论文学习:AFPN: Asymptotic Feature Pyramid Network for Object Detection-全新特征融合模块AFPN,完胜PAFPN_athrunsunny的博客-CSDN博客
论文的作者是说在yolo上效果有提升,不过还没有测试,具体还不清楚,把代码撸出来先。yolov7的代码结构类似,可以参照tiny的yaml进行修改
先上配置文件yolov7-tiny-AFPN.yaml(hight-level做两次)
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
activation: nn.LeakyReLU(0.1)
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov7-tiny backbone
backbone:
# [from, number, module, args] c2, k=1, s=1, p=None, g=1, act=True
[[-1, 1, Conv, [32, 3, 2, None, 1]], # 0-P1/2
[-1, 1, Conv, [64, 3, 2, None, 1]], # 1-P2/4
[-1, 1, Conv, [32, 1, 1, None, 1]],
[-2, 1, Conv, [32, 1, 1, None, 1]],
[-1, 1, Conv, [32, 3, 1, None, 1]],
[-1, 1, Conv, [32, 3, 1, None, 1]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1]], # 7
[-1, 1, MP, []], # 8-P3/8
[-1, 1, Conv, [64, 1, 1, None, 1]],
[-2, 1, Conv, [64, 1, 1, None, 1]],
[-1, 1, Conv, [64, 3, 1, None, 1]],
[-1, 1, Conv, [64, 3, 1, None, 1]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1]], # 14
[-1, 1, MP, []], # 15-P4/16
[-1, 1, Conv, [128, 1, 1, None, 1]],
[-2, 1, Conv, [128, 1, 1, None, 1]],
[-1, 1, Conv, [128, 3, 1, None, 1]],
[-1, 1, Conv, [128, 3, 1, None, 1]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1]], # 21
[-1, 1, MP, []], # 22-P5/32
[-1, 1, Conv, [256, 1, 1, None, 1]],
[-2, 1, Conv, [256, 1, 1, None, 1]],
[-1, 1, Conv, [256, 3, 1, None, 1]],
[-1, 1, Conv, [256, 3, 1, None, 1]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1, None, 1]], # 28
]
# yolov7-tiny head
head:
[[14, 1, Conv, [64, 1, 1, None, 1]], # 29
[21, 1, Conv, [128, 1, 1, None, 1]], # 30
[28, 1, Conv, [256, 1, 1, None, 1]], # 31
[ 29, 1, Conv, [ 64, 1, 1, None, 1 ] ], # 32
[ 30, 1, Conv, [ 128, 1, 1, None, 1 ] ], # 33
[ 31, 1, Conv, [ 256, 1, 1, None, 1 ] ], # 34
[ [ 33, 34 ], 1, ASFF_2, [ 128, 0 ] ], # 35
[ [ 33, 34 ], 1, ASFF_2, [ 256, 1 ] ], # 36
[35, 1, Conv, [64, 1, 1, None, 1]],
[35, 1, Conv, [64, 1, 1, None, 1]],
[-1, 1, Conv, [64, 3, 1, None, 1]],
[-1, 1, Conv, [64, 3, 1, None, 1]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1]], # 42
[ 36, 1, Conv, [ 128, 1, 1, None, 1 ] ],
[ 36, 1, Conv, [ 128, 1, 1, None, 1 ] ],
[ -1, 1, Conv, [ 128, 3, 1, None, 1 ] ],
[ -1, 1, Conv, [ 128, 3, 1, None, 1 ] ],
[ [ -1, -2, -3, -4 ], 1, Concat, [ 1 ] ],
[ -1, 1, Conv, [ 256, 1, 1, None, 1 ] ], # 48
[[32, 42, 48], 1, ASFF_3, [64, 0]], # 49
[[32, 42, 48], 1, ASFF_3, [128, 1]], # 50
[[32, 42, 48], 1, ASFF_3, [256, 2]], # 51
[ 49, 1, Conv, [ 32, 1, 1, None, 1 ] ],
[ 49, 1, Conv, [ 32, 1, 1, None, 1 ] ],
[ -1, 1, Conv, [ 32, 3, 1, None, 1 ] ],
[ -1, 1, Conv, [ 32, 3, 1, None, 1 ] ],
