曝光调整论文调研
M. Afifi, K. G. Derpanis, B. Ommer and M. S. Brown, “Learning Multi-Scale Photo Exposure Correction,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 2021, pp. 9153-9163, doi: 10.1109/CVPR46437.2021.00904.
- 这是2021CVPR的一篇论文,提出了一个新的数据集和一个新的模型,来进行图像曝光调整。将曝光调整分为两个子问题,一个是颜色增强,一个是细节增强。
- 数据集用的是fivek提供的5000张raw data,用不同的EV值render成为不同曝光水平的图像,用fivek提供的专家retouch的结果作为GT。丢掉了一些和GT配不准的图像,所以最终有24330张多曝光图像。
- 网络结构如下图所示
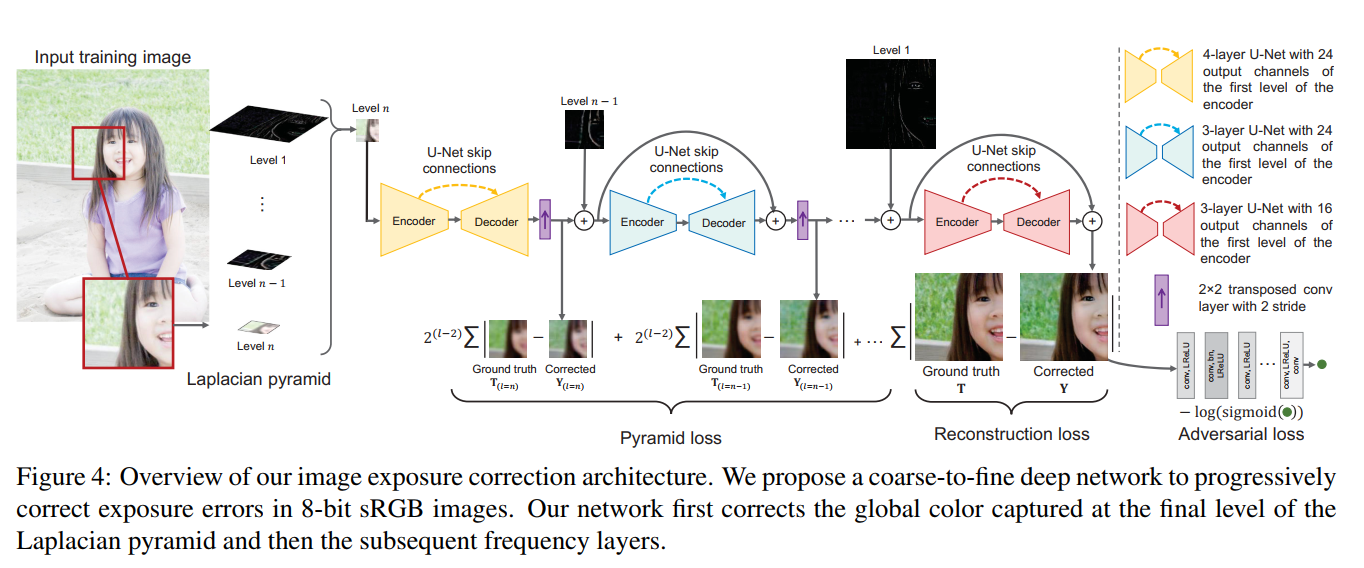
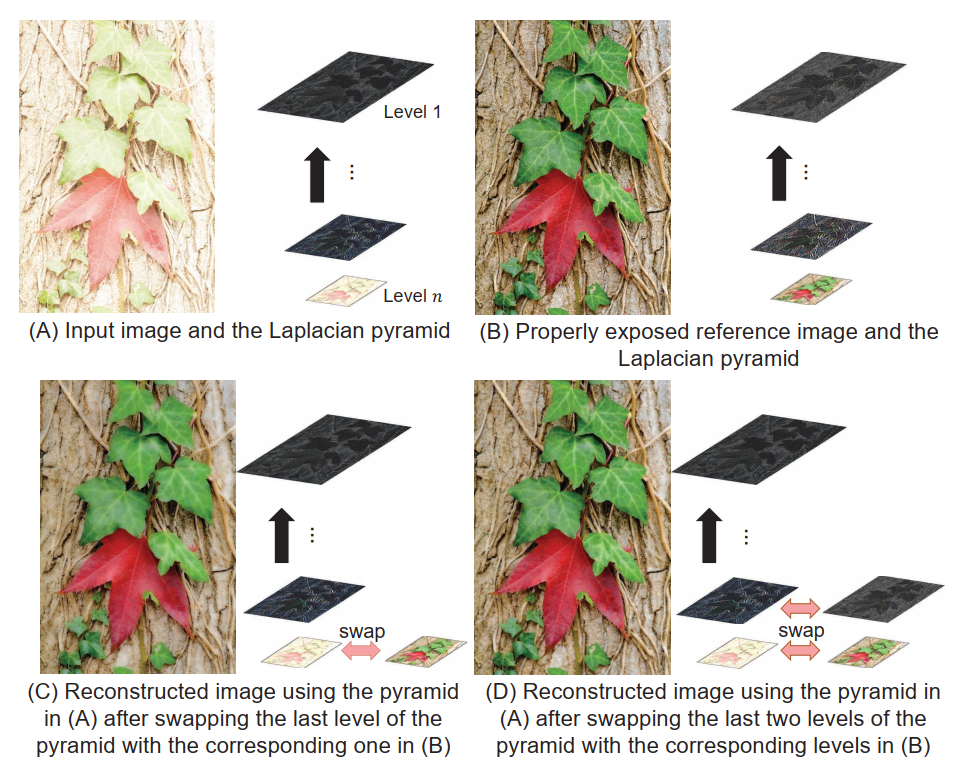
- 图片一目了然了已经。先求图像的laplacian pyramid作为网络的输入,之所以说颜色增强和细节增强,是任务laplacian金字塔的第n层代表颜色信息,所以第一个网络是做颜色增强的,后面每一个网络都在添加细节。这一动机是基于如下图的观察:交换laplacian 金字塔的不同层,产生的效果可以看出第n层对应着颜色,其他层对应着细节。
- 损失函数由三部分组成,由于是有监督任务,所以其实基本就是算增强结果
Y
Y
Y和GT
T
T
T之间的距离。三个损失分别是增强结果与GT的L1距离,不同stage的中间增强结果与GT的Gaussian pyramid不同level的图片的L1距离,以及增强结果的对抗损失:
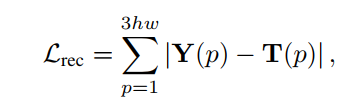

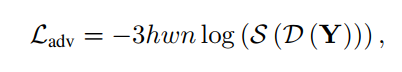
- 模型是多尺度递进训练的,首先在128x128上训练,然后在256x256上训练,最后在512x512上训练。而且模型训练的一开始没有加adv损失,在收敛阶段再添加的adv损失,这个技巧可能还挺重要的。从实验结果上看,虽然在暗图增强比不过别人,但在过曝抑制和多曝光调整上表现很好:
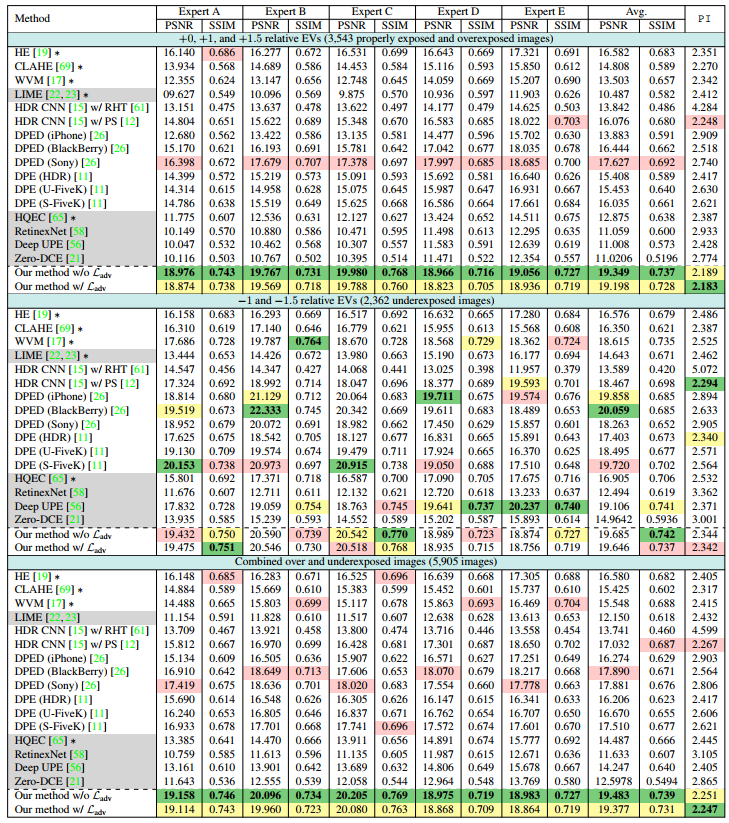

- 也有失败的结果,可以看到过饱和区域的信息丢失导致网络复原不出来了:

Ma L, Ma T, Xue X, et al. Practical Exposure Correction: Great Truths Are Always Simple[J]. arXiv preprint arXiv:2212.14245, 2022.
- 这是大连理工大学马龙博士的一篇arxiv上的论文,应该是还没发表的,用非深度学习方法做的曝光校正,提出了一个迭代的算法。
- 首先定义了一个exposure adversarial function:
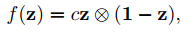
