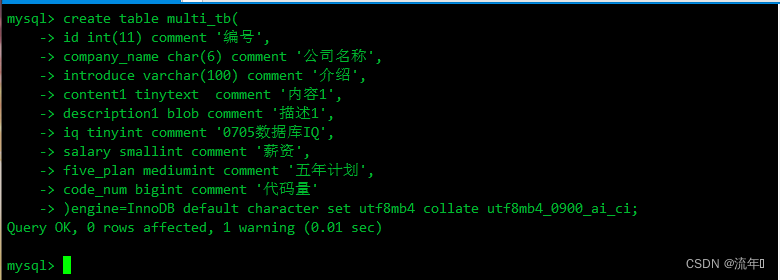
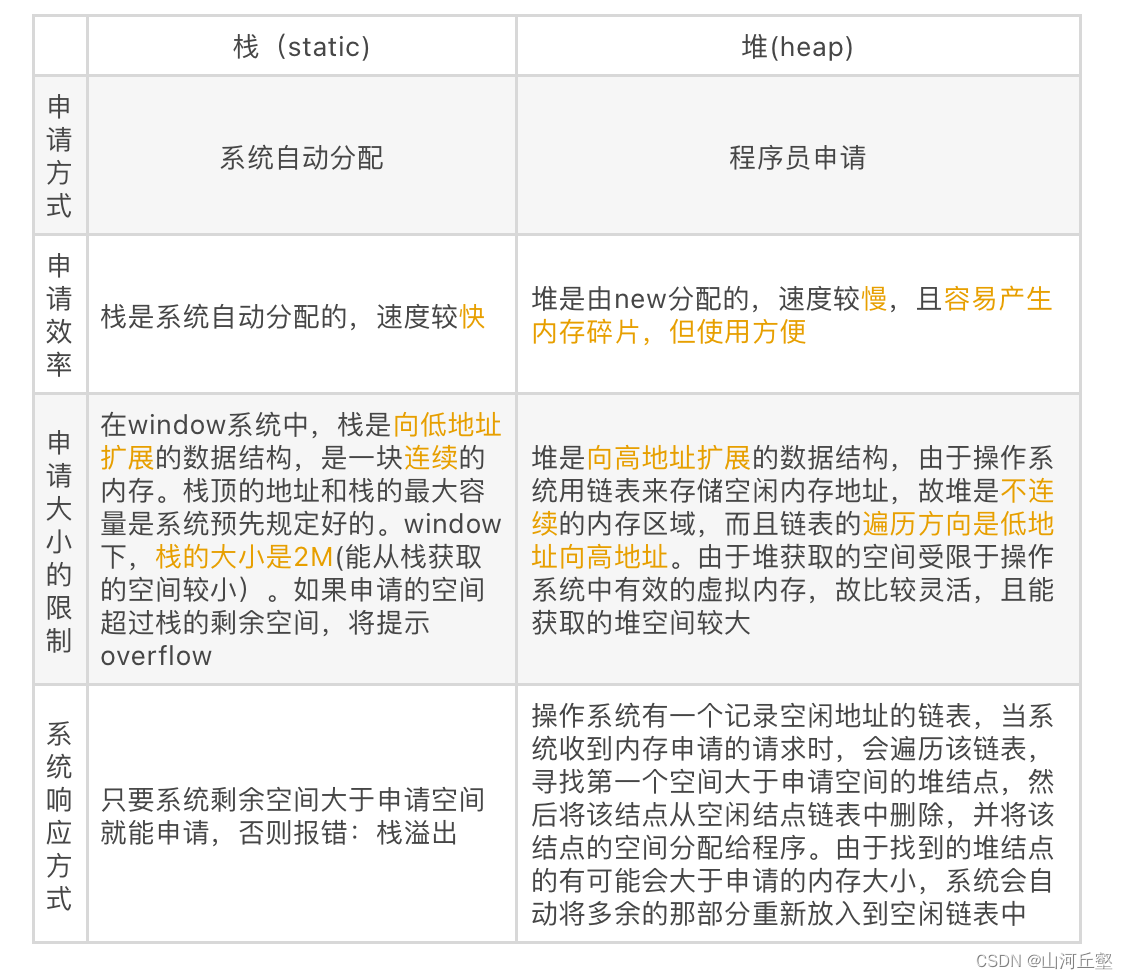
算法分析和设计选择和判断
目录
平时测试
1.算法概述
1.1渐进符号的概念
1.2求时间复杂度
1.3比较时间复杂度
1.4时间复杂度定义
1.5算法的有效性
1.6算法的性质
1.7顺序搜索法
1.8渐进算法分析
2.递归和分治策略
2.1归并排序
2.2归并的空间复杂度
2.3插入排序
2.4递归
2.5归并排序
2.6外排序
2.7二分查找
2.8分治法
2.9快速排序
2.10二分查找
2.11归并排序
2.12分治法思想
2.13快速排序
2.14算法分析的主要方面
2.15快速排序时间复杂度
2.16比较算法
2.17时间复杂度
2.18判断:插入排序
3.动态规划
3.1切原木问题
3.2动态规划
3.3递推方程
3.4最优二叉树
3.5动态规划
3.6动态规划相关
4.贪心算法
4.1 0-1背包问题
4.2哈夫曼编码
4.3哈夫曼编码
4.4活动选择问题
4.5局部最优解
4.6活动选择问题
4.7活动选择问题
4.8最优前缀编码
5.回溯和分治限界法
5.1分治限界法
5.2优先队列
5.3回溯和分支限界法
5.4回溯搜索法
5.5回溯解决最优装载
1.算法概述作业题
2.分治法作业
3.动态规划
4.贪心算法
5.分支限界法
1.算法概述
1.1渐进符号的概念
算法分析中,记号O表示渐进上界,记号Ω表示( )
A.渐进下界
B.渐进上界
C.非紧上界
D.紧渐进界
1.2求时间复杂度
2n2 + n + 2100 ,以下( )是不正确描述
- A.Ω(logn) 下界
- B.2100
- C.Θ(n2)紧确界
- D.O(n3)上界
渐进上界:存在n0和c比当前的函数值大就行。
渐进下界:存在n0和c比当前的数小就行
紧确界:存在n0和c1和c2使得当前函数在中间
1.3比较时间复杂度
当输入规模为n时,算法增长率最小的是( )。
- A.2n2
- B.20log2n
- C.3nlog3n
- D.5n
常数<对数<线性
2n2算法的增长率是O(n^2)
20log2n的增长率为O(logn)
3nlog3n增长率为O(nlogn)
5n的是O(n)
所以说B是最小的
1.4时间复杂度定义
判断什么时候用什么时间复杂度
当上下限表达式相等时,我们使用下列哪种表示法来描述算法代价?( )
- A.大Ω表示法
- B.Θ表示法
- C.大O表示法
- D.小o表示法
解析:关键点就是上下限相等
1.5算法的有效性
概念理解:什么叫做算法的有效性
解决一个问题通常有多种方法。若说一个算法“有效”是指( )。
- A.这个算法比其他已知算法都更快地将问题解决
- B.这个算法能在一定的时间和空间资源限制内将问题解决
- C.这个算法能在人的反应时间内将问题解决
- D.这个算法能在一定的时间和空间资源限制内将问题解决;这个算法比其他已知算法都更快地将问题解决。
解析:算法肯定是有限制的,需要在一定的空间和时间资源的限制中去完成我们需要完成的事情。
1.6算法的性质
算法性质的概念
一个算法应该包含如下几条性质,除了( )。
- A.有限性
- B.正确性
- C.可终止性
- D.二义性
解析:算法的性质
- 有限性
- 正确性
- 可终止
- 确定性
1.7顺序搜索法
采用“顺序搜索法”从一个长度为N的随机分布数组中搜寻值为K的元素。以下对顺序搜索法分析正确的是( )。
