框架介绍
scrapy中文文档
scrapy是用python实现的一个框架,用于爬取网站数据,使用了twisted异步网络框架,可以加快下载的速度。
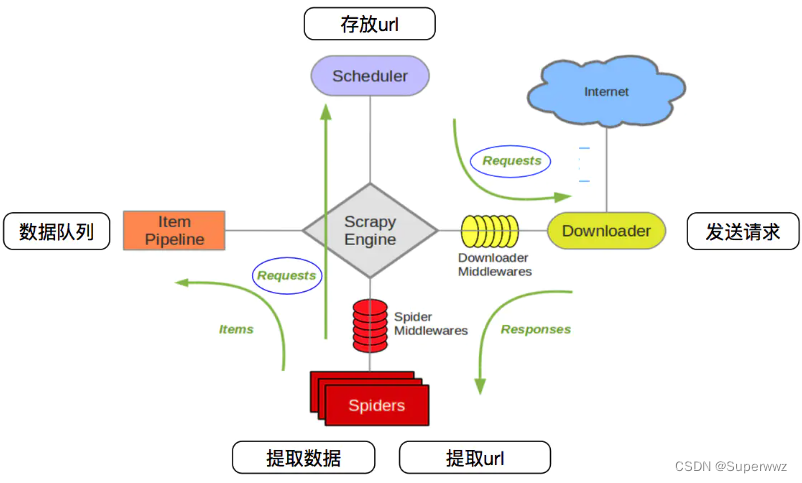
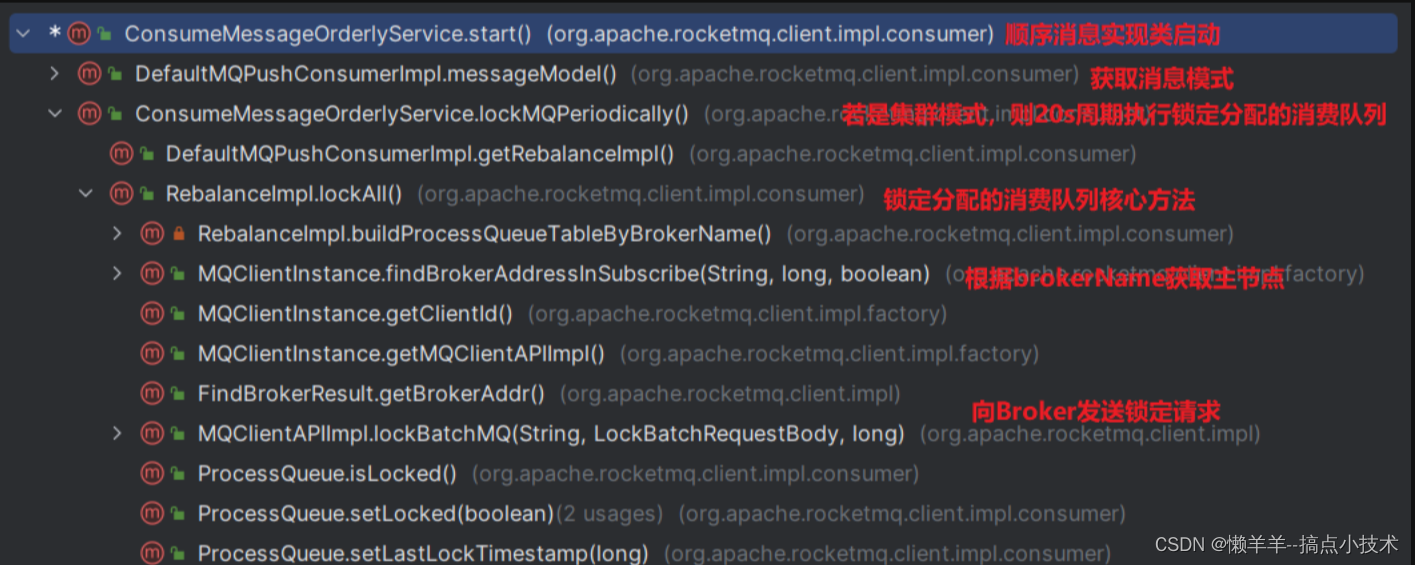
scrapy的架构图,可以看到主要包括scheduler、Downloader、Spiders、pipline、Scrapy
Engine和中间件。各个部分的功能如下:
- Schduler:调度器,负责接受引擎发送过来的request,并按照一定的方式进行整理排列、入队,当引擎需要时,交还给引擎
- Downloader:下载器,下载请求,将获取到的response交还给scrapy engine,由scrapy engine交给spider来处理。建立在twisted上,异步实现
- Spider:爬虫,解析response,提取需要的数据,并将需要跟进的url交还给引擎,再次进入Scheduler
- pipeline:管道,对spider解析的数据进行后处理,包括过滤、存储等
- Scrapy Engine:中间的通讯、信号、数据传递
- 各个中间件:自定义需求的
scrapy的运行流程如下,以关键词搜索爬取处理为例:
- 自定义关键词,在schduler中形成指定的url队列
- scrapy engine从调度器中取出一个url,并将其封装成request传给downloader
- downloader下载资源,封装成response
- spider解析response,并将解析出的信息交给pipeline,解析出的url交给scheduler
项目结构

其中,需要自己写的就是search.py、pipelines.py、items.py这几个文件
- search.py:这个是爬取代码,可以根据自己的需求自定义,这里使用的是关键词搜索爬取,所以取名search。里面需要实现的是一个自定义类,该类继承自scrapy.Spider,在类里需要,定义name,一般与文件同名;urls列表;自定义parse函数,用来实现对response的信息解析。
- pipelines.py:用来保存数据,可以根据需求自定义对爬取数据的保存方式,一般分为文件保存和sql保存,每种保存方式都会指定的书写格式,并传入指定的参数。同时,需要在setting中定义对应的管道调用指令
- items.py:使用scrapy.Field定义存储爬取内容的容器
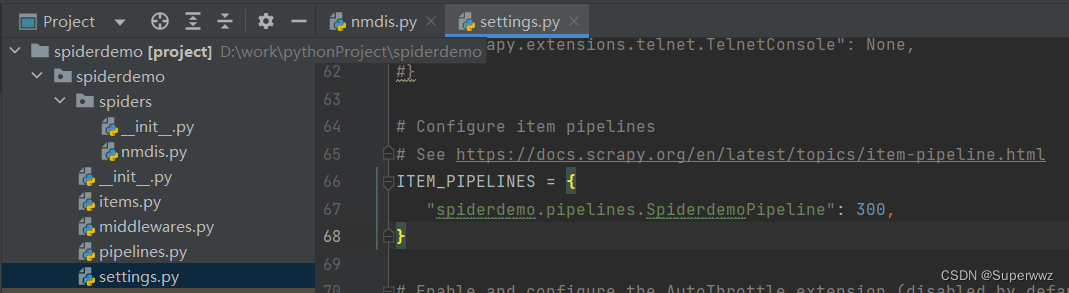
其中,后面的数字表示执行的顺序,数字越小 执行优先级越高
执行命令
scrapy crawl xxx # xxx为创建的项目名
scrapy crawl xxx --nolog # 不打印日志运行
scrapy crawl nmdis -o nmdis.csv # 输出到csv文件