这个函数的性质是越接近0.5越大,从而可以配合下面定义的补偿函数,即图中越接近0.5的区域改变越大,从而实现过曝和欠曝区域的对比度拉伸:
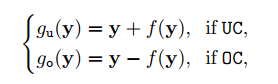
- 进一步地,可以对增强结果进行迭代,公式如下:
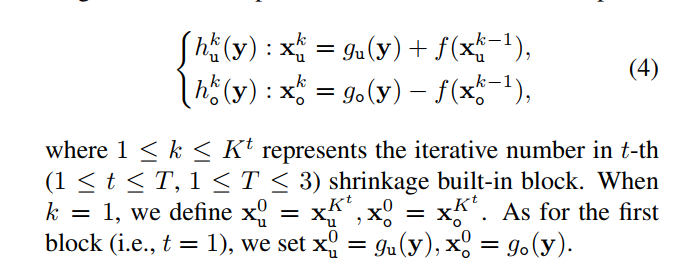
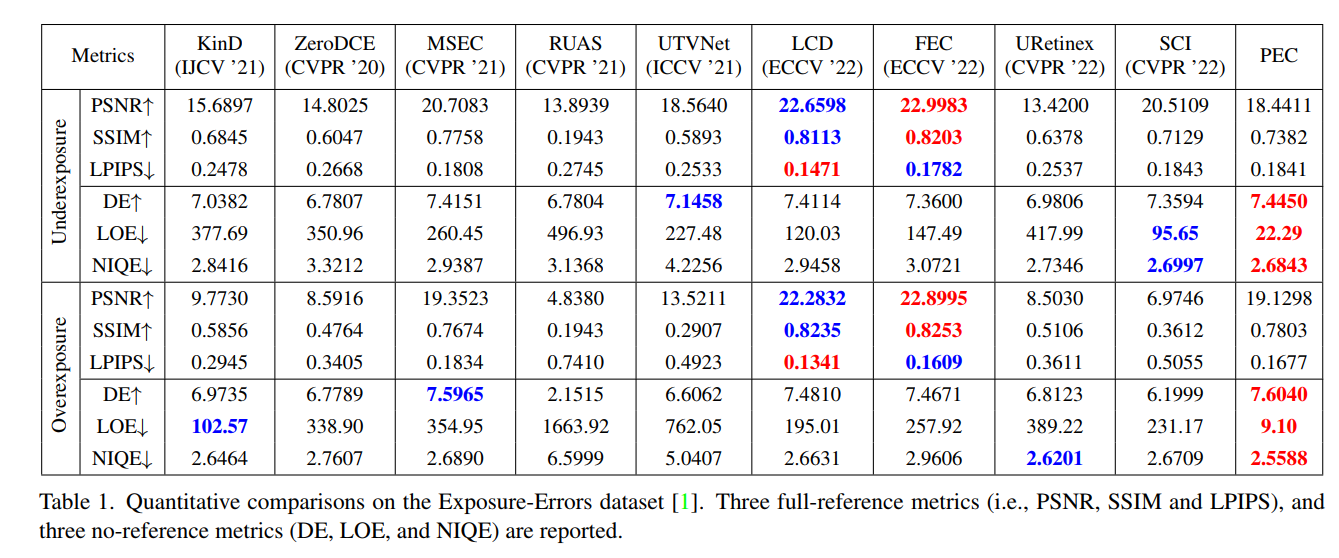
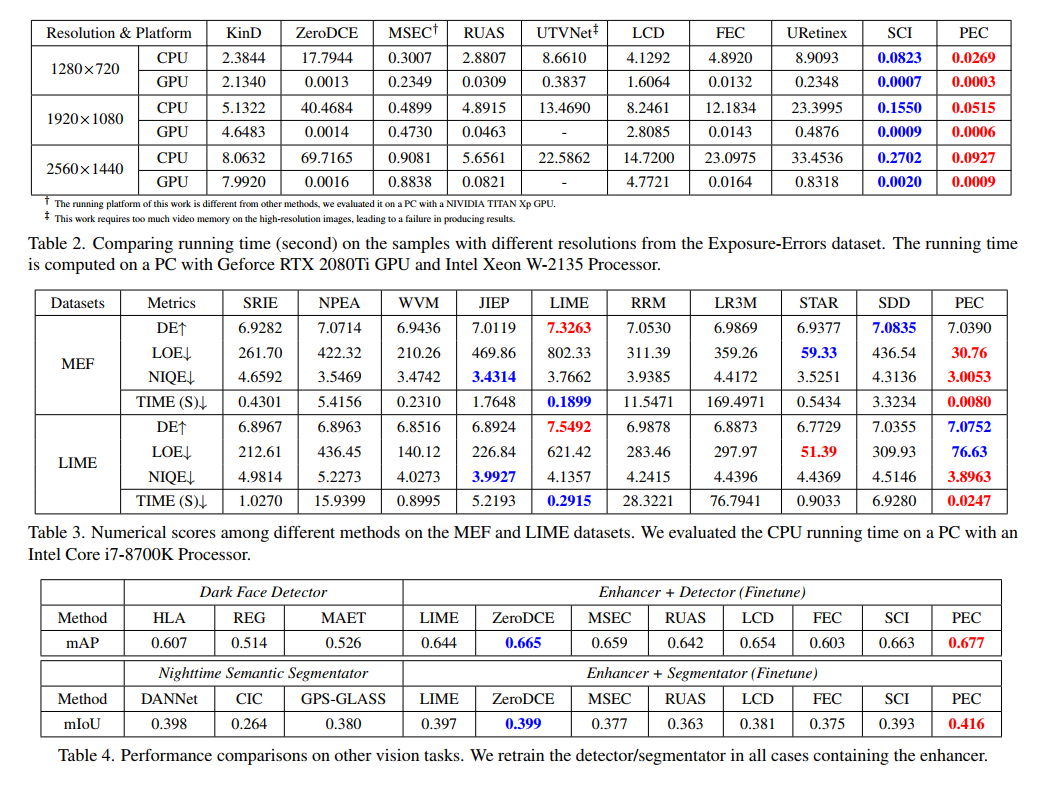
- 实验结果可以看到这一算法的无参考图像指标(在exposure error数据集和LIME MEF数据集上都测了)还不错,运行速度也很快,还在黑暗环境下的人脸目标检测和语义分割任务上提升了性能(虽然没有提用的是什么检测器):
- 也给出了在SICE数据集上的可视化效果:

- 总体看,效果是很不错的。不过我在想,迭代的方式,反正公式是写死的,也没有优化步骤,是不是可以推导一下一步到位?以及,这一公式处理背光图像如何?
Y. Niu, J. Wu, W. Liu, W. Guo and R. W. H. Lau, “HDR-GAN: HDR Image Reconstruction From Multi-Exposed LDR Images With Large Motions,” in IEEE Transactions on Image Processing, vol. 30, pp. 3885-3896, 2021, doi: 10.1109/TIP.2021.3064433.
- 这是2021年TIP的一篇有监督多曝光图像融合的论文。值得注意的是这里的多曝光图像是多次拍摄的,也就是说图像之间存在移动。
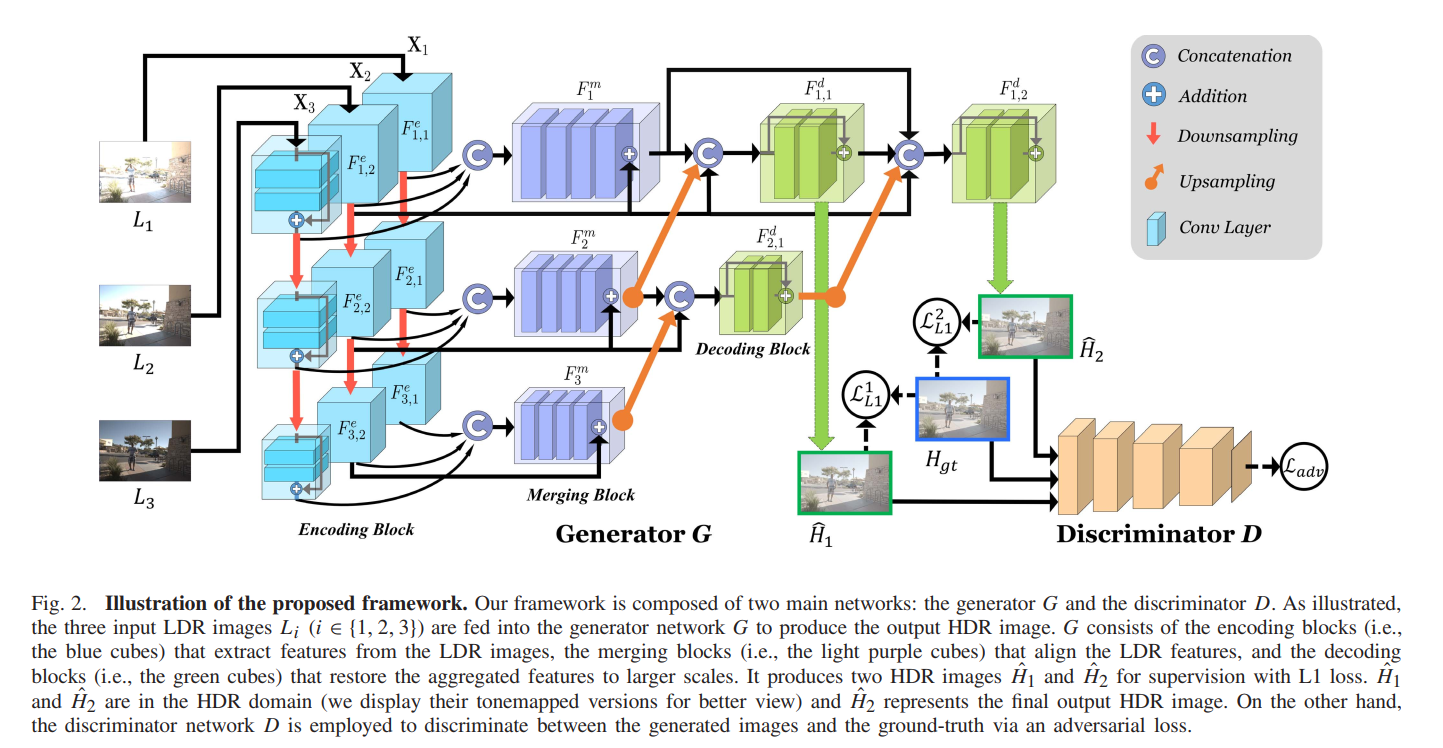
- 网络结构如下图所示:
- 网络的输入是按如下公式构建的,其中
L
i
L_i
Li表示输入的图片,即对输入的图片做gamma校正后除以曝光时间,然后和原图concatenate在一起:
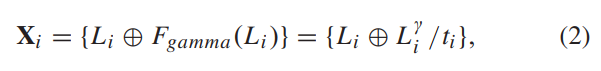
- 三张不同的曝光水平的图片分别提取特征后concatenate到一起,在网络的最后两层会分别产生两个增强结果,这两个增强结果都要用来算损失。三张图片会选一张作为reference image,其前面单独产生的特征会被作为残差跳层连接到后面的特征图中。网络采取有监督训练的范式,每三张图有一张对应的GT图像作为HDR image,损失函数如下,其中
H
^
1
\hat H_1
H^1和
H
^
2
\hat H_2
H^2分别表示网络最后两层产生的两个增强结果:
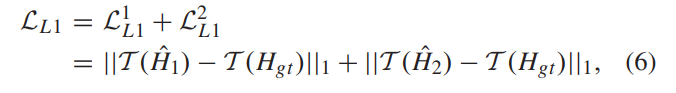
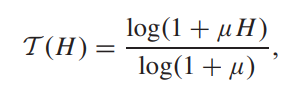
- 除此之外还有GAN的损失,所以总的损失如下:

- 文章是在HDR数据集上训练和测试的。可以看到其实没有办法解决背光问题,仅仅是对整张图片的EV做了调整,这也是数据集本身设计的原因:

K. Wu, J. Chen, Y. Yu and J. Ma, “ACE-MEF: Adaptive Clarity Evaluation-Guided Network with Illumination Correction for Multi-exposure Image Fusion,” in IEEE Transactions on Multimedia, doi: 10.1109/TMM.2022.3233299.
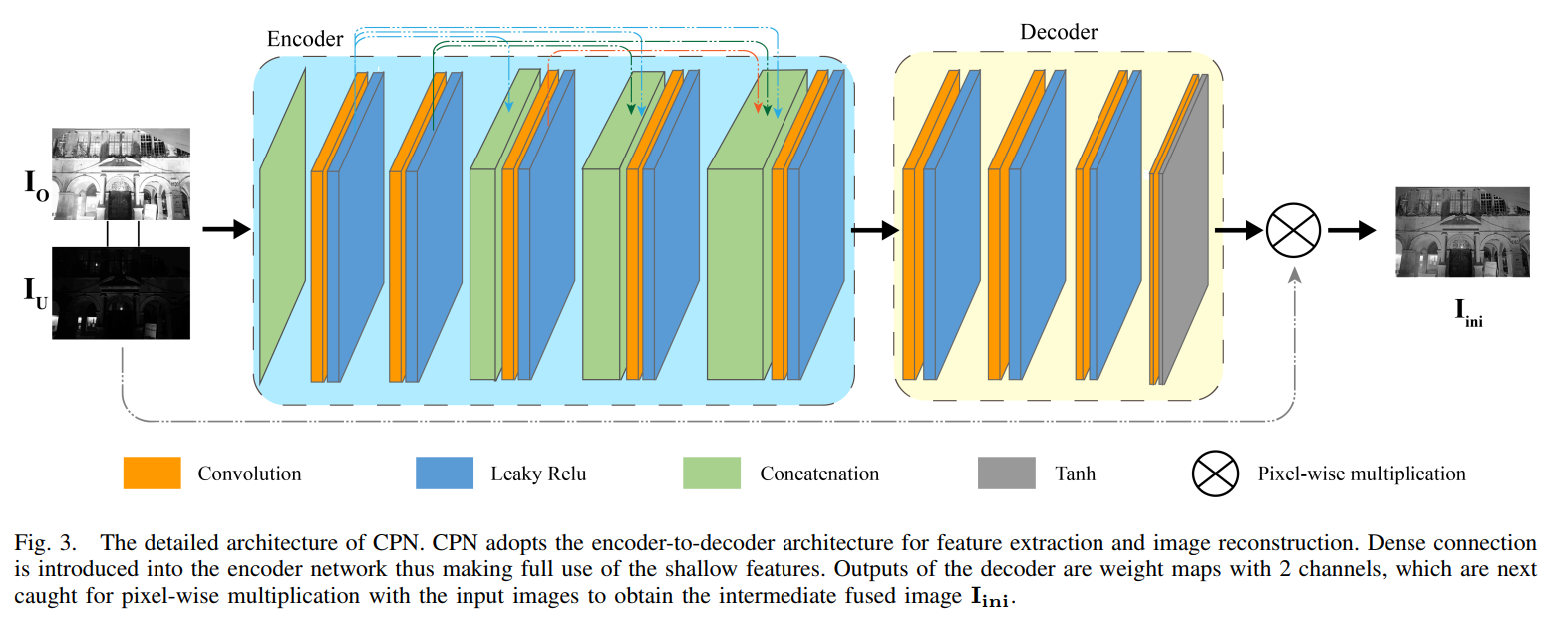
- 这是2022年TMM的一篇无监督多曝光图像融合的论文,网络由两部分串联组成:CPN和IAN,并且只对图像的YCbCr的Y通道进行处理。第一步的CPN基本就是对两张图像进行加权融合,保留各自清晰的部分。两张图都不清晰的部分,在IAN模块中进行调整。
- CPN的网络结构很简单,先生成两张weight map
W
1
,
W
2
W_1,W_2
W1,W2,再对过曝和欠曝图片的亮度通道进行加权平均得到初步调整后的亮度通道
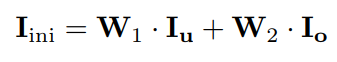
- 这一步的损失函数由两部分组成,如下所示,其中
w
u
w_u
wu和
w
o
w_o
wo分别是欠曝和过曝算损失时的weight map。MEF损失函数是衡量增强结果和原图的亮度和结构信息的相似性。
w
i
w_i
wi是由三个变量定义的,分别用来衡量对比度、色饱和度和曝光水平。对比度由原图的平方的高斯模糊(3x3)和高斯模糊的平方的差定义,而饱和度由三通道的方差图定义,曝光水平由原图偏离0.7的程度组成,是一个高斯概率衡量。第二部分的损失是weight map的TV loss:
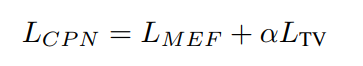
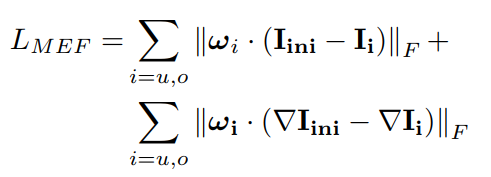
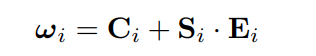

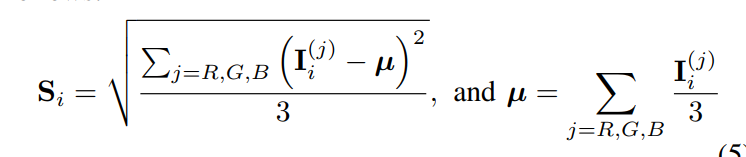
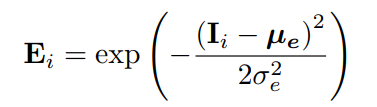
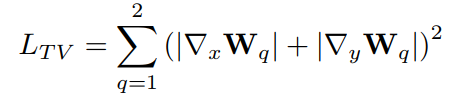
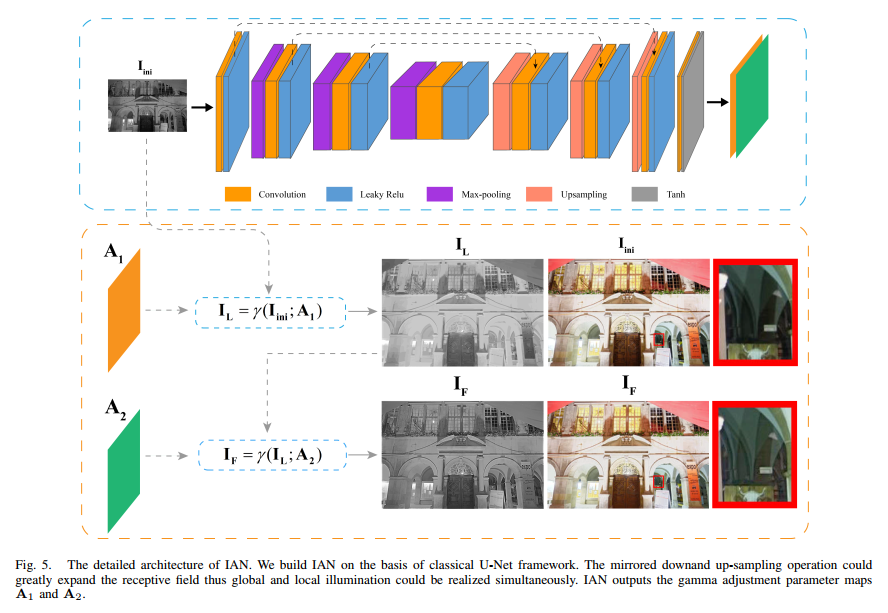
- IAN的网络结构如下图所示,网络的输出是两个parameter maps,分别用于element-wise地进行gamma校正,也就是说这两个A都是放到指数上进行gamma校正的。第一步校正是为了增强黑暗的区域,第二步校正是为了把第一步的时候过增强的区域调回来:
- IAN的损失函数分为三部分,第一项是第一次gamma校正的结果高斯模糊后和0.7的差,第二项是第二次gamma校正的结果和初步调整结果的差,第三项没有介绍(我傻了,还能这样的?):
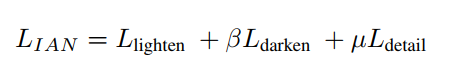
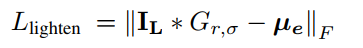
- 颜色通道也要做调整,如下,Cb和Cr都用下面的公式调整,
τ
=
128
\tau=128
τ=128:
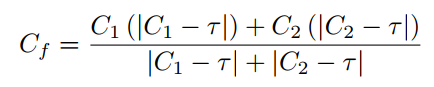
- 训练的时候两个网络是各自训练的,所以应该是先训练第一个网络,训练完fix参数训练第二个网络。在SCIE数据上训练。结果还不错:

J. Cai, S. Gu and L. Zhang, “Learning a Deep Single Image Contrast Enhancer from Multi-Exposure Images,” in IEEE Transactions on Image Processing, vol. 27, no. 4, pp. 2049-2062, April 2018, doi: 10.1109/TIP.2018.2794218.
- 这是TIP 2018的多曝光图像对比度增强的论文,论文构建了一个多曝光图像数据集,提供了GT图像,从而有监督地训练一个多曝光对比度增强的卷积神经网络模型。
- 数据集是这样实现的,首先是室内室外拍摄了一些多曝光序列图片(室内可以构建静态场景调节相机参数多次拍摄,室外则通过快拍实现,为了避免室外移动物体的对不准,室外的快拍序列通常只有3-5张,而室内可以有7-18张),然后对每张个场景用最先进的13种MEF和HDR算法产生高对比度图像,然后进行主观评价实验挑选最优的一张作为GT,找不出好的结果的场景会被丢弃。这样的方式我觉得其实有局限性,也就是说这样的方式构建的数据集进行有监督训练出来的网络的上限就是这13种算法的ensemble了,而且作为测试集来评价一些具有更高性能的算法时也不具有合理性。
- 训练模型用的损失函数是MSE、L1-norm 和 DSSIM 损失:

- 首先将输入图像根据(Zeev Farbman, Raanan Fattal, Dani Lischinski, and Richard Szeliski. 2008. Edge-preserving decompositions for multi-scale tone and detail manipulation. ACM Trans. Graph. 27, 3 (August 2008), 1–10. https://doi.org/10.1145/1360612.1360666)中的WLS方法分解为低频和高频分量:
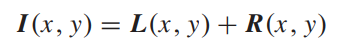
随后将两个分量分别送进两个并行的子网络并训练这两个子网络。然后将两个子网络fix,将两个增强后的分量输入到另一个CNN中产生最终的增强结果,网络结构如下图所示
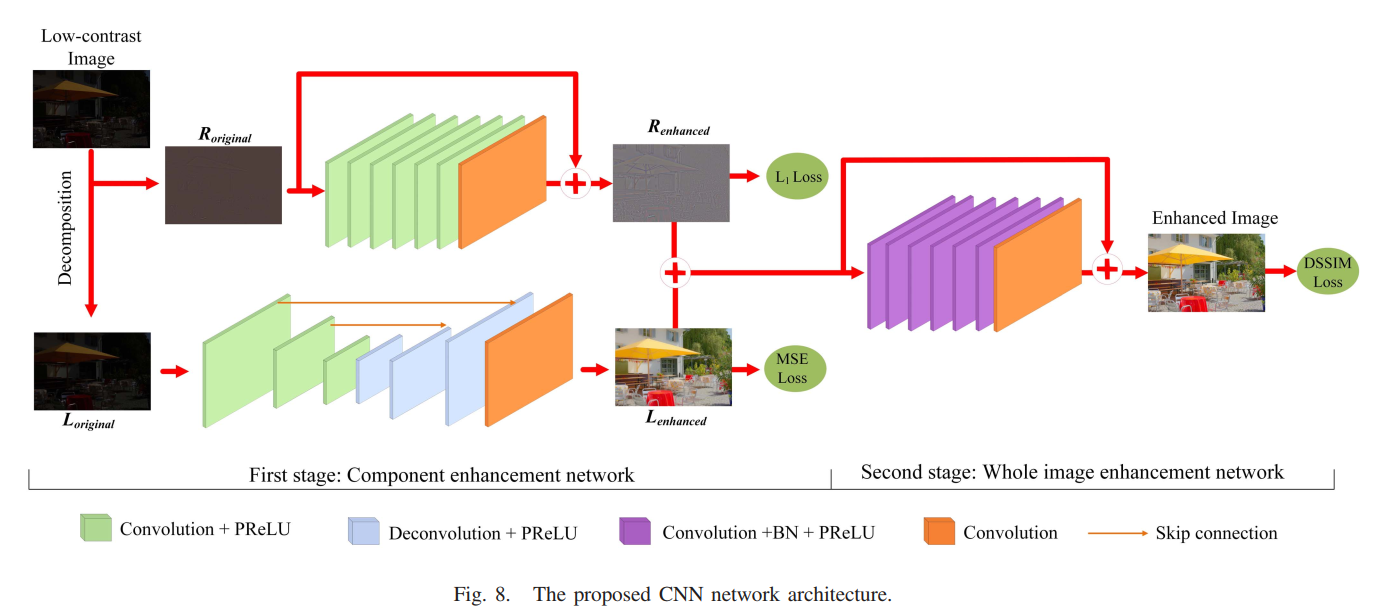
这里提到了一个技巧,卷积的padding会产生伪影,因此网络中并没有使用padding,而是使用反卷积来保持size。另一个技巧是认为暗图增强需要正负的激活值,因此不使用relu而使用prelu,我觉得也有点道理。这里的三个网络用的分别是三个不同的损失函数。L的增强网络用的是和GT的L分量的MSE loss作为损失,R的增强网络用的是GT的R分量的l1 loss 作为损失,第二阶段的网络用的是和GT的DSSIM损失
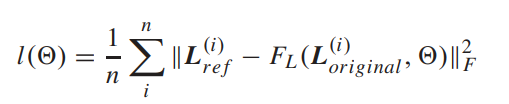
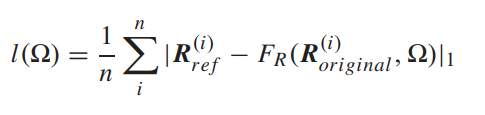
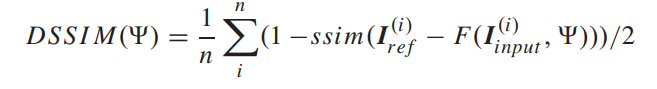
- 实验结果还是很不错的:

- 文章的高低频分治的idea是重要的,但两阶段有待商榷,感觉不美。但是演讲稿看起来是不错的,不知道能不能处理一张图片上同时需要过曝抑制和欠曝补偿的情况。
Haoyuan Wang, Ke Xu, and Rynson W. H. Lau. 2022. Local Color Distributions Prior for Image Enhancement. In Computer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XVIII. Springer-Verlag, Berlin, Heidelberg, 343–359. https://doi.org/10.1007/978-3-031-19797-0_20
- 这是ECCV2022的文章,看标题看不出是做多曝光调整的,其实就是做同一张图片上有欠曝和过曝的时候的多曝光调整的,属于有监督学习。
- 文章首先基于fivek提出了一个多曝光数据集,他拿fivek的raw data,去掉那些GT(专家retouch的)质量不高的,剩下的对raw data 模拟相机ISP生成过曝和欠曝的图片,并检查和返工那些生成的不好的图片,直到挑不出毛病。产生过曝和欠曝的图片用的是下面这个公式,其中
I
I
I是原来的raw data 归一化到0-1之间的图片,
ϕ
\phi
ϕ是clip,通过调整k可以产生过曝和欠曝的图片。
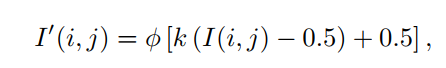
- 方法上,提出了一个基于局部颜色分布的网络,主要点在于一个是生成了多尺度的局部颜色分布图,其实就是分patch统计了patch内部的分颜色直方图,所以得到的M的第i,j位置是一个
3
×
B
3\times B
3×B的向量,表示三通道各个bin得到的概率,根据分patch的大小不同可以得到不同尺度的M。M会被送到LCDE模块,这是一个DRConv模块,根据前面送进来的特征生成卷积核,根据M生成的guided mask来对M的不同位置使用不同的卷积核。
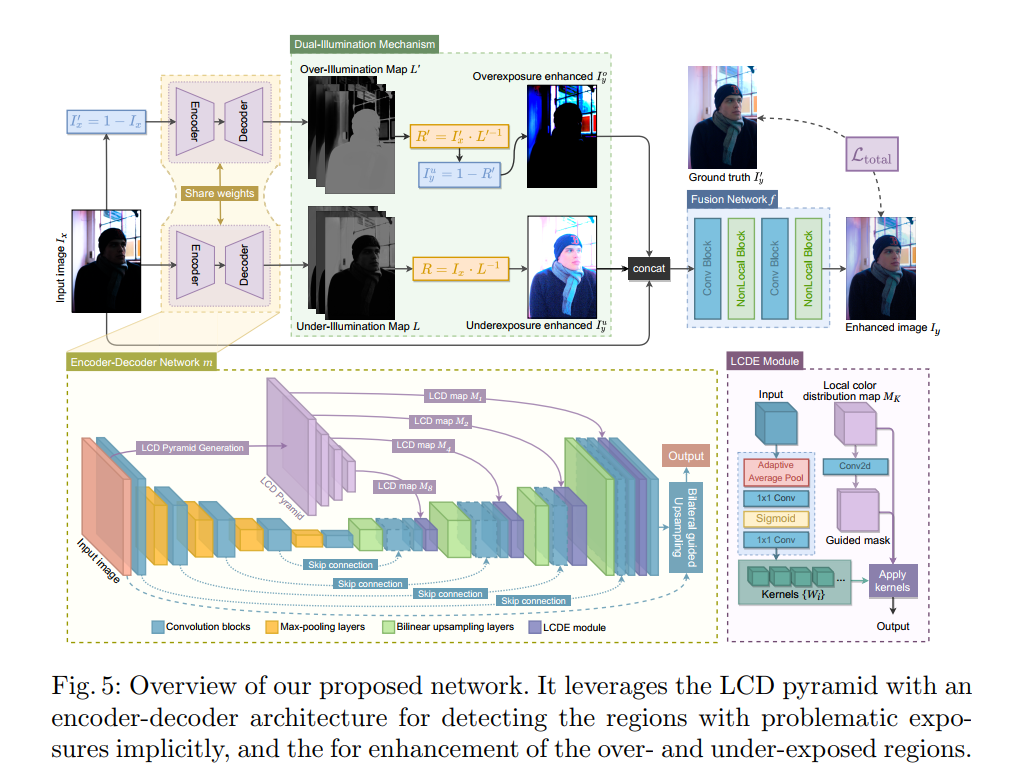
- 为了抑制过曝,取了图像的反图送进同一个网络产生增强结果,再取增强结果的反图。融合增强结果及反图的增强结果的反图可以得到最终的增强结果。融合用的是一个网络预测的权重图,融合对象是原图、增强结果、反图的增强结果的反图。
- 损失函数是原图和增加个的mse loss、cos loss(DeepUPE用到的),以及两个illumination map的tv loss。
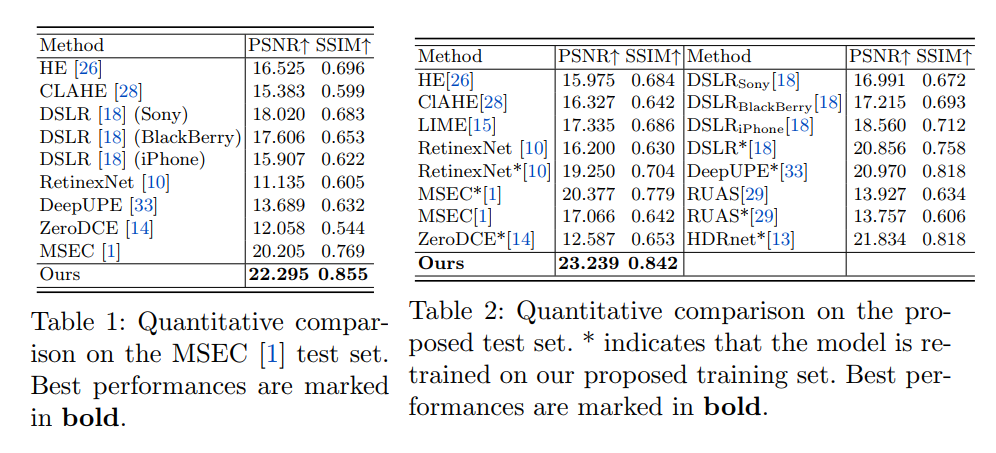
- 实验上,在自己制作的数据集上测了PSNR SSIM
- 可以看到,欠曝补偿和过曝抑制的效果都还行,不过也有点能做到同一张图片既补偿又抑制(得益于双支路)

- 用反图进行双支路应该是这个方法成功的关键。
Liang J, Yang Y, Zhang A, et al. FCNet: A Convolutional Neural Network for Arbitrary-Length Exposure Estimation[J]. arXiv preprint arXiv:2203.03624, 2022.
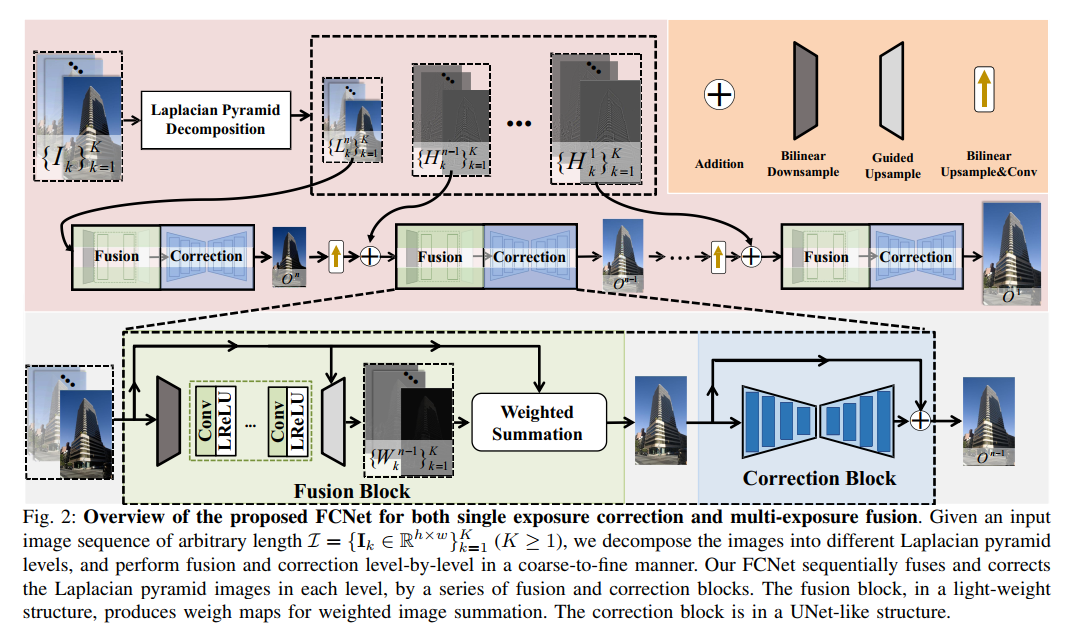
- 这是arxiv 2022上的一篇多曝光校正和多曝光融合的文章,标题换了一次,一开始叫 “Fusion-Correction Network for Single-Exposure
Correction and Multi-Exposure Fusion”, 后来改成 “FCNet: A Convolutional Neural Network for Arbitrary-Length Exposure Estimation” ,文章提出了一种能够融合任意长度的多曝光序列的方法,当长度为1时可以作为single image的exposure correction模型使用。 - 网络结构如图所示, 拉普拉斯金字塔分解插入到网络不同阶段的网络结构在2021年CVPR的这篇文章“Learning Multi-Scale Photo Exposure Correction”里面见过,而fusion block其实仅仅是对每张图片预测权重图进行加权平均,损失函数也是照抄这里面的,唯一称得上创新的地方在于提出了一个这样的流程,从粗到细不断地融合和校正多张曝光图片:
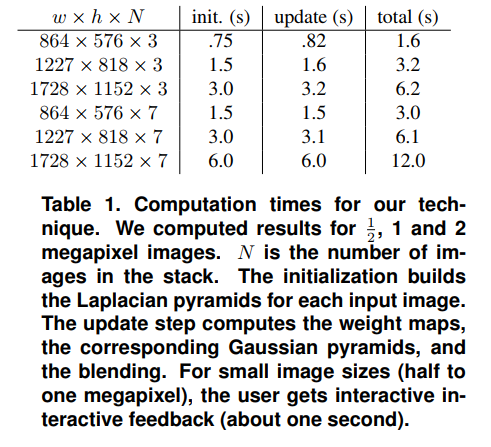
T. Mertens, J. Kautz and F. Van Reeth, “Exposure Fusion,” 15th Pacific Conference on Computer Graphics and Applications (PG’07), Maui, HI, USA, 2007, pp. 382-390, doi: 10.1109/PG.2007.17.
- 这是2007年一篇传统多曝光融合的论文。考虑下面三个指标来实现对多张图像的融合权重:
- 对比度C:用拉普拉斯滤波的结果的绝对值来表示对比度的大小
- 色饱和度S:用三通道的标准差来表示色饱和度的大小
- 曝光度E:用像素值落在以0.5为中心,0.2为方差的高斯分布的概率来衡量,如下公式:
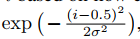
- 综合起来的权重如下:
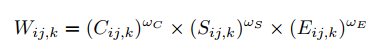
- 再对不同图像的权重进行归一化,然后对图像进行element-wise的加权平均得到融合结果:

- 对于上述的算法产生的结果,论文还不是太满意,因此论文对算法进一步改进,引入了laplacian pyramid。首先对输入的图片分解为laplacian pyramid,对上一步得到的weight map计算gaussian pyramid。然后对pyramid的不同level各自进行加权求和得到各自的融合结果,再从pyramid恢复出原图像即可得到最终的融合结果。而对颜色图片,则对各个颜色通道分别进行融合。
- 算法的速度如下所示: