作者:早恒
前一段时间重温了伪共享(false sharing)问题,了解到深处有几个问题一直想不明白,加上开发过程中遇到volatile时总觉得理解不够透彻,借着这次脑子里这几个问题,探究下Java可见性的本质到底是什么。
一、 提出问题
1)如果线程间存在内存可见性问题,那线程内为什么没有内存可见性问题?
(这里解释一下,在一个多核机器上,一个线程是有可能被操作系统调度到任意一个核上的。)
那我们站在硬件的角度思考,如果A(运行在核1)、B(运行在核2)两个线程间存在内存可见性问题,那么A的两次调度(假设分别在核1、核2)间为什么不存在内存可见性问题?
2)无论问题1的原因是什么,结论都是众所周知的,线程内是不存在内存可见性问题的。也就是说计算机在某个地方解决了线程内的可见性问题,那这个地方是哪里?是怎么解决的?为什么还存在永远不可见问题?
3)什么时候应该用volatile,什么时候可以不用?这块一直比较模糊。
PS:赶时间的同学,可以跳过分析过程,直接到 [4、回答问题] 看结论。
二、分析问题
2.1 测试
2.1.1 代码
我们写一段代码,定义一个Visible类,类里声明一个布尔属性bool,然后启动两个线程来读写bool变量,来重现JMM规范中的永远不可见例子(官方文档见附录1文档第10页)。
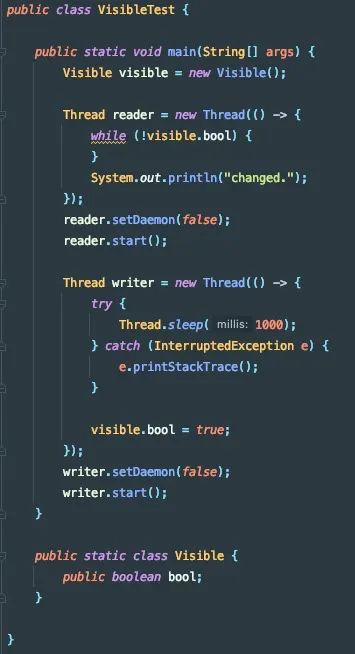
2.1.2 环境
我们一共用了两个环境来跑上面这个测试代码:
-
环境1
设备:MacBook Pro (Retina, 15-inch, Mid 2015)
配置:Intel Core i7 2.2 GHz 4核 16G
OS: macOS Big Sur 11.2.3 (20D91)
JDK:
Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
Java(TM) SE Runtime Environment (build 1.8.0_151-b12)
java version "1.8.0_151"
-
环境2
设备:INSPUR x86
配置:Intel Xeon Platinum 8163 2.50GHz 多路96核 512G
容器:Pouch (ali docker) 4核 8G cpuset
OS: 3.10.0-327.ali2016.alios7.x86_64 (centos7)
JDK:
java version "1.8.0_112"
OpenJDK Runtime Environment (Alibaba 8.3.6_fp5) (build 1.8.0_112-b21)
OpenJDK 64-Bit Server VM (Alibaba 8.3.6_fp5) (build 25.112-b21, mixed mode)
2.1.3 测试结果
我们分别看下在两个环境下的测试结果:
-
环境1

可以看到,编译后执行了两次:
第1次—默认参数执行死循环,直到按键ctrl+z终止;
第2次—增加-Djava.compiler=NONE参数后正常打印"changed."并结束。
-
环境2
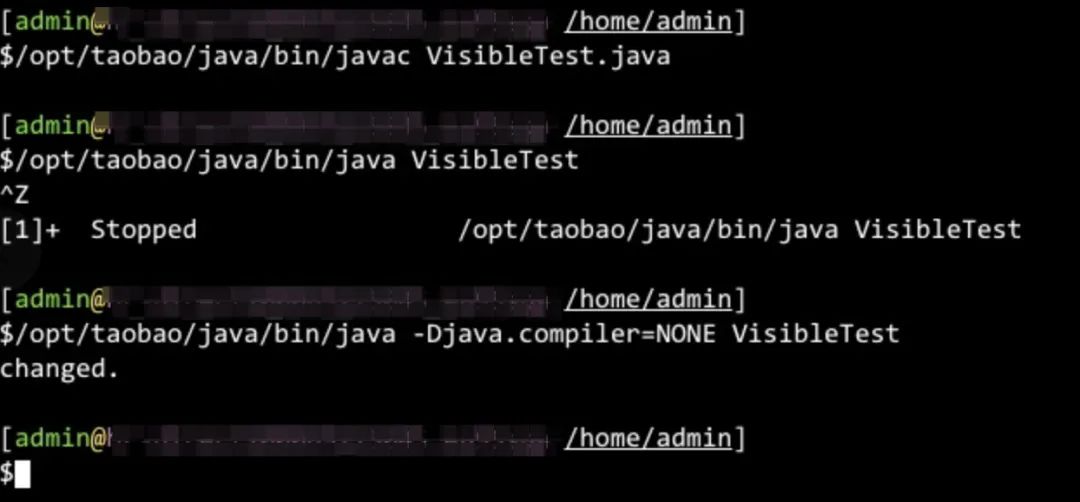
环境2上的结论和环境1完全相同。
到这里就有一个线索产生了,我们通过关闭JIT就会影响可见性。这里先不展开,我们继续分析。
2.1.4 进一步测试
我们修改一下代码,进一步测试下什么因素会导致bool变量可见。在循环体内插入下述任意一行代码,都会导致bool变量立即可见。

