在研究农情的方向中,作物计数是一个很重要的方向,前文已经提到了一些要使用的方法
前文链接:作物计数方法汇总_追忆苔上雪的博客-CSDN博客
在研究计数过程中,还需要将上文处理过的数据信息存入json文件方便后续使用,这里参考FSC147数据集的json文件写了一个脚本传入我们上述获得文件信息
<1>FSC147数据集json文件研究
先写一个测试脚本看看FSC147数据集json文件的构成
import json
with open('annotation_FSC147_384.json') as f:
json_1 = json.load(f)
print(type(json_1)) # <class 'dict'>
print(json_1.keys())
a = json_1['999.jpg']
print('标记:', a, '标记:', type(a), a.keys()) # 标记: <class 'dict'>
# dict_keys(['H', 'W', 'box_examples_coordinates', 'box_examples_path', 'density_path',
# 'density_path_fixed', 'img_path', 'points', 'r', 'ratio_h', 'ratio_w'])输出结果如下
1)json文件文件的类型和格式(这里复制了部分的输出结果)
<class 'dict'>
dict_keys(['1050.jpg', '1053.jpg', '1061.jpg', '1074.jpg', '1077.jpg', '1084.jpg',
'1085.jpg', '1087.jpg', '1106.jpg', '1123.jpg', '1130.jpg', '1246.jpg',
'1282.jpg', '1306.jpg', '1325.jpg', '1328.jpg', '1386.jpg', '1391.jpg',
'1397.jpg', '1455.jpg', '1456.jpg', '1458.jpg', '1461.jpg', '1462.jpg',
'1463.jpg', '1464.jpg', '1467.jpg', '1493.jpg', '1497.jpg', '1509.jpg',
'1537.jpg', '1572.jpg', '1625.jpg', '1636.jpg', '1668.jpg', '1762.jpg',
'996.jpg', '998.jpg', '999.jpg'])从输出结果来看,json内容是由字典构成的,字典的键是相对应图片的名字
2)json文件键值对中对应的值内容
上面我们知道了目标json文件是一对一对键值构成的字典形式,为了完成这个json文件,再来看一下每一对键值对应的内容,这里选择了其中一个图片的信息,可以看到其中的数值还是由字典构成
标记: {'H': 300,
'W': 218,
'box_examples_coordinates': [[[143, 22], [143, 66], [201, 66], [201, 22]], [[142, 170], [142, 217], [213, 217], [213, 170]], [[124, 300], [124, 338], [179, 338], [179, 300]]],
'box_examples_path': ['/nfs/bigneuron/viresh/FSC_NewDataOnly/box_examples/999_0.jpg', '/nfs/bigneuron/viresh/FSC_NewDataOnly/box_examples/999_1.jpg', '/nfs/bigneuron/viresh/FSC_NewDataOnly/box_examples/999_2.jpg'],
'density_path': '/nfs/bigneuron/viresh/FSC_NewDataOnly/gt_density_map_adaptive_384_VarV2/999.npy',
'density_path_fixed': '/nfs/bigneuron/viresh/FSC_NewDataOnly/gt_density_map_fixed/999.npy',
'img_path': '/nfs/bigneuron/viresh/FSC_NewDataOnly/images_384_VarV2/999.jpg',
'points': [[9.65724770642202, 199.36], [40.23853211009175, 50.0352], [106.58532110091744, 36.6592], [163.59302752293578, 40.7296], [248.65541284403673, 53.5296], [343.93651376146795, 40.1408], [354.1552293577982, 190.2592], [257.17100917431196, 213.5296], [178.06018348623854, 197.824], [149.12587155963305, 312.4352], [87.86972477064221, 299.0592], [217.19449541284405, 289.74080000000004], [272.4803669724771, 296.1408], [375.41614678899083, 283.9296]],
'r': [22, 22],
'ratio_h': 1.28,
'ratio_w': 1.871559633027523}
标记: <class 'dict'>
dict_keys(['H', 'W',
'box_examples_coordinates',
'box_examples_path',
'density_path',
'density_path_fixed',
'img_path',
'points',
'r',
'ratio_h',
'ratio_w'])可以看到其中包括图片的高和宽信息,密度图的路径,原图的路径,点的位置等信息
3)开始上手生成所需的json文件
1.获取json字典的"键"名字
上面已经知道,json字典的键名字是图片的名字,利用脚本获取键名, 并存入列表中以供后续使用
import os
path = r'D:\苏大研究生生活\2023项目\遥感\栅格图分割\jpgImages-part'
files = os.listdir(path)
# print(files)
key_outer = [] # 创建空列表储存键命
for file in files:
file_name = os.path.basename(os.path.realpath(file))
# print(file_name, type(file_name)) # 示例:watermelon_transparent_mosaic_group1_23.jpg
key_outer.append(file_name)
print(key_outer)输出结果如下
['watermelon_transparent_mosaic_group1_23.jpg', 'watermelon_transparent_mosaic_group1_24.jpg', 'watermelon_transparent_mosaic_group1_25.jpg', 'watermelon_transparent_mosaic_group1_26.jpg', 'watermelon_transparent_mosaic_group1_27.jpg', 'watermelon_transparent_mosaic_group1_28.jpg', 'watermelon_transparent_mosaic_group1_29.jpg', 'watermelon_transparent_mosaic_group1_30.jpg', 'watermelon_transparent_mosaic_group1_31.jpg', 'watermelon_transparent_mosaic_group1_32.jpg', 'watermelon_transparent_mosaic_group1_33.jpg', 'watermelon_transparent_mosaic_group1_34.jpg', 'watermelon_transparent_mosaic_group1_35.jpg', 'watermelon_transparent_mosaic_group1_36.jpg', 'watermelon_transparent_mosaic_group1_43.jpg', 'watermelon_transparent_mosaic_group1_44.jpg', 'watermelon_transparent_mosaic_group1_45.jpg', 'watermelon_transparent_mosaic_group1_46.jpg', 'watermelon_transparent_mosaic_group1_47.jpg', 'watermelon_transparent_mosaic_group1_48.jpg']2.获取json字典的"值"并组合
上面已经知道每一个键对应的值还是一个字典
根据实际的内容,我们需要获取
'H', 'W', 'density_path', 'img_path', 'points'这五个信息,获取这五个信息后,组合成字典并与上述获得的键再进行组合成一个嵌套的字典
import os
import json
# 先提取外层键值对的键
path = r'D:\苏大研究生生活\2023项目\遥感\栅格图分割\jpgImages-part'
files = os.listdir(path)
# print(files)
key_outer = [] # 创建空列表储存键命
for file in files:
file_name = os.path.basename(os.path.realpath(file))
# print(file_name, type(file_name)) # 示例:watermelon_transparent_mosaic_group1_23.jpg
key_outer.append(file_name)
# print(key_outer)
"""获取json外层字典的内容"""
value_outer = [] # 创建空列表存储值内容
json_inner_key = {'H': '', 'W': '', 'density_path': '', 'img_path': '', 'points': '', } # 先创建一个空字典
json_inner_info = ["64", "576", "", "", ""] # 64, 576是H和W的数值,这是之前对图像切片的尺寸
# 获取指定密度图路径
str_density = str('D:/苏大研究生生活/2023项目/遥感/栅格图分割/density_map')
# density_path_info = os.listdir(r'D:\苏大研究生生活\2023项目\遥感\栅格图分割\density_map')
str_Img = str('D:/苏大研究生生活/2023项目/遥感/栅格图分割/jpgImages-part')
# Img_path_info = os.listdir(r'D:\苏大研究生生活\2023项目\遥感\栅格图分割\jpgImages-part')
label_path = 'D:\\苏大研究生生活\\2023项目\\遥感\\栅格图分割\\label'
files = os.listdir(label_path) # 返回文件夹包含名字的名字列表
for name in files:
name_dir = name.split('.')[0]
# print(name_dir)
if name.endswith('.json'): # 判断文件名是否以json结尾
fp = open(os.path.join(label_path, name), 'r') # 读取文件
json_data = json.load(fp) # 读取json格式数据
# print(json_data)
points_data = json_data['shapes'] # 读取shapes对象的内容
# print(points_data)
for point in points_data:
# print(point, point.keys()) # dict_keys(['label', 'points', 'group_id', 'description', 'shape_type', 'flags'])
# print(point['points'][0]) # point['points'][0]就是每个点的坐标,如[302.7354260089686, 30.53811659192826]
coordinate = point['points'][0] # 提取坐标值
# print(coordinate)
density_path_dir = str_density + '/' + name_dir
Img_path_dir = str_Img + '/' + name_dir
json_inner_info[2] = density_path_dir # 指定更新列表的数值
json_inner_info[3] = Img_path_dir # 指定更新列表的数值
json_inner_info[4] = coordinate
json_inner = dict(zip(json_inner_key.keys(), json_inner_info))
value_outer.append(json_inner)
# print(value_outer)
json_fin = dict(zip(key_outer, value_outer))
print(json_fin)部分输出结果如下
{'watermelon_transparent_mosaic_group1_23.jpg': {'H': '64', 'W': '576', 'density_path': 'D:/苏大研究生生活/2023项目/遥感/栅格图分割/density_map/watermelon_transparent_mosaic_group1_23', 'img_path': 'D:/苏大研究生生活/2023项目/遥感/栅格图分割/jpgImages-part/watermelon_transparent_mosaic_group1_23', 'points': [606.7713004484305, 45.33632286995517]},
'watermelon_transparent_mosaic_group1_24.jpg': {'H': '64', 'W': '576', 'density_path': 'D:/苏大研究生生活/2023项目/遥感/栅格图分割/density_map/watermelon_transparent_mosaic_group1_24', 'img_path': 'D:/苏大研究生生活/2023项目/遥感/栅格图分割/jpgImages-part/watermelon_transparent_mosaic_group1_24', 'points': [351.16591928251125, 573.1390134529148]},
'watermelon_transparent_mosaic_group1_25.jpg': {'H': '64', 'W': '576', 'density_path': 'D:/苏大研究生生活/2023项目/遥感/栅格图分割/density_map/watermelon_transparent_mosaic_group1_25', 'img_path': 'D:/苏大研究生生活/2023项目/遥感/栅格图分割/jpgImages-part/watermelon_transparent_mosaic_group1_25', 'points': [443.542600896861, 572.6905829596412]},
'watermelon_transparent_mosaic_group1_26.jpg': {'H': '64', 'W': '576', 'density_path': 'D:/苏大研究生生活/2023项目/遥感/栅格图分割/density_map/watermelon_transparent_mosaic_group1_26', 'img_path': 'D:/苏大研究生生活/2023项目/遥感/栅格图分割/jpgImages-part/watermelon_transparent_mosaic_group1_26', 'points': [546.2331838565023, 631.8834080717489]}3.字典传入json文件的方法
在获得上述字典的信息后,需要将json文件传入字典中
# 将字典传入json文件中,字典内容写入json时,需要用json.dumps将字典转换为字符串,然后再写入
with open('annotation_watermelon.json', 'w', encoding='utf-8') as f:
json.dump(json_fin, f, indent=4, sort_keys=True, ensure_ascii=False)
# 使用indent=4 参数来对json进行数据格式化输出,会根据数据格式缩进显示,读起来更加清晰
# Key是文本的时候,如果sort_keys是False,则随机打印结果,如果sortkeys为true,则按顺序打印, 这里要顺序写入
# json在进行序列化时,默认使用的是编码是ASCII,而中文为Unicode编码,ASCII中不包含中文,所以出现了乱码。
# 想要json.dumps()能正常显示中文,只要加入参数ensure_ascii=False即可,这样json在序列化的时候,就不会使用默认的ASCII编码
# 读取annotation_watermelon.json看看效果
with open('annotation_watermelon.json', encoding='utf-8') as f:
json_file = json.load(f)
print(json_file) # 打印一下生成的json文件看看有没有问题代码传入代码仓库中
为了后续的使用,个人需要将代码传入类似github的代码仓库中,这里要先学一下readme文件的编写,README文件后缀名为md;md是markdown的缩写,markdown是一种编辑博客的语言。
以下内容来自Markdown官方教程,:Markdown 标题语法 | Markdown 官方教程
<1>Markdown标题语法
要创建标题,请在单词或短语前面添加井号 (#) 。# 的数量代表了标题的级别。例如,添加三个 # 表示创建一个三级标题 (<h3>) (例如:### My Header)。
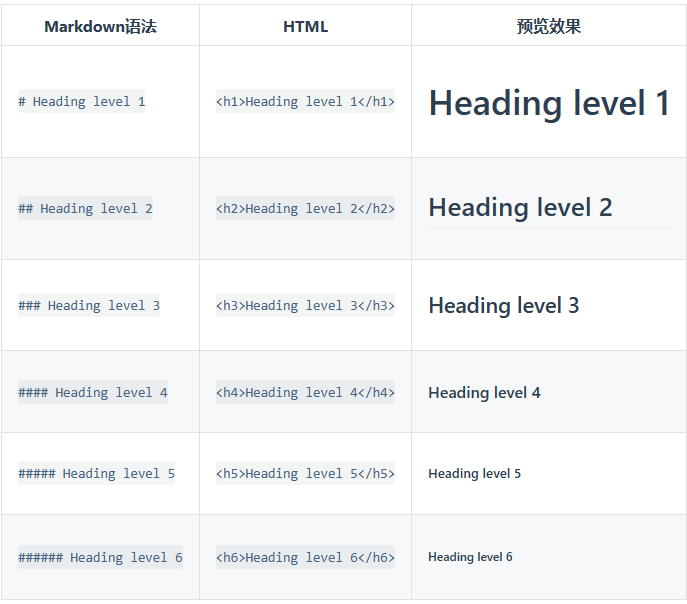
不同的 Markdown 应用程序处理 # 和标题之间的空格方式并不一致。为了兼容考虑,请用一个空格在 # 和标题之间进行分隔。