- A.最佳情况的渐进代价要好于平均情况的渐进代价,而平均情况的渐进代价要好于最差情况的渐进代价
- B.最佳情况、最差情况和平均情况下,顺序搜索法的渐进代价都相同
- C.最佳情况的渐进代价要好于最差情况和平均情况的渐进代价
- D.最佳情况和平均情况的渐进代价要好于最差情况的渐进代价
解析:
最佳就是第一个就是我们需要找的元素,代价是最小的
最坏:最后一个或者是找不到。代价最大需要比较所有的元素
平均:需要比较大约一半的元素。
1.8渐进算法分析
渐进算法分析的概念。和渐进符号是有关系的。
渐进算法分析是指( )。
- A.算法在最佳情况、最差情况和平均情况下的代价
- B.在最小输入规模下算法的资源代价
- C.数据结构所占用的空间
- D.当规模逐步往极限方向增大时,对算法资源开销“增长率”上的简化分析
解析:就是对算法资源开销的一种简化分析。
2.递归和分治策略
2.1归并排序
归并排序的时间复杂度
对N个记录进行归并排序,归并趟数的数量级是( ):
- A.O(logN)
- B.O(N2 )
- C.O(N)
- D.O(NlogN)
解析:
拆分的时间复杂度是O(logN),因为每次拆分都将数组规模减半,需要进行logN次拆分。
合并的时间复杂度是O(N),因为合并过程需要比较和移动每个元素,而每个元素最多只会被比较和移动一次。
因此,总的时间复杂度是O(NlogN)。

| private static void mergeSort(int[] arr) { mergeSort(arr, 0, arr.length - 1); } private static void mergeSort(int[] arr, int low, int high) { int mid = (low + high) / 2; if (low < high) { mergeSort(arr, low, mid); mergeSort(arr, mid + 1, high); //左右归并 merge(arr, low, mid, high); } } private static void merge(int[] arr, int low, int mid, int high) { int[] temp = new int[high - low + 1]; int i = low; int j = mid + 1; int k = 0; // 把较小的数先移到新数组中 while (i <= mid && j <= high) { if (arr[i] < arr[j]) { temp[k++] = arr[i++]; } else { temp[k++] = arr[j++]; } } // 把左边剩余的数移入数组 while (i <= mid) { temp[k++] = arr[i++]; } // 把右边边剩余的数移入数组 while (j <= high) { temp[k++] = arr[j++]; } System.arraycopy(temp, 0, arr, low, temp.length); } |
2.2归并的空间复杂度
需要借助一个temp数组
对N个记录进行归并排序,空间复杂度为( ):
- A.O(N)
- B.O(NlogN)
- C.O(logN)
- D.O(N2)
解析:
在归并排序中,需要使用额外的空间来存储临时数组。这个临时数组的长度与待排序的数组长度相同,所以空间复杂度是O(N)。
2.3插入排序
