的每个元素,称为是一个 “栈帧”,这一个栈帧里会包含这个方法的入口地址,方法的参数,返回地址,局部变量.. 如下图所示。 |
| (3)程序计数器(Program Counter Register) | 记录当前线程执行到哪一个指令(很小的一块内存),也是每个线程都有一份的。 |
| (4)堆(heap) | 整个JVM空间最大的区域 ,new出来的对象都是在堆上的。类的成员变量也就是在堆上了。(new出来的对象包含成员变量) |
| (5)元数据区(Metaspace)(Java8之前叫做方法区) | 元的意思是属性,里边存放的是类对象,常量池,静态成员。 |
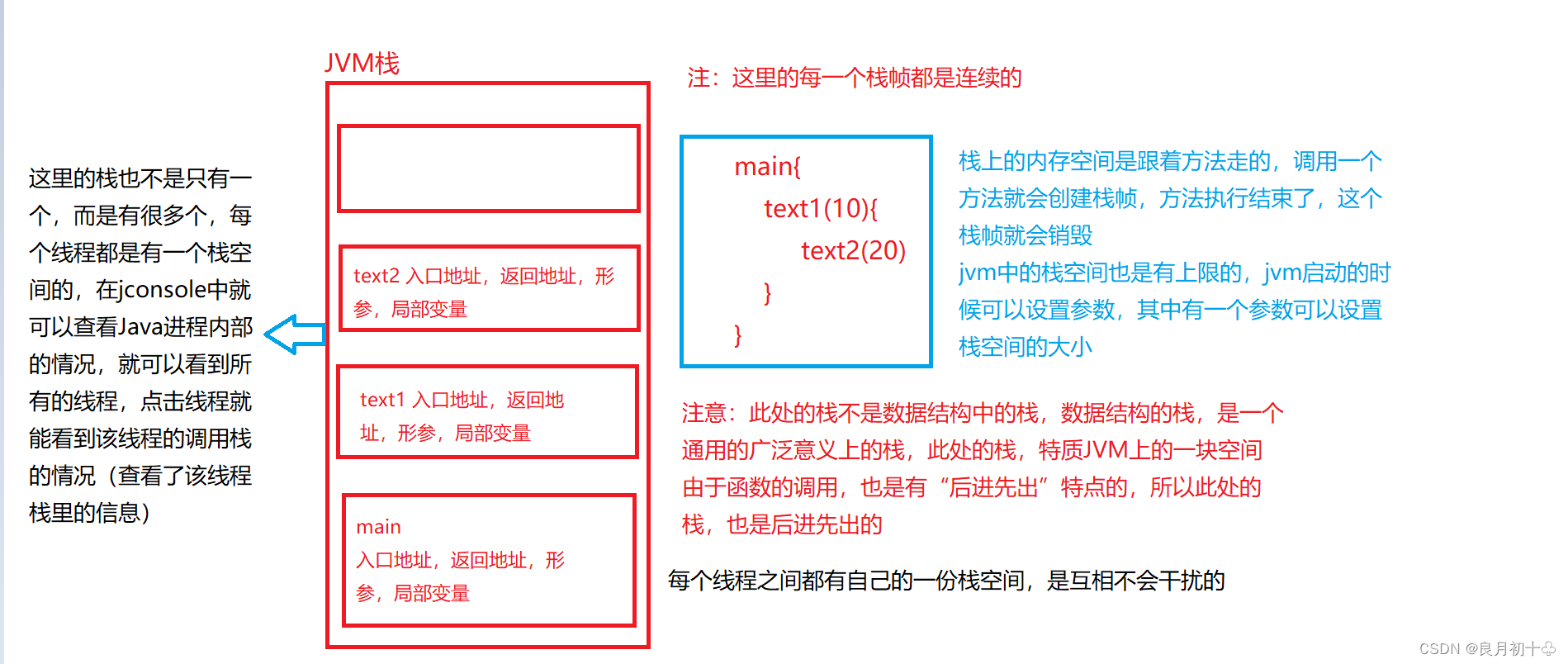
3. 堆区详解:
堆是一个进程只有一份的,栈是每个线程有一份,一个进程有N个。堆是多个线程用的都是同一个堆,栈,是每个线程用自己的栈(也就是网上说的栈是线程私有的)
但是这个说法其实还不是很准确,因为在两个线程中,一个线程是可以拿到另一个线程中占栈上的内容的,如下代码: counter这个对象是主线程中的局部变量,但是通过变量捕获,是可以在t1线程中拿到的。
public static void main(String[] args) throws InterruptedException {
Counter1 counter1 = new Counter1();
Thread t1 = new Thread(() -> {
synchronized (counter1) {
for (int i = 0; i < 10000; i++) {
counter1.add();
}
}
});
Thread t2 = new Thread(() -> {
synchronized (counter1) {
for (int i = 0; i < 10000; i++) {
counter1.add();
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(counter1.getCounter1());
}4. 给一段代码,问某个变量是在那个区域上?
