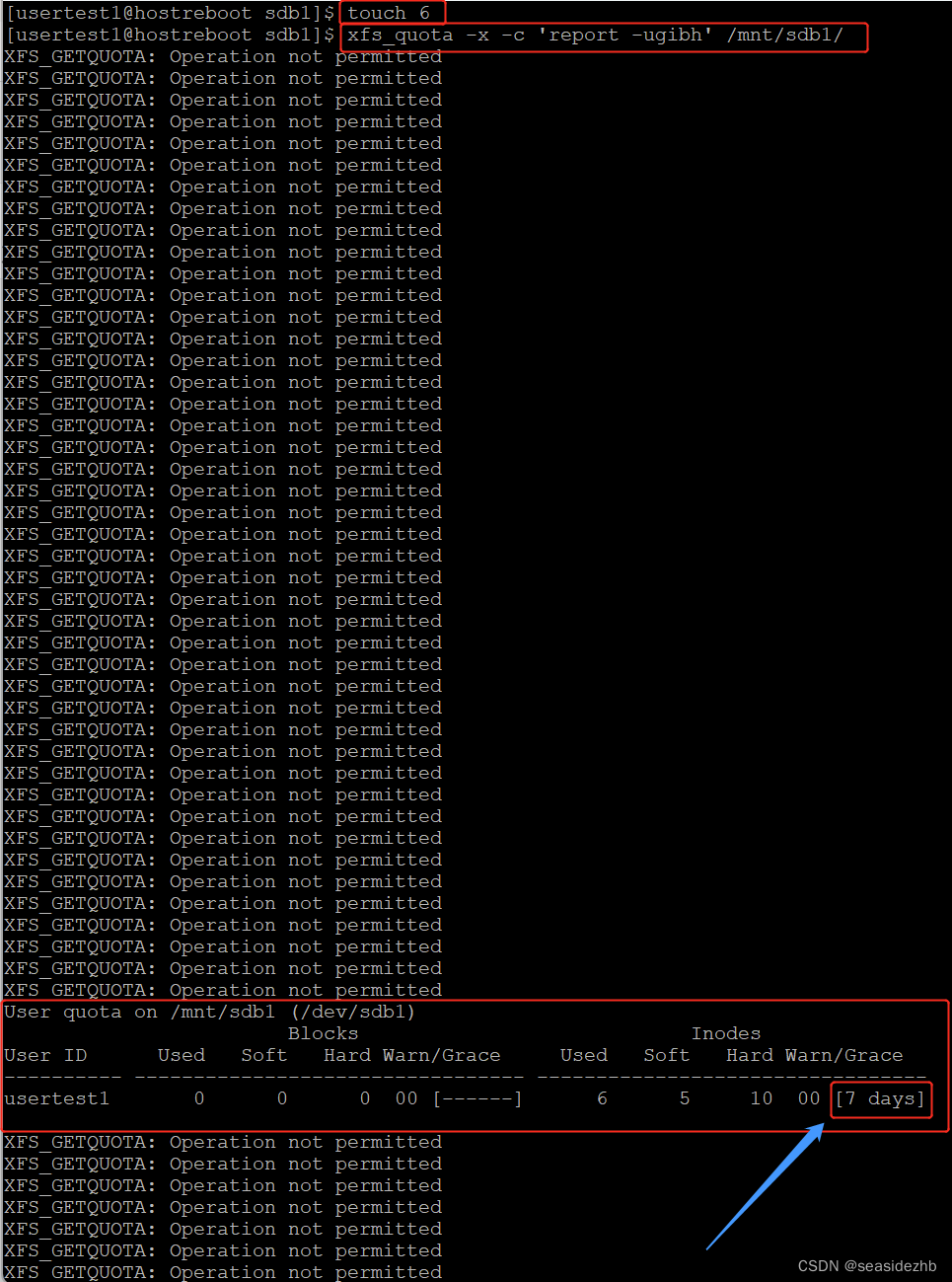
缓冲区溢出是指当数据写入某个缓冲区(buffer)时,超出了为该缓冲区分配的内存空间,从而导致覆盖了相邻内存区域的情况。这种现象可能导致程序崩溃、数据损坏,甚至引发安全漏洞,允许攻击者利用这一漏洞执行恶意代码。
typedef struct {
int a[2];
double d;
} struct_t;
double fun(int i) {
volatile struct_t s;
s.d = 3.14;
s.a[i] = 1073741824; /* Possibly out of bounds */
return s.d;
}比如这个代码中,在内存中,a中的元素和d其实是挨着的,如果给a赋值了超过了它当前容量的数据,那么就会覆盖d的内容,导致d的值混乱。
栈破坏攻击(Stack Smashing Attacks)
在上篇文章我们知道当函数调用另一个函数时,会为其分配一个栈帧,并且这个栈帧的上面就是返回地址,那么如果我们在被调用的函数中超量使用了给它分配的内存,就会有可能覆盖那个返回地址,从而引发错误。

比如这个例子中,被调用的函数使用gets()方法接受用户输入,然由于这个gets方法的不安全性(它不对用户输入内容的长度做限制),所以只要我们输入一大长串,我们的输入就会从底部一直往上填补,直到我们覆盖了绿色方块部分也就是函数返回地址,我们就把程序搞崩溃了。在栈破坏攻击中,攻击者覆盖的返回地址通常属于上一个函数的栈帧。系统帮我们把函数返回值放在了上一个栈帧的最底部,并且在新的栈帧中留了很大一部分空间,但只要输入够多,总会把上面的内容覆盖。
上面的例子就叫做栈破坏攻击(Stack Smashing Attacks)。大概原理就是攻击者首先需要找到一个目标程序中存在缓冲区溢出漏洞的函数。通常,这些函数会接收外部输入,且未对输入长度进行适当的检查。攻击者构造一段恶意输入数据,使其在被处理时会导致栈上的缓冲区溢出。我们甚至可以直接把函数返回值直接覆盖成别的函数地址,从而改变程序的执行顺序。
代码注入攻击(Code Injection Attacks)
代码注入攻击和上面的攻击很像,就是多加了一步,你不是可以修改函数返回地址吗? 那我们干脆直接跳转到我们写的函数上去!我们把自己写的代码(转换成可执行的字节表示后)放进空闲区,并且知道它的地址,直接把覆盖地址写成这个地址就好了。
这种情况下,自己写的代码叫做exploit code,当函数返回时(因为返回地址B处被修改了),代码就会跳到exploit code那继续执行。

避免buffer overflow的保护措施
1.提高代码的健壮性,使用限制字符串长度的库函数。例如:
- 使用
fgets代替gets。fgets允许您指定读取的最大字符数,从而避免缓冲区溢出。 - 使用
strncpy代替strcpy。strncpy允许您指定复制的最大字符数,防止目标缓冲区溢出。 - 避免使用
scanf函数的%s格式说明符。因为%s不会限制读取的字符串长度,容易导致缓冲区溢出。可以使用fgets读取字符串,代替使用scanf。或者在scanf中使用%ns格式说明符,其中n是一个合适的整数,用于限制读取的字符数
/* Echo Line */
void echo() {
char buf[4];
fgets(buf, 4, stdin); // 使用fgets以限制读取的字符数
puts(buf);
}2. 使用系统级别的保护 System-Level Protections
2.1随机化栈偏移(Randomized Stack Offsets)
也称为地址空间布局随机化(ASLR, Address Space Layout Randomization)。在程序启动时,为栈分配随机大小的空间,从而改变整个程序的栈地址。这使得攻击者难以预测插入代码的起始地址。随着程序的多次执行,栈的位置会不断改变,就算把代码注入进去了,也不知道它的地址是在哪里。提高了攻击难度。

2.2 不可执行内存(Non-Executable Memory)
对于较旧的x86 CPU,它们会从任何可读地址执行机器代码。x86-64 架构引入了一种标记内存区域为不可执行的方法。如果程序尝试跳转到这些区域执行代码(也就是上面图中的B区域,假如它是不可执行的话),将立即导致崩溃。现代操作系统(如 Linux 和 Windows)会将栈标记为不可执行内存,从而增加攻击的难度。这个时候即使我们把代码注入进内存,也无法是执行的。
2.3 Stack Canaries
我也不知道这个canaries要翻译成啥哈哈,"canary"就是在缓冲区之后的栈上放置一个特殊值,在函数退出之前,检查该特殊值是否被破坏。如果被破坏了就说明我们遇到了buffer overflow。

这个canaries的值是系统内部随机的,攻击者也很难知道是啥。GCC编译器提供了一个选项-fstack-protector,用于启用栈保护。
unix>./bufdemo-sp
Type a string:0123456
0123456
unix>./bufdemo-sp
Type a string:012345678
*** stack smashing detected ***检测到了溢出就直接报错,用的就是这个canaries。
面向返回的编程攻击(Return-Oriented Programming Attacks, ROP攻击)
虽然我们有上面那些应对办法,但依然无法处理ROP攻击。ROP的攻击思想是直接使用现有代码,这些代码可以是程序本身的一部分,也可以是C库中的代码。这些代码必然在可执行的内存区域,所以不存在什么内存保护的说法。
攻击者在ROP攻击中利用了程序中已经存在的代码片段,这些片段被称为“gadgets”。他们仔细选择这些片段,使得这些片段的执行顺序能够实现攻击者的目的。这种攻击方法的关键在于利用程序中的现有代码,而不是像传统的缓冲区溢出攻击那样插入新的恶意代码。
尽管ROP攻击可以绕过栈随机化和非可执行内存的保护(绕过随机化是因为它不需要寻找注入的代码的地址,只需要去找现有的代码的地址;绕过内存保护也是类似道理,它不需要在stack中注入代码来执行,而是直接去找现有的可执行代码),但它不能克服栈保护(Stack Canaries),因为攻击者依然需要覆盖栈上的返回地址。
使用现有的代码,如何能达到攻击的目的呢?顶多就是把某些语句多执行几遍呗?并不是,对于machine code中的字节表示形式下的代码,攻击者可以从中进行截取,就可以可以做到“无中生有”。比如:

这里,原句最多就是一个赋值操作,但是如果我们截取从48后开始,那么就是另一个指令movq %rax, %rdi了。做到从48开始也很简单,原地址4004d9+3字节就来到了4004dc。就是通过这种拼凑的方式,可以得到攻击者想要的指令。
最后附一张常用指令对应的机器码,如果一个程序中包含了某一块,就可以被利用攻击。

这篇写了几个基于buffer overflow的攻击和保护措施,想更清楚理解可以去做attack lab,会有更清晰的认识~