在循环体内执行if判断,当if为true时不可见,为false后立即可见。
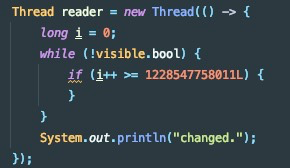
到这里我们发现,看来除了JIT还有其他能影响可见性的因素。
2.2 Java代码执行过程
开始分析问题之前,我们先回顾一下一段java代码是怎么被执行的,然后再从上往下的分析下问题出在哪里。
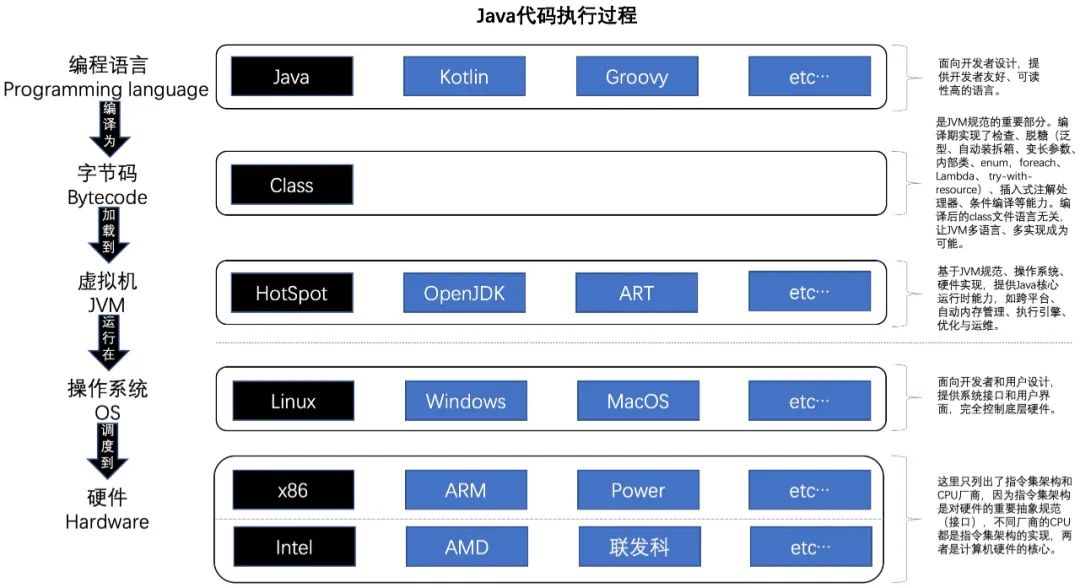
2.2.1 编程语言
在编程语言层面,我们主要了解下理论和规范,在看下java提供的解决可见性的手段。
2.2.1.1 JMM
我们看下JMM是如何定义描述java内存模型的。
java内存模型和线程规范(JSR-133 Java Memory Model and Thread Specification):

《深入理解Java虚拟机》中的简化版JMM:
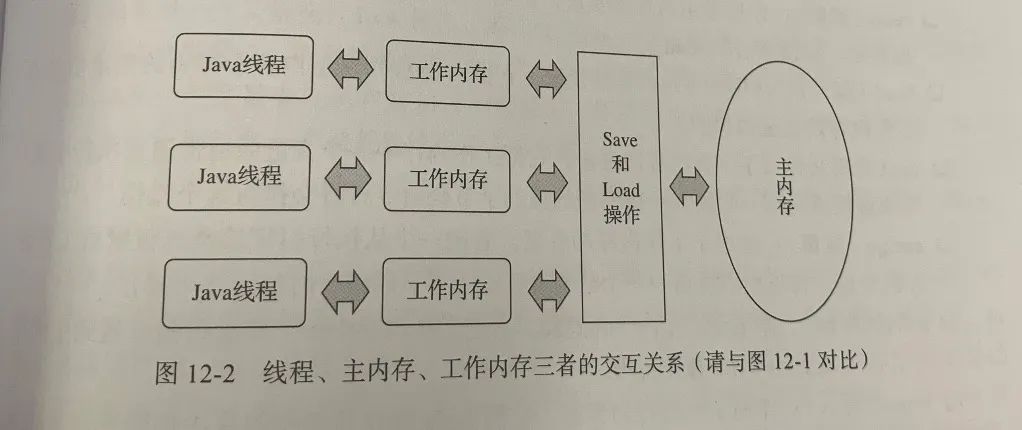
ps:这里的“工作内存”不是指的线程栈,也千万不要认为“工作内存”在内存里,可以简单理解为寄存器。
2.2.1.2 可见性
再看下Java对可见性的定义描述:

不同于理想情况下的可见性,Java对可见性的定义是有前提的:A行为的结果可以被B行为观测到,则A、B必须存在 happen before 关系。
2.2.1.3 happens-before
happens-before的定义:
java内存模型和线程规范(JSR-133 Java Memory Model and Thread Specification)。

2.2.1.4 内存屏障
如果需要在没有happen before关系的时候可见,就要用到内存屏障了。在聊屏障之前还是先了解下屏障到底是在解决什么样的问题。
重排序
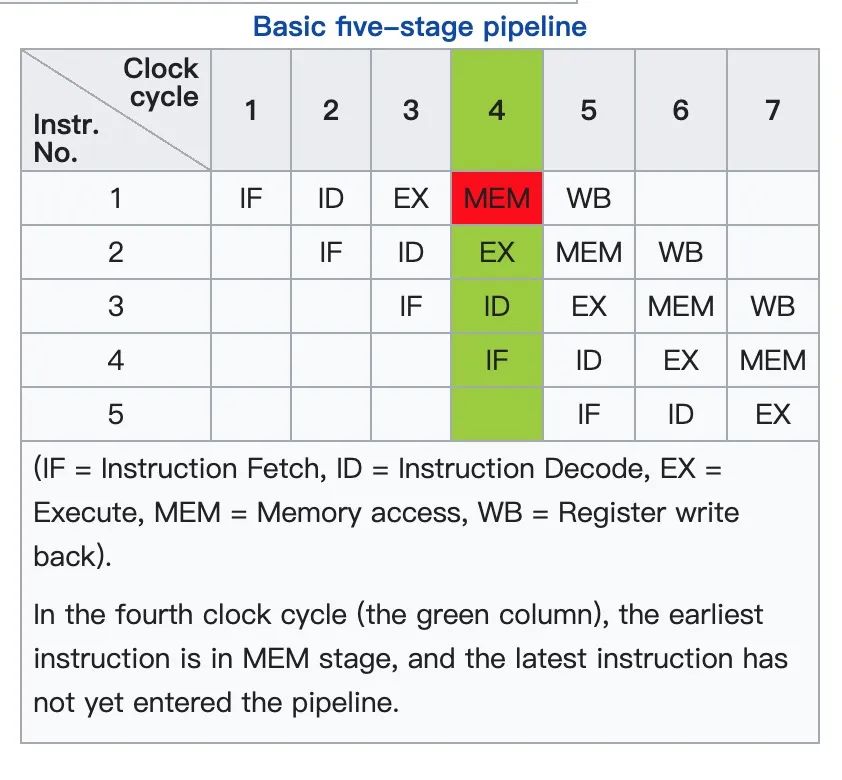
是在不违反JMM规范的前提下,JIT编译器进行的优化重排序,和CPU为了指令流水线(Instruction pipelining)的高效利用,进行的乱序执行(out-of-order execution)。发生在几个阶段:

-
编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句 的执行顺序。
-
指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应 机器指令的执行顺序。
-
内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上 去可能是在乱序执行(out-of-order execution)。
as-if-serial
意思是,不管怎么重排序,单线程程序的执行结果不能被改变。
屏障
保证顺序的手段,可以想象为一个栅栏,以栅栏为界,之前的和之后的相互不能越界。
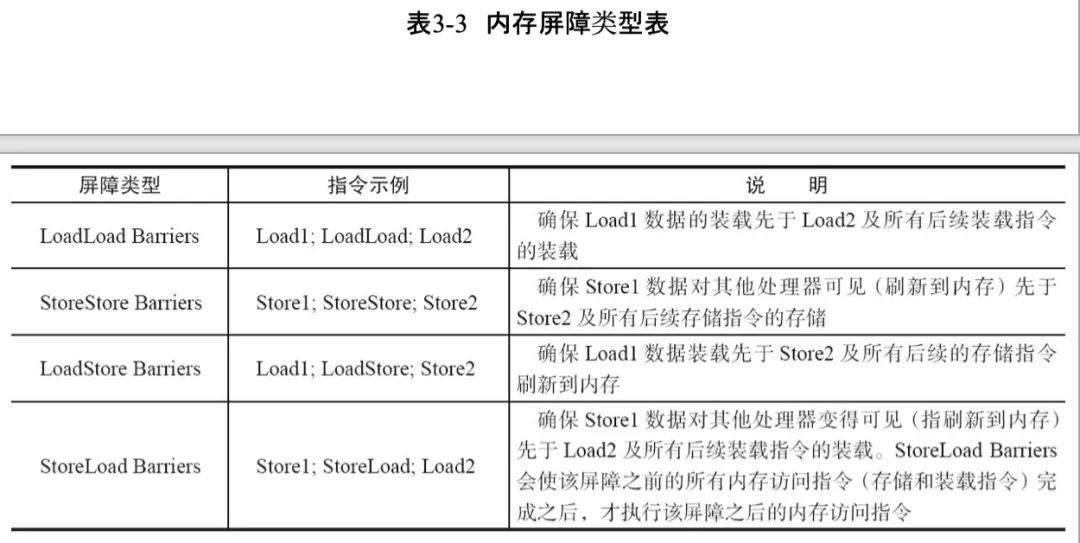
volatile关键字的本质
-
禁止编译重排序;
-
插入运行时内存屏障。
volatile内存屏障的实现方式:
-
在每个volatile写操作的前面插入一个StoreStore屏障;
-
在每个volatile写操作的后面插入一个StoreLoad屏障;
-
在每个volatile读操作的前面插入一个LoadLoad屏障;
-
在每个volatile读操作的后面插入一个LoadStore屏障。
(如果有性能要求的场景,可以不在变量声明时使用volatile,而是在使用时按需选择是否用volatile,使用Unsafe、jdk9 VarHandle可以做到这点,它们的底层实现是相同的)
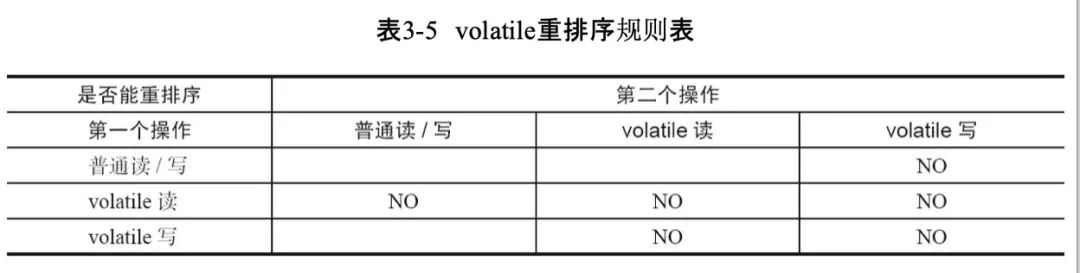

