首先,搭建网络:
AlexNet神经网络原理图:


net代码:【根据网络图来搭建网络,不会的看看相关视频会好理解一些】
import torchfrom torch import nnimport torch.nn.functional as Fclass MyAlexNet(nn.Module):def __init__(self):super(MyAlexNet, self).__init__()#继承self.c1 = nn.Conv2d(in_channels=3, out_channels=48, kernel_size=11, stride=4, padding=2)#搭建第一层网络,输入通道3层,输出通道48,核11self.ReLU = nn.ReLU()#激活函数self.c2 = nn.Conv2d(in_channels=48, out_channels=128, kernel_size=5, stride=1, padding=2)#上面输出48,下面输入也是48,输出125,卷积核5self.s2 = nn.MaxPool2d(2)#池化层self.c3 = nn.Conv2d(in_channels=128, out_channels=192, kernel_size=3, stride=1, padding=1)self.s3 = nn.MaxPool2d(2)self.c4 = nn.Conv2d(in_channels=192, out_channels=192, kernel_size=3, stride=1, padding=1)self.c5 = nn.Conv2d(in_channels=192, out_channels=128, kernel_size=3, stride=1, padding=1)self.s5 = nn.MaxPool2d(kernel_size=3, stride=2)self.flatten = nn.Flatten()#平展层self.f6 = nn.Linear(4608, 2048)self.f7 = nn.Linear(2048, 2048)self.f8 = nn.Linear(2048, 1000)self.f9 = nn.Linear(1000, 2)#输出二分类网络def forward(self, x):x = self.ReLU(self.c1(x))x = self.ReLU(self.c2(x))x = self.s2(x)#池化层x = self.ReLU(self.c3(x))x = self.s3(x)x = self.ReLU(self.c4(x))x = self.ReLU(self.c5(x))x = self.s5(x)x = self.flatten(x)#平展层x = self.f6(x)x = F.dropout(x, p=0.5)#防止过拟合,有50%的网络随机失效x = self.f7(x)x = F.dropout(x, p=0.5)x = self.f8(x)x = F.dropout(x, p=0.5)x = self.f9(x)return xif __name__ == '__mian__':x = torch.rand([1, 3, 224, 224])#张量形式数组model = MyAlexNet()y = model(x)
测试一下这个网络:

划分数据集:(8:2)(spilit_data)
import osfrom shutil import copyimport randomdef mkfile(file):if not os.path.exists(file):os.makedirs(file)# 获取data文件夹下所有文件夹名(即需要分类的类名)file_path = 'D:/Users/Twilight/PycharmProjects/AlexNet/data_name'flower_class = [cla for cla in os.listdir(file_path)]# 创建 训练集train 文件夹,并由类名在其目录下创建5个子目录mkfile('data/train')for cla in flower_class:mkfile('data/train/' + cla)# 创建 验证集val 文件夹,并由类名在其目录下创建子目录mkfile('data/val')for cla in flower_class:mkfile('data/val/' + cla)# 划分比例,训练集 : 验证集 = 8:2split_rate = 0.2# 遍历所有类别的全部图像并按比例分成训练集和验证集for cla in flower_class:cla_path = file_path + '/' + cla + '/' # 某一类别的子目录images = os.listdir(cla_path) # iamges 列表存储了该目录下所有图像的名称num = len(images)eval_index = random.sample(images, k=int(num * split_rate)) # 从images列表中随机抽取 k 个图像名称for index, image in enumerate(images):# eval_index 中保存验证集val的图像名称if image in eval_index:image_path = cla_path + imagenew_path = 'data/val/' + clacopy(image_path, new_path) # 将选中的图像复制到新路径# 其余的图像保存在训练集train中else:image_path = cla_path + imagenew_path = 'data/train/' + clacopy(image_path, new_path)print("\r[{}] processing [{}/{}]".format(cla, index + 1, num), end="") # processing barprint()print("processing done!")