下列排序算法中,( )算法可能出现:在最后一趟开始之前,所有的元素都不在其最终的位置上?(设待排元素个数N>2)
- A.冒泡排序
- B.快速排序
- C.堆排序
- D.插入排序
解析:
插入排序算法可能出现在最后一趟开始之前,所有的元素都不在其最终的位置上。
插入排序是一种简单直观的排序算法,在每一趟排序中,它将一个元素插入到已排序序列的合适位置,并保持已排序序列的顺序。当待排序数组中的元素相对有序时,插入排序可以达到较好的效率。
然而,如果待排序数组是逆序的或者部分有序的,插入排序需要进行多次元素交换才能将一个元素移动到其最终位置。因此,在最后一趟开始之前,所有的元素都可能不在其最终的位置上。
2.4递归
递归通常用( )来实现。
- A.有序的线性表
- B.数组
- C.栈
- D.队列
解析:
在递归算法中,每次递归调用都会将当前的执行状态(包括变量值、返回地址等)保存在栈中,然后进入下一层递归。当递归到达基本情况(递归结束条件)后,开始逐层返回,并从栈中取回保存的执行状态,继续执行之前的操作。
由于递归的本质是函数的嵌套调用,而函数调用的时候会使用栈来保存执行状态,因此栈结构在实现递归时非常常用。
2.5归并排序
若数据元素序列{ 12, 13, 8, 11, 5, 16, 2, 9 }是采用下列排序方法之一得到的第一趟排序后的结果,则该排序算法只能是( ):
- A.堆排序
- B.归并排序
- C.快速排序
- D.选择排序
解析:
2.6外排序
在外排序中,设我们有5个长度分别为2、8、9、5、3的有序段。则下列哪种归并顺序可以得到最短归并时间?( )
- A.归并长度为2和3的有序段,得到段Run#1;将Run#1与长度为5的有序段归并,得到段Run#2;归并长度为8和9的有序段,得到段Run#3;归并Run#2和Run#3
- B.归并长度为2和3的有序段,得到段Run#1;归并长度为5和8的有序段,得到段Run#2;归并Run#1和Run#2,得到段Run#3;将Run#3与长度为9的有序段归并
- C.归并长度为2和3的有序段,得到段Run#1;归并长度为5和8的有序段,得到段Run#2;将Run#2与长度为9的有序段归并,得到段Run#3;归并Run#1和Run#3
- D.归并长度为2和3的有序段,得到段Run#1;将Run#1与长度为5的有序段归并,得到段Run#2;将Run#2与长度为8的有序段归并,得到段Run#3;将Run#3与长度为9的有序段归并
2.7二分查找
对线性表进行二分查找时,要求线性表必须( )。
- A.以链接方式存储
- B.以链接方式存储,且结点按关键字有序排序
- C.以顺序方式存储
- D.以顺序方式存储,且结点按关键字有序排序
2.8分治法
用分治法解决一个规模为N的问题。下列哪种方法是最慢的?( )
- A.每步将问题分成规模均为N/3的3个子问题,且治的步骤耗时O(NlogN)
- B.每步将问题分成规模均为N/3的2个子问题,且治的步骤耗时O(NlogN)
- C.每步将问题分成规模均为N/2的3个子问题,且治的步骤耗时O(N)
- D.每步将问题分成规模均为N/3的2个子问题,且治的步骤耗时O(N)
2.9快速排序
采用递归方式对顺序表进行快速排序,下列关于递归次数的叙述中,正确的是( ):
- A.每次划分后,先处理较短的分区可以减少递归次数
- B.递归次数与初始数据的排列次序无关
- C.每次划分后,先处理较长的分区可以减少递归次数
- D.递归次数与每次划分后得到的分区处理顺序无关
