大数据开发要学Java框架吗?学习大数据要去学习Java而且还要精通,不仅要掌握Java基础知识还要掌握一些核心的Java架构。从java基础开始,学习大数据开发过程中必备的离线数据分析、实时数据分析和内存数据计算等,掌握大数据体系中几乎所有的核心技术。
Java具有非常多的优秀特性,同时拥有庞大的类库生态和大量的开发者,在大数据生态体系中,大数据生态组件很多都是用Java语言或基于JVM的语言(如Scala)开发的。想入行做大数据,必须要掌握相应的Java基础:
1、Java基本概念及特性
Java是面向对象的高级编程语言,所谓对象就是真实世界中的实体,对象与实体是一一对应的,也就是说现实世界中每一个实体都是一个对象,它是一种具体的概念,正所谓万物皆对象。
Java中的几个很重要的基础概念,面向对象、类、对象、封装、继承、多态和泛型,都是入门必须掌握的。
2、Java常见的集合及方法
在大数据当中,常常需要使用到集合来存储和处理数据,因此需要大家对集合的分类和功能有所了解。Java的集合框架分为两部分,分别对应两大接口:Collection接口和Map接口。
3、Java常用的字符串处理方法
大数据工作中,通过Hive写类SQL语言处理数据是常见的操作,而类SQL语法中处理字符串的方法都是通过对Java的字符串处理方法进行一层封装得到的,所以这部分要加深理解。
4、json的解析与操作
这部分的重点,一是Java变量和json格式之间的相互转化,二是json对象与字符串的相互转化。
5、JDBC
Java连接数据库的操作步骤,这是大数据当中常用的操作,必须掌握。
6、正则表达式
掌握正则表达式的概念、作用、基本规则。
编程人员面对的最大挑战就是复杂性,硬件越来越复杂,OS越来越复杂,编程语言和API越来越复杂,我们构建的应用也越来越复杂。大数据是庞大或复杂的数据集,小编整理后列出了Java程序员经常使用到的一些工具或框架。因此传统的数据处理程序不足以支持如此庞大的体量。在许多情况下使用SQL数据库存储/检索数据都是很好的选择,今天介绍下不同的非SQL存储/处理数据工具:
1、MongoDB跨平台面向文档的数据库
MongoDB是一个基于分布式文件存储的数据库,使用C++语言编写。旨在为Web应用提供可扩展的高性能数据存储解决方案。应用性能高低依赖于数据库性能,MongoDB则是非关系数据库中功能最丰富,最像关系数据库的,随着MongDB 3.4版本发布,其应用场景适用能力得到了进一步拓展。
MongoDB的核心优势就是灵活的文档模型、高可用复制集、可扩展分片集群。你可以试着从几大方面了解MongoDB,如实时监控MongoDB工具、内存使用量和页面错误、连接数、数据库操作、复制集等。
2、Elasticsearch 云构建的分布式RESTful搜索引擎
ElasticSearch是基于Lucene的搜索服务器。它提供了分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是比较流行的企业级搜索引擎。
ElasticSearch不仅是一个全文本搜索引擎,还是一个分布式实时文档存储,其中每个field均是被索引的数据且可被搜索;也是一个带实时分析功能的分布式搜索引擎,并且能够扩展至数以百计的服务器存储及处理PB级的数据。ElasticSearch在底层利用Lucene完成其索引功能,因此其许多基本概念源于Lucene。
3、Cassandra开源分布式数据库管理系统
处理许多商品服务器上的大量数据,提供高可用性,没有单点故障。Apache Cassandra是一套开源分布式NoSQL数据库系统。集Google BigTable的数据模型与Amazon Dynamo的完全分布式架构于一身。于2008开源,此后,由于Cassandra良好的可扩展性,被Digg、Twitter等Web 2.0网站所采纳,成为了一种流行的分布式结构化数据存储方案。
因Cassandra是用Java编写的,所以理论上在具有JDK6及以上版本的机器中都可以运行,官方测试的JDK还有OpenJDK 及Sun的JDK。 Cassandra的操作命令,类似于我们平时操作的关系数据库,对于熟悉MySQL的朋友来说,操作会很容易上手。
4、Redis开源(BSD许可)内存数据结构存储