<2>Markdown段落语法
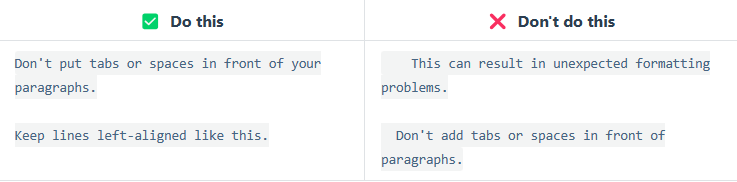
要创建段落,请使用空白行将一行或多行文本进行分隔。
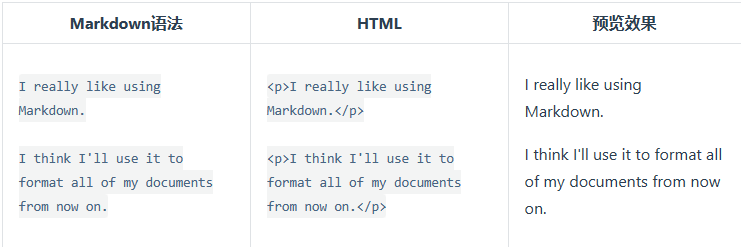
不要用空格(spaces)或制表符( tabs)缩进段落。
<3>Markdown换行语法
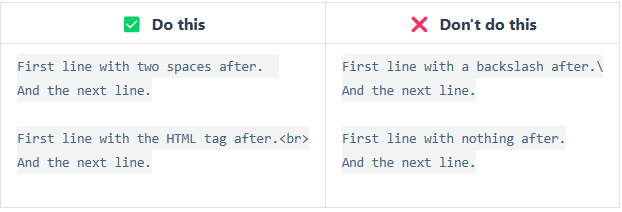
在一行的末尾添加两个或多个空格,然后按回车键,即可创建一个换行(<br>)。

几乎每个 Markdown 应用程序都支持两个或多个空格进行换行,称为 结尾空格(trailing whitespace) 的方式,但这是有争议的,因为很难在编辑器中直接看到空格,并且很多人在每个句子后面都会有意或无意地添加两个空格。由于这个原因,你可能要使用除结尾空格以外的其它方式来换行。幸运的是,几乎每个 Markdown 应用程序都支持另一种换行方式:HTML 的 <br> 标签。
为了兼容性,请在行尾添加“结尾空格”或 HTML 的 <br> 标签来实现换行。
<4>Markdown强调语法
通过将文本设置为粗体或斜体来强调其重要性
1)粗体(Bold)
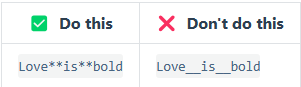
要加粗文本,请在单词或短语的前后各添加两个星号(asterisks)或下划线(underscores)。如需加粗一个单词或短语的中间部分用以表示强调的话,请在要加粗部分的两侧各添加两个星号(asterisks)。

Markdown 应用程序在如何处理单词或短语中间的下划线上并不一致。为兼容考虑,在单词或短语中间部分加粗的话,请使用星号(asterisks)。
2)斜体(Italic)
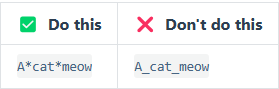
要用斜体显示文本,请在单词或短语前后添加一个星号(asterisk)或下划线(underscore)。要斜体突出单词的中间部分,请在字母前后各添加一个星号,中间不要带空格。

要同时用粗体和斜体突出显示文本,请在单词或短语的前后各添加三个星号或下划线。要加粗并用斜体显示单词或短语的中间部分,请在要突出显示的部分前后各添加三个星号,中间不要带空格。
3)粗体(Bold)和斜体(Italic)
要同时用粗体和斜体突出显示文本,请在单词或短语的前后各添加三个星号或下划线。要加粗并用斜体显示单词或短语的中间部分,请在要突出显示的部分前后各添加三个星号,中间不要带空格。

Markdown 应用程序在处理单词或短语中间添加的下划线上并不一致。为了实现兼容性,请使用星号将单词或短语的中间部分加粗并以斜体显示,以示重要。

<5>Markdown引用语法
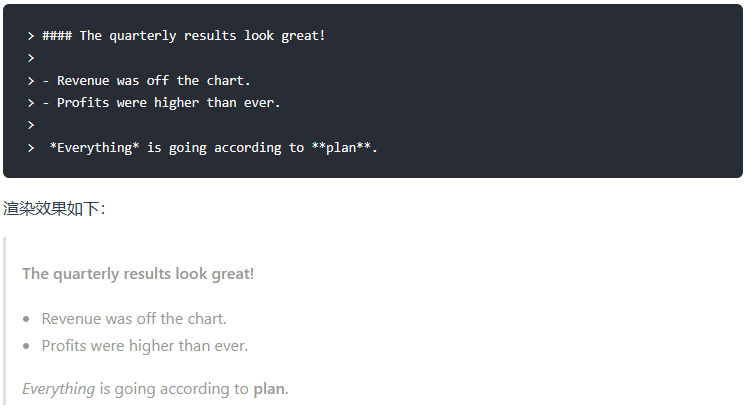
要创建块引用,请在段落前添加一个 > 符号。

1)多个段落的块引用
块引用可以包含多个段落。为段落之间的空白行添加一个 > 符号。

2)嵌套块引用
块引用可以嵌套。在要嵌套的段落前添加一个 >> 符号。

3)带有其它元素的块引用
块引用可以包含其他 Markdown 格式的元素。并非所有元素都可以使用,你需要进行实验以查看哪些元素有效。
<6>Markdown列表语法
可以将多个条目组织成有序或无序列表。
1)有序列表
要创建有序列表,请在每个列表项前添加数字并紧跟一个英文句点。数字不必按数学顺序排列,但是列表应当以数字 1 起始。

CommonMark 和其它几种轻量级标记语言允许使用括号 ( ) 或者半括号 )作为分隔符,例如1) First item)
但并非所有Markdown应用程序都支持这一点,所以从兼容性的角度来看,这不是一个很好的选择。为了兼容性,请仅使用英文句点。

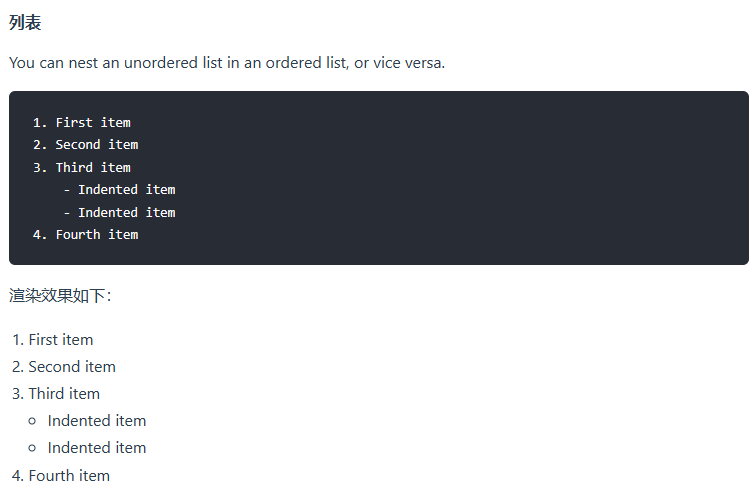
2)无序列表
要创建无序列表,请在每个列表项前面添加破折号 (-)、星号 (*) 或加号 (+) 。缩进一个或多个列表项可创建嵌套列表。

Markdown应用程序在如何处理同一列表中的不同定界符上没有达成一致。为了兼容,不要在同一个列表中混合使用定界符,选择一个并坚持使用它。

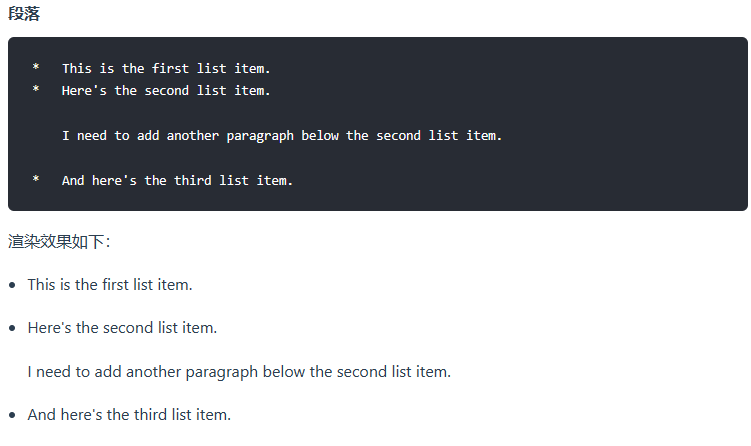
3)在列表中嵌套其他元素
要在保留列表连续性的同时在列表中添加另一种元素,请将该元素缩进四个空格或一个制表符,如下例所示:


<7>Markdown代码语法
要将单词或短语表示为代码,请将其包裹在反引号 (`) 中。

1)转义反引号
如果你要表示为代码的单词或短语中包含一个或多个反引号,则可以通过将单词或短语包裹在双反引号(``)中。

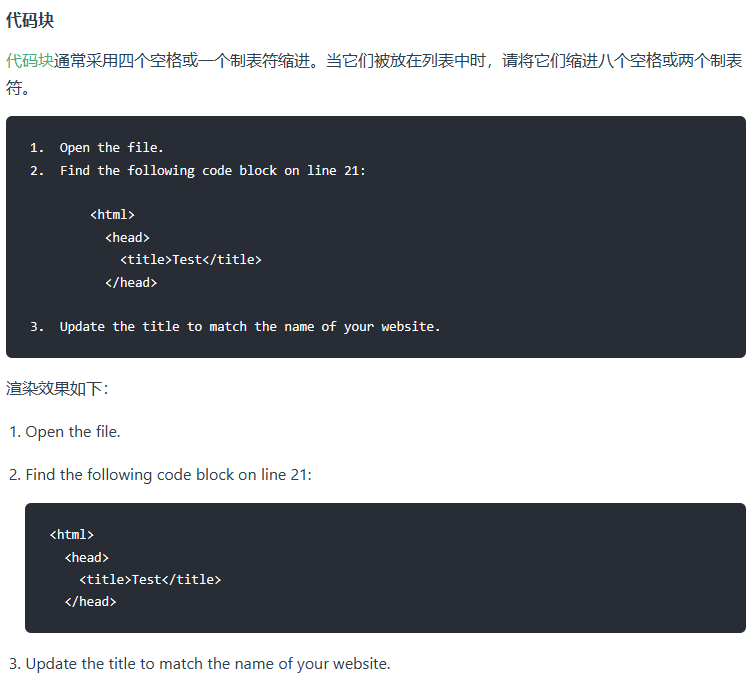
2)代码块
要创建代码块,请将代码块的每一行缩进至少四个空格或一个制表符。

Note: 要创建不用缩进的代码块,请使用 围栏式代码块(fenced code blocks).
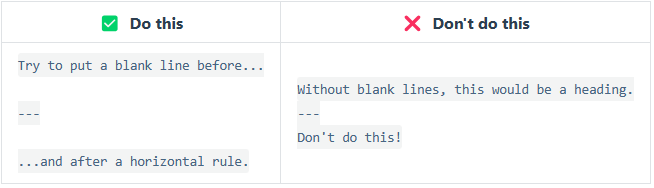
<8>Markdown分割线语法
要创建分隔线,请在单独一行上使用三个或多个星号 (***)、破折号 (---) 或下划线 (___) ,并且不能包含其他内容。

以上三个分隔线的渲染效果看起来都一样:
为了兼容性,请在分隔线的前后均添加空白行。
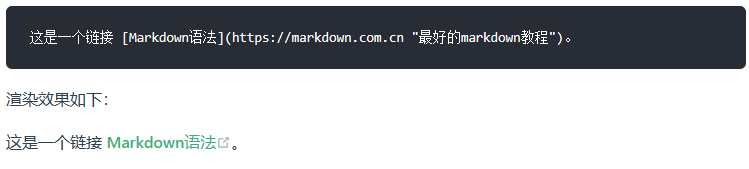
<9>Markdown链接语法
链接文本放在中括号内,链接地址放在后面的括号中,链接title可选。
超链接Markdown语法代码:[超链接显示名](超链接地址 "超链接title")
对应的HTML代码:<a href="超链接地址" title="超链接title">超链接显示名</a>

1)给链接增加 Title
链接title是当鼠标悬停在链接上时会出现的文字,这个title是可选的,它放在圆括号中链接地址后面,跟链接地址之间以空格分隔。
2)网址和Email地址
使用尖括号可以很方便地把URL或者email地址变成可点击的链接。

3)带格式化的链接
强调 链接, 在链接语法前后增加星号。 要将链接表示为代码,请在方括号中添加反引号。

4)引用类型链接
引用样式链接是一种特殊的链接,它使URL在Markdown中更易于显示和阅读。参考样式链接分为两部分:与文本保持内联的部分以及存储在文件中其他位置的部分,以使文本易于阅读。
链接的第一部分格式
引用类型的链接的第一部分使用两组括号进行格式设置。第一组方括号包围应显示为链接的文本。第二组括号显示了一个标签,该标签用于指向您存储在文档其他位置的链接。
尽管不是必需的,可以在第一组和第二组括号之间包含一个空格。第二组括号中的标签不区分大小写,可以包含字母,数字,空格或标点符号。
以下示例格式对于链接的第一部分效果相同:
- [hobbit-hole][1]
- [hobbit-hole] [1]
链接的第二部分格式
引用类型链接的第二部分使用以下属性设置格式:
- 放在括号中的标签,其后紧跟一个冒号和至少一个空格(例如[label]:)。
- 链接的URL,可以选择将其括在尖括号中。
- 链接的可选标题,可以将其括在双引号,单引号或括号中。
以下示例格式对于链接的第二部分效果相同:
- [1]: https://en.wikipedia.org/wiki/Hobbit#Lifestyle
- [1]: https://en.wikipedia.org/wiki/Hobbit#Lifestyle "Hobbit lifestyles"
- [1]: https://en.wikipedia.org/wiki/Hobbit#Lifestyle 'Hobbit lifestyles'
- [1]: https://en.wikipedia.org/wiki/Hobbit#Lifestyle (Hobbit lifestyles)
- [1]: <https://en.wikipedia.org/wiki/Hobbit#Lifestyle> "Hobbit lifestyles"
- [1]: <https://en.wikipedia.org/wiki/Hobbit#Lifestyle> 'Hobbit lifestyles'
- [1]: <https://en.wikipedia.org/wiki/Hobbit#Lifestyle> (Hobbit lifestyles)
可以将链接的第二部分放在Markdown文档中的任何位置。有些人将它们放在出现的段落之后,有些人则将它们放在文档的末尾(例如尾注或脚注)。
不同的 Markdown 应用程序处理URL中间的空格方式不一样。为了兼容性,请尽量使用%20代替空格。

<10>Markdown图片语法
要添加图像,请使用感叹号 (!), 然后在方括号增加替代文本,图片链接放在圆括号里,括号里的链接后可以增加一个可选的图片标题文本。
插入图片Markdown语法代码:。
对应的HTML代码:<img src="图片链接" alt="图片alt" title="图片title">

1)链接图片
给图片增加链接,请将图像的Markdown 括在方括号中,然后将链接添加在圆括号中。

<11>Markdown 转义字符语法
要显示原本用于格式化 Markdown 文档的字符,请在字符前面添加反斜杠字符 \ 。
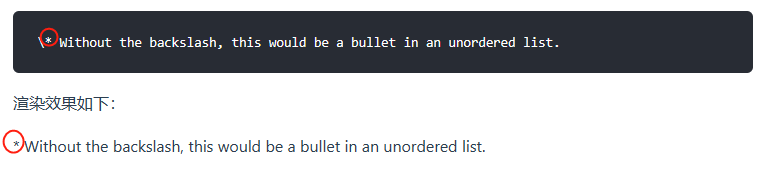
1)可做转义的字符
以下列出的字符都可以通过使用反斜杠字符从而达到转义目的。

2)特殊字符自动转义
在 HTML 文件中,有两个字符需要特殊处理: < 和 & 。 < 符号用于起始标签,& 符号则用于标记 HTML 实体,如果你只是想要使用这些符号,你必须要使用实体的形式,像是 < 和 &。
& 符号其实很容易让写作网页文件的人感到困扰,如果你要打「AT&T」 ,你必须要写成「AT&T」 ,还得转换网址内的 & 符号,如果你要链接到:

你必须要把网址转成:

才能放到链接标签的 href 属性里。不用说也知道这很容易忘记,这也可能是 HTML 标准检查所检查到的错误中,数量最多的。
Markdown 允许你直接使用这些符号,它帮你自动转义字符。如果你使用 & 符号的作为 HTML 实体的一部分,那么它不会被转换,而在其它情况下,它则会被转换成 &。所以你如果要在文件中插入一个著作权的符号,你可以这样写:

Markdown 将不会对这段文字做修改,但是如果你这样写:

Markdown 就会将它转为:

类似的状况也会发生在 < 符号上,因为 Markdown 支持 行内 HTML ,如果你使用 < 符号作为 HTML 标签的分隔符,那 Markdown 也不会对它做任何转换,但是如果你是写:

Markdown 将会把它转换为:

需要特别注意的是,在 Markdown 的块级元素和内联元素中, < 和 & 两个符号都会被自动转换成 HTML 实体,这项特性让你可以很容易地用 Markdown 写 HTML。(在 HTML 语法中,你要手动把所有的 < 和 & 都转换为 HTML 实体。)
<12>Markdown 内嵌 HTML 标签
对于 Markdown 涵盖范围之外的标签,都可以直接在文件里面用 HTML 本身。如需使用 HTML,不需要额外标注这是 HTML 或是 Markdown,只需 HTML 标签添加到 Markdown 文本中即可
1)行级內联标签
HTML 的行级內联标签如 <span>、<cite>、<del> 不受限制,可以在 Markdown 的段落、列表或是标题里任意使用。依照个人习惯,甚至可以不用 Markdown 格式,而采用 HTML 标签来格式化。例如:如果比较喜欢 HTML 的 <a> 或 <img> 标签,可以直接使用这些标签,而不用 Markdown 提供的链接或是图片语法。当你需要更改元素的属性时(例如为文本指定颜色或更改图像的宽度),使用 HTML 标签更方便些。
HTML 行级內联标签和区块标签不同,在內联标签的范围内, Markdown 的语法是可以解析的。

渲染效果如下:
This word is bold. This word is italic.
2)区块标签
区块元素──比如 <div>、<table>、<pre>、<p> 等标签,必须在前后加上空行,以便于内容区分。而且这些元素的开始与结尾标签,不可以用 tab 或是空白来缩进。Markdown 会自动识别这区块元素,避免在区块标签前后加上没有必要的 <p> 标签。
例如,在 Markdown 文件里加上一段 HTML 表格:
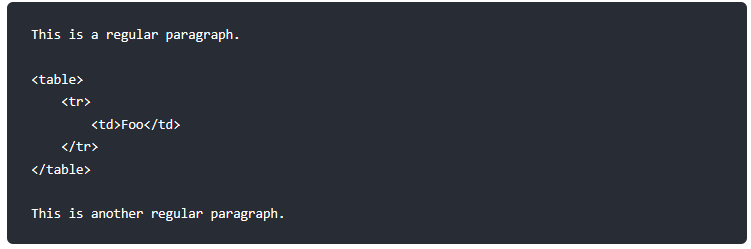
请注意,Markdown 语法在 HTML 区块标签中将不会被进行处理。例如,你无法在 HTML 区块内使用 Markdown 形式的*强调*。

以上个人开发使用的脚本方法未经本人允许,不得搬运,谢谢!!!