原则:
| 1. 如果是局部变量 --> 栈 |
| 2. 如果是普通成员变量 --> 堆 |
| 3. 如果是静态成员变量 --> 方法区/元数据区 |
二、JVM类加载机制
1.类加载的过程
类加载的过程就是.class文件(就是.java文件通过javac编译),从文件(硬盘)被加载到内存中(元数据区)这样一个过程,这个过程是很复杂的,但是大概可以分为这个么几个步骤:
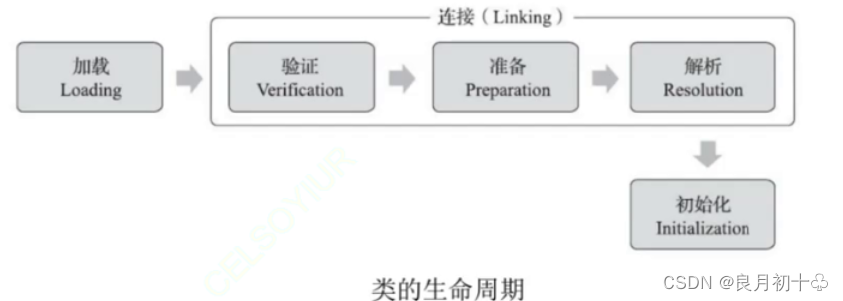
| 1. 加载 | 把.class文件找到(找的过程),打开文件,读文件,把文件内容读到内存中。(最终加载完成,是要得到类对象) |
| 2. 验证 | 检查.class文件格式是否正确,.class是一个二进制文件,如果格式不匹配,就加载失败了。这里的格式是有严格的规定的,官方提供了JVM虚拟机规范,规范文档上详细的描述了.class的格式。 |
| 3. 准备 | 给类对象分配内存空间(先在元数据去占个位置),也会使静态成员变量被设置成0值。 |
| 4.解析 | 初始化字符串常量,把符号引用转为直接引用。 (字符串常量,得有一块内存空间,存这个字符的实际内容,还得有一个引用,来保存这个内存空间的起始地址,在类加载之前,字符串常量此时是在.class文件中的,此时这个“引用”记录的并不是真正的地址,而是它在文件中的“偏移量”这个东西(或者是个占位符),类加载之后,才真正把这个字符串常量给放到内存中,此时才有“内存地址”,这个引用才能被真正赋值成指定内存地址) 这个占位符或者偏移量就是指符号引用,加载之后的内存地址就是直接引用。 |
| 5. 初始化 | 真正针对类对象里面的内容进行初始化,加载父类,执行静态代码块的代码。 |
2. 类加载的时机
注:不是Java程序一运行,就把所有的类都加载了,而是真正用到才加载(懒汉模式)
| 1. 构造类的实例 |
| 2. 调用这个类的静态方法 / 使用静态属性 |
| 3. 加载子类,就会先加载其父类 |
一旦加载之后,后续再使用就不用重复加载了。
3. 双亲委派模型(经典面试)
加载就是把.class文件找到,读取文件内容,双亲委派模型描述的是这个加载,找.class文件的基本过程。
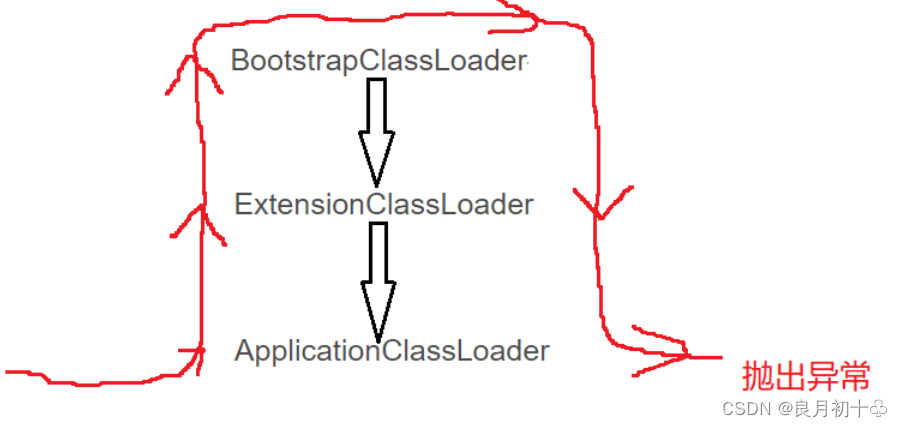
Java默认提供了三个类加载器:
| BootstrapClassLoader | 负责加载标准库中的类(java规范要求提供的一些类,无论是哪种JVM的实现,都会提供这些一样的类) |
| ExtensionClassLoader | 负责架子啊JVM扩展库中的类(规范之外,由JVM的厂商 / 组织提供的额外的功能) |
| ApplicationClassLoader | 负责加载用户提供的第三方库 / 用户项目代码 中的类 |
上述三个类,存在 “父子关系” (不是父类子类,而是说相当于每个 classloader 有一个parent属性,指向自己的父 类加载器 )
上述类加载器如何配合工作: 首先加载一个类的时候,是先从AppLicationClassLoader开始,但是AppLicationClassLoader会把加载任务交给父亲,让父亲去执行,于是ExtensionClassLoader要去加载了,但是也不是真加载,而是再委托给自己的父亲BootstrapClassLoader让它去加载,BootstrapClassLoader要去加载了,也是想委托给自己的父亲,但是发现自己的父亲是null,最后没有父亲 / 没找到类,才由自己进行加载。
(1)所以此时BootstrapClassLoader就会搜索自己负责的标准库目录的相关的类,如果找到,就加载,如果没找到,就继续由子类加载器进行加载。
(2)ExtensionClassLoader 真正搜索扩展库相关的目录,如果找到就加载,如果没找到,就由子类加载器进行加载。
(3)ApplicationClassLoader 真正搜索用户项目相关的目录,如果找到就加载,没找到还是由子类进行加载(但是当前已经没有子类了,就只能抛出 类没有找到 这样的异常) 如下图:
上述这套顺序其实是出自于JVM实现代码的逻辑,这段代码就是大概类似于 “递归” 的方式写的。
这个顺序最主要的目的,就是为了保证BootStrap能够先加载,Application能够后加载,这就可以避免了说因为用户创建了一些奇怪的类 如:java.lang.Sring 这样的类引起不必要的bug,按照上述流程加载,此时JVM加载的还是标准库的类,不会加载自己写的这个类。
这样就可以保证,即使出现上述问题,也不会让JVM已有的代码出现混乱,最多是程序猿自己写的类不会生效。
另一方面,类加载器其实是可以程序猿自己自定义的,上述三个类加载器是JVM自带的,也就是说如果自己写了一个类加载器,也是可以把这个类加载器挂在上述类似链表的三个原生类加载器之中的,而且是可以挂在任意的地方,根据业务的需求,想让自定义的类加载器什么时候生效就可以什么时候生效。 这样就可以和原生的类加载器相互配合使用了。
上述的类加载,包括类加载的过程,类加载的时机,双亲委派模型,站在JVM的角度,这三个都不是类加载的真正核心内容,真正的核心应该是 解析.class文件,解析每个字节都是做什么的。
三、JVM垃圾回收机制(GC)
1. 为什么要有GC
垃圾:指的是不再使用的内存,垃圾回收就是把不用的内存来帮我们自动进行释放。
在C,C++中,如果不手动释放垃圾,这块内存的空间就会持续存在,一直存在到进程结束(堆上的内存生命周期比较长,不像栈,栈空间会随着方法执行结束,栈帧销毁而自动释放,堆,则默认不能自动释放),这就可能导致内存泄露,注意:内存泄露是一个很严重的问题。尤其是对于服务器来说,它要7*24小时运行。
GC就是一种最主流的回收垃圾的方式, 首先GC是有好处也有坏处的:
| GC好处:非常省心,让程序猿写代码简单,不容易出错。 |
| GC坏处:需要消耗额外的系统资源,也有额外的性能开销。另外GC还会涉及到STW(stop the world)问题。 如果有时候内存中的垃圾已经很多了,此时触发一次GC操作开销可能很大,可能会吃了很多的系统资源,另一方面GC回收垃圾的时候可能会设计hi到一些锁操作,导致业务代码无法正常执行,这样的卡顿极端情况下可能是出现几十毫秒或者上百毫秒的,这 也是C C++不采用GC的原因。 |
GC垃圾回收要和文件资源的释放区分开,像Scanner,DataSource这样的文件资源是需要手动释放的,它是文件资源,和内存以及垃圾回收是两回事。
2. GC针对哪些内存区域进行释放
| 1. 堆 | GC主要是针对堆进行垃圾回收,内存的释放的。 |
| 2. 栈 | 栈中是存在一块一块的栈帧的这样的内存空间,栈帧是随着方法的执行而申请,方法的结束而销毁的,所以栈空间内存是不需要GC的。 |
| 3.程序计数器 | 每个线程就只有一个,记录的是执行到了哪一条指令,线程销毁了之后,程序计数器自然也就没有了。 |
| 4. 方法区 | 主要指存放的类对象,类对象一般只考虑类的加载,而不会考虑类的卸载。所以也没有必要进行GC。 |
3. 如何进行垃圾回收
GC是以 “对象” 为基本单位,进行回收的(而不是字节),如下图:

GC回收的是,整个对象都不再使用的情况,而一部分使用,一部分不使用的对象,暂时是不会回收的。(一个对象里面有很多属性,可能其中10个属性后面要用,10个属性后面再也不用了)
