很多刚接触Python的同学会觉得Python就和shell语言一样,是一门脚本语言,并不需要设计,只需要关注要实现的功能。确实一门计算机语言的诞生就是为了去更好的解决当前的痛点,功能实现肯定是第一位的。但是如何在功能实现的前提下,更好的去保证软件的质量,可维护性,健壮性,这就需要开发者去学习语言的精髓,将精髓注入到程序中,这就是设计。
本文不会过多去介绍Python具体实现的技术细节,而是在整体上去总结如何写好一个Python程序,如何让你的Python程序让后面接手的同学不会说这是一个屎山。
目录
一:命名设计
二:函数设计
三:数据结构设计
四:程序框架设计
五:文件结构设计
一:命名设计
名字需要设计,好的命名会让你的代码可读性和可维护性直接上一个台阶,让读的人赏心悦目。之前看过一个大牛对于命名的重视,说对于程序中变量函数的命名,要像给自己的baby取名一样去重视,虽然有点夸张,但是足以看出命名规范的重要性。

下面总结一下Python命名的原则,有的条目对于其他语言也适用:
1,有意义简洁的命名
对于变量的命名要一眼看上去能直接知道变量的作用,对于函数的命名要清楚的知道其要实现的功能,对于类的命名要大概让读者知道该类实现的功能模块。
2,避免使用缩写
只有在很特殊的情况下,才可以使用缩写来命名变量,不要怕名字长。因为缩写会导致代码可读性的降低,尤其是对不熟悉缩写的人而言,会让人去猜作者的意图,这样的代码读起来确实很崩溃。
3,避免使用Python的关键字
一些Python保留字在编程过程中被Python所使用,所以不能用来命名变量。例如,一个变量的名称不能是print或者import
4,变量和函数的命名要有区分
当一个变量名称和函数名称很相似时,就引起了歧义。为了避免这种情况的发生,应该给变量命名加上一些不同的前缀或者后缀。比如我个人的习惯,对于变量的命名后缀会加上该变量的类型,字典,如studentDict,列表,如studentList。对于函数的命名看上去更像是一个描述句,如获取学生的名字,getStudentName()
5,命名的形式
比较常见的形式有两种,一是下划线的形式,二是驼峰式。下划线很好理解就是用下划线来连接各个段的命名,驼峰式是单词的首字母大写,整个命名中间没有下划线。
我个人比较喜欢用驼峰式,这样看上去整个程序更加的紧凑。不管是下划线还是驼峰式,原则是整个程序用一种统一的风格,不要一会用下划线,一会用驼峰式
二:函数设计
好的Python程序一定是有函数的设计在里面的,好多同学刚接触Python是用Python来写写脚本,实现一些简单的脚本功能,可能整个脚本加起来不过是几行或者几十行。但是如果要用Python实现了大点的功能,就一定要有函数的设计。
函数的设计也是有规范的,不是说我def一个函数,我的程序就有函数了,我就见过一个Python函数800行,看到最后都记不起来前面实现了啥。好的函数设计会让人赏心悦目

为什么要有函数的设计:
1. 函数是可重用的代码块,可以在程序的不同部分多次使用。
2. 函数可以接受任意数量的输入参数,并返回任意数量的输出结果。
3. 函数可以嵌套在其他函数中,从而实现更复杂的功能。
函数的设计应该遵循以下原则
1. 函数应该尽可能简单明了,只完成一个特定的任务。
2. 函数应该有一个清晰的名称,能够描述函数的功能。
3. 函数的输入和输出应该尽可能清晰明了,以便于其他程序员理解和使用。
4. 函数应该避免使用全局变量,而是使用局部变量。
5. 函数应该避免使用副作用,即修改参数或全局变量的值。
三:数据结构设计
接触编程的同学想必都知道下面的公式:

数据是程序的中心。数据结构和算法两个概念间的逻辑关系贯穿了整个程序世界,首先二者表现为不可分割的关系。没有数据间的有机关系,程序根本无法设计。数据结构是底层,算法高层。数据结构为算法提供服务。算法围绕数据结构操作。
数据结构是编程中的基础,不同的数据结构适用于不同的场景,选择合适的数据结构可以提高程序的效率和可读性。可以这么说一般的功能,设计好了数据结构,算法就是顺势而为了。
Python常见的数据结构包括列表(List)、元组(Tuple)、字典(Dictionary)和集合(Set),我们要擅于利用这四种数据结构,灵活组合使用可以大大提高程序的效率同时降低实现的难度。
下面我们通过形象的描述来展示他们的用途和特点,了解它们的基本操作和复杂度分析可以帮助我们更好地应用它们来处理数据
1,列表(List)就像我们的购物清单,可以记录我们要买的多种物品。我们可以随时增加或删除其中的物品,也可以根据需要对它们进行排序。
2,元组(Tuple)就像我们的收据,一旦生成就不可更改,用于存储一组固定的数据,例如一个订单的订单号和价格。
3,字典(Dictionary)就像我们的地址簿,可以通过一个关键字(例如姓名)来查找对应的值(例如电话号码)。字典可以随时添加或删除条目,也可以根据需要进行排序。
4,集合(Set)就像我们的珍藏品,可以存储多个独立的元素,但每个元素只能在集合中出现一次。集合支持常见的集合操作,例如并集、交集和差集
Python常见的数据结构可以分为以下几类:
1,序列型数据结构:这类数据结构是有序的元素集合,可以通过索引访问。主要包括列表(List)、元组(Tuple)和字符串(String)
2,映射型数据结构:这类数据结构是基于键值对(key-value)的映射关系。主要有字典(Dict)。
3,集合型数据结构:这类数据结构中的元素是无序且不重复的。主要有集合(Set)。
4,数值型数据结构:这类数据结构用于存储相同类型的数值数据,更加节省空间。主要有数组(Array)。
在进行大规模数据操作时,需要注意时间复杂度,选择合适的数据结构和算法以提高效率。
四:程序框架设计
好的程序不仅要考虑功能的实现,也要考虑功能的可扩展性和可复用性。当需求变更的时候,整个程序能以最小的改动来实现新的需求或者需求的变更。这就需要程序刚开始的时候得设计出好的框架。
好的框架具备以下的特点:
1,类的设计:类的基本作用是封装代码,我们知道python是一个面向对象的计算机编程语言,面向对象的特点就是程序内的一切皆是对象,而面向对象也有着继承、封装、多态这三大特性。类能够实现面向对象三大特性,例如封装实际上就是将多个方法或者是属性放在一个私有类之中,而这个私有类不会被其他对象所访问。继承指的就是一个类去继承另一个类的所有方法和属性,这样它就能够使用两个类的对象了。多态就是类中的方法是可以被重写的,子类将父类已经创建好的方法使用不同的参数和数据类型进行再构造就是多态。
2,类的功能单一:在大型程序中就是以类为单元,如果类的规模过大,功能不单一,在需求变更或者新的需求,想复用代码就比较困难,如果随着功能的实现或者需求的增加,类的功能不再单一的时候,得及时去拆分类,提取公共的类,保持类的功能单一,控制类的规模
3,尽量避免使用全局变量:全局变量的出现会让程序的移植性变差,全局变量使用不当也会影响程序的健壮性。
4,程序主入口尽量简洁:整个程序的入口要尽量简洁,最好整个程序的实现流程能在主入口就能体现,这会让读代码的人更加容易理解程序的流程。不要把过多具体的实现放在主入口里,影响代码的可读性。
5,设计好的数据结构:我们拿到需求的那一刻,不要急于编码,要充分理解需求,将需求转化成具体的模型,根据模型去设计功能实现所需要的数据结构。好的数据结构,能大大简化我们的功能代码,降低功能实现的难度。
五:文件结构设计
在实现一个复杂程序时,需要编写的代码量往往很庞大。将所有的代码都放在一个文件里,显然很不合适。这时就需要将代码分割成多个文件,每个文件中放置功能相对独立的代码。在使用时,同时将多个文件中的代码导入到当前代码文件中,以实现完整的功能。这种被裁分后的仍具有独立功能的代码文件就是模块(Module)。概括地说,模块是一个支持导入功能的,以 .py 结尾的代码文件。
当模块足够庞大时,维护起来不太方便。这就需要使用包(Package)。包可以把多个模块(.py文件)放在同一个文件夹中,以便归类与管理。概括地说,包就是放置模块的文件夹。
下面展示一个Python包的样例:
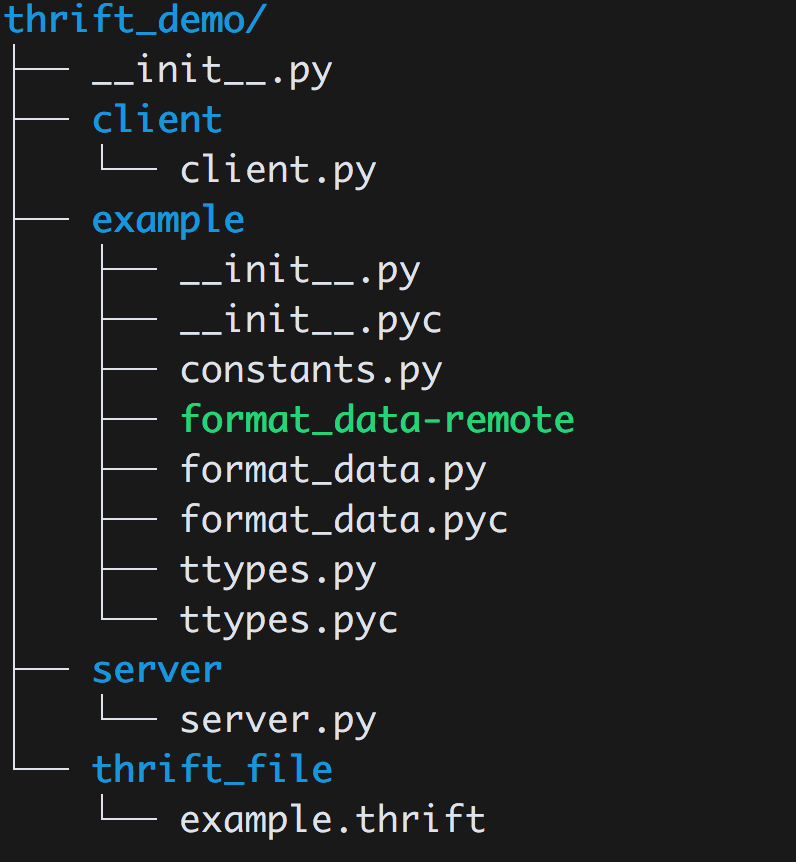
1,Python程序由包(package)、模块(module)和函数组成。包是由一系列模块组成的集合。模块是处理某一类问题的函数和类的集合
2,包就是一个完成特定任务的工具箱
3,包必须含有一个__init__.py文件,它用于标识当前文件夹是一个包
4,python的程序是由一个个模块组成的。模块把一组相关的函数或代码组织到一个文件中,一个文件即是一个模块。模块由代码、函数和类组成。导入模块使用import语句