🎏目录
🎈1 SGD
🎄1.1 原理
🎄1.2 构造
🎄1.3 参数详解——momentum
✨1 SGD
🥚2.1 原理
SGD为随机梯度下降,原理可看刘建平老师博客。
🎃 2.2 构造
构造:
class torch.optim.SGD(
params,
lr,
momentum=0,
dampening=0,
weight_decay=0,
nesterov=False
)
参数:
params:需要优化的参数lr:float, 学习率momentum:float,动量因子dampening:float,动量的抑制因子weight_decay:float,权重衰减nesterov:bool,是否使用Nesterov动量
🎉 2.3 参数详解——momentum
一般随机梯度下降时,每次更新公式都是:
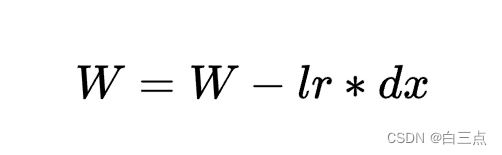
而增加动量后,公式是:

即在原值乘一个动量因子momentum(0<momentum<1),起到减速作用:
以一个例子说明,假设现梯度为5,经历两次梯度变化分别是-2和+3,momuntu=0.9。
传统下经历两次梯度变化,最终梯度应该是5=》3=》6。
使用momentum后本次梯度应该是5=》3=》0.9*3+3=5.7。局部上第二次梯度变化虽然仍是+3,但是由于使用了momuntu,整体上看是+2.7,起到一个减速作用。