所以要进行GC,就是回收整个对象,而不会 “回收半个对象”。
这样设定目的就是简单,如果按照字节来进行回收,此时就需要标记好哪个字节是垃圾,哪个不是,此时标记的成本就很高。
4. GC时机工作过程
| 1. 找到垃圾 / 判定垃圾(哪个对象是垃圾,哪个不是,哪个对象以后一定不用了,哪个对以后还可能使用) |
| 2. 再进行对象的释放。 |
(1)判定垃圾
关键就是抓住这个对象,看看它到底是否有 “引用” 指向它,Java中对象的使用就只有通过引用来使用,所以如果一个对象有引用指向它,就有可能被使用到,如果这个对象没有引用指向它,就不会再被使用了。
再主流编程语言中,通过值访问 / 地址访问 / 引用访问,指的都是语言 / 语法层面的概念,不是系统 / CPU 层面的概念,如果是站在CPU角度看,任何访问都是通过地址进行的,值访问相当于CPU寻址的时候一次就找到了,地址访问就相当于CPU寻址的时候需要两次才能找到。
(2)具体如何知道对象是否有引用指向
| 1. 引用计数(不是Java的做法,phython / php的做法) | 给 每个 对象分配了一个整数计数器,每次创建一个引用指向该对象,计数器 + 1,每次该引用被销毁了,计数器 -1. |
| 2. 可达性分析(Java使用的方法) | 从 “树”的起点(GCroots)开始,一个代码中有很多这样的起点,把每个起点都往下遍历一遍,就完成了一次扫描过程。 |
引用计数:

引用计数的缺点:
| 1. 内存空间浪费多(利用率低) | 每个对象都要分配一个计数器,如果按4个字节算,代码中的对象非常少,可以,如果对象多了,占用的额外的空间就很多,尤其是每个对象都比较小的情况 |
| 2. 存在循环引用的问题 | 如下图: |
可达性分析(Java的做法)
Java中的对象,都是通过引用来指向并访问的,经常,是一个引用指向一个对象,这个对象里的成员又指向别的对象,如下代码:
static class TreeNode{
public int val;
public TreeNode left;
public TreeNode right;
public TreeNode(char val) {
this.val = val;
}
}
public TreeNode createTree() {
TreeNode A = new TreeNode('A');
TreeNode B = new TreeNode('B');
TreeNode C = new TreeNode('C');
TreeNode D = new TreeNode('D');
TreeNode E = new TreeNode('E');
TreeNode F = new TreeNode('F');
TreeNode G = new TreeNode('G');
TreeNode H = new TreeNode('H');
A.left = B;
A.right = C;
B.left = D;
B.right = E;
E.right = H;
C.left = F;
C.right = G;
this.root = A;
return root;
}整个Java中所有的对象就通过类似于上述的关系,通过这种链式 / 树形的结构,整体串起来。
可达性分析就是把所有这些对象被组织的结构视为树,就从根节点出发开始遍历树,所有能被访问到的对象标记为 “可达”,(不能被访问到的对象就是不可达) JVM自己拿着一个所有对象的名单,通过上述遍历,把可达的标记出来,剩下的不可达的对象就可以作为垃圾进行回收了。
可达性分析的遍历过程就是从 “树”的起点(GCroots)开始,一个代码中有很多这样的起点,把每个起点都往下遍历一遍,就完成了一次扫描过程。
