目标:
微信公众号是现代社交媒体中最受欢迎的平台之一,每天都有数以百万计的人在浏览不同的公众号,其中大部分都包含了图片内容。如果你是一位公众号的管理员或者粉丝,你可能想要在本地保存一些感兴趣的图片。但是,微信公众号并不提供直接下载图片的功能,那么该怎么办呢?一种简单的解决方案是通过Python编写一个爬虫程序来实现图片的下载。

学习内容:
首先打开你感兴趣的文章,并将文章的URL复制到剪切板中。
具体步骤如下👇👇👇:
Step1:电脑登入微信,打开一篇文章
Step2:用浏览器打开
Step3:搜索栏的网址就是URL,需要记录下来
https://mp.weixin.qq.com/s/khgmRGBbbZMbsgeZlKRPDA
接下来,你需要安装Python的第三方库——BeautifulSoup和Requests,这两个库可以帮助我们解析HTML页面和发送HTTP请求。下面是爬虫程序的核心代码:
import requests
from bs4 import BeautifulSoup
import re
import os
#获取网页信息
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
#解析网页,获取所有图片url
def getimgURL(html):
soup = BeautifulSoup(html , "html.parser")
adlist=[]
for i in soup.find_all("img"):
try:
ad= re.findall(r'.*src="(.*?)?" .*',str(i))
if ad :
adlist.append(ad)
except:
continue
return adlist
#新建文件夹pic,下载并保存爬取的图片信息
def download(adlist):
#注意更改文件目录
root="D:\\公众号爬取\\"
for i in range(len(adlist)):
path=root+str(i)+"."+'gif'
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r=requests.get(adlist[i][0])
with open(path,'wb') as f:
f.write(r.content)
f.close()
def main():
url = 'https://www.gangqinjianpu.com/1690.html'
html=getHTMLText(url)
list=getimgURL(html)
download(list)
main()以上的代码首先通过Requests库发送HTTP请求获取HTML页面,然后通过BeautifulSoup库解析HTML页面,提取文章中的图片链接。接着,创建一个保存图片的文件夹,在循环中使用Requests库下载每张图片,并保存到本地磁盘。
运行这段代码时,它会自动下载文章中的所有图片,并保存到指定的文件夹中。如果你想要下载其他文章的图片,只需要将main函数的url替换为目标文章的url即可。爬取结果如下:
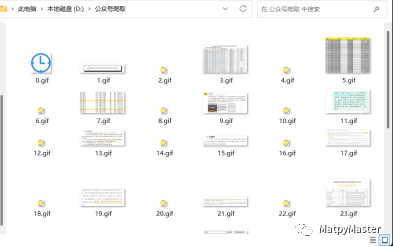
这篇文章介绍了如何利用Python编写一个简单的爬虫程序来爬取微信公众号文章中的图片。通过这个例程,你可以学习如何使用Requests和BeautifulSoup库来解析HTML页面和发送HTTP请求。
最后:
如果你想要进一步了解Python爬虫的相关知识,可以关注下面公众号联系~会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!