本文主要介绍了DDR4设计方法与仿真分析,并示范SIwave如何做DDR4的瞬时眼图、SSN、on-die de-cap影响、DBI耗电分析与规范性测试。
1.DDR4和DDR3的区别
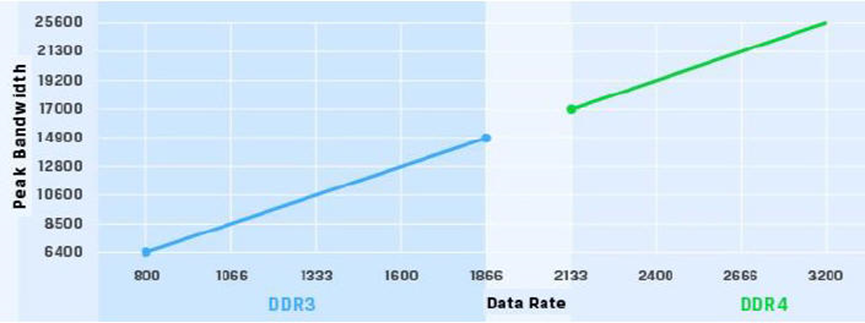
1.1 DDR4传输速度与带宽增加
DDR3 1600/1866MHz -> DDR4 1866/3200MHz
DDR3采用多点分支单流架构,DDR4采用点对点传输架构
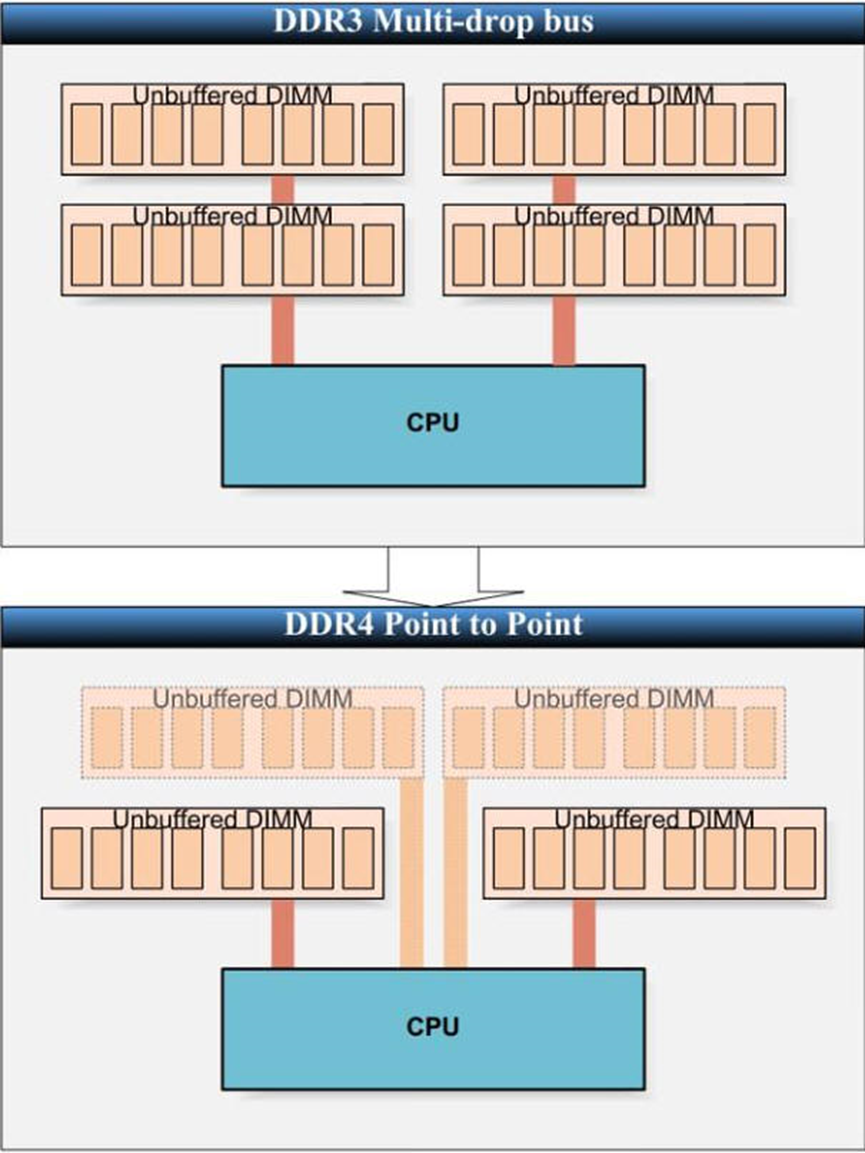
DDR3采用了大水库理论,所有数据集中到一根大水管后送出。而DDR4则采用点对点分流架构,当每一条水管流量都很大时,累加起来的流量会超过单一条大水管,能避免单条信道传输带宽的瓶颈拖慢整体效能。
现在DDR4大部分还是采用2SPC (2 Slot per Channel)或称2DPC (2 DIMM per Channel)的架构,2017 Q1最新的Intel® Core™ i7-7920HQ处理器,最快支持到DDR4 2400MHz;开发中的2666/3200MHz也是采用2SPC传输架构。
1.2 DDR4更省电
操作电压降低:DDR4(1.2V), DDR3(1.5V)。除了降低工作电压,LPDDR4支持深度省电模式(DPD, Deep Power Down Mode),DDR4支持Max Power Saving Mode,在暂时不需要用到内存的时候可进入休眠状态,可进一步减少待机时功率的消耗。
Deep Power Down Mode:SDRAM controller发送Deep Power Down命令可以将SDRAM芯片推送到一个极低功耗状态(约15uA)。这时候存储数组的power会被shutdown,也就是意味着所有的数据是丢失掉了,这时候,mode register的设定是保持的。当从Deep Power Down退出的时候,需要对SDRAM芯片进行一个完整的初始化过程。
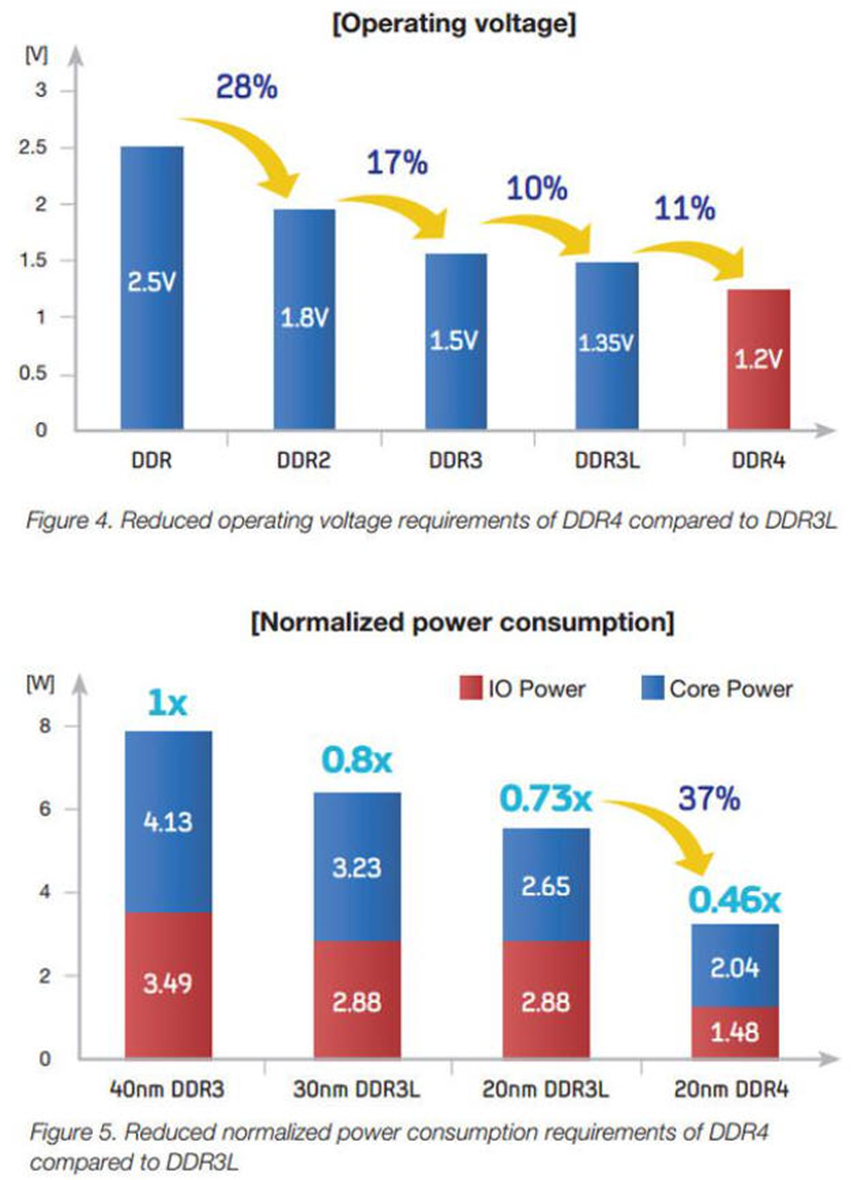
DDR4搭载了温度自更新回馈机制(TCSE,Temperature Compensated Self-Refresh),能够降低芯片在自动更新时所需耗费的电力,同时,还导入了数据汇流反转机制(DBI,Data Bus Inversion),使得VDDQ电流量得到有效控制。

DDR4使用POD(Pseudo Open Drain)接口,用以减少I/O电源消耗量。
对DDR4的IO来说,drive high时几乎不耗电的(下图右的红色虚线电流路径),这就是为何采用DBI+POD机制具有优势的原因。
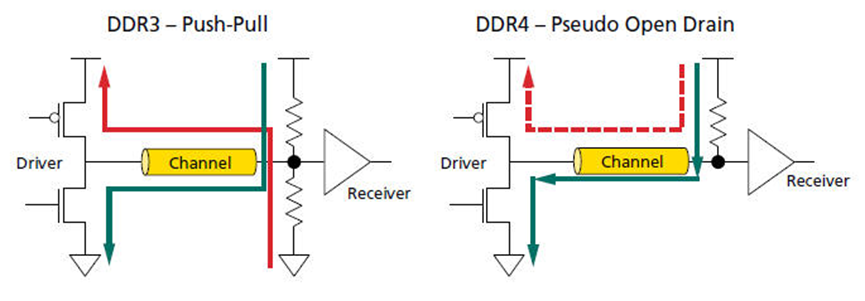
DDR4虽然drive high的时候不耗电,但是在drive low的时候会消耗相比于SSTL两倍的电。所以,省电的关键在于较少输出0的数量。如果将要输出的数据bus上0比1多,DDR4会将数据翻转以达到降低功耗的目的。
1.3 DDR4高速讯号传输技术
-- I/O 技术不同:
DDR3采用SSTL,Vref=VDDQ/2;DDR4采用PODL,Vref不是固定的,会随VDDQ的AC变动而变动Vref=((2Rs+Rt)/(Rs+Rt))*VDDQ/2。
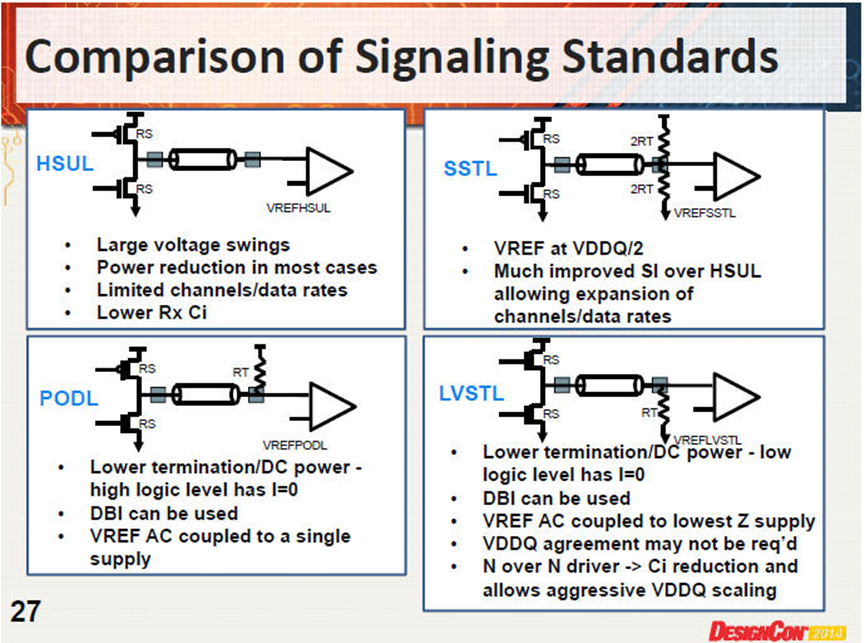
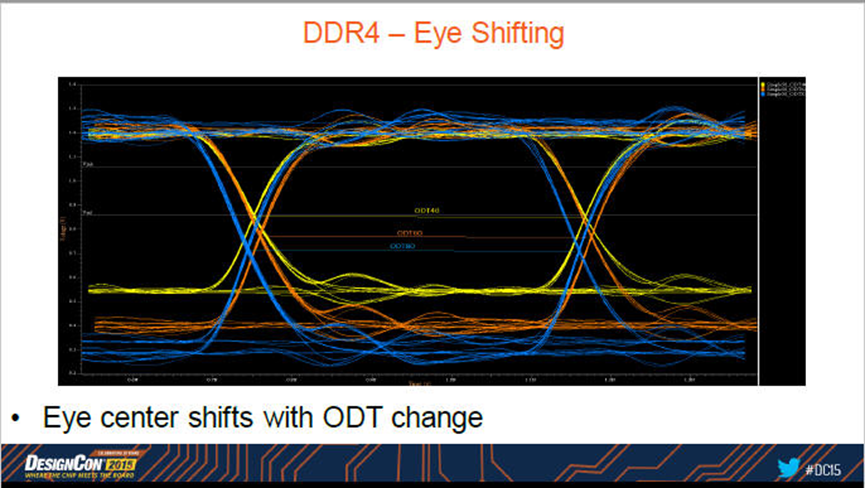
-- ODT眼图特征不同:
请注意下图是DQ的眼图,而不是DQS pair的眼图,前者DDR4眼图的crossover中心才会随ODT强度而变化。


-- DDR4增加了DBI(Data Bus Inversion)、CRC(Cyclic Redundancy Check)、CA parity等功能,让DDR4内存在更快速与更省电的同时亦能改善数据传输及储存的可靠性。
-- 对于2933/3200的支持,CPU/DIMM在DQ上都增加了EQ (CTLE),但是CAC (Command/Address/CTL)上,暂时还没有EQ,虽然其速率比DQ低,但是在DIMM卡上Diasy Chain 的结构 CTL有9 loads,Command/Address有36个loads,所以CAC的高速设计,对于UDIMM和SODIMM来说,更是一个很大的挑战。对于CAC,目前都是在DIMM最末端用电阻端接到Vtt来做终端 。
1.4 其他
DDR4 新增了4 个Bank Group 数据组的设计,Bnak Group可以选择2个或4个独立分组,而DDR4模块内的每单位Bnak Group都可独立进行读取、写入、唤醒及更新等动作。Bank Group 数据组可套用多任务的观念来想象,亦可解释为DDR4 在同一频率工作周期内,至多可以处理4 笔数据,效率明显好过于DDR3。又DDR4 虽然增加内存组数(bank)为 16,但却加入内存群组(bank group)的限制。不同 bank 但若属于同一个 bank group,连续读写指令间必须增加等待时间周期,造成数据总线的闲置机率升高,传输效能降低。在此种限制下,如何充分利用数据总线以达成最高效率,对于控制 DDR4 的逻辑电路设计是新的挑战。
由于以上因素,DDR3与DDR4不能混用(工作电压与防呆插槽的设计都不同)。
2.DDR4设计方法
DDR4的设计方法,其实与DDR3雷同,只是速度更快,设计要求更高。早从DDR3时代开始,从主控IC->PCB->内存整条信道,基于"3D结构"的角度考虑信道间耦合(inter-channel coupling)、因为回路(return path)的影响考虑封装的ball map与ball下方的slot、SI+PI的仿真...。
以下是一个欠佳的设计范例:

以下是优化后的设计范例:
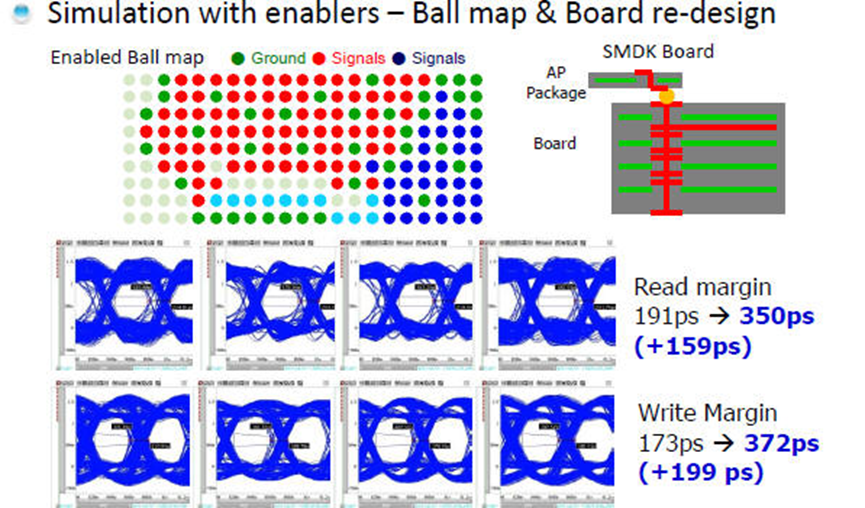
这里为什么选择Via Stub较长的做法反而SI会比较好呢?这是考验所学的SI设计知识是否活用的好机会,想不出来的请参阅下面的2.4.1
2.1 3D封装(SiP,PoP,TSV,InFO)
2.1.1 Traditional 3D Packaging Technologies:SiP and PoP

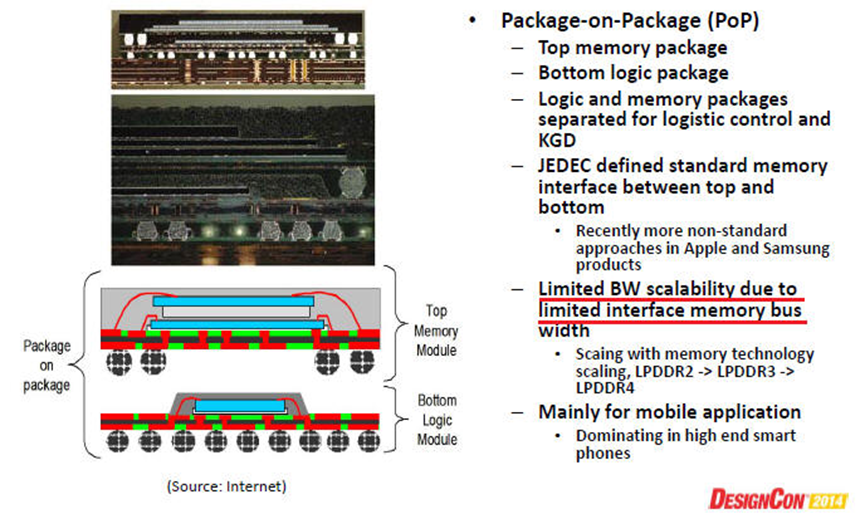
POP用于中高端,MCP(Sip)用于低端到中端
2.1.2 基于TSV的3D封装新技术:用于宽IO DRAM和高带宽存储器
TSV硅穿孔技术因为成本高,良率与散热问题不易处理,有兴趣的人请自行参考数据。
2.1.3 TSMC's InFO (Integrated FanOut)
一般的Fan-Out技术:

TSMC的Fan-Out技术:

2.2 IC的PI优化
早从DDR3时代开始,on-die de-cap摆放的大小,已经成为速度上不去的关键。记得数年前刚从DDR2转DDR3的年代,几家国内知名的IC设计公司,明明已经打开过别人IC看过,里面就是放一堆on-die de-cap,但就是不愿意把on-die de-cap加大,被cost-down的死脑筋卡关,拼命想着如何在封装与PCB层级内改善,最后还是徒劳无功。唉...这样的例子在业界屡见不鲜。
Micron DDR4甚至直接告诉你他on-die电容放多少(写在IBIS\SPICE quality report内),真是佛心来的,大厂的风范与格局就是不同。

对于DDR3,美光on-die de-cap加522pF per DQ/DQS。但对于DDR4,美光on-die de-cap加484pF per DQ/DQS。
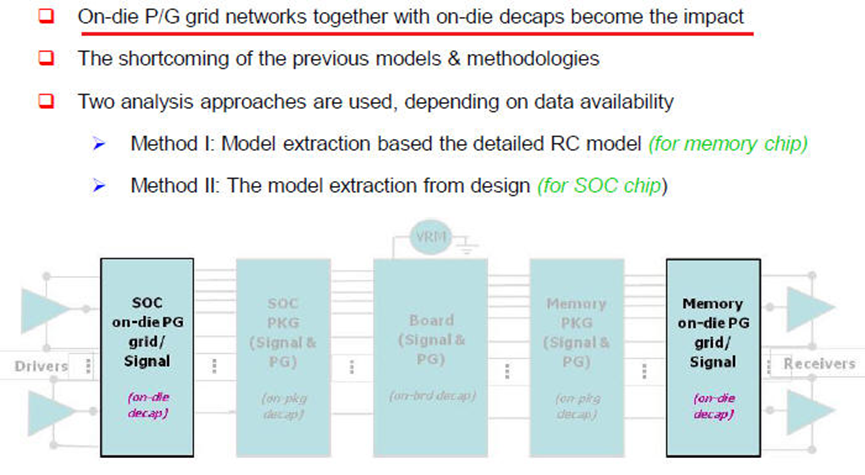
2.3 系统的PI优化
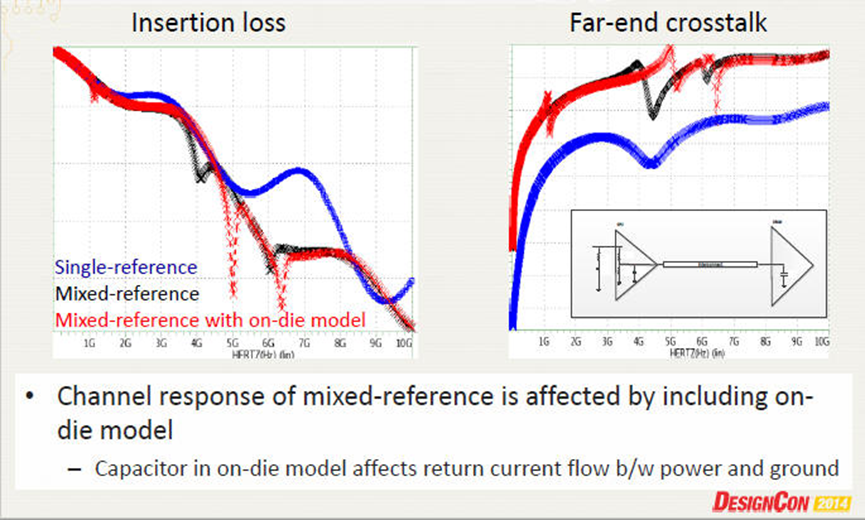
如果从IC->封装->PCB都有抽取model正确的考虑,模拟的准确度是非常高的,不论是高速讯号或是EMI干扰的问题都可以有效分析 。
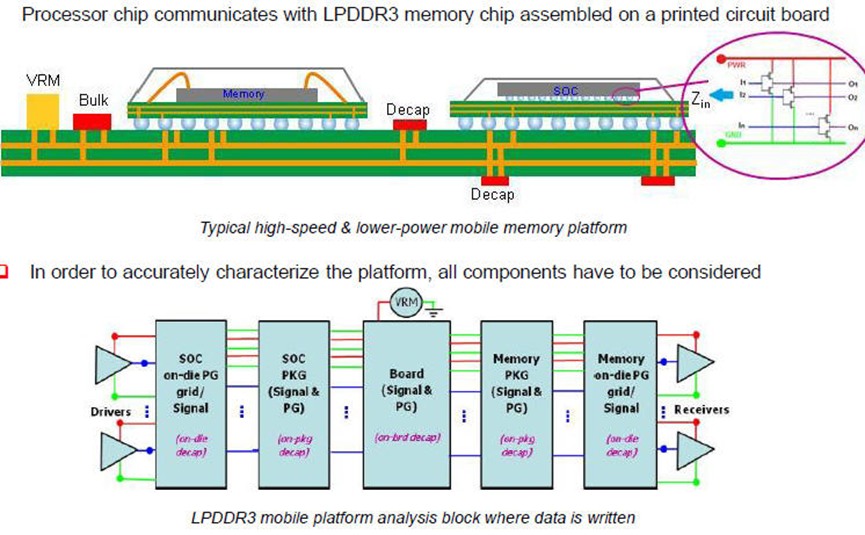

从下图中可以看出,百MHz的de-cap靠PCB叠层的设计,在P/G层之间的平板电容,而GHz以上的de-cap必须要靠on-die de-cap。
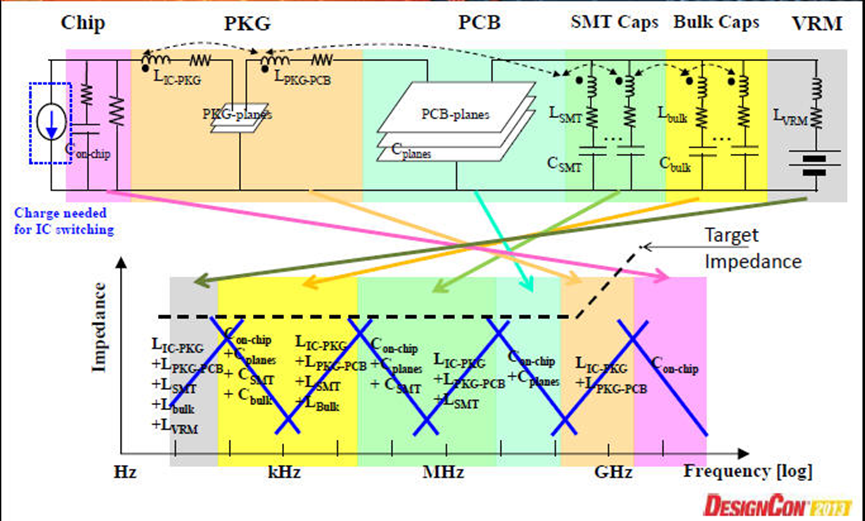
2.4 系统的SI优化
2.4.1在DesignCon2013由Samsung所发表的LPDDR3优化设计中,与在DesignCon2015由Xilinx所发表的DDR4 2400优化设计中,我们不约而同地看到了选择via导通长度较短(shorter via effective length, but longer via stub)的设计,得到较好的DDR SI特性。
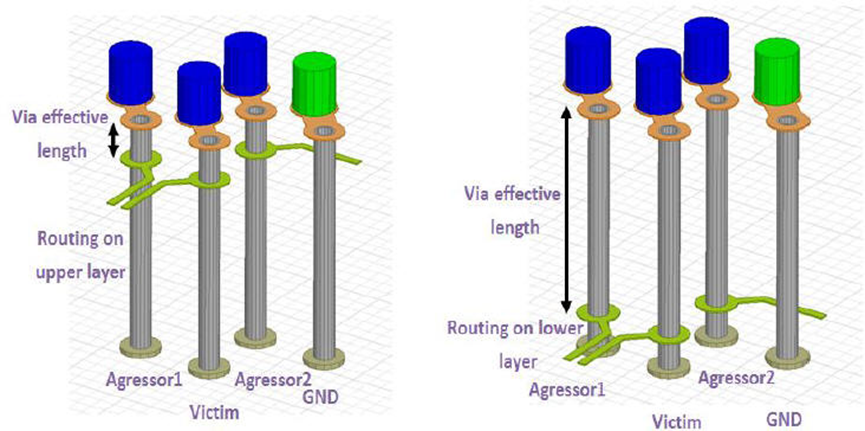
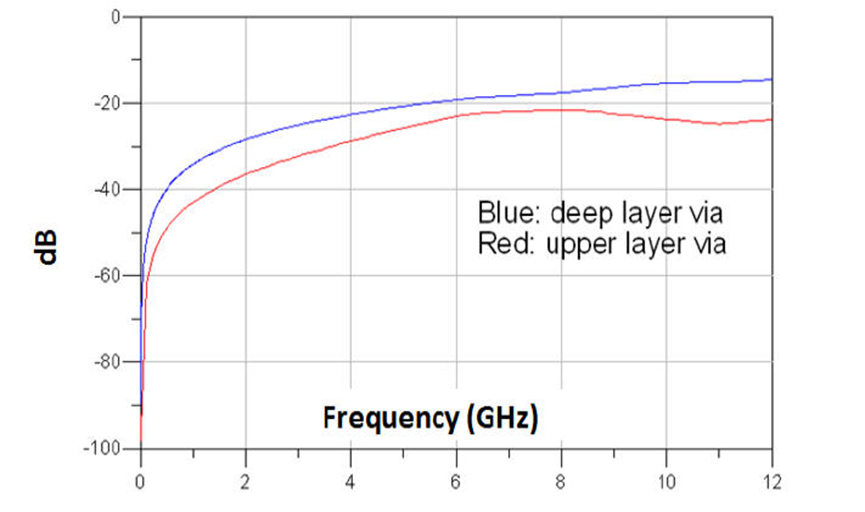
这是因为,在via barrel结构上,讯号经过的部份(via effective length)贡献串联电感效应,而讯号没经过的部分(via stub)贡献电容效应,这两者是相互trade-off的。基于不同的板厚与传输速度带宽考虑,有时是以短的via effective length较佳,有时则以短的via stub较佳。
在DDR4的设计中,大部分时候,via stub并不是起主要作用,而via之间的crosstalk则是很重要的一个因素。
2.4.2减少因讯号换层引起的回路不连续,也是一个重要的方面。

2.4.3对于DDR4 3200,甚至DDR5的DQ都还是维持以单端讯号(Single-end)的方式传送,如何减少crosstalk也是很关键。
减少讯号线走线间的crosstalk – 保持间距, 保持2~3W比起插入保护地线在layout空间上较可行。

同时,也应减少因跨地引起的crosstalk :
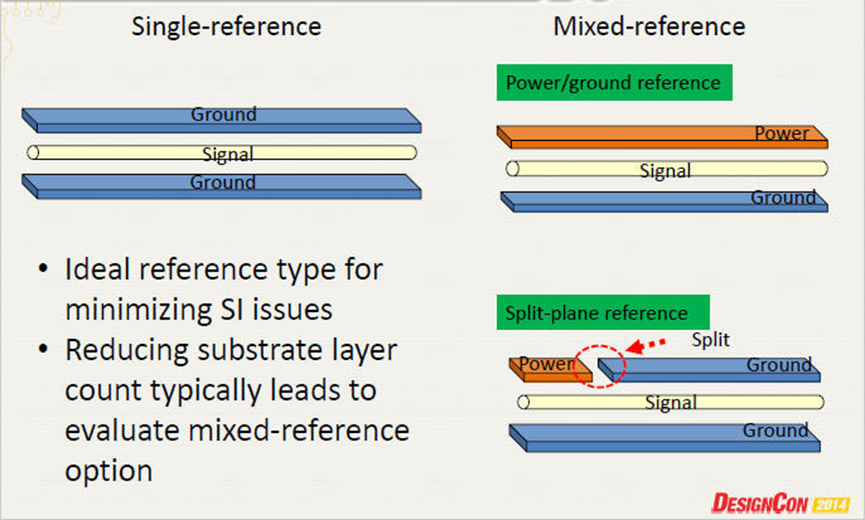
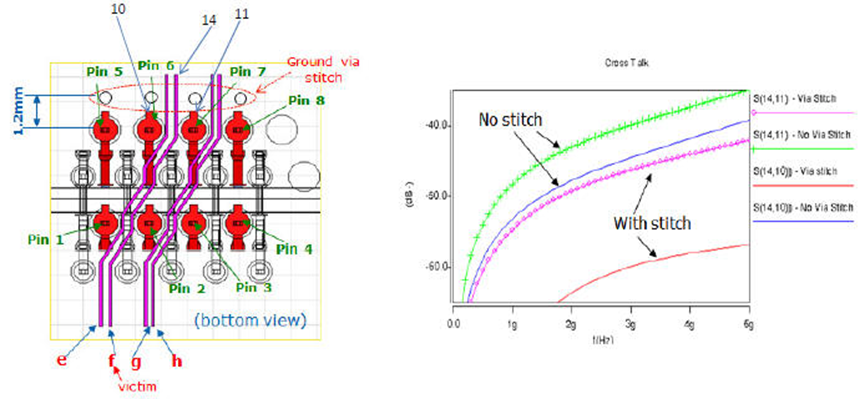
减少DIMM connector与memory buffer routing间的crosstalk -- 在连接器焊盘旁边添加接地过孔:

【未完待续】