可达性分析的缺点
这个操作需要进行类似 “树遍历”这个操作相比于计数来说肯定要更慢一些的,但是速度慢没关系,上述可达性分析遍历操作,并不需要一直执行,只要每隔一段时间分析一遍即可。
5. 如何清理垃圾
| 1. 标记清除 | 简单粗暴,但是又内存碎片问题 |
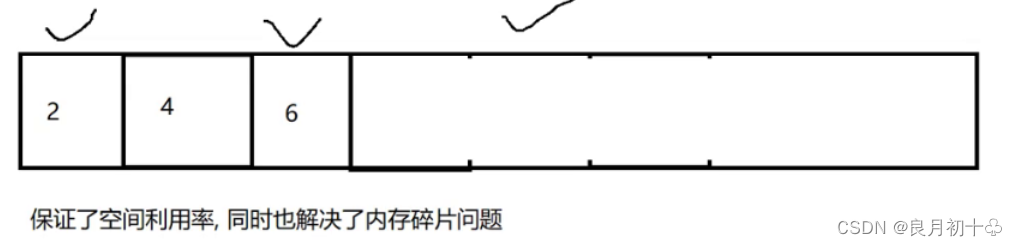
| 2. 复制算法 | 解决了内存碎片的问题,直接把整个内存分成两半,用一半,丢一半 每次触发复制算法,都是向另外一次进行复制,但是也有缺点:1. 空间利用率低, 2. 如果垃圾少,有效对象多,复制成本就很大。 |
| 3. 标记整理 | 类似于顺序表删除中间元素,会有元素搬运的一个操作,解决了复制算法的缺点,保证了空间利用率,同时也解决了内存碎片问题:
但是缺点也明显:效率低,若是要搬运的元素比较多,此时开销也是很大的。 |

上述的垃圾回收算法都并不完美,所以基于上述这些基本的算法,就引出了一个符合策略。
6. 分代回收
就是把垃圾回收分成不同的场景,有的场景有这个算法,有的场景就使用那个算法,各展所长。
(1)分代回收如何分?
基于一个经验规律:如果一个东西存在了很长时间,那么大概率还是会继续长时间的存在下去,如主流的编程开发语言Java,已经存在了很多年了,但是现在网上的风评不是很好,就说Java凉了之类的,但是现在Java仍然是主流的编程语言,所以有的东西一直存在就应该大概率是有它存在的道理的。
上述规律,对于Java的对象也是有效的(是有论证的过程的),Java对象要么就是生命周期特别段,要么就是特别长,所以就根据声明周期的长短分别使用不同的算法。
综上所述,就给对象引入一个 “年龄” 的概念,(此时的年龄单位不是年,而是熬过GC的伦次),经过一轮的可达性遍历分析,发现这个对象不是垃圾,此时就称为“熬过一轮GC”, 年龄越大,这个对象存在的时间就越久 ,
然后JVM就把堆划分成一系列区域,如下图:

| 1. 刚new出来的对象,年龄就是0,放到伊甸区,熬过一轮GC,对象就要被放到幸存区了,虽然幸存区看起来很小,伊甸区很大,但是够用(大部分java对象都是声明周期非常短的). |
| 2. 幸存区之后,也要周期性的接受GC的考验,如果变成垃圾,就要被释放,如果不是垃圾,就拷贝到另外一个幸存区(两个幸存区同一时刻只用一个)在两者之间来回拷贝(复制算法),由于幸存区内存不大,所以此时浪费的空间也是可以接受的 . |
| 3. 如果这个对象已经在两个幸存区来回拷贝很多次了,此时就要进入老年代了,老年代都是年纪大的对象,周明周期更长,针对老年代,也要周期性GC扫描,但是频率更低了. |
7. GC中典型的垃圾回收器
上述的如何确定对象是垃圾,如何清理垃圾都是一个宏观层面的策略,时机JVM在实现的时候,会有一定的差异,JVM也有很多的 “垃圾回收实现”,叫做垃圾回收器,回收器具体的实现做法会按照上述算法展开,但是会有一些变化。
不同的垃圾回收器侧重带你不同,有的是追求快速扫描,有的是扫描的精准,也有的是追求对用户的打扰少(STW尽量短)
可以重点关注:CMSD,G1,ZGC几种垃圾回收器,此处不再详细展开介绍。
![Linux分布式应用 Zabbix监控配置[添加主机 自定义监控内容 邮件报警 自动发现/注册 代理服务器 高可用集群]](https://img-blog.csdnimg.cn/7516be885518481e9d811b2c951bbcea.png)



![[物理层]传输方式](https://img-blog.csdnimg.cn/5c7f0dbd7a154d83b8dbe0f3bf868379.png#pic_center)