目录
摘要:
1. 图像增广简介
2. 图像增广的原理
3. 常见的图像增广技术
4. 如何在实际项目中应用图像增广
5.实际应用
摘要:
当今,深度学习已经在计算机视觉领域取得了令人瞩目的成就。图像增广作为一种数据处理技术,让我们在使用有限的图像数据集时能够充分挖掘图像特征,提高模型的泛化能力。本文将详细介绍图像增广的概念、原理以及如何在实际项目中应用。
1. 图像增广简介
图像增广(Image Augmentation)是一种通过对原始图像进行各种变换来生成新的图像的方法。这些变换包括旋转、翻转、缩放、剪切、色彩变换等。通过图像增广,我们可以扩大数据集的规模,增加模型训练时的输入样本。这有助于提高模型的泛化能力,从而在面对新的、未知的数据时,也能达到较高的准确性。
2. 图像增广的原理
深度学习模型在训练过程中需要大量的数据来学习特征表达。然而,在实际应用中,我们并不总是能获得足够多的数据。图像增广通过对原始图像进行各种变换,创造出具有不同视觉特征的新图像。这样一来,模型在训练时可以接触到更多样的数据,从而学习到更丰富的特征表达,提高泛化能力。
值得注意的是,图像增广并不能完全解决数据不足的问题,但它可以在一定程度上缓解这个问题,提高模型的性能。
3. 常见的图像增广技术
以下是一些常见的图像增广技术:
- **旋转**:将图像按一定的角度进行旋转。
- **翻转**:对图像进行水平或垂直翻转。
- **缩放**:对图像进行放大或缩小。
- **剪切**:在图像上随机选择一块区域,将其裁剪为新的图像。
- **色彩变换**:改变图像的亮度、对比度、饱和度等色彩属性。
- **噪声添加**:在图像中添加随机噪声。
- **仿射变换**:对图像进行平移、旋转、缩放等操作。
4. 如何在实际项目中应用图像增广
许多深度学习框架都提供了图像增广的相关工具,例如 TensorFlow、PyTorch、Keras 等。在使用这些框架时,我们可以轻松地将图像增广技术应用到我们的项目中。以下是一个使用 Keras 进行图像增广的简单示例:
from keras.preprocessing.image import ImageDataGenerator
# 创建一个图像数据生成器
datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# 将数据生成器应用到训练集
train_generator = datagen.flow_from_directory(
train_data_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='categorical')在上述代码中,我们定义了一个图像数据生成器,并设置了一些增广参数。然后,我们使用这个数据生成器对训练集进行处理。
5.实际应用
%matplotlib inline
import torch
import torchvision
from torch import nn
from d2l import torch as d2l导入图片: 图片大小为400*500

d2l.set_figsize()
img = d2l.Image.open('./img/1.jpg') #务必将图片放到该根目录
d2l.plt.imshow(img)大多数图像增广方法都具有一定的随机性。为了便于观察图像增广的效果,我们下面定义辅助函数apply。 此函数在输入图像img上多次运行图像增广方法aug并显示所有结果。
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5):#aug增广
Y = [aug(img) for _ in range(num_rows * num_cols)]
d2l.show_images(Y, num_rows, num_cols, scale=scale)左右翻转图像通常不会改变对象的类别。这是最早且最广泛使用的图像增广方法之一。 使用transforms模块来创建RandomFlipLeftRight实例,这样就各有50%的几率使图像向左或向右翻转。

上下翻转并不常用:
apply(img, torchvision.transforms.RandomVerticalFlip())
随机剪切函数:剪切大小200*200像素,在10%-100%的范围内剪切,长宽比为1:2
shape_aug = torchvision.transforms.RandomResizedCrop((200,200),scale=(0.1,1),ratio=(0.5,2))
apply(img,shape_aug)
随机改变亮度
apply(img,torchvision.transforms.ColorJitter(brightness=0.5,contrast=0,saturation=0,hue=0))

改变色调:
apply(img, torchvision.transforms.ColorJitter(
brightness=0, contrast=0, saturation=0, hue=0.5))
创建一个RandomColorJitter实例,并设置如何同时随机更改图像的亮度(brightness)、对比度(contrast)、饱和度(saturation)和色调(hue)。
color_aug = torchvision.transforms.ColorJitter(
brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)
apply(img, color_aug)
最常用的就是将各种增广方法结合起来:
augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(), color_aug, shape_aug])
apply(img, augs)
下载一个常用数据集:
#下载数据集
all_images = torchvision.datasets.CIFAR10(train=True, root="./data",
download=True)
d2l.show_images([all_images[i][0] for i in range(32)], 4, 8, scale=0.8);
通常对训练样本只进行图像增广,且在预测过程中不使用随机操作的图像增广。使用ToTensor实例将一批图像转换为深度学习框架所要求的格式,即形状为(批量大小,通道数,高度,宽度)的32位浮点数,取值范围为0~1。
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor()]) #变成一个4d矩阵
test_augs = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()])def load_cifar10(is_train, augs, batch_size):
dataset = torchvision.datasets.CIFAR10(root="./data", train=is_train,
transform=augs, download=True)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=is_train, num_workers=d2l.get_dataloader_workers())
return dataloader使用gpu进行训练数据:
#@save
#使用多GPU对模型进行训练和评估
def train_batch_ch13(net, X, y, loss, trainer, devices):
"""用多GPU进行小批量训练"""
if isinstance(X, list):
# 微调BERT中所需
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred, y)
l.sum().backward()
trainer.step()
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum
#@save
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices=d2l.try_all_gpus()):
"""用多GPU进行模型训练"""
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
# 4个维度:储存训练损失,训练准确度,实例数,特点数
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = train_batch_ch13(
net, features, labels, loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3],
None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {metric[0] / metric[2]:.3f}, train acc '
f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
f'{str(devices)}')可以定义train_with_data_aug函数,使用图像增广来训练模型。该函数获取所有的GPU,并使用Adam作为训练的优化算法,将图像增广应用于训练集,最后调用刚刚定义的用于训练和评估模型的train_ch13函数。
batch_size, devices, net = 256, d2l.try_all_gpus(), d2l.resnet18(10, 3)
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
def train_with_data_aug(train_augs, test_augs, net, lr=0.001):
train_iter = load_cifar10(True, train_augs, batch_size)
test_iter = load_cifar10(False, test_augs, batch_size)
loss = nn.CrossEntropyLoss(reduction="none")
trainer = torch.optim.Adam(net.parameters(), lr=lr)
train_ch13(net, train_iter, test_iter, loss, trainer, 10, devices)train_with_data_aug(train_augs, test_augs, net)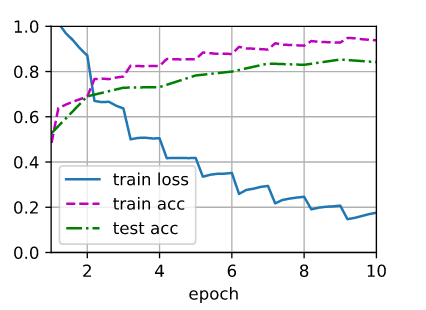
总之,图像增广作为一种数据处理技术,在深度学习领域具有重要的意义。通过应用图像增广,我们能够充分挖掘图像特征,提高模型的泛化能力。在实际项目中,我们可以根据需求选择不同的增广技术,从而优化模型的性能。