解析:
2.10二分查找
用二分查找从100个有序整数中查找某数,最坏情况下需要比较的次数是( ):
- A.10
- B.99
- C.50
- D.7
解析:二分查找的最大比较次数是⌊ l o g ( N ) ⌋ + 1 \lfloor log(N) \rfloor+1⌊log(N)⌋+1
二分搜索方法充分利用了元素间的次序关系,采用分治策略,可在最坏情况下用 O(logn) 时间完成搜索任务;该题中有log100+1=6+1=7
2.11归并排序
给定 100,000,000 个待排记录,每个记录 256 字节,内存为128MB,一次只能读入512个记录,若采用简单2路归并,需要做多少轮?( )
- A.9
- B.8
- C.10
- D.7
解析:1MB有4个记录,内存总共128×4 = 512个记录,512=29,则需要做 log 29 = 9(log以2为底)轮;
2.12分治法思想
分治法的设计思想是将一个难以直接解决的大问题分割成规模较小的子问题,分别解决子问题,最后将子问题的解组合起来形成原问题的解。这要求原问题和子问题( )。
- A.问题规模不同,问题性质不同
- B.问题规模相同,问题性质相同
- C.问题规模不同,问题性质相同
- D.问题规模相同,问题性质不同
解析:
2.13快速排序
在寻找n个元素中第k小元素问题中,如快速排序算法思想,运用分治算法对n个元素进行划分,如何选择划分基准?下面( )答案解释最合理。
- A.以上皆可行。但不同方法,算法复杂度上界可能不同
- B.随机选择一个元素作为划分基准
- C.用中位数的中位数方法寻找划分基准
- D.取子序列的第一个元素作为划分基准
2.14算法分析的主要方面
算法分析的两个主要方面是时间复杂度和空间复杂度的分析。( )
- 对
- 错
2.15快速排序时间复杂度
对N个记录进行快速排序,在最坏的情况下,其时间复杂度是O(NlogN)。( )
- 对
- 错
2.16比较算法
仅基于比较的算法能得到的最好的“最坏时间复杂度”是O(NlogN)。( )
- 对
- 错
2.17时间复杂度
在具有N个结点的单链表中,访问结点和增加结点的时间复杂度分别对应为O(1)和O(N)( )
- 对
- 错
解析:访问节点的时间复杂度为O(N)
2.18判断:插入排序
插入排序算法在最好情况下的时间复杂度为O(n)。( )
- 对
- 错
解析:当待排序的数组已经是有序的时候,插入排序只需要进行 n-1 次比较,而不需要进行元素的移动操作。在这种情况下,插入排序的时间复杂度达到了最优值 O(n)。
因此,对于已经有序或接近有序的输入,插入排序是一种高效的排序算法,它可以快速完成排序操作。
需要注意的是,插入排序的平均时间复杂度为 O(n^2),在最坏情况下也会达到 O(n^2),因此在处理大规模随机无序的数据时,可能存在更优秀的排序算法。
3.动态规划
3.1切原木问题
切原木问题:给定一根长度为N米的原木;另有一个分段价格表,给出长度L=1,2,⋯,M对应的价格P L 。要求你找出适当切割原木分段出售所能获得的最大收益R N 。例如,根据下面给出的价格表,若要出售一段8米长的原木,最优解是将其切割为2米和6米的两段,这样可以获得最大收益R8 =P2+P6=5+17=22。而若要出售一段3米长的原木,最优解是根本不要切割,直接售出。Length L 1 2 3 4 5 6 7 8 9 10, Price PL 1 5 8 9 10 17 17 20 23 28, 下列哪句陈述是错的?( )