生成的新的文件夹:

由于数据集量太大,划分完了我还删了很多图片,我的data里面只有1000张,训练集猫狗分别400,测试集猫狗分别100。【跑不动根本跑不动】
训练代码:(train)
import torchfrom torch import nnfrom net import MyAlexNetimport numpy as npfrom torch.optim import lr_schedulerimport osfrom torchvision import transformsfrom torchvision.datasets import ImageFolderfrom torch.utils.data import DataLoaderimport matplotlib.pyplot as plt# 解决中文显示问题(乱码)plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = FalseROOT_TRAIN = r'D:/Users/Twilight/PycharmProjects/AlexNet/data/train'#数据集路径训练集ROOT_TEST = r'D:/Users/Twilight/PycharmProjects/AlexNet/data/val'# 将图像的像素值归一化到【-1, 1】之间normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])#train_transform = transforms.Compose([#训练集transforms.Resize((224, 224)),#224*224transforms.RandomVerticalFlip(),#随机垂直transforms.ToTensor(),#转化为张量normalize])#归一化val_transform = transforms.Compose([#验证集transforms.Resize((224, 224)),transforms.ToTensor(),normalize])train_dataset = ImageFolder(ROOT_TRAIN, transform=train_transform)val_dataset = ImageFolder(ROOT_TEST, transform=val_transform)train_dataloader = DataLoader(train_dataset, batch_size=4, shuffle=True)#批次32,打乱val_dataloader = DataLoader(val_dataset, batch_size=4, shuffle=True)device = 'cuda' if torch.cuda.is_available() else 'cpu'#数据导入显卡里面model = MyAlexNet().to(device)#把数据送到神经网络中,然后输到显卡里面# 定义一个损失函数loss_fn = nn.CrossEntropyLoss()# 定义一个优化器optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)#随机梯度下降法,把模型参数传给优化器,学习率0.01# 学习率每隔10轮变为原来的0.5lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)# 定义训练函数def train(dataloader, model, loss_fn, optimizer):#数据,模型,学习率,优化器传入loss, current, n = 0.0, 0.0, 0#指示器for batch, (x, y) in enumerate(dataloader):image, y = x.to(device), y.to(device)output = model(image)#进行训练cur_loss = loss_fn(output, y)#看误差_, pred = torch.max(output, axis=1)#_代表不关心返回的最大值是多少。只需要得到predcur_acc = torch.sum(y==pred) / output.shape[0]#算精确率# 反向传播optimizer.zero_grad()#梯度降为0cur_loss.backward()#反向传播optimizer.step()#更新梯度loss += cur_loss.item()#Loss值累加起来(一轮很多批次)current += cur_acc.item()#准确度加起来n = n+1#轮train_loss = loss / n#计算这一轮学习的学习率(每一批的)train_acc = current / nprint('train_loss' + str(train_loss))print('train_acc' + str(train_acc))#训练精确的return train_loss, train_acc#返回后面可视化用# 定义一个验证函数def val(dataloader, model, loss_fn):# 将模型转化为验证模型model.eval()loss, current, n = 0.0, 0.0, 0with torch.no_grad():for batch, (x, y) in enumerate(dataloader):image, y = x.to(device), y.to(device)output = model(image)cur_loss = loss_fn(output, y)_, pred = torch.max(output, axis=1)cur_acc = torch.sum(y == pred) / output.shape[0]loss += cur_loss.item()current += cur_acc.item()n = n + 1val_loss = loss / nval_acc = current / nprint('val_loss' + str(val_loss))print('val_acc' + str(val_acc))return val_loss, val_acc# 定义画图函数def matplot_loss(train_loss, val_loss):plt.plot(train_loss, label='train_loss')plt.plot(val_loss, label='val_loss')plt.legend(loc='best')plt.ylabel('loss')plt.xlabel('epoch')plt.title("训练集和验证集loss值对比图")plt.show(block=True)def matplot_acc(train_acc, val_acc):plt.plot(train_acc, label='train_acc')plt.plot(val_acc, label='val_acc')plt.legend(loc='best')plt.ylabel('acc')plt.xlabel('epoch')plt.title("训练集和验证集acc值对比图")plt.show(block=True)# 开始训练loss_train = []acc_train = []loss_val = []acc_val = []epoch = 20 #20轮min_acc = 0for t in range(epoch):lr_scheduler.step()#每十步分析一下学习率print(f"epoch{t+1}\n-----------")train_loss, train_acc = train(train_dataloader, model, loss_fn, optimizer)val_loss, val_acc = val(val_dataloader, model, loss_fn)loss_train.append(train_loss)#写到集合里头acc_train.append(train_acc)loss_val.append(val_loss)acc_val.append(val_acc)# 保存最好的模型权重if val_acc >min_acc:#如果模型精确度大于0folder = 'save_model'if not os.path.exists(folder):#如果文件夹不存在os.mkdir('save_model')#生成min_acc = val_accprint(f"save best model, 第{t+1}轮")torch.save(model.state_dict(), 'save_model/best_model.pth')# 保存最后一轮的权重文件if t == epoch-1:torch.save(model.state_dict(), 'save_model/last_model.pth')matplot_loss(loss_train, loss_val)matplot_acc(acc_train, acc_val)print('Done!')

最好的模型保存,嘻嘻。
生成的loss、acc图:

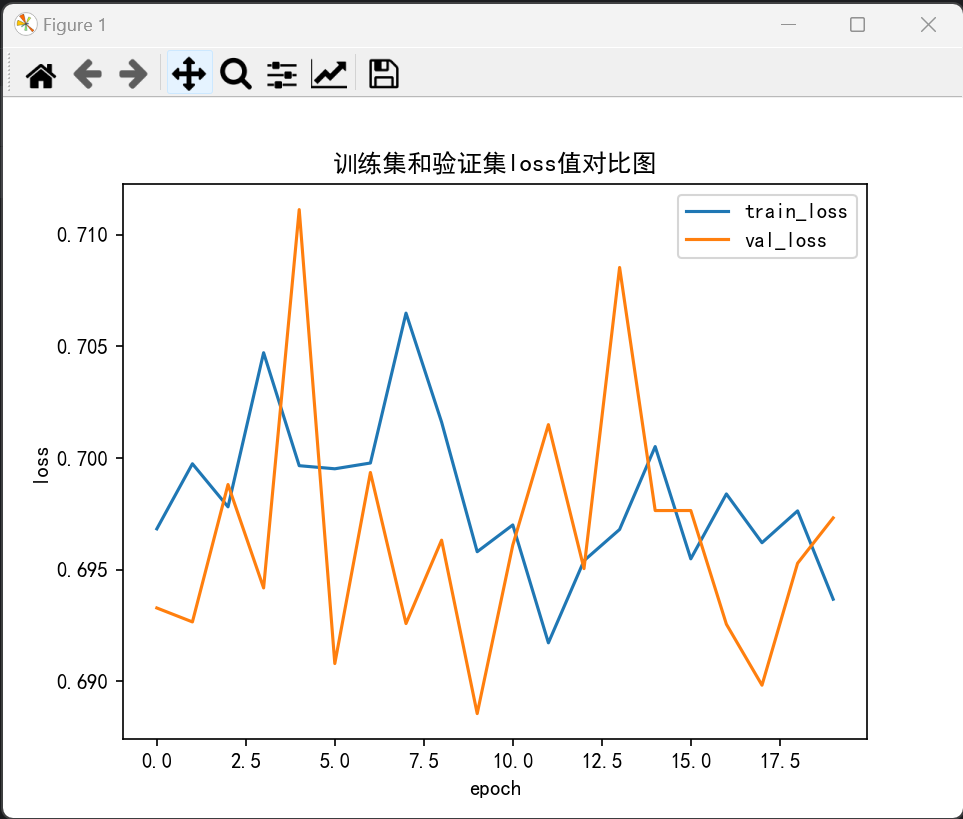
(效果其实是非常不好的,因为数据量太少了哈哈,然后参数某些地方也可以再调一下)
测试代码(test)
import torchfrom net import MyAlexNetfrom torch.autograd import Variablefrom torchvision import datasets, transformsfrom torchvision.transforms import ToTensorfrom torchvision.transforms import ToPILImagefrom torchvision.datasets import ImageFolderfrom torch.utils.data import DataLoaderROOT_TRAIN = r'D:/Users/Twilight/PycharmProjects/AlexNet/data/train'#数据集路径训练集ROOT_TEST = r'D:/Users/Twilight/PycharmProjects/AlexNet/data/val'# 将图像的像素值归一化到【-1, 1】之间normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])train_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.RandomVerticalFlip(),transforms.ToTensor(),normalize])val_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),normalize])train_dataset = ImageFolder(ROOT_TRAIN, transform=train_transform)#变张量val_dataset = ImageFolder(ROOT_TEST, transform=val_transform)train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=True)device = 'cuda' if torch.cuda.is_available() else 'cpu'model = MyAlexNet().to(device)# 加载模型model.load_state_dict(torch.load("D:/Users/Twilight/PycharmProjects/AlexNet/save_model/best_model.pth"))# 获取预测结果classes = ["cat","dog",]# 把张量转化为照片格式,后面可视化show = ToPILImage()# 进入到验证阶段model.eval()for i in range(10):#验证前十张x, y = val_dataset[i][0], val_dataset[i][1]show(x).show()x = Variable(torch.unsqueeze(x, dim=0).float(), requires_grad=True).to(device)#把值传入到显卡里面x = torch.tensor(x).to(device)with torch.no_grad():pred = model(x)predicted, actual = classes[torch.argmax(pred[0])], classes[y]print(f'predicted:"{predicted}", Actual:"{actual}"')