关于 "Java的对象创建" 这个话题分布在各种论坛、各种帖子,文章的水平参差不齐。并且大部分仅仅是总结 "面试宝典" 的流程,小部分就是copy其他帖子,极少能看到拿源码作为论证。所以特意写下这篇文章。
版本信息如下:
jdk版本:jdk8u40
为了源码的简单,使用字节码解释器:C++解释器
为了源码的简单,垃圾回收器使用serial new/old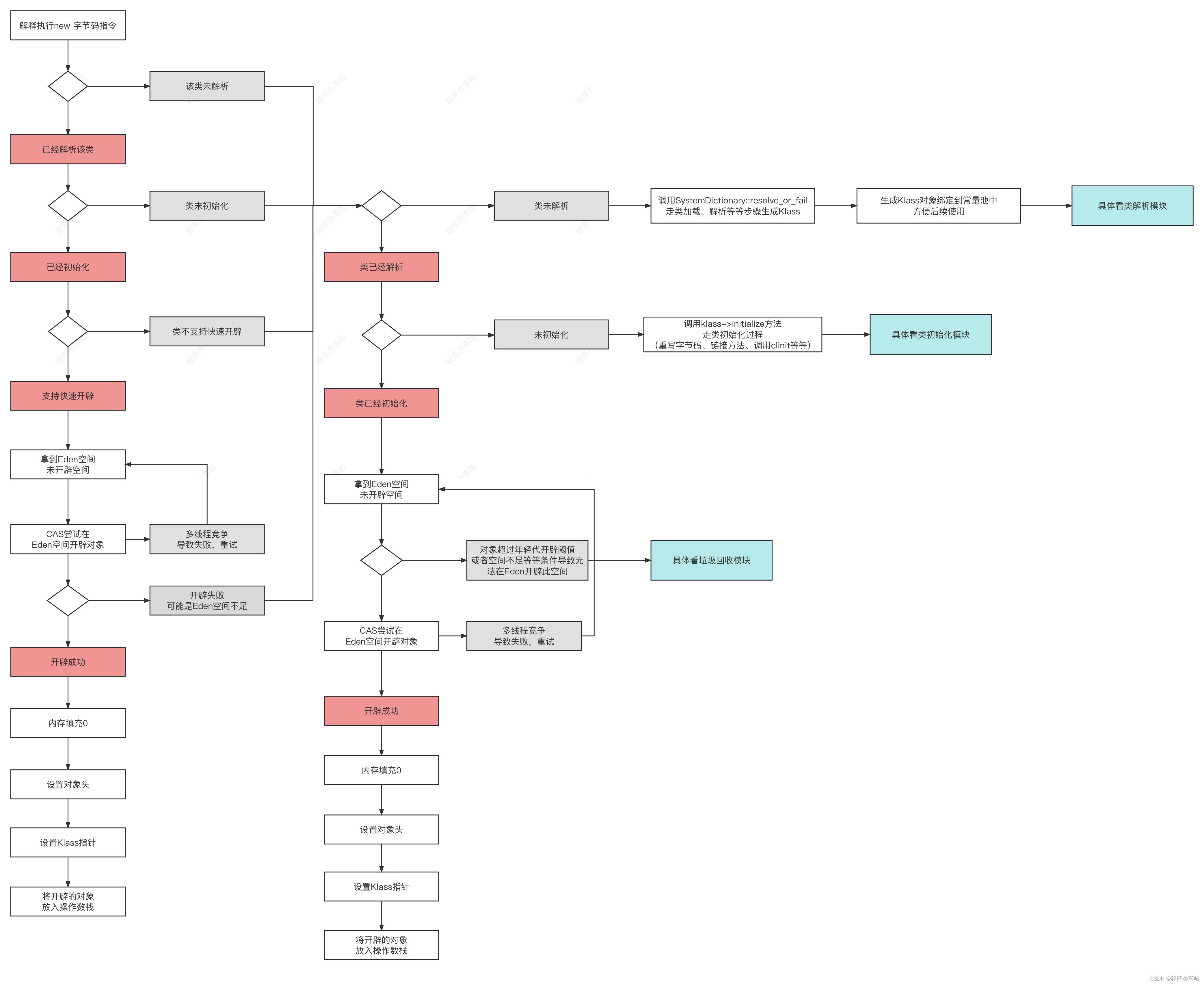 首先把总结图放在这。接下来分析源码~
首先把总结图放在这。接下来分析源码~
用一个非常简单的案例来打开新世界的大门。
public class demo{
public static void main(String[] args) {
new A();
}
}
class A{
static{
System.out.println("123");
}
}通过javac命令编译后的字节码如下:
Constant pool:
#1 = Methodref #5.#14 // java/lang/Object."<init>":()V
#2 = Class #15 // A
#3 = Methodref #2.#14 // A."<init>":()V
#4 = Class #16 // demo
#5 = Class #17 // java/lang/Object
#6 = Utf8 <init>
#7 = Utf8 ()V
#8 = Utf8 Code
#9 = Utf8 LineNumberTable
#10 = Utf8 main
#11 = Utf8 ([Ljava/lang/String;)V
#12 = Utf8 SourceFile
#13 = Utf8 demo.java
#14 = NameAndType #6:#7 // "<init>":()V
#15 = Utf8 A
#16 = Utf8 demo
#17 = Utf8 java/lang/Object
{
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=1, args_size=1
0: new #2 // class A
3: dup
4: invokespecial #3 // Method A."<init>":()V
7: pop
8: return
LineNumberTable:
line 4: 0
line 5: 8
}可以清楚的看到,main方法中就简简单单的几条字节码指令,而在Hotspot中执行器分为解释器和JIT,所以为了分析的简单,我们使用c++解释器。src/share/vm/interpreter/bytecodeInterpreter.cpp 文件中的run方法。
CASE(_new): {
// 拿到new指令携带的指向常量池的下标
u2 index = Bytes::get_Java_u2(pc+1);
ConstantPool* constants = istate->method()->constants();
// 判断当前类是否已经解析
if (!constants->tag_at(index).is_unresolved_klass()) {
Klass* entry = constants->slot_at(index).get_klass();
Klass* k_entry = (Klass*) entry;
InstanceKlass* ik = (InstanceKlass*) k_entry;
// 判断当前类是否已经初始化完毕,并且是否支持快速开辟
if ( ik->is_initialized() && ik->can_be_fastpath_allocated() ) {
// 因为类是对象的模板,所以类就已经决定对象的大小和变量的排布。
size_t obj_size = ik->size_helper();
oop result = NULL;
if (result == NULL) {
need_zero = true;
retry:
/*
这里很简单,由于类是对象的模板,所以开辟对象的大小都已经是确定值。
在Java堆初始化就已经使用mmap系统调用开辟了一大段空间,并且根据垃圾回收器和垃圾回收策略决定好空间的分布
所以当前只需要从开辟好的空间中得到当前对象所需的空间的大小作为当前对象的内存。
并发的情况下就使用cmpxchg_ptr保证Java堆内存的原子性。
而c/c++很妙的地方在于可以直接操作内存,可以动态对内存的解释做改变(改变指针类型)
所以得到一小段空间并返回基地址(对象的起始地址),而这片空间直接使用oop来解释。
如果:后续给对象中某个属性赋值,这将是一个很简单的寻址问题,已知基地址 + 对象头的常数偏移量 + 偏移量(类中保存了对象排布)= 属性的地址
*/
HeapWord* compare_to = *Universe::heap()->top_addr();
HeapWord* new_top = compare_to + obj_size;
if (new_top <= *Universe::heap()->end_addr()) {
// cas确保Java堆空间的原子性,并发的情况下失败了就重试。
if (Atomic::cmpxchg_ptr(new_top, Universe::heap()->top_addr(), compare_to) != compare_to) {
goto retry;
}
result = (oop) compare_to;
}
}
// 对象开辟成功,需要对其初始化,设置对象头
if (result != NULL) {
if (need_zero ) {
HeapWord* to_zero = (HeapWord*) result + sizeof(oopDesc) / oopSize;
obj_size -= sizeof(oopDesc) / oopSize;
if (obj_size > 0 ) {
memset(to_zero, 0, obj_size * HeapWordSize);
}
}
// 如果使用偏向锁的话,对象头的内容需要修改。
if (UseBiasedLocking) {
result->set_mark(ik->prototype_header());
} else {
result->set_mark(markOopDesc::prototype());
}
result->set_klass_gap(0);
// 对象头部存在klass的指针。
result->set_klass(k_entry);
// 发布,让其他线程可见
OrderAccess::storestore();
// 把对象地址放入到0号操作数栈中。
SET_STACK_OBJECT(result, 0);
UPDATE_PC_AND_TOS_AND_CONTINUE(3, 1);
}
}
}
// 上面仅仅是优化开辟,如果优化开辟的条件不通过,此时走漫长的开辟过程
CALL_VM(InterpreterRuntime::_new(THREAD, METHOD->constants(), index),
handle_exception);
// 发布,让其他线程可见
OrderAccess::storestore();
// 把对象地址放入到0号操作数栈中。
SET_STACK_OBJECT(THREAD->vm_result(), 0);
THREAD->set_vm_result(NULL);
UPDATE_PC_AND_TOS_AND_CONTINUE(3, 1);
}这里是对new字节码指令的解释,过程比较复杂,代码中已经附上了详细的注释了。这里也对其做一个简单的总结:
- 取到new字节码指令携带的常量,用于指向常量池,拿到类信息。
- 如果已经解析,如果已经初始化,如果支持快速开辟对象,此时会拿到Java堆中Eden空间中未开辟的空间,然后CAS尝试开辟对象空间(因为Java堆空间是共享的,所以存在多线程的竞争问题,所以使用CAS保证开辟对象空间的原子性)。开辟成功后,将内存初始化为0,设置对象头,设置Klass指针,然后保存到操作数栈中。
- 如果不满足已经解析、已经初始化、快速开辟对象,此时就会走InterpreterRuntime::_new方法走慢开辟逻辑,也是我们下面需要分析的代码。
- 当InterpreterRuntime::_new方法开辟好对象后,会放入到操作数栈,然后执行完毕。
IRT_ENTRY(void, InterpreterRuntime::_new(JavaThread* thread, ConstantPool* pool, int index))
// 确保类已经加载并且解析
// 如果没有加载和解析,那么就去加载和解析类,得到最终的Klass对象
Klass* k_oop = pool->klass_at(index, CHECK);
instanceKlassHandle klass (THREAD, k_oop);
// 确保不是实例化的一个抽象类
klass->check_valid_for_instantiation(true, CHECK);
// 确保类已经完成初始化工作
klass->initialize(CHECK);
// 在Java堆内存中开辟对象
oop obj = klass->allocate_instance(CHECK);
// 使用线程变量完成 值的传递
thread->set_vm_result(obj);
IRT_END在Hotspot中使用二分模型Klass / oop 来表示类和对象,而类是对象的模板。在上文的案例中,在main方法中 new A对象,所以需要确保类A已经被加载、解析完毕,生成好对应的Klass。而生成好Klass类对象后,需要对类做初始化过程,也即链接类中所有的方法和调用父类以及本身的<clinit>方法(也即A类的static块)。本文重点赘述对象的创建过程,类的创建过程详细请参考:JVM规范手册第4章、第5章内容 以及Hotspot虚拟机的实现。
当类加载、解析、初始化完毕后,会调用klass->allocate_instance 方法尝试在Java堆内存中开辟对象。
instanceOop InstanceKlass::allocate_instance(TRAPS) {
// 因为类是对象的模板,所以可以从类中得到一个对象的大小
int size = size_helper();
KlassHandle h_k(THREAD, this);
instanceOop i;
// 尝试在Java堆中开辟对象
i = (instanceOop)CollectedHeap::obj_allocate(h_k, size, CHECK_NULL);
return i;
}
oop CollectedHeap::obj_allocate(KlassHandle klass, int size, TRAPS) {
// 尝试在Java堆中开辟对象
HeapWord* obj = common_mem_allocate_init(klass, size, CHECK_NULL);
// 开辟好Java对象后,做初始化工作,比如:设置对象头、设置Klass指针。
post_allocation_setup_obj(klass, obj, size);
return (oop)obj;
}
HeapWord* CollectedHeap::common_mem_allocate_init(KlassHandle klass, size_t size, TRAPS) {
// 尝试在Java堆中开辟对象
HeapWord* obj = common_mem_allocate_noinit(klass, size, CHECK_NULL);
// 内存清零
init_obj(obj, size);
return obj;
}
HeapWord* CollectedHeap::common_mem_allocate_noinit(KlassHandle klass, size_t size, TRAPS) {
HeapWord* result = NULL;
bool gc_overhead_limit_was_exceeded = false;
result = Universe::heap()->mem_allocate(size,
&gc_overhead_limit_was_exceeded);
return result;
…………
省略JVMTI的模块处理
}
HeapWord* GenCollectedHeap::mem_allocate(size_t size,
bool* gc_overhead_limit_was_exceeded) {
return collector_policy()->mem_allocate_work(size,
false /* is_tlab */,
gc_overhead_limit_was_exceeded);
}
HeapWord* GenCollectorPolicy::mem_allocate_work(size_t size,
bool is_tlab,
bool* gc_overhead_limit_was_exceeded) {
GenCollectedHeap *gch = GenCollectedHeap::heap();
HeapWord* result = NULL;
// 循环创建对象,因为可能一次创建不成功。
for (int try_count = 1, gclocker_stalled_count = 0; /* return or throw */; try_count += 1) {
HandleMark hm; // discard any handles allocated in each iteration
// First allocation attempt is lock-free.
Generation *gen0 = gch->get_gen(0);
// 是否能够直接在gen0代(年轻代)开辟对象。
// 需要满足条件:
// 1、如果创建的对象大于年轻代的大小阈值,会直接去其他代创建
// 2、如果eden空间不足够开辟当前对象的话会去其他代创建
if (gen0->should_allocate(size, is_tlab)) {
// 尝试在eden开辟对象
// 如果因为eden空间不够了,会尝试去其他代创建此对象
result = gen0->par_allocate(size, is_tlab);
if (result != NULL) {
assert(gch->is_in_reserved(result), "result not in heap");
return result;
}
}
/* 代表在年轻代开辟对象失败了,后续要根据策略选择其他代开辟此对象,必要时发生GC */
unsigned int gc_count_before; // read inside the Heap_lock locked region
{
MutexLocker ml(Heap_lock);
// 是否需要在其他代开辟此对象(大对象直接在老年代开辟(防止在年轻代一直复制浪费性能))
bool first_only = ! should_try_older_generation_allocation(size);
/*
得出2点
1、如果创建的对象大于年轻代的大小阈值,会直接去其他代创建
2、如果eden空间不足够开辟当前对象的话会去其他代创建
*/
// 尝试在其他代开辟对象。
result = gch->attempt_allocation(size, is_tlab, first_only);
if (result != NULL) {
return result;
}
// 记录一下发生GC前的次数
gc_count_before = Universe::heap()->total_collections();
}
// 因为在年轻代和老年代创建对象都失败了,所以需要GC回收一下内存了。
// 然后再尝试去开辟对象。
VM_GenCollectForAllocation op(size, is_tlab, gc_count_before);
VMThread::execute(&op);
}
}调用栈比较深,最终会在Java堆中创建对象,正常情况下满足:对象在年轻代的Eden空间创建,如果对象大于年轻代的创建大小阈值(因为年轻代使用复制算法,太大的对象一直拷贝影响性能),如果Eden的空间不足够创建此对象,此时就会去老年代创建此对象,如果老年代也开辟不了对象,此时就会发生GC,发生GC后再去尝试开辟对象。
由于调用栈特别深,考虑到篇幅,所以这里直接给出Eden创建对象的代码。src/share/vm/memory/space.cpp 文件中 par_allocate_impl方法
inline HeapWord* ContiguousSpace::par_allocate_impl(size_t size,
HeapWord* const end_value) {
do {
HeapWord* obj = top();
// 是否还有空间容纳当前对象,如果没有空间了就直接返回null,交给其他代去创建。
if (pointer_delta(end_value, obj) >= size) {
HeapWord* new_top = obj + size;
// 因为存在并发,所以使用平台原子性指令
HeapWord* result = (HeapWord*)Atomic::cmpxchg_ptr(new_top, top_addr(), obj);
// 根据CAS的规范,只有result == obj才代表成功
// 其他情况下,就是发生并发,导致CAS失败,所以进入下一轮循环。
if (result == obj) {
assert(is_aligned(obj) && is_aligned(new_top), "checking alignment");
return obj;
}
} else {
return NULL;
}
} while (true);
}代码非常的简单,是不是跟解释器解释执行new字节码指令的快速创建对象的逻辑一摸一样呢?
到这,已经分析完 new 字节码指令,但是从上文的案例对应的字节码来说,是不是还有dup和invokespecial指令。
这两个指令就非常的简单了,我们知道new 指令会把对象放在操作数栈中,dup指令就是复制一份放在操作数栈中,此时操作数栈就存在2份创建的对象了。而invokespecial指令会消耗操作数栈中一份对象,并且执行对象的<init>方法,也即大家口中的构造方法。此时就完成了整个对象的创建