Json简介:Json,全名 JavaScript Object Notation,是一种轻量级的数据交换格式。Json最广泛的应用是作为AJAX中web服务器和客户端的通讯的数据格式。现在也常用于http请求中,所以对json的各种学习,是自然而然的事情。
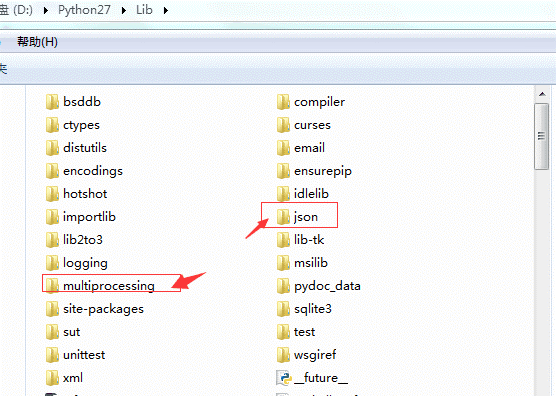
Json API 使用:python在版本2.6之前,是需要先下载包,安装后才能使用的,有点类似现在的RF内使用SeleniumLibrary一样。但是在2.6中,官方文档(https://docs.python.org/2.6/whatsnew/2.6.html)明显指出,“有一些重要的新的软件包添加到了标准库,比如multiprocessing 和json,但是跟python 3比,2.6的这些包不会引进更多的新功能。"于是安装python2.6以上版本的童鞋,可以不需要下载json包,直接在所需的地方就import json 即可使用,在安装目录下的Lib 下,看到这两个包(点进去仔细阅读这些源码,会有更多的收获,)如下文所示:
Python2.6 以上版本支持Json的编码和解码,支持python的大部分内置类型与Json进行转换。最简单的例子如下所示:
>>> import json
>>> data = {"spam" : "foo", "parrot" : 42}
>>> in_json = json.dumps(data) # Encode the data
>>> in_json
'{"parrot": 42, "spam": "foo"}'
>>> json.loads(in_json) # Decode into a Python object
{"spam" : "foo", "parrot" : 42}Encode过程,是把python对象转换成json对象的一个过程,常用的两个函数是dumps和dump函数。两个函数的唯一区别就是dump把python对象转换成json对象生成一个fp的文件流,而dumps则是生成了一个字符串:


其他参数的使用都是一样的。以下是部分学习的代码片段:
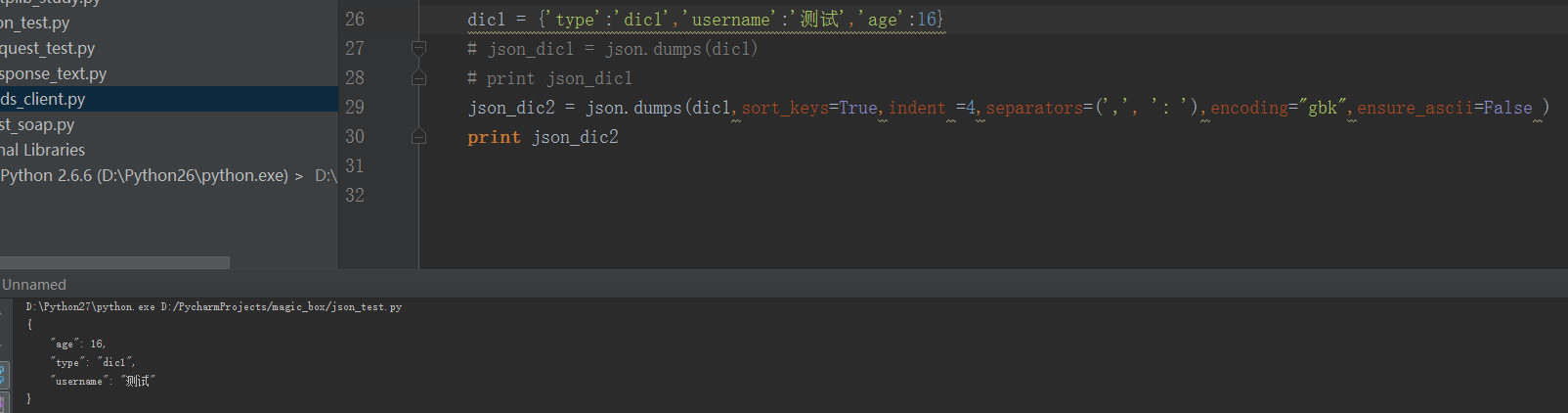
dic1 = {'type':'dic1','username':'loleina','age':16}
json_dic1 = json.dumps(dic1)
print json_dic1
json_dic2 = json.dumps(dic1,sort_keys=True,indent =4,separators=(',', ': '),encoding="gbk",ensure_ascii=True )
print json_dic2
运行结果如下所示:

如果把实例中的key'username'的value换成中文的“测试”,则用第一次不加参数转换则会报错,但是用第二个加参数的就能正常运行。
实际上就是对函数的参数的一个理解过程,下面列出几个常用的参数:
Skipkeys:默认值是False,如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None),设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key
ensure_ascii:默认值True,如果dict内含有non-ASCII的字符,则会类似\uXXXX的显示数据,设置成False后,就能正常显示
indent:应该是一个非负的整型,如果是0,或者为空,则一行显示数据,否则会换行且按照indent的数量显示前面的空白,这样打印出来的json数据也叫pretty-printed json
separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(',',':');这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。
encoding:默认是UTF-8,设置json数据的编码方式。
sort_keys:将数据根据keys的值进行排序。
Decode过程,是把json对象转换成python对象的一个过程,常用的两个函数是loads和load函数。区别跟dump和dumps是一样的。
if __name__ == '__main__':
# 将python对象test转换json对象
test = [{"username":"测试","age":16},(2,3),1]
print type(test)
python_to_json = json.dumps(test,ensure_ascii=False)
print python_to_json
print type(python_to_json)
# 将json对象转换成python对象
json_to_python = json.loads(python_to_json)
print json_to_python
print type(json_to_python)运行结果如下:

从上面2个例子的测试结果可以看到,python的一些基本类型通过encode之后,tuple类型就转成了list类型了,再将其转回为python对象时,list类型也并没有转回成tuple类型,而且编码格式也发生了变化,变成了Unicode编码。具体转化时,类型变化规则如下所示:
Python-->Json
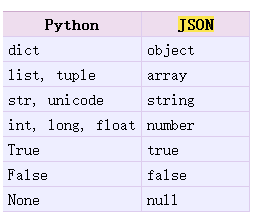
Json-->Python

Json处理中文问题:
关于python字符串的处理问题,如果深入的研究下去,我觉得可以写2篇文章了(实际上自己还没整很明白),在这里主要还是总结下使用python2.7.11处理json数据的问题。前期做接口测试,处理最多的事情就是,把数据组装成各种协议的报文,然后发送出去。然后对返回的报文进行解析,后面就遇到将数据封装在json内嵌入在http的body内发送到web服务器,然后服务器处理完后,返回json数据结果的问题。在这里面就需要考虑json里有中文数据,怎么进行组装和怎么进行解析,以下是基础学习的一点总结:
第一:Python 2.7.11的默认编码格式是ascii编码,而python3的已经是unicode,在学习编解码的时,有出现乱码的问题,也有出现list或者dictionary或者tuple类型内的中文显示为unicode的问题。出现乱码的时候,应该先看下当前字符编码格式是什么,再看下当前文件编码格式是什么,或者没有设置文件格式时,查看下IDE的默认编码格式是什么。最推崇的方式当然是每次编码,都对文件编码格式进行指定,如在文件前 设置# coding= utf-8。
第二:字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。因此,转码的时候一定要先搞明白,字符串str是什么编码,然后decode成unicode,然后再encode成其他编码
第三:将json数据转换成python数据后,一般会得到一个dict类型的变量,此时内部的数据都是unicode编码,所以中文的显示看着很痛苦,但是对于dict得到每个key的value后,中文就能正常显示了,如下所示:
# coding= utf-8
import json
import sys
if __name__ == '__main__':
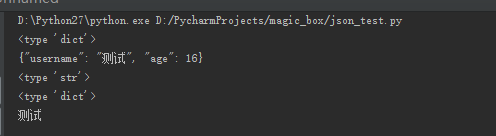
# 将python对象test转换json对象
test = {"username":"测试","age":16}
print type(test)
python_to_json = json.dumps(test,ensure_ascii=False)
print python_to_json
print type(python_to_json)
# 将json对象转换成python对象
json_to_python = json.loads(python_to_json)
print type(json_to_python)
print json_to_python['username']运行结果: