目录
01
前言
02
架构说明
03
先决条件
04
创建 EKS 集群
05
部署 Milvus 数据库
06
优化 Milvus 配置
07
测试 Milvus 集群
08
总结
01
前言
生成式 AI(Generative AI)的火爆引发了广泛的关注,也彻底点燃了向量数据库(Vector Database)市场,众多的向量数据库产品开始真正出圈,走进大众的视野。
根据 IDC 的预测,到2025年,超过80%的业务数据将是非结构化的,以文本、图像、音频、视频或其他格式存储。而大规模存储和查询非结构化数据是一个非常大的挑战。
在生成式 AI 和深度学习领域通常的做法是通过将非结构化数据转换为向量进行存储,并通过向量相似性搜索(Vector similarity search)技术进行语义相关性搜索。而快速地存储、索引和搜索 Embedding 向量,正是向量数据库的核心功能。
那么,什么是 Embedding 呢?简单地说,Embedding 就是浮点数的向量的嵌入式表征。两个向量之间的距离表示它们的相关性,距离越近相关性越高,距离越远相关性越低。如果两个 Embedding 相似,就意味着他们代表的原始数据也是相似的。这一点与传统的关键词搜索有很大的不同。

当前市面上主流的向量数据库可以分为两大类,一类是在既有数据库产品上进行扩展,例如 Amazon OpenSearch 服务通过 KNN 插件、Amazon RDS for PostgreSQL 通过 pgvector 扩展实现对向量的支持。另一类是独立的向量数据库产品,比较知名的有 Milvus、Zilliz Cloud (powered by Milvus)、Pinecone、Weaviate、Qdrant、Chroma 等。在这类向量数据库中,向量是一等公民,所有的功能都是围绕着它建立的。
Embedding 技术和向量数据库可以被广泛应用于各类 AI 驱动的应用场景,包括图片检索、视频分析、自然语言理解、推荐系统、定向广告、个性化搜索、智能客服和欺诈检测等。
在众多的向量数据库中,Milvus 是全球最流行的开源向量数据库之一,截止本文创作时至,在 Github 有超过1.8万颗 Star。且看 Milvus 的官方介绍:
Milvus 是一个高度灵活、可靠且速度极快的云原生开源向量数据库。它为 embedding 相似性搜索和 AI 应用程序提供支持,并努力使每个组织都可以访问向量数据库。 Milvus 可以存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的十亿级别以上的 embedding 向量。
本文主要探讨基于 Amazon EKS 等服务部署 Milvus 集群的实践。
02
架构说明
作为一款云原生的向量数据库产品,Milvus 的设计采用了共享存储的架构,存储计算完全分离,数据、查询和索引节点分离,并使用消息队列实现各个核心组件之间的解藕。核心工作节点是无状态的,因此可以提供极大的弹性和灵活性。
Milvus 遵循数据流和控制流分离的原则,整体分为了四个层次,分别为接入层(access layer)、协调服务(coordinator service)、工作节点(worker node)和存储层(storage)。
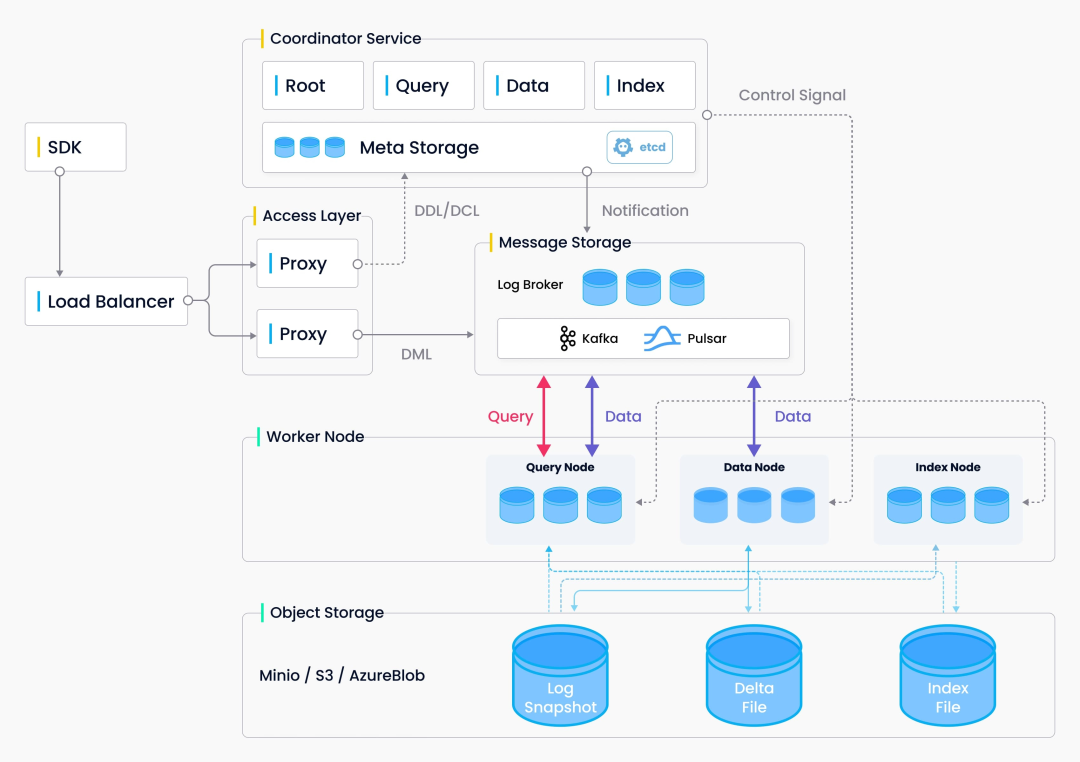
Milvus 设计之初就支持 Kubernetes 平台。本文采用 Amazon EKS 作为底层容器平台,并使用 Amazon S3、Amazon MSK (Managed Streaming for Apache Kafka)、Amazon ELB 等托管服务分别用作其中的 Object Storage、Message storage、Load Balancer 等核心组件,以搭建可靠、弹性的 Milvus 数据库集群,使其更适合生产环境使用。
本文采用渐进的方式一步步地部署、优化 Milvus 集群,使您更容易理解 EKS 和 Milvus 部署和配置过程。
03
先决条件
本文使用命令行的方式创建 EKS 和部署 Milvus 数据库集群,因此需要如下的预备条件:
#1. 一台个人电脑或者 Amazon EC2,安装 Amazon CLI,并配置相应的权限。如果您使用 Amazon Linux 2 或者 Amazon Linux 2023,Amazon CLI 工具默认已经安装。
#2. 安装 EKS 相关工具,包括 Helm,Kubectl,eksctl 等。
#3. 一个 Amazon S3 存储桶。
#4. 一个 Amazon MSK 实例。
MSK 创建注意事项:
1)当前最新稳定版本的 Milvus(v2.2.8)依赖 Kafka 的 autoCreateTopics 特性,因此在创建 MSK 时需要使用自定义配置,并将属性 auto.create.topics.enable 由默认的 false 改为 true 。另外,为了提高 MSK 的消息吞吐量,建议调大 message.max.bytes 和 replica.fetch.max.bytes 的值。详见 Custom MSK configurations (https://docs.aws.amazon.com/msk/latest/developerguide/msk-configuration-properties.html)。
auto.create.topics.enable=true message.max.bytes=10485880 replica.fetch.max.bytes=20971760
左滑查看更多
2)Milvus 不支持 MSK 的 IAM role-based 认证,因此 MSK 创建时需要在安全配置里打开 SASL/SCRAM authentication 选项,并在 Secret Manager 里配置 username 和 password ,详见 Sign-in credentials authentication with Amazon Secrets Manager(https://docs.aws.amazon.com/msk/latest/developerguide/msk-password.html)。
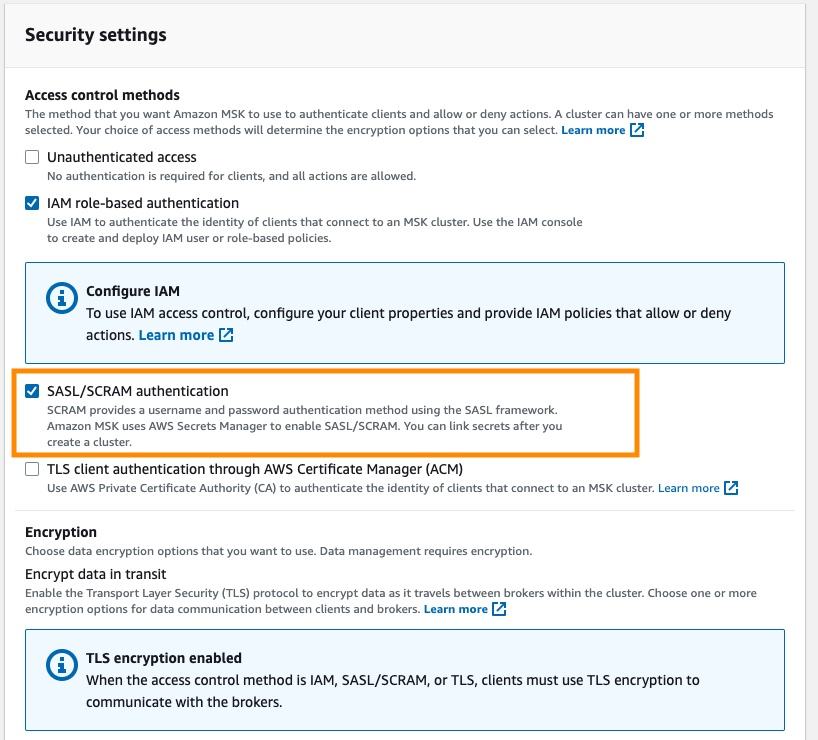
3)MSK 的安全组要允许 EKS 集群安全组或者 IP 地址段进行访问。
04
创建 EKS 集群
EKS 集群的创建方式有很多,如控制台、CloudFormation、eksctl 等。本文使用 eksctl 的方式。
eksctl 是一款简单的命令行工具,用于在 Amazon EKS 上创建和管理 Kubernetes 集群。 eksctl 提供使用 Amazon EKS 节点创建新集群的最快、最简单的方式。如需查阅官方文档,请参阅 https://eksctl.io/。
#1. 首先,用如下内容创建 eks_cluster.yaml 文件。请将 cluster-name 替换为您的集群名称,将 region-code 替换为创建集群的 Amazon 区域,将 private-subnet-idx 替换为您的私有子网。注:该配置文件通过指定私有 subnets 的方式在现有的 VPC 创建 EKS。您也可以删除 VPC 及 subnets 的配置,这样 eksctl 会自动创建一个全新的 VPC。
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: <cluster-name>
region: <region-code>
version: "1.26"
iam:
withOIDC: true
serviceAccounts:
- metadata:
name: aws-load-balancer-controller
namespace: kube-system
wellKnownPolicies:
awsLoadBalancerController: true
- metadata:
name: milvus-s3-access-sa
# if no namespace is set, "default" will be used;
# the namespace will be created if it doesn't exist already
namespace: milvus
labels: {aws-usage: "milvus"}
attachPolicyARNs:
- "arn:aws:iam::aws:policy/AmazonS3FullAccess"
# Use existed VPC to create EKS.
# If you don't config vpc subnets, eksctl will automatically create a brand new VPC
vpc:
subnets:
private:
us-west-2a: { id: <private-subnet-id1> }
us-west-2b: { id: <private-subnet-id2> }
us-west-2c: { id: <private-subnet-id3> }
managedNodeGroups:
- name: ng-1-milvus
labels: { role: milvus }
instanceType: m6i.2xlarge
desiredCapacity: 3
privateNetworking: true
addons:
- name: vpc-cni # no version is specified so it deploys the default version
attachPolicyARNs:
- arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy
- name: coredns
version: latest # auto discovers the latest available
- name: kube-proxy
version: latest
- name: aws-ebs-csi-driver
wellKnownPolicies: # add IAM and service account
ebsCSIController: true