用作数据库缓存和消息代理,Redis是一个开源的使用ANSI C语言编写的、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。Redis 有三个主要使其有别于其它很多竞争对手的特点:Redis是完全在内存中保存数据的数据库,使用磁盘只是为了持久性目的; Redis相比许多键值数据存储系统有相对丰富的数据类型; Redis可以将数据复制到任意数量的从服务器中。
5、Hazelcast 基于Java的开源内存数据网格
Hazelcast 是一种内存数据网格 in-memory data grid,提供Java程序员关键任务交易和万亿级内存应用。虽然Hazelcast没有所谓的‘Master’,但是仍然有一个Leader节点(the oldest member),这个概念与ZooKeeper中的Leader类似,但是实现原理却完全不同。同时,Hazelcast中的数据是分布式的,每一个member持有部分数据和相应的backup数据,这点也与ZooKeeper不同。
Hazelcast的应用便捷性深受开发者喜欢,但如果要投入使用,还需要慎重考虑。
5、EHCache广泛使用的开源Java分布式缓存。
主要面向通用缓存、Java EE和轻量级容器。EhCache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的CacheProvider。主要特性有:快速简单,具有多种缓存策略;缓存数据有两级,内存和磁盘,因此无需担心容量问题;缓存数据会在虚拟机重启的过程中写入磁盘;可以通过RMI、可插入API等方式进行分布式缓存;具有缓存和缓存管理器的侦听接口;支持多缓存管理器实例,以及一个实例的多个缓存区域;提供Hibernate的缓存实现。
6、Hadoop --用Java编写的开源软件框架
用于分布式存储,并对非常大的数据集进行分布式处理。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算。
7、Solr 开源企业搜索平台
用Java编写,来自Apache Lucene项目。Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
与ElasticSearch一样,同样是基于Lucene,但它对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化。
9、Spark开源集群计算框架
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
10、Memcached 通用分布式内存缓存系统
Memcached是一套分布式快取系统,当初是Danga Interactive为了LiveJournal所发展的,但被许多软件(如MediaWiki)所使用。Memcached作为高速运行的分布式缓存服务器,具有以下的特点:协议简单,基于libevent的事件处理,内置内存存储方式。
11、Apache Hive 在Hadoop之上提供类似SQL的层。
Hive是一个基于Hadoop的数据仓库平台。通过hive,可以方便地进行ETL工作。hive定义了一个类似于SQL的查询语言,能够将用户编写的SQL转化为相应的Mapreduce程序基于Hadoop执行。目前,已经发布了Apache Hive 2.1.1 版本。
12、Apache Kafka 分布式订阅消息系统
Apache Kafka是一个开源消息系统项目,由Scala写成。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。Kafka维护按类区分的消息,称为主题(topic)。生产者(producer)向kafka的主题发布消息,消费者(consumer)向主题注册,并且接收发布到这些主题的消息。kafka以一个拥有一台或多台服务器的集群运行着,每一台服务器称为broker。
时势造英雄,对个人而言亦是如此。跟随趋势,找准自己未来发力的赛道,在合适的时间干合适的事,就是抓住自己的未来。
而行业研究就是为了得出面向未来的结论。所以,了解行业趋势,太重要了。
在互联网时代,未来的机会在哪呢?
日前,北京大数据研究院联合大数据分析与应用技术国家工程实验室、北京治数科技有限公司共同发布了《2022年中国大数据产业发展指数报告》。
研究团队在2020年、2021年连续发布大数据产业发展指数的基础上,深入调研了各地大数据政策环境、大数据产业和企业发展状况,基于自身企业库中收录的 7472 家大数据企业数据和相关合作方数据,对全国 31 个省级行政区(不包含港澳台地区)和 150个 重点城市的大数据产业发展情况进行综合评估。以下是从报告中摘录的部分:
产业整体发展持续向好
但差异和分化态势显著
从大数据产业发展省级得分来看,全国 31 个省级行政区(不包含港澳台地区)大数据产业发展水平差异和分化态势显著。
大数据产业发展前20强城市
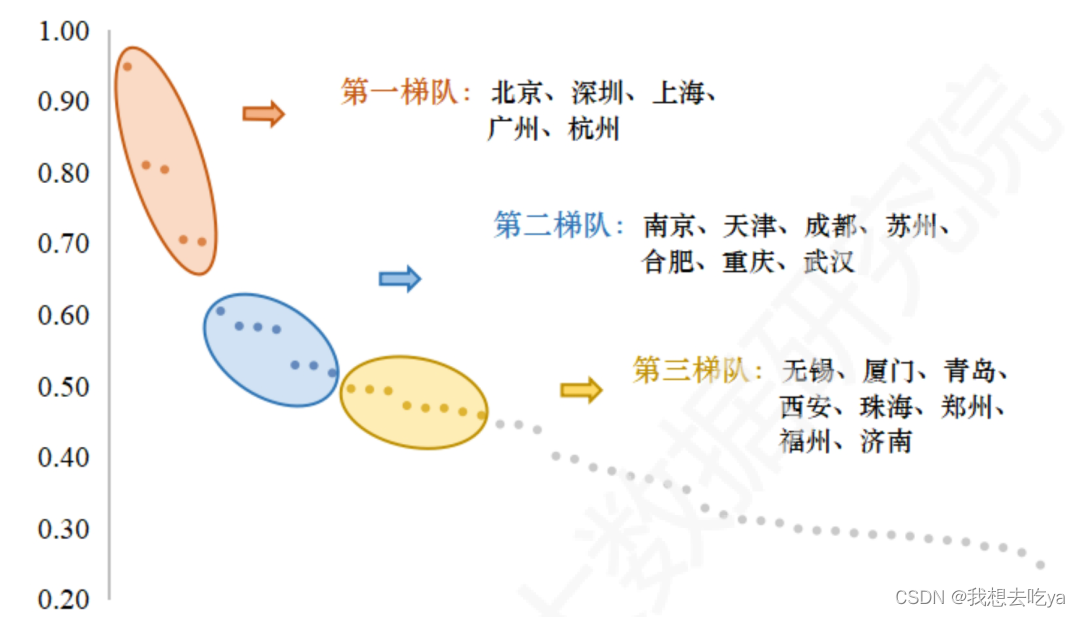
△大数据产业发展指数城市排名散点图
从梯队和排名变化情况可以看出,城市大数据产业发展水平与城市综合发展水平呈正相关。
第一梯队优势明显,引领大数据产业发展
排名依次为北京、深圳、上海、广州、杭州5个城市。这些城市实力雄厚,大数据产业发展水平处于全国头部,指数排名稳居全国前五。
第二梯队追赶势头强劲,大数据产业规模扩大
排名依次为南京、天津、成都、苏州、合肥、重庆、武汉7个城市。
这些城市大数据产业发展指数相对集中,排名位次变化较大,市场竞争激烈,其中重庆、天津、成都排名上升较快,合肥、苏州、武汉等城市排名有所下滑。
第三梯队发展趋势良好,但仍有较大提升空间
排名依次为无锡、厦门、青岛、西安、珠海、郑州、福州、济南,这些城市大数据产业发展整体趋势较好,具有较大发展潜力和市场空间,需加快追赶步伐。
头部企业情况
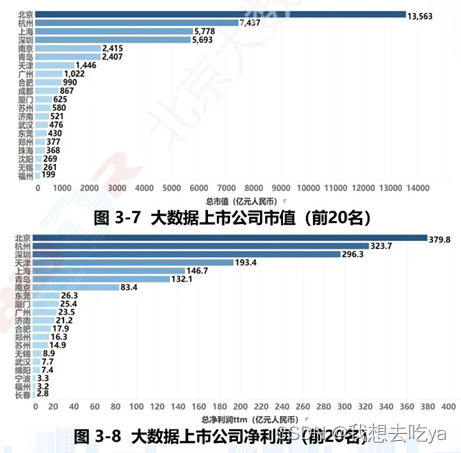
*以上截图均来源《2022年中国大数据产业发展指数报告》,如侵删
从各地大数据上市公司市值情况来看,北京以 1.356 万亿元位居榜首,成为全国唯一超万亿元的城市,其次杭州、上海、深圳紧随其后,市值超五千亿元,其中杭州为 0.744 万亿元、上海为 0.578 万亿元、深圳为 0.569 万亿元;
从上市公司净利润来看,北京、杭州、深圳、天津、上海、青岛六个城市净利润超百亿元,其中,北京、天津、上海上升势头强劲,北京超越杭州和深圳,以 379.8 亿元领先于其他城市,天津和上海均跻身百亿净利润企业俱乐部。
大数据遍地开花
如何抓住学习机会?