- A.算法的时间复杂度是O(N2 )
- B.此问题可以用动态规划求解
- C.若N>M,则有RN =max1≤i {Ri +RN−M }
- D.若N≤M,则有RN =max{PN ,max1≤i {Ri +RN−i }}
3.2动态规划
在动态规划中,我们要推导出一个子问题的解与其他子问题解的递推关系。要将这种关系转换为自底向上的动态规划算法,我们需要以正确的顺序填写子问题解的表格,使得在解任一子问题时,所有它需要的子问题都已经被解决了。在下列关系式中,哪一个是不可能被计算的?( )
- A.A(i,j)=F(A(i,j−1),A(i−1,j−1),A(i−1,j+1))
- B.A(i,j)=F(A(i−2,j−2),A(i+2,j+2))
- C.A(i,j)=min(A(i−1,j),A(i,j−1),A(i−1,j−1))
- D.A(i,j)=F(A(min{i,j}−1,min{i,j}−1),A(max{i,j}−1,max{i,j}−1))
3.3递推方程
给定递推方程 f i,j,k =f i,j+1,k + min 0≤l≤k {f i−1,j,l +w j,l }。要通过循环解此方程,我们一定不能用下列哪种方法填表?( )
- A.for k in 0 to n: for i in 0 to n: for j in n to 0
- B.for i in 0 to n: for j in n to 0: for k in n to 0
- C.for i in 0 to n: for j in 0 to n: for k in 0 to n
- D.for i in 0 to n: for j in n to 0: for k in 0 to n
3.4最优二叉树
最优二叉搜索树的根结点一定存放的是搜索概率最高的那个关键字。( )
- 对
- 错
3.5动态规划
如果一个问题可以用动态规划算法解决,则总是可以在多项式时间内解决的。( )
- 对
- 错
3.6动态规划相关
用动态规划而非递归的方法去解决问题时,关键是将子问题的计算结果保存起来,使得每个不同的子问题只需要被计算一次。子问题的解可以被保存在数组或哈希散列表中。( )
- 对
- 错
4.贪心算法
4.1 0-1背包问题
对于0-1背包问题和背包问题的解法,下面( )答案解释正确。
- A.0-1背包问题和背包问题都可用贪心算法求解
- B.0-1背包问题可用贪心算法求解,但背包问题则不能用贪心算法求解
- C.0-1背包问题不能用贪心算法求解,但可以使用动态规划或搜索算法求解,而背包问题则可以用贪心算法求解
- D.因为0-1背包问题不具有最优子结构性质,所以不能用贪心算法求解
4.2哈夫曼编码
给定一段文本中的 4 个字符 (u,v,w,x) 及其出现频率 (fu,fv,fw,fx)。若对应的哈夫曼编码为 u: 00, v: 010, w: 011, x: 1,则下列哪组频率可能对应(fu,fv,fw,fx)? ( )
- A.15, 23, 16, 45
- B.30, 21, 12, 33
- C.41, 12, 20, 32
- D.55, 22, 18, 46
4.3哈夫曼编码
给定一段文本中的4个字符(a, b, c, d)。设a和b具有最低的出现频率。下列哪组编码是这段文本可能的哈夫曼编码?( )
- A.a: 000, b:001, c:01, d:1
- B.a: 000, b:001, c:01, d:11
- C.a: 000, b:001, c:10, d:1
- D.a: 010, b:001, c:01, d:1
4.4活动选择问题
在活动选择问题(Activity Selection Problem)中,令 S 为活动的集合。以“每次收集最迟开始的活动”为贪心原则,可以正确找到 S 中相互兼容活动的最大规模的子集合。( )
- 对
- 错
4.5局部最优解
只有当局部最优跟全局最优解一致的时候,贪心法才能给出正确的解。( )
- 对
- 错
4.6活动选择问题
令S为活动选择问题(Activity Selection Problem)中所有活动的集合。则一定存在S的某个最大相容活动子集是包含了最早结束的活动am的。( )
- 对
- 错
4.7活动选择问题
令S为活动选择问题(Activity Selection Problem)中所有活动的集合。则最早结束的活动am一定被包含在S的所有最大相容活动子集中。( )
- 对
- 错
4.8最优前缀编码
令 C 为字母集,其中每个字符 c 有对应频率 c.freq。若 C 的大小为 n,则其中任一字符 c 的最优前缀编码长度都不会超过 n−1. ( )
- 对
- 错
5.回溯和分治限界法
5.1分治限界法
在分支限界算法中,根据从活结点表中选择下一扩展结点的不同方式可有几种常用分类,以下( )描述最为准确
- A.采用最大值堆的优先队列式分支限界法
- B.采用FIFO队列的队列式分支限界法
- C.采用最小值堆的优先队列式分支限界法
- D.以上都常用,针对具体问题可以选择采用其中某种更为合适的方式
5.2优先队列
优先队列通常用以下( )数据结构来实现。
- A.队列
- B.堆
- C.二叉查找树
- D.栈
5.3回溯和分支限界法
关于回溯算法和分支限界法,以下( )是不正确描述。
- A.回溯法中,每个活结点只有一次机会成为扩展结点
- B.回溯法采用深度优先的结点生成策略
- C.分支限界法中,活结点一旦成为扩展结点,就一次性产生其所有儿子结点,在这些儿子结点中,那些导致不可行解或导致非最优解的儿子结点被舍弃,其余儿子加入活结点表中
- D.分支限界法采用广度优先或最小耗费优先(最大效益优先)的结点生成策略
5.4回溯搜索法
关于回溯搜索法的介绍,下面( )是不正确描述。
- A.回溯法是一种既带系统性又带有跳跃性的搜索算法
- B.回溯算法在生成解空间的任一结点时,先判断该结点是否可能包含问题的解,如果肯定不包含,则跳过对该结点为根的子树的搜索,逐层向祖先结点回溯
- C.回溯法有“通用解题法”之称,它可以系统地搜索一个问题的所有解或任意解
- D.回溯算法需要借助队列这种结构来保存从根结点到当前扩展结点的路径
5.5回溯解决最优装载
用回溯法求解最优装载问题时,若待选物品为m种,则该问题的解空间树的结点个数为( )。
- A.2m+1
- B.2m
- C.m!
- D.2m+1-1
1.算法概述作业题
算法分析题:1-1、1-2、1-3、1-4
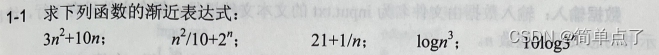
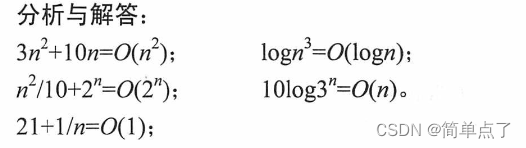
![]()
![]()



2.分治法作业
2 算法分析题:2-3,2-13





3.动态规划
3 对矩阵规模序列<5,10,3,12,5,50,6>,求矩阵链最优括号化方案




4 对于0-1背包问题,试设计一个解决此问题的动态规划算法,并分析算法的复杂性