在x86架构下,只有StoreLoad在运行时有作用,具体实现是StoreLoad时立即write-back store buffer,且发送MESI修改消息。
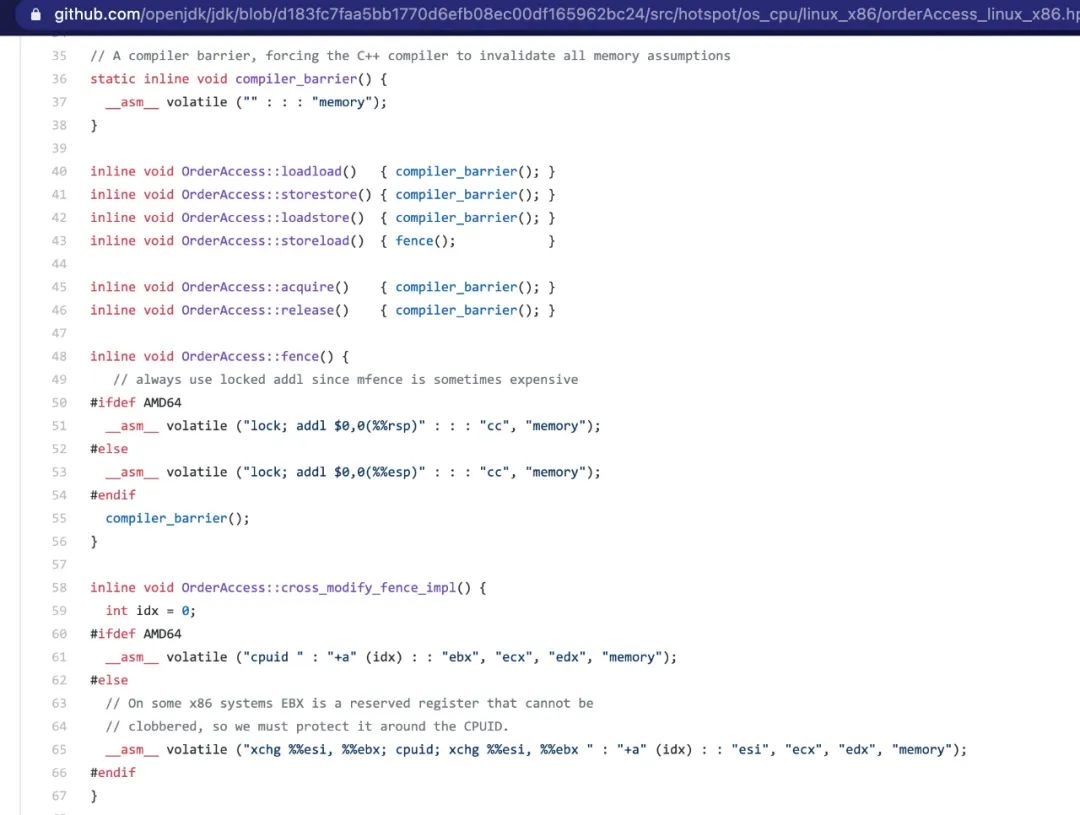
OpenJDK linux x86内存屏障实现
可以看到,在x86架构下,内存屏障CPU实现指令为lock(前缀)。
2.2.1.5 volatile之外
piggybacking间接触发的屏障
可以发现,所有的解决可见性的手段,最终都基于CPU指令lock。

java.util.concurrent包里的很多类就利用了这一点(ArrayBlockingQueue、LinkedBlockingQueue),没有使用volatile,通过ReentrantLock、cas等间接触发可见。
灰色的不是JMM规范。比如线程上下文切换,硬件层面保证了硬中断后的可见性,操作系统层面保证了前后两个时间片执行线程不同时的可见性,但排除这两种情况的其它情况(线程上下文切换但下一个线程还是当前线程)取决于是否使用lock,如parkNanos底层就使用了cas所以总是可见,sleep、yield未使用lock则取决于是否发生调度换出。
JMM对Sleep、Yield没有happen-before关系的说明

2.2.2 字节码
在字节码层面,因为编译器的优化也会导致加剧可见性问题,比如Android的提前编译器。
JVM规范(The Java Virtual Machine Specification)中定义了class的JVM指令集,这是一种基于栈的指令集。在android平台,class还需经过class [打包]-> dex [安装]-> 机器码才能交由ART执行。dex和机器码属于基于寄存器的指令集。
编译器
检查、脱糖(泛型、自动装拆箱、变长参数、内部类、enum,foreach、Lambda、 try-with-resource)、插入式注解处理器、条件编译等能力。编译后的class文件语言无关,让JVM多语言、多实现成为可能。
提前编译器(Ahead-of-time, AOT)
针对Android平台的ART,在用户安装APP时会进行的dex -> 机器码的编译行为。但从Android7.0开始,为了解决安装耗时过长问题,这一行为会在系统空闲时后台自动进行,或在运行时使用即时编译器进行。
2.2.3 虚拟机
在虚拟机层面,运行时JIT的优化也是导致可见性问题的原因。
解释器(interpreter)
即时编译器(Just-in-time, JIT)
-
Client compiler (C1);
-
Server compiler (C2);
-
条件:1.方法的调用次数;2.循环回边的执行次数;
-
激进预测性优化(Aggressive speculative optimization)。
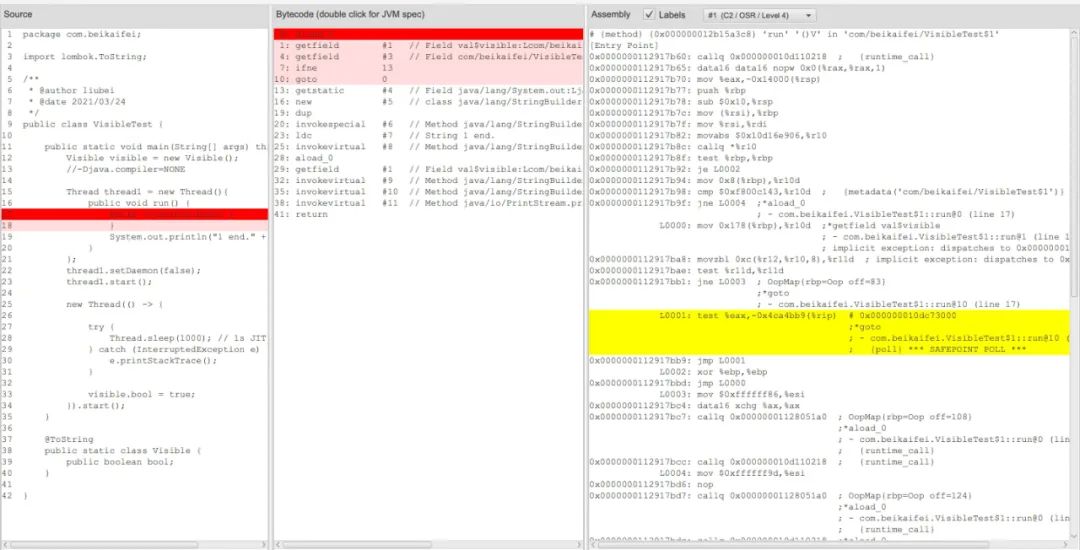
图:JITWatch
上图是问题2对应代码的JIT优化结果,可以看到test比对的数据是寄存器中的,eax是寄存器的一个区域,程序进入到这个循环后并不会更新寄存器了,加上寄存器随线程切换而保存恢复,所以当test为true时这里是一个死循环(寄存器结果可以看下面的Intel示意图)。
2.2.4 操作系统
在操作系统层面,我们需要关心线程调度对可见性的处理。
pthread
POSIX Threads,一个线程API规范,几乎在所有unix like(unix、linux、maxOS)系统上默认支持。
https://en.wikipedia.org/wiki/POSIX_Threads
context switch
上下文切换会保存当前线程状态,主要是保存寄存器、堆栈指针、程序计数器、刷新转换后备缓冲区(TLB)、下一个进程的页表。
CFS Scheduler
不同的操作系统都有自己的Scheduler实现,以linux的Scheduler为例,又支持多种调度策略(Scheduling policies)。
time-sharing scheduling policy
SCHED_OTHER、SCHED_IDLE、SCHED_BATCH同属于分时调度策略,也称为普通调度策略,是linux的默认调度策略。
real-time scheduling policy
又分为SCHED_FIFO、SCHED_RR,实时线程的调度优先级总是高于普通线程,一般用于系统调用。
deadline scheduling policy
SCHED_DEADLINE,该任务应该在该相对时间前停止运行,运行时具有最高优先级。
上下文切换
上下文切换时,如果当前进程与下一个进程不是同一个进程,则插入内存屏障,包括用户态内核态切换。见下图linux内核代码/kernel/sched/core.c 函数__schedule (bool preempt)。
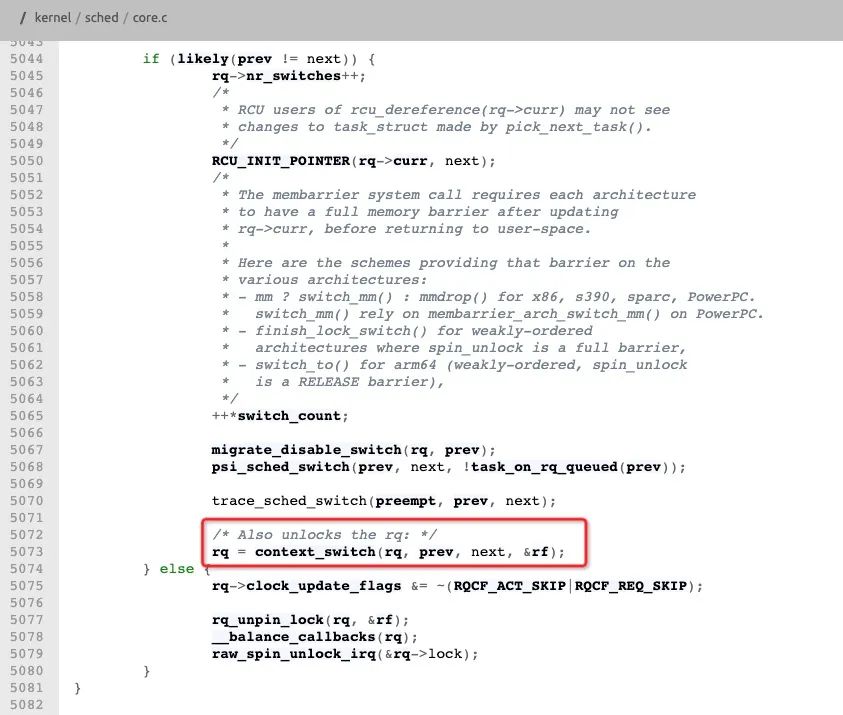
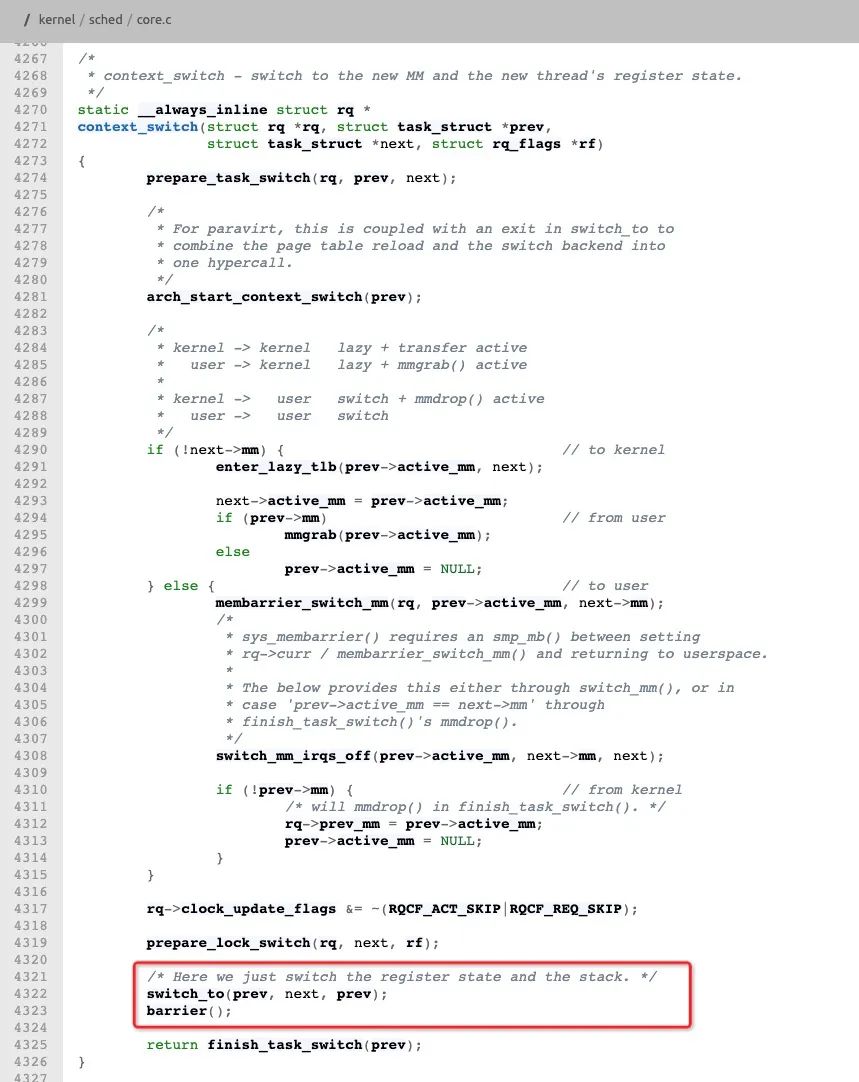
https://elixir.bootlin.com/linux/latest/source/kernel/sched/core.c#L3324
2.2.5 硬件
在硬件层面,我们需要了解硬件是如何设计并导致可见性问题的,以及硬件对问题的解决方案。
Intel 内核流水线功能图
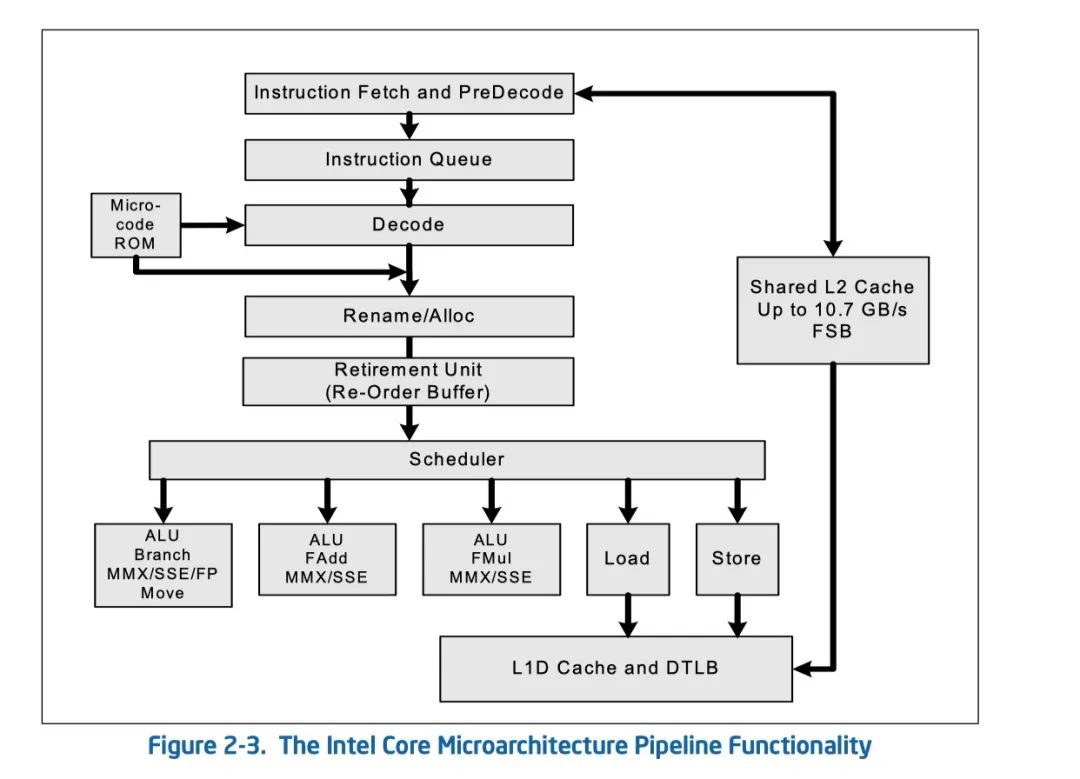
寄存器


指令流水线并行示意
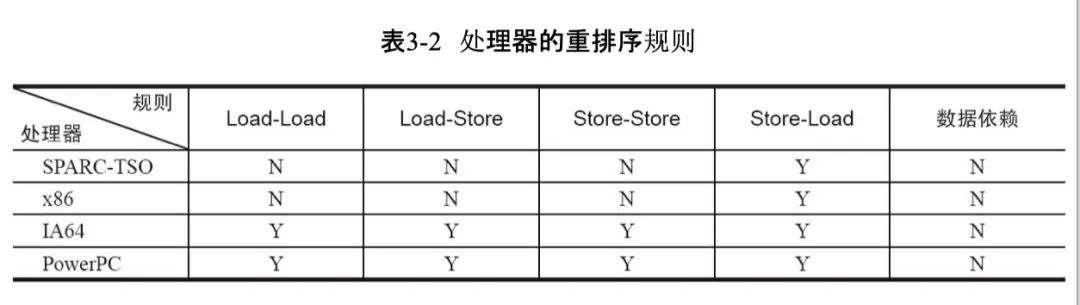
不同指令集架构重排序规则
Intel x86处理器的详细规则

写缓冲

除了上述这些点会回写内存,还有:
-
store buffer满的时候;
-
缓存行覆盖的时候。
Lock操作的影响

-
确保对内存的读-改-写操作原子执行。(Intel P6之后在一定情况下使用Cache Locking代替Bus Locking) ;
-
禁止该指令,与之前和之后的读和写指令重排序;
-
把store buffer中的所有数据刷新到内存中。
Lock之外

三、回答问题
1)如果线程间存在内存可见性问题,那线程内为什么没有内存可见性问题?
(这里解释一下,在一个多核机器上,一个线程是有可能被操作系统调度到任意一个核上的。)
那我们站在硬件的角度思考,如果A(运行在核1)、B(运行在核2)两个线程间存在内存可见性问题,那么A的两次调度(假设分别在核1、核2)间为什么不存在内存可见性问题?
这里我们以"环境2"说明下结论:
-
linux CFS Scheduler本身具有一定的处理器亲和性(负载均衡算法设计了在处理器之间迁移任务是有一定"阻力"的),在不发生处理器迁移时,两个时间片执行在同一个处理器核,即使我们的数据在store buffer还没有回写主存,也会因为store-buffer forwarding而取到最新的数据;
-
如果发生处理器之间迁移,因为context switch中判断当前进程与下一个进程不是同一个进程,则插入内存屏障,store buffer 回写主存并发送MESI修改消息,数据在新处理器核可见。
2)无论问题1的原因是什么,结论都是众所周知的,线程内是不存在内存可见性问题的。也就是说计算机在某个地方解决了线程内的可见性问题,那这个地方是哪里?是怎么解决的?为什么还存在永远不可见问题?
前几问上面已经有答案了,这里回答下“为什么还存在永远不可见问题?”:
是JIT的激进优化导致的,可以看到优化后的汇编码是直接从寄存器取值判断的,且判断为true后循环这个动作,根本不会重新加载主存更新寄存器,寄存器是跟随context switch而保存恢复的,所以这个寄存器地址将永远不会更新,导致死循环。而向循环体添加代码会使得JIT不进行激进优化,且如果添加的代码满足"3.2.1.5、间接触发的屏障"中的一种时,会导致内存立即可见。
3)什么时候应该用volatile,什么时候可以不用?
目前大部分CPU为了性能默认都不保证不同核心之间的可见性,但都提供同步API供开发者按需实现同步和可见,这是一种比较合理的设计,给了CPU很大的性能优化空间。可见性问题发生的原因是编译期和运行期的重排序,解决办法是直接或间接使用内存屏障(x86 lock),知道这些后我们可以很轻松的认识到何时应该使用volatile,需要关注这些因素:
-
首先,基于JMM规范,存在happen-before关系的不需要使用volatile。
-
直接或间接触发屏障的,屏障之前的内存对屏障之后可见,不需要使用volatile。需要注意的是如果是间接触发的屏障,你需要评估依赖方法的稳定性和实现变更的可能性,最好基于通用的实现。一个反例是线程上下文切换,虽然它有可能解决问题,但这是JMM所不推荐的,很有可能在不同平台,或者未来发生变化。
-
其它情况下需要线程间可见性的,请使用volatile或屏障相关API,包括不在a、b内,或者在a、b内但存在交叉读写多次同步的场景。
四、总结
-
简单来说,以x86架构举例,可见性问题就是JIT激进优化和CPU store buffer导致的,解决办法是直接或间接使用CPU指令lock,以阻止JIT优化和强制回写store buffer。
-
通常情况下,因为三方库、JDK、JVM、操作系统大都有在使用屏障,所以内存可见性问题并不是很严重,甚至很难遇到,但为了系统健壮性,了解什么时候应该用屏障是非常必要的。见“什么时候应该用volatile,什么时候可以不用?”
-
相比单处理器,多处理器机器硬件是非常复杂的,以占据绝大部分服务器市场的x86来说:L1\2\3 cache解决CPU读写内存效率的问题,但引出了缓存一致性问题;MESI协议解决缓存一致性问题,但加剧了总线占用和资源竞争;store buffer进一步解决CPU效率的问题,但引出了可见性问题;最终可见性问题抛给了开发者,硬件只提供了lock指令。
-
硬件保证了一个CPU核前后执行的代码的可见性;操作系统保证了加上线程调度后,在线程上下文切换后的可见性(线程切出的时候加入内存屏障,绝对的保证了线程内前后时间片的可见,但不保证线程间相互可见,因为取决于是否发生了线程切出);程序层面需要保证其它情况下的可见性。
-
由于底层差异巨大,JMM是Java站在跨平台的角度上,对JVM厂商做的最小约束,和对开发者的最小承诺。在大多数环境下,实际的可见性情况都好于JMM。但要知道,任何超出JMM规范之外的用法,都可能在不同平台,或者未来失效。
-
JVM较好的抽象设计让人印象深刻,这应该也在JVM生态的发展上起了很大作用。但JMM相关文档做的比较差,且官方反复修改(最早JMM这部分内容是在JVM规范中的,但因为反复修改,就提取为了JSR单独维护,甚至在jdk1.5之前还存在Bug,可见jdk本身的开发者都搞不太清楚)。可能站在Java的角度无法穷举所有平台特性,只能高度抽象。这种问题可能没有很好的解法,就像《演进式架构》中说到的,没有抽象是完美的,如果有,那它将不再是抽象,而是实际存在。但我们可以从抽象到细节的去全面掌握它。

图:《演进式架构》P104 -- 抽象泄露
-
有些知识点本身涉及东西比较多,比如可见性这个问题,从Java到操作系统到硬件都有涉及,这类知识要透彻的掌握只简单看些二手资料是不够的,要花时间找权威的资料,全面的理解梳理。
参考阅读
[01]《JSR 133 Java Memory Model and Thread Specification》
https://download.oracle.com/otndocs/jcp/memory_model-1.0-pfd-spec-oth-JSpec/
[02]《Intel® 64 and IA-32 Architectures Software Developer’s Manual》
https://software.intel.com/content/www/us/en/develop/articles/intel-sdm.html
[03]《Multithreaded Programming Guide》(for solaris)
https://docs.oracle.com/cd/E37838_01/pdf/E61057.pdf
[04]《Understanding Just-In-Time Compilation and Optimization》
https://docs.oracle.com/cd/E15289_01/JRSDK/underst_jit.htm
[05]《Java Language and Virtual Machine Specifications》
https://docs.oracle.com/javase/specs/index.html
[06]《Java并发编程的艺术》
[07]《Java并发编程实战》
[08]《深入理解Java虚拟机》
[09]Linux调度:
https://www.cnblogs.com/charlieroro/p/12133100.html