[ [ -1, -2, -3, -4 ], 1, Concat, [ 1 ] ],
[ -1, 1, Conv, [ 64, 1, 1, None, 1 ] ], # 57
[ 50, 1, Conv, [ 64, 1, 1, None, 1 ] ],
[ 50, 1, Conv, [ 64, 1, 1, None, 1 ] ],
[ -1, 1, Conv, [ 64, 3, 1, None, 1 ] ],
[ -1, 1, Conv, [ 64, 3, 1, None, 1 ] ],
[ [ -1, -2, -3, -4 ], 1, Concat, [ 1 ] ],
[ -1, 1, Conv, [ 128, 1, 1, None, 1 ] ], # 63
[51, 1, Conv, [128, 1, 1, None, 1]],
[51, 1, Conv, [128, 1, 1, None, 1]],
[-1, 1, Conv, [128, 3, 1, None, 1]],
[-1, 1, Conv, [128, 3, 1, None, 1]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1]], # 69
[57, 1, Conv, [64, 3, 1, None, 1]],
[63, 1, Conv, [128, 3, 1, None, 1]],
[69, 1, Conv, [256, 3, 1, None, 1]],
[[70,71,72], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
yolov7-tiny-AFPN.yaml(low-level做两次,论文的方法)
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
activation: nn.LeakyReLU(0.1)
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# yolov7-tiny backbone
backbone:
# [from, number, module, args] c2, k=1, s=1, p=None, g=1, act=True
[[-1, 1, Conv, [32, 3, 2, None, 1]], # 0-P1/2
[-1, 1, Conv, [64, 3, 2, None, 1]], # 1-P2/4
[-1, 1, Conv, [32, 1, 1, None, 1]],
[-2, 1, Conv, [32, 1, 1, None, 1]],
[-1, 1, Conv, [32, 3, 1, None, 1]],
[-1, 1, Conv, [32, 3, 1, None, 1]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1]], # 7
[-1, 1, MP, []], # 8-P3/8
[-1, 1, Conv, [64, 1, 1, None, 1]],
[-2, 1, Conv, [64, 1, 1, None, 1]],
[-1, 1, Conv, [64, 3, 1, None, 1]],
[-1, 1, Conv, [64, 3, 1, None, 1]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1, None, 1]], # 14
[-1, 1, MP, []], # 15-P4/16
[-1, 1, Conv, [128, 1, 1, None, 1]],
[-2, 1, Conv, [128, 1, 1, None, 1]],
[-1, 1, Conv, [128, 3, 1, None, 1]],
[-1, 1, Conv, [128, 3, 1, None, 1]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1]], # 21
[-1, 1, MP, []], # 22-P5/32
[-1, 1, Conv, [256, 1, 1, None, 1]],
[-2, 1, Conv, [256, 1, 1, None, 1]],
[-1, 1, Conv, [256, 3, 1, None, 1]],
[-1, 1, Conv, [256, 3, 1, None, 1]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1, None, 1]], # 28
]
# yolov7-tiny head
head:
[[14, 1, Conv, [64, 1, 1, None, 1]], # 29
[21, 1, Conv, [128, 1, 1, None, 1]], # 30
[28, 1, Conv, [256, 1, 1, None, 1]], # 31
[ 29, 1, Conv, [ 64, 1, 1, None, 1 ] ], # 32
[ 30, 1, Conv, [ 128, 1, 1, None, 1 ] ], # 33
[ 31, 1, Conv, [ 256, 1, 1, None, 1 ] ], # 34
[ [ 32, 33 ], 1, ASFF_2, [ 64, 0 ] ], # 35
[ [ 32, 33 ], 1, ASFF_2, [ 128, 1 ] ], # 36
[35, 1, Conv, [32, 1, 1, None, 1]],
[35, 1, Conv, [32, 1, 1, None, 1]],
[-1, 1, Conv, [32, 3, 1, None, 1]],
[-1, 1, Conv, [32, 3, 1, None, 1]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [64, 1, 1, None, 1]], # 42