从《2022年中国大数据产业发展指数报告》中,我们可以看到,现在大数据相关的产业已经在各个城市发展起来,产业规模也不断在扩大,相关行业对人才的需求量也在不断增加!
据《新职业——大数据工程技术人员就业景气现状分析报告》显示,预计2025年前大数据人才需求仍保持 30%-40% 的增速,行业人才需求量达到 250 万 。
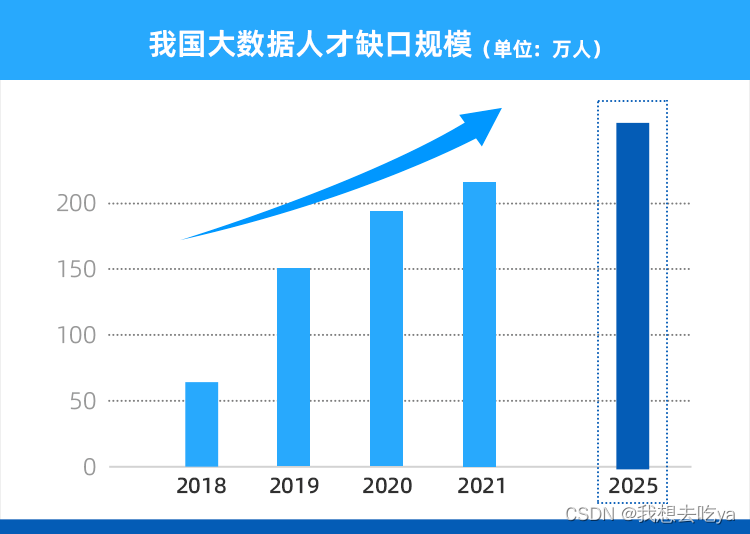
不仅招聘需求多,大数据开发人才在各大城市的就业薪资也非常可观。
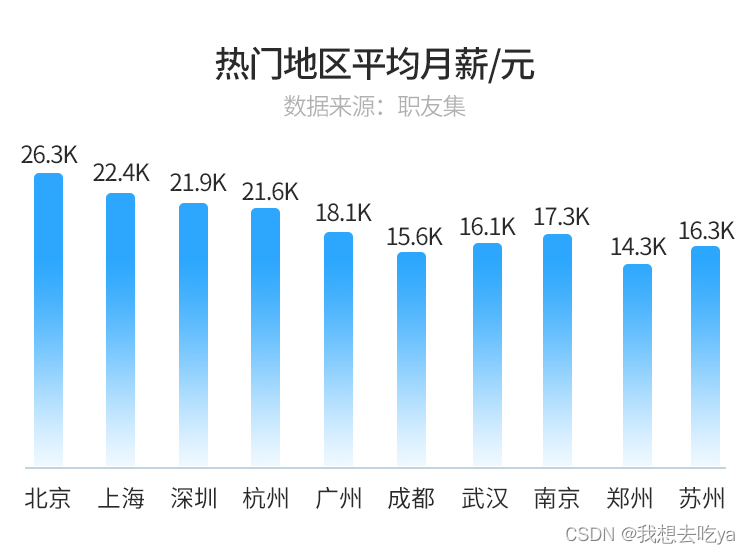
△数据来源职友集,如侵删
薪资高、缺口大,自然成为职场人的“薪”选择!
任何学习过程都需要一个科学合理的学习路线,才能够有条不紊的完成我们的学习目标。Python+大数据所需学习的内容纷繁复杂,难度较大,为大家整理了一个全面的Python+大数据学习路线图,帮大家理清思路,攻破难关!
Python+大数据学习路线图详细介绍(均为免费视频教程哈)
第一阶段 大数据开发入门
学前导读:从传统关系型数据库入手,掌握数据迁移工具、BI数据可视化工具、SQL,对后续学习打下坚实基础。
1.大数据数据开发基础MySQL8.0从入门到精通
MySQL是整个IT基础课程,SQL贯穿整个IT人生,俗话说,SQL写的好,工作随便找。本课程从零到高阶全面讲解MySQL8.0,学习本课程之后可以具备基本开发所需的SQL水平。
2022最新MySQL知识精讲+mysql实战案例_零基础mysql数据库入门到高级全套教程
第二阶段 大数据核心基础
学前导读:学习Linux、Hadoop、Hive,掌握大数据基础技术。
2022版大数据Hadoop入门教程
Hadoop离线是大数据生态圈的核心与基石,是整个大数据开发的入门,是为后期的Spark、Flink打下坚实基础的课程。掌握课程三部分内容:Linux、Hadoop、Hive,就可以独立的基于数据仓库实现离线数据分析的可视化报表开发。
2022最新大数据Hadoop入门视频教程,最适合零基础自学的大数据Hadoop教程
第三阶段 千亿级数仓技术
学前导读:本阶段课程以真实项目为驱动,学习离线数仓技术。
数据离线数据仓库,企业级在线教育项目实战(Hive数仓项目完整流程)
本课程会、建立集团数据仓库,统一集团数据中心,把分散的业务数据集中存储和处理 ;目从需求调研、设计、版本控制、研发、测试到落地上线,涵盖了项目的完整工序 ;掘分析海量用户行为数据,定制多维数据集合,形成数据集市,供各个场景主题使用。
大数据项目实战教程_大数据企业级离线数据仓库,在线教育项目实战(Hive数仓项目完整流程)
第四阶段 PB内存计算
学前导读:Spark官方已经在自己首页中将Python作为第一语言,在3.2版本的更新中,高亮提示内置捆绑Pandas;课程完全顺应技术社区和招聘岗位需求的趋势,全网首家加入Python on Spark的内容。
1.python入门到精通(19天全)
python基础学习课程,从搭建环境。判断语句,再到基础的数据类型,之后对函数进行学习掌握,熟悉文件操作,初步构建面向对象的编程思想,最后以一个案例带领同学进入python的编程殿堂。
全套Python教程_Python基础入门视频教程,零基础小白自学Python必备教程
2.python编程进阶从零到搭建网站
学完本课程会掌握Python高级语法、多任务编程以及网络编程。
Python高级语法进阶教程_python多任务及网络编程,从零搭建网站全套教程
3.spark3.2从基础到精通
Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。本课程基于Python语言学习Spark3.2开发,课程的讲解注重理论联系实际,高效快捷,深入浅出,让初学者也能快速掌握。让有经验的工程师也能有所收获。
Spark全套视频教程,大数据spark3.2从基础到精通,全网首套基于Python语言的spark教程
4.大数据Hive+Spark离线数仓工业项目实战
通过大数据技术架构,解决工业物联网制造行业的数据存储和分析、可视化、个性化推荐问题。一站制造项目主要基于Hive数仓分层来存储各个业务指标数据,基于sparkSQL做数据分析。核心业务涉及运营商、呼叫中心、工单、油站、仓储物料。
全网首次披露大数据Spark离线数仓工业项目实战,Hive+Spark构建企业级大数据平台



![[附源码]JAVA毕业设计外卖点餐系统(系统+LW)](https://img-blog.csdnimg.cn/8ddb2ed32b3749e0a4e06f685e40d890.png)


![[附源码]JAVA毕业设计微留学学生管理系统(系统+LW)](https://img-blog.csdnimg.cn/1e4d8401e9fb472ca008da1736bb0224.png)



![[附源码]JAVA毕业设计微服务的高校二手交易平台(系统+LW)](https://img-blog.csdnimg.cn/093db51fd0474c54a2187fc68086e26b.png)


![[附源码]计算机毕业设计JAVA中青年健康管理监测系统](https://img-blog.csdnimg.cn/a720e01ce73f4a9db94f9efb04146515.png)