左滑查看更多
#2. 然后,运行 eksctl 命令创建 EKS 集群。
eksctl create cluster -f eks_cluster.yaml
左滑查看更多
该过程将创建如下资源:
- 创建一个指定版本的 EKS 集群。
- 创建一个拥有3个 m6i.2xlarge EC2 实例的托管节点组。
- 创建 IAM OIDC 身份提供商和名为 aws-load-balancer-controller 的 ServiceAccount,后文安装 Amazon Load Balancer Controller 时使用。
- 创建一个命名空间 milvus ,并在此命名空间里创建名 milvus-s3-access-sa 的 ServiceAccount。后文为 Milvus 配置 S3 做 Object Storage 时使用。注意,此处为了方便授予了 milvus-s3-access-sa 所有 S3 访问权限,在生产环境部署时建议遵循最小化授权原则,只授予指定用于 Milvus 的 S3 存储桶的访问权限。
- 安装多个插件,其中 vpc-cni , coredns , kube-proxy 为 EKS 必备核心插件。 aws-ebs-csi-driver 是 Amazon EBS CSI 驱动程序,允许 EKS 集群管理 Amazon EBS 持久卷的生命周期。
等待集群创建完成。集群创建过程中会自动创建或者更新 kubeconfig 文件。您也可以运行如下命令手动更新,注意将 region-code 替换为创建集群的 Amazon 区域,将 cluster-name 替换为您的集群名称。
aws eks update-kubeconfig --region <region-code> --name <cluster-name>
左滑查看更多
集群创建完毕之后,运行如下命令就可以查看您的集群节点。
kubectl get nodes -A -o wide
左滑查看更多
#3. 创建 ebs-sc StorageClass,配置 GP3 作为存储类型,并设置为 default StorageClass。Milvus 使用 etcd 作为 Meta Storage,需要依赖该 StorageClass 创建和管理 PVC。
cat <<EOF | kubectl apply -f -
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ebs-sc
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: ebs.csi.aws.com
volumeBindingMode: WaitForFirstConsumer
parameters:
type: gp3
EOF
左滑查看更多
并将原来的 gp2 StorageClass 设置为非默认:
kubectl patch storageclass gp2 -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'
左滑查看更多
#4. 安装 Amazon Load Balancer Controller,后文中 Milvus Service 和 Attu Ingress 需要用到该 Controller,我们在此提前进行安装。
添加 eks-charts 仓库并更新。
helm repo add eks https://aws.github.io/eks-charts helm repo update
左滑查看更多
安装 Amazon Load Balancer Controller。请将 cluster-name 替换为您的集群名称。此处名为 aws-load-balancer-controller 的 ServiceAccount 已经在创建 EKS 集群时创建。
helm install aws-load-balancer-controller eks/aws-load-balancer-controller \ -n kube-system \ --set clusterName=<cluster-name> \ --set serviceAccount.create=false \ --set serviceAccount.name=aws-load-balancer-controller
左滑查看更多
检查 Controller 是否安装成功。
kubectl get deployment -n kube-system aws-load-balancer-controller
左滑查看更多
输出示例如下。
NAME READY UP-TO-DATE AVAILABLE AGE aws-load-balancer-controller 2/2 2 2 12m
左滑查看更多
05
部署 Milvus 数据库
Milvus 支持 Operator 和 Helm 等多种部署方式,相比较而言,通过 Operator 进行部署和管理要更为简单,但 Helm 方式要更加直接和灵活,因此本文采用 Helm 的部署方式。 在使用 Helm 部署 Milvus 时,可以通过配置文件 values.yaml 进行自定义配置,点击 values.yaml (https://raw.githubusercontent.com/milvus-io/milvus-helm/master/charts/milvus/values.yaml)可以查看所有配置选项。 Milvus 默认创建 in-cluster 的 minio 和 pulsar 分别作为 Object Storage 和 Message Storage。为了更适合在生产环境使用,我们通过配置文件使用 S3 和 MSK 作为替代。
#1. 首先,添加 Milvus Helm 仓库并更新。
helm repo add milvus https://milvus-io.github.io/milvus-helm/ helm repo update
左滑查看更多
#2. 配置 S3 作为 Object Storage。配置 serviceAccount 是为了授予 Milvus 访问 S3 的权限(此处为 milvus-s3-access-sa ,在创建 EKS 集群时已经创建)。注意将 <region-code> 替换为创建集群的 Amazon 区域。将 <bucket-name> 替换为 S3 存储桶的名字, <root-path> 替换为 S3 存储桶的前缀(可以为空)。
################################### # Service account # - this service account are used by External S3 access ################################### serviceAccount: create: false name: milvus-s3-access-sa ################################### # Close in-cluster minio ################################### minio: enabled: false ################################### # External S3 # - these configs are only used when `externalS3.enabled` is true ################################### externalS3: enabled: true host: "s3.<region-code>.amazonaws.com" port: "443" useSSL: true bucketName: "<bucket-name>" rootPath: "<root-path>" useIAM: true cloudProvider: "aws" iamEndpoint: ""
左滑查看更多
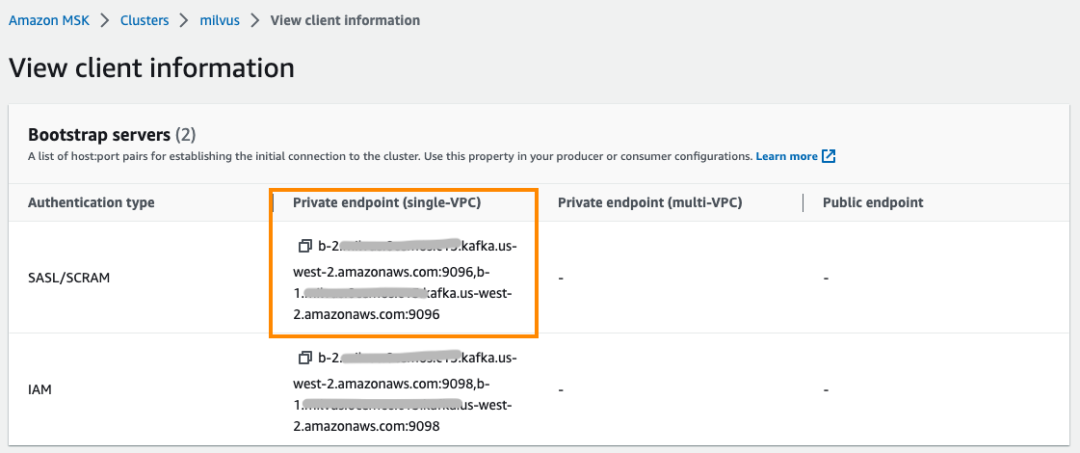
#3. 配置 MSK 作为 Message Storage。注意将 <broker-list> 替换为 MSK 的 SASL/SCRAM 认证类型对应的 endpoint 地址, <username> 和 <password>替换为 MSK 的账号和密码。
注意:MSK 的安全组要配置允许 EKS 集群安全组或者 IP 地址段进行访问。
###################################
# Close in-cluster pulsar
###################################
pulsar:
enabled: false
###################################
# External kafka
# - these configs are only used when `externalKafka.enabled` is true
###################################
externalKafka:
enabled: true
brokerList: "<broker-list>"
securityProtocol: SASL_SSL
sasl:
mechanisms: SCRAM-SHA-512
username: "<username>"
password: "<password>"
左滑查看更多
#4. 将2-3步的配置合并并保存为 milvus_cluster.yaml 文件,并使用 Helm 命令创建 Milvus(部署在 milvus 命名空间)。注意,您可以将 demo 替换为自定义名称。
helm install demo milvus/milvus -n milvus -f milvus_cluster.yaml
左滑查看更多
运行如下命令检查 pods 的状态。
kubectl get pods -n milvus
running 状态表明创建成功。
NAME READY STATUS RESTARTS AGE demo-etcd-0 1/1 Running 0 114s demo-etcd-1 1/1 Running 0 114s demo-etcd-2 1/1 Running 0 114s demo-milvus-datacoord-548bf76868-b6vzb 1/1 Running 0 115s demo-milvus-datanode-5fc794dd8b-z8l2x 1/1 Running 0 115s demo-milvus-indexcoord-c9455db7d-sx22q 1/1 Running 0 115s demo-milvus-indexnode-58bd66bbb7-f5xbp 1/1 Running 0 114s demo-milvus-proxy-664c68c7b4-x6jqn 1/1 Running 0 114s demo-milvus-querycoord-679bcf7497-7xg4v 1/1 Running 0 115s demo-milvus-querynode-64f94b6f97-wl5v4 1/1 Running 0 114s demo-milvus-rootcoord-5f9b687b57-d22s6 1/1 Running 0 115s
左滑查看更多
#5. 获取 Milvus 访问终端节点。
kubectl get svc -n milvus
输出示例如下,demo-milvus 就是 Milvus 的服务终端节点,其中19530为数据库访问端口,9091为 Metrics 访问端口。默认的 Service 类型为 ClusterIP,这种类型只能在 EKS 集群内部访问。我们将在下一章节讲解如何配置为允许集群外访问。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE demo-etcd ClusterIP 172.20.103.138 <none> 2379/TCP,2380/TCP 6m46s demo-etcd-headless ClusterIP None <none> 2379/TCP,2380/TCP 6m46s demo-milvus ClusterIP 172.20.219.33 <none> 19530/TCP,9091/TCP 6m46s demo-milvus-datacoord ClusterIP 172.20.214.106 <none> 13333/TCP,9091/TCP 6m46s demo-milvus-datanode ClusterIP None <none> 9091/TCP 6m46s demo-milvus-indexcoord ClusterIP 172.20.106.51 <none> 31000/TCP,9091/TCP 6m46s demo-milvus-indexnode ClusterIP None <none> 9091/TCP 6m46s demo-milvus-querycoord ClusterIP 172.20.136.213 <none> 19531/TCP,9091/TCP 6m46s demo-milvus-querynode ClusterIP None <none> 9091/TCP 6m46s demo-milvus-rootcoord ClusterIP 172.20.173.98 <none> 53100/TCP,9091/TCP 6m46s
左滑查看更多
06
优化 Milvus 配置
至此,我们已经成功地部署了 Milvus 集群,但很多 Milvus 的默认配置无法满足生产环境自定义需求,本部分主要围绕如下三个方面进行配置优化。
#1. Milvus 默认部署 ClusterIP 类型的 service,这种 service 只能在 EKS 内部访问,将 Milvus service 更改为 Loadbalancer 类型,使集群外也可以进行访问。
#2. 安装 Attu,通过可视化界面管理 Milvus 数据库。
#3. 优化各个组件的配置,使其满足于您的负载情况。
前两项配置需要用到 Amazon Load Balancer Controller,请确认在第三章中完成安装。
6.1 配置 Milvus 服务可供 EKS 集群外访问
Helm 支持在创建之后使用 helm upgrade 命令进行配置更新,我们采用这种方式对 Milvus 进行配置。 使用如下代码创建 milvus_service.yaml 配置文件,该配置文件指定使用 Load Balancer Controller 创建 LoadBalancer 类型的 service,以方便在集群外进行访问。LoadBalancer 类型的 Service 使用 Amazon NLB 作为负载均衡器。根据安全最佳实践,此处 aws-load-balancer-scheme 默认配置为 internal 模式,即只允许内网访问 Milvus。如果您确实需要通过 Internet 访问 Milvus,需要将 internal 更改为 internet-facing 。访问链接查看 NLB 配置说明(https://docs.aws.amazon.com/eks/latest/userguide/network-load-balancing.html)。
## Expose the Milvus service to be accessed from outside the cluster (LoadBalancer service).
## or access it from within the cluster (ClusterIP service). Set the service type and the port to serve it.
##
service:
type: LoadBalancer
port: 19530
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: external #AWS Load Balancer Controller fulfills services that has this annotation
service.beta.kubernetes.io/aws-load-balancer-name : milvus-service #User defined name given to AWS Network Load Balancer
service.beta.kubernetes.io/aws-load-balancer-scheme: internal # internal or internet-facing, later allowing for public access via internet
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip #The Pod IPs should be used as the target IPs (rather than the node IPs)
左滑查看更多
然后使用 Helm 更新配置文件。
helm upgrade demo milvus/milvus -n milvus --reuse-values -f milvus_service.yaml
左滑查看更多
运行如下命令:
kubectl get svc -n milvus
可以看到 demo-milvus 服务已经更改为 LoadBalancer 类型,底层使用 NLB 作为服务均衡器,其中 EXTERNAL-IP 一栏即为集群外访问地址。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE demo-etcd ClusterIP 172.20.103.138 <none> 2379/TCP,2380/TCP 62m demo-etcd-headless ClusterIP None <none> 2379/TCP,2380/TCP 62m demo-milvus LoadBalancer 172.20.219.33 milvus-nlb-xxxx.elb.us-west-2.amazonaws.com 19530:31201/TCP,9091:31088/TCP 62m demo-milvus-datacoord ClusterIP 172.20.214.106 <none> 13333/TCP,9091/TCP 62m demo-milvus-datanode ClusterIP None <none> 9091/TCP 62m demo-milvus-indexcoord ClusterIP 172.20.106.51 <none> 31000/TCP,9091/TCP 62m demo-milvus-indexnode ClusterIP None <none> 9091/TCP 62m demo-milvus-querycoord ClusterIP 172.20.136.213 <none> 19531/TCP,9091/TCP 62m demo-milvus-querynode ClusterIP None <none> 9091/TCP 62m demo-milvus-rootcoord ClusterIP 172.20.173.98 <none> 53100/TCP,9091/TCP 62m
左滑查看更多
6.2 安装可视化管理工具 Attu
Attu 是 Milvus 的高效开源管理工具。它具有直观的图形用户界面(GUI),使您可以轻松地与数据库进行交互。只需点击几下,您就可以可视化集群状态、管理元数据、执行数据查询等等。
本部分我们使用 Helm 安装并配置 Attu。
首先,使用如下代码创建 milvus_attu.yaml 配置文件。在配置文件里开启 Attu 选项,配置使用 Amazon ALB 作为 Ingress,并设置为 internet-facing 类型可通过 Internet 亦可访问 Attu。访问链接查看 ALB 配置说明(https://docs.aws.amazon.com/eks/latest/userguide/alb-ingress.html)。
attu:
enabled: true
name: attu
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: alb # Annotation: set ALB ingress type
alb.ingress.kubernetes.io/scheme: internet-facing #Places the load balancer on public subnets
alb.ingress.kubernetes.io/target-type: ip #The Pod IPs should be used as the target IPs (rather than the node IPs)
alb.ingress.kubernetes.io/group.name: attu # Groups multiple Ingress resources
hosts:
-
左滑查看更多
然后使用 Helm 更新配置文件。
helm upgrade demo milvus/milvus -n milvus --reuse-values -f milvus_attu.yaml
左滑查看更多
再次运行如下命令:
kubectl get ingress -n milvus
可以看到名为 demo-milvus-attu 的 Ingress,其中 ADDRESS 一栏即为访问地址。
NAME CLASS HOSTS ADDRESS PORTS AGE demo-milvus-attu <none> * k8s-attu-xxxx.us-west-2.elb.amazonaws.com 80 27s
左滑查看更多
使用浏览器打开 Ingress 地址,即可看到如下界面,点击 Connect 即可进行登录。
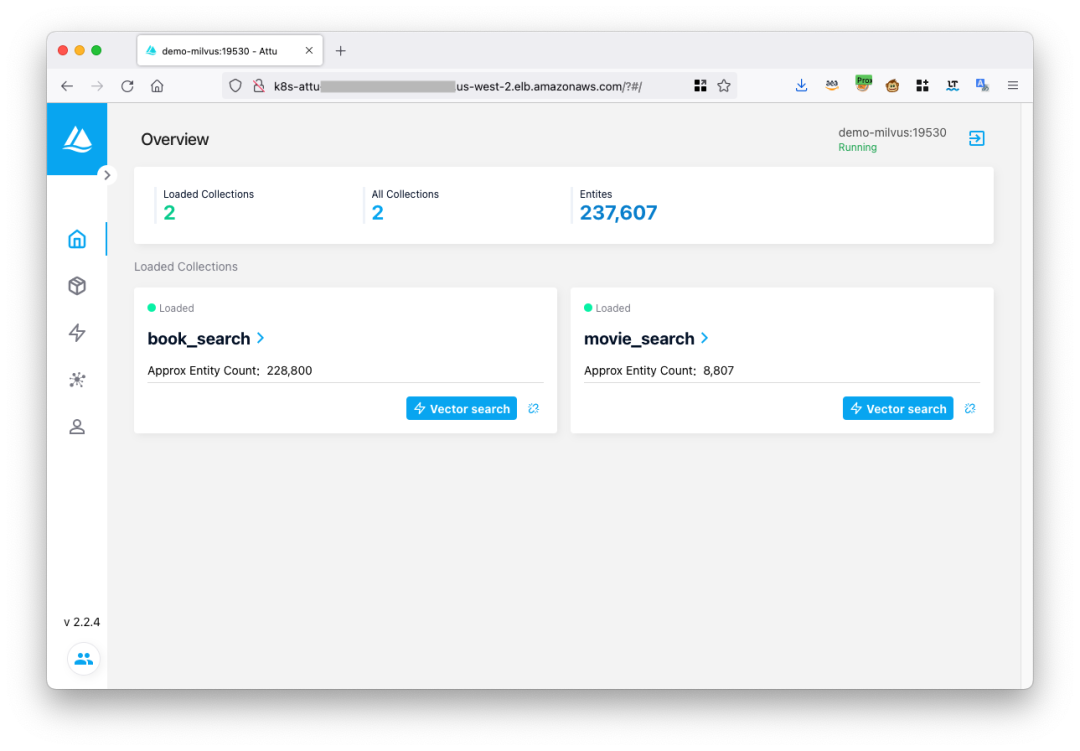
登录之后就可以通过可视化的方式管理 Milvus 数据库。
6.3 优化 Milvus 的资源分配
本部分介绍如何调整 EKS 上 Milvus 组件资源分配。 通常,您在生产环境中分配给 Milvus 集群的资源应该与工作负载成正比。虽然您可以在集群运行时更新配置,但我们建议在正式部署工作负载之前进行配置。
通过前边的架构图我们可以看到 Milvus 包含多个独立且解藕的组件,运行 kubectl get deployment -n milvus 命令可以看到 Milvus 的核心组件。
NAME READY UP-TO-DATE AVAILABLE AGE demo-milvus-attu 1/1 1 1 2d20h demo-milvus-datacoord 1/1 1 1 2d22h demo-milvus-datanode 1/1 1 1 2d22h demo-milvus-indexcoord 1/1 1 1 2d22h demo-milvus-indexnode 1/1 1 1 2d22h demo-milvus-proxy 1/1 1 1 2d22h demo-milvus-querycoord 1/1 1 1 2d22h demo-milvus-querynode 1/1 1 1 2d22h demo-milvus-rootcoord 1/1 1 1 2d22h
左滑查看更多
在默认情况下,Milvus 未明确指定 Pod 的 CPU 和 Memory 资源配置,且各个组件的 replica 为1。我们可以根据业务负载为这些组件灵活分配资源,Milvus 官网也提供了配置生成工具(https://milvus.io/tools/sizing/),可以根据数据量、向量维度和索引类型等多个维度给出配置建议,并一键生成 Helm 配置文件。
如下配置是在100万条数据、128维向量和 HNSW 索引类型的条件下,工具给出的配置建议。
rootCoordinator:
replicas: 1
resources:
limits:
cpu: 1
memory: 2Gi
indexCoordinator:
replicas: 1
resources:
limits:
cpu: "0.5"
memory: 0.5Gi
queryCoordinator:
replicas: 1
resources:
limits:
cpu: "0.5"
memory: 0.5Gi
dataCoordinator:
replicas: 1
resources:
limits:
cpu: "0.5"
memory: 0.5Gi
proxy:
replicas: 1
resources:
limits:
cpu: 1
memory: 4Gi
queryNode:
replicas: 1
resources:
limits:
cpu: 1
memory: 4Gi
dataNode:
replicas: 1
resources:
limits:
cpu: 1
memory: 4Gi
indexNode:
replicas: 1
resources:
limits:
cpu: 4
memory: 8Gi
左滑查看更多
使用以上配置创建 milvus_resources.yaml 文件,并使用 Helm 命令进行更新。
helm upgrade demo milvus/milvus -n milvus --reuse-values -f milvus_resources.yaml
左滑查看更多
以其中一个资源变更的 pod 为例,运行 kubectl describe pod <pod-name> -n milvus 就可以看到 Pod 的 cpu 和 memory 资源分配已经更新为指定值。
Containers:
querynode:
Container ID: containerd://0c29912397aa1b18471b1ec90d6da5bb6ae855fe14e3b1f85f5e60d01da3ca9c
Image: milvusdb/milvus:v2.2.8
Image ID: docker.io/milvusdb/milvus@sha256:e6ecd1a10b02dd9b179333b351caa6b685d430a32c1c1a3c9e80ec2dd9b4549d
Ports: 21123/TCP, 9091/TCP
Host Ports: 0/TCP, 0/TCP
Args:
/milvus/tools/run-helm.sh
milvus
run
querynode
State: Running
Started: Wed, 17 May 2023 09:08:11 +0000
Ready: True
Restart Count: 0
Limits:
cpu: 1
memory: 4Gi
Requests:
cpu: 1
memory: 4Gi
左滑查看更多
07
测试 Milvus 集群
我们使用 Milvus 官方的示例代码来测试 Milvus 集群能否正常工作。首先,直接下载 hello_milvus.py 示例代码。
wget https://raw.githubusercontent.com/milvus-io/pymilvus/v2.2.8/examples/hello_milvus.py
左滑查看更多
修改示例代码中的 host 为 Milvus 服务终端节点地址。
print(fmt.format("start connecting to Milvus"))
connections.connect("default", host="milvus-nlb-xxx.elb.us-west-2.amazonaws.com", port="19530")
左滑查看更多
运行代码:
python3 hello_milvus.py
返回如下结果即证明 Milvus 运行正常。
=== start connecting to Milvus === Does collection hello_milvus exist in Milvus: False === Create collection `hello_milvus` === === Start inserting entities === Number of entities in Milvus: 3000 === Start Creating index IVF_FLAT === === Start loading ===
左滑查看更多
该示例代码验证了 PyMilvus(Milvus 的 Python SDK)的基本操作流程,包括:
- 连接到 Milvus
- 创建 collection
- 插入数据
- 创建索引
- 搜索、查询和混合搜索
- 根据主键删除 entities
- 删除 collection
08
总结
本文介绍了基于 Amazon EKS 部署 Milvus 集群的方案,并在方案中集成 S3、MSK、ELB 等托管服务实现更高的弹性和可靠性。
当前,生成式 AI 领域的发展一日千里,各类大模型与向量数据库的结合也激发了无数的创新。近期,使用 LangChain、大语言模型(LLM)与向量数据库构建基于企业知识库的智能搜索和智能问答应用,颠覆了传统的开发模式,得到了广泛的关注。
Milvus 已经支持 Amazon SageMaker、PyTorch、HuggingFace、LlamaIndex、LangChain 等业界主流的 AI 模型和框架,赶快使用 Milvus 开始您的创新之旅吧。

![[管理与领导-7]:新任管理第1课:管理转身--从技术业务走向管理 - 管理常识1](https://img-blog.csdnimg.cn/img_convert/ad37af93a77d51cf25752adf117357df.jpeg)






![[uni-app]设置运行到微信小程序](https://img-blog.csdnimg.cn/25008edc263b4c1b8f75010a70ee36d1.png)