[ 36, 1, Conv, [ 64, 1, 1, None, 1 ] ],
[ 36, 1, Conv, [ 64, 1, 1, None, 1 ] ],
[ -1, 1, Conv, [ 64, 3, 1, None, 1 ] ],
[ -1, 1, Conv, [ 64, 3, 1, None, 1 ] ],
[ [ -1, -2, -3, -4 ], 1, Concat, [ 1 ] ],
[ -1, 1, Conv, [ 128, 1, 1, None, 1 ] ], # 48
[[42, 48, 34], 1, ASFF_3, [64, 0]], # 49
[[42, 48, 34], 1, ASFF_3, [128, 1]], # 50
[[42, 48, 34], 1, ASFF_3, [256, 2]], # 51
[ 49, 1, Conv, [ 32, 1, 1, None, 1 ] ],
[ 49, 1, Conv, [ 32, 1, 1, None, 1 ] ],
[ -1, 1, Conv, [ 32, 3, 1, None, 1 ] ],
[ -1, 1, Conv, [ 32, 3, 1, None, 1 ] ],
[ [ -1, -2, -3, -4 ], 1, Concat, [ 1 ] ],
[ -1, 1, Conv, [ 64, 1, 1, None, 1 ] ], # 57
[ 50, 1, Conv, [ 64, 1, 1, None, 1 ] ],
[ 50, 1, Conv, [ 64, 1, 1, None, 1 ] ],
[ -1, 1, Conv, [ 64, 3, 1, None, 1 ] ],
[ -1, 1, Conv, [ 64, 3, 1, None, 1 ] ],
[ [ -1, -2, -3, -4 ], 1, Concat, [ 1 ] ],
[ -1, 1, Conv, [ 128, 1, 1, None, 1 ] ], # 63
[51, 1, Conv, [128, 1, 1, None, 1]],
[51, 1, Conv, [128, 1, 1, None, 1]],
[-1, 1, Conv, [128, 3, 1, None, 1]],
[-1, 1, Conv, [128, 3, 1, None, 1]],
[[-1, -2, -3, -4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1, None, 1]], # 69
[57, 1, Conv, [64, 3, 1, None, 1]],
[63, 1, Conv, [128, 3, 1, None, 1]],
[69, 1, Conv, [256, 3, 1, None, 1]],
[[70,71,72], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]两个配置文件的区别在于一个是将backbone中最后一层的输出做两次ASFF,另一个是将倒数第三层的输出做两次ASFF,也就是论文的做法,不过论文的做法参数会量少一点,总共5.9M多一点
在models/common.py中修改,确保可以从yaml中传入参数
class Conv(nn.Module):
# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, activation)
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
x = self.act(self.bn(self.conv(x)))
return x
def forward_fuse(self, x):
return self.act(self.conv(x))在models/common.py增加
class Upsample(nn.Module):
def __init__(self, in_channels, out_channels, scale_factor=2):
super(Upsample, self).__init__()
self.upsample = nn.Sequential(
Conv(in_channels, out_channels, 1),
nn.Upsample(scale_factor=scale_factor, mode='bilinear')
)
# carafe
# from mmcv.ops import CARAFEPack
# self.upsample = nn.Sequential(
# BasicConv(in_channels, out_channels, 1),
# CARAFEPack(out_channels, scale_factor=scale_factor)
# )
def forward(self, x):
x = self.upsample(x)
return x
class Downsample(nn.Module):
def __init__(self, in_channels, out_channels, scale_factor=2):
super(Downsample, self).__init__()
self.downsample = nn.Sequential(
Conv(in_channels, out_channels, scale_factor, scale_factor, 0)
)
def forward(self, x):
x = self.downsample(x)
return x
class ASFF_2(nn.Module):
def __init__(self, inter_dim=512, level=0, channel=[64, 128]):
super(ASFF_2, self).__init__()
self.inter_dim = inter_dim
compress_c = 8
self.weight_level_1 = Conv(self.inter_dim, compress_c, 1, 1)
self.weight_level_2 = Conv(self.inter_dim, compress_c, 1, 1)
self.weight_levels = nn.Conv2d(compress_c * 2, 2, kernel_size=1, stride=1, padding=0)
self.conv = Conv(self.inter_dim, self.inter_dim, 3, 1)
self.upsample = Upsample(channel[1], channel[0])
self.downsample = Downsample(channel[0], channel[1])
self.level = level
def forward(self, x):
input1, input2 = x
if self.level == 0:
input2 = self.upsample(input2)
elif self.level == 1:
input1 = self.downsample(input1)
level_1_weight_v = self.weight_level_1(input1)
level_2_weight_v = self.weight_level_2(input2)
levels_weight_v = torch.cat((level_1_weight_v, level_2_weight_v), 1)
levels_weight = self.weight_levels(levels_weight_v)
levels_weight = F.softmax(levels_weight, dim=1)
fused_out_reduced = input1 * levels_weight[:, 0:1, :, :] + \
input2 * levels_weight[:, 1:2, :, :]
out = self.conv(fused_out_reduced)
return out
class ASFF_3(nn.Module):
def __init__(self, inter_dim=512, level=0, channel=[64, 128, 256]):
super(ASFF_3, self).__init__()
self.inter_dim = inter_dim
compress_c = 8
self.weight_level_1 = Conv(self.inter_dim, compress_c, 1, 1)
self.weight_level_2 = Conv(self.inter_dim, compress_c, 1, 1)
self.weight_level_3 = Conv(self.inter_dim, compress_c, 1, 1)
self.weight_levels = nn.Conv2d(compress_c * 3, 3, kernel_size=1, stride=1, padding=0)
self.conv = Conv(self.inter_dim, self.inter_dim, 3, 1)
self.level = level
if self.level == 0:
self.upsample4x = Upsample(channel[2], channel[0], scale_factor=4)
self.upsample2x = Upsample(channel[1], channel[0], scale_factor=2)
elif self.level == 1:
self.upsample2x1 = Upsample(channel[2], channel[1], scale_factor=2)
self.downsample2x1 = Downsample(channel[0], channel[1], scale_factor=2)
elif self.level == 2:
self.downsample2x = Downsample(channel[1], channel[2], scale_factor=2)
self.downsample4x = Downsample(channel[0], channel[2], scale_factor=4)
def forward(self, x):
input1, input2, input3 = x
if self.level == 0:
input2 = self.upsample2x(input2)
input3 = self.upsample4x(input3)
elif self.level == 1:
input3 = self.upsample2x1(input3)
input1 = self.downsample2x1(input1)
elif self.level == 2:
input1 = self.downsample4x(input1)
input2 = self.downsample2x(input2)
level_1_weight_v = self.weight_level_1(input1)
level_2_weight_v = self.weight_level_2(input2)
level_3_weight_v = self.weight_level_3(input3)
levels_weight_v = torch.cat((level_1_weight_v, level_2_weight_v, level_3_weight_v), 1)
levels_weight = self.weight_levels(levels_weight_v)
levels_weight = F.softmax(levels_weight, dim=1)
fused_out_reduced = input1 * levels_weight[:, 0:1, :, :] + \
input2 * levels_weight[:, 1:2, :, :] + \
input3 * levels_weight[:, 2:, :, :]
out = self.conv(fused_out_reduced)
return out在models/yolo.py中修改:
def parse_model(d, ch): # model_dict, input_channels(3)
logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
# anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')
if act:
Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
pass
n = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in [nn.Conv2d, Conv, RobustConv, RobustConv2, DWConv, GhostConv, RepConv, RepConv_OREPA, DownC,
SPP, SPPF, SPPCSPC, GhostSPPCSPC, MixConv2d, Focus, Stem, GhostStem, CrossConv,
Bottleneck, BottleneckCSPA, BottleneckCSPB, BottleneckCSPC,
RepBottleneck, RepBottleneckCSPA, RepBottleneckCSPB, RepBottleneckCSPC,
Res, ResCSPA, ResCSPB, ResCSPC,
RepRes, RepResCSPA, RepResCSPB, RepResCSPC,
ResX, ResXCSPA, ResXCSPB, ResXCSPC,
RepResX, RepResXCSPA, RepResXCSPB, RepResXCSPC,
Ghost, GhostCSPA, GhostCSPB, GhostCSPC,
SwinTransformerBlock, STCSPA, STCSPB, STCSPC,
SwinTransformer2Block, ST2CSPA, ST2CSPB, ST2CSPC]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [DownC, SPPCSPC, GhostSPPCSPC,
BottleneckCSPA, BottleneckCSPB, BottleneckCSPC,
RepBottleneckCSPA, RepBottleneckCSPB, RepBottleneckCSPC,
ResCSPA, ResCSPB, ResCSPC,
RepResCSPA, RepResCSPB, RepResCSPC,
ResXCSPA, ResXCSPB, ResXCSPC,
RepResXCSPA, RepResXCSPB, RepResXCSPC,
GhostCSPA, GhostCSPB, GhostCSPC,
STCSPA, STCSPB, STCSPC,
ST2CSPA, ST2CSPB, ST2CSPC]:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum([ch[x] for x in f])
elif m is Chuncat:
c2 = sum([ch[x] for x in f])
elif m is Shortcut:
c2 = ch[f[0]]
elif m is Foldcut:
c2 = ch[f] // 2
elif m in [Detect, IDetect, IAuxDetect, IBin, IKeypoint]:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is ReOrg:
c2 = ch[f] * 4
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
elif m in {ASFF_2, ASFF_3}:
c2 = args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args[0] = c2
args.append([ch[x] for x in f])
else:
c2 = ch[f]
m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum([x.numel() for x in m_.parameters()]) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
logger.info('%3s%18s%3s%10.0f %-40s%-30s' % (i, f, n, np, t, args)) # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
ch.append(c2)
return nn.Sequential(*layers), sorted(save)在yolo.py中配置--cfg为yolov7-tiny-AFPN.yaml,点击运行,可见下图:
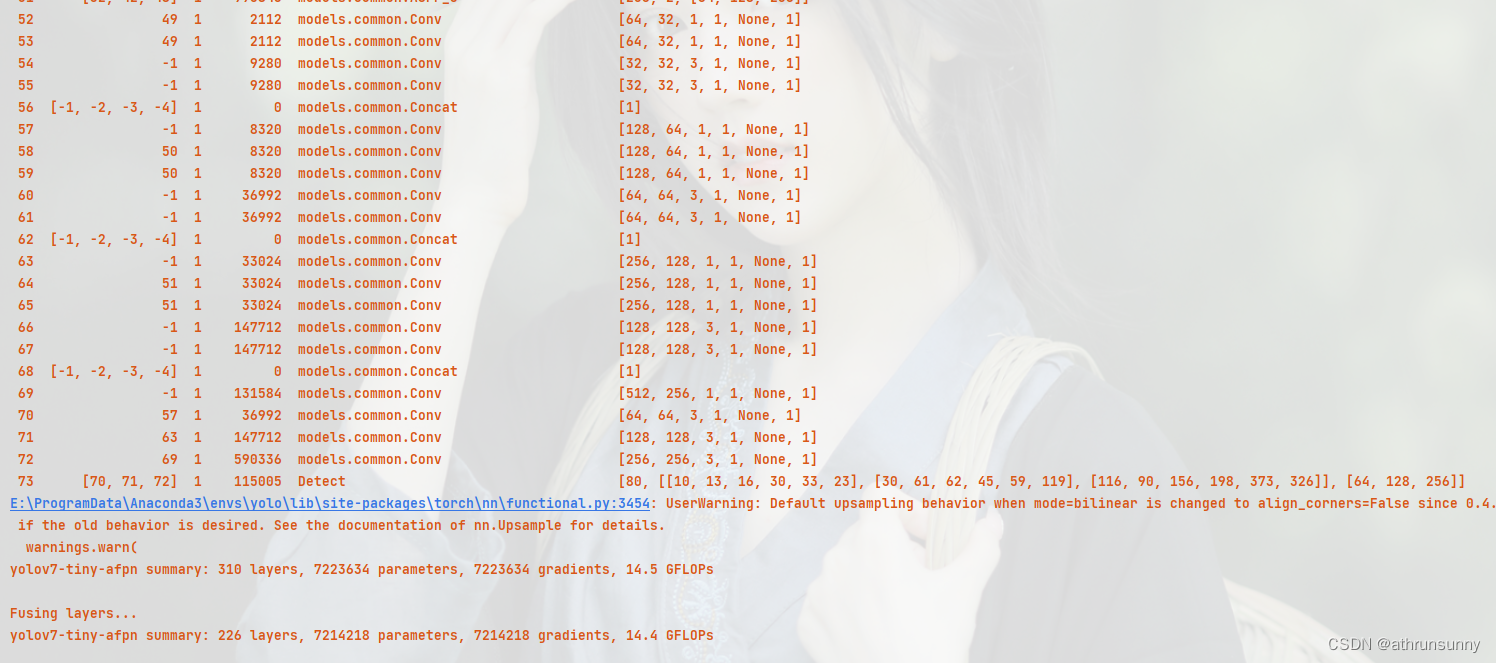
PS:不过这个14.5GFLOPs是在yolov5代码框架上的结果,在v7上竟然算出来是315.8GFLOPs,有点离谱,看了一圈也没发现问题在哪。。。评论区有说是正常的,那应该是我的v7有问题了