【天池题解】题解:CAAI-BDSC2023社交图谱链接预测(任务一:社交图谱小样本场景链接预测)
文章目录
- 【天池题解】题解:CAAI-BDSC2023社交图谱链接预测(任务一:社交图谱小样本场景链接预测)
- 比赛介绍
- 1. 方法介绍
- 2. 算法描述
- 2.1 构建用户特征
- 2.2 基于特征进行预测
- 3. 参数设置
- 4. 方法分析

比赛介绍
比赛地址:官网
-
CAAI第八届全国大数据与社会计算学术会议(China National Conference on Big Data & Social Computing,简称BDSC2023)将于2023年7月9-11日在新疆乌鲁木齐召开,由中国人工智能学会主办、社会计算与社会智能专委、新疆工程学院共同承办。本届会议的主题为“数字化转型与可持续发展”,立足全球数字化转型的技术变革、治理与政策实践,通过跨学科交叉视野探索通过数字化推动可持续发展的全球经验与中国智慧。
-
“社交图谱链接预测”赛道背景
社会网络是由社会个体成员之间因为互动而形成的相对稳定的社会结构,成员之间的互动和联系进一步影响人们的社会行为,电子商务平台大范围的普及和使用,不仅满足人们丰富多样的消费需求,也承载着社会成员基于商品消费产生的互动链接,形成基于电商平台的在线社交网络,电商场景社交知识图谱的构建有助于深入理解在线社交网络的结构特性与演化机理,为用户社交属性识别和互动规律发现提供有效方式。电商平台活动和场景形式丰富多样,用户表现出不同的社交行为偏好,且伴随活动场景、互动对象、互动方式、互动时间的不同而不断发生变化,动态性高,不确定性强,这些都给社交知识图谱的构建和应用带来巨大挑战。 -
本赛道基于阿里电子商务平台用户互动数据展开社交图谱链接预测任务,本次评测包括两个子任务:社交图谱小样本场景链接预测,社交图谱动态链接预测。
1. 方法介绍
方法—github地址: 潘子你缺W吗?
本方法采用基于启发式的特征工程方法来建模并解决社交图谱小样本场景链接预测问题。总的来说,分为以下两部分:
- 1) 构建用户特征:对源场景的数据集进行处理,获得用户的正向邀请关系和反向被邀请关系,以此来构成用户的特征。
- 2) 基于特征进行预测:基于用户的特征,采用启发式的方法(一阶邻居与二阶邻居结合)来对用户邀请的用户进行预测。
2. 算法描述
2.1 构建用户特征
源场景数据集中,每个数据样本含有以下信息:
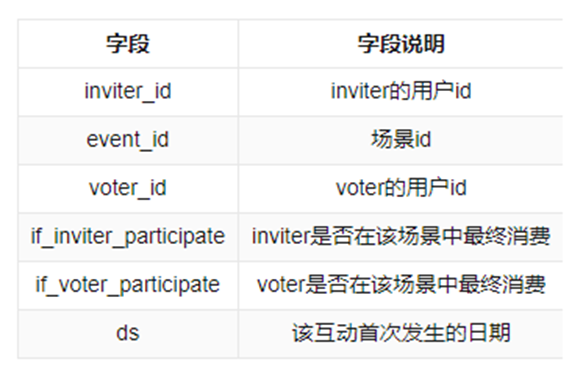
我们对每个数据样本,对inviter_id、event_id、voter_id、ds四个字段进行处理,并保存到正向邀请关系和反向的被邀请关系中。举个例子,在2022年5月5日,用户1在场景2下邀请了用户3,那么我们便保存相应的信息如下:
- 正向邀请关系:data[1][3].append((2,20220505))
- 反向被邀请关系:data1[3][1].append((2,20220505))
- 注:data[i][j]是一个list,其中元素为二元组:(场景,时间)。data[i][j]可以理解为用户i邀请用户j的历史记录;data1[i][j]也是一个list,其中元素也为二元组(场景,时间)。Data1[i][j]则可以理解为用户i被用户j邀请的历史记录。
经过上述的处理之后,我们便得到了用户的正向邀请关系和反向被邀请关系,以此来构成用户的特征。
2.2 基于特征进行预测
对于每个待预测的样本(s,r),其中s代表邀请者,r代表目标场景,我们要预测用户s在场景r下可能邀请的用户。接下来我们基于启发式的方法来进行预测。
- 首先,我们对用户s的一阶邻居进行得分构建。
s的一阶邻居包含:s邀请过的用户,以及邀请过s的用户(也就是上述2.1中data和data1中存储的信息)。data(data1)中保存的信息其实就是用户的历史交互信息,我们根据交互的时间和次数来衡量一个用户是否与用户s关系密切,也就是s是否会邀请这个用户。
① 对于时间处理,由于源场景数据的时间范围(20211227-20221224)大概为1年时间,因此我们对时间减去一个初始的时间(20211101),然后再除以一个时间因子tc(默认为100),防止过大,影响效果(将三位数变为一位数)。
② 对于次数处理,我们简单的采用累加进行计算权重。举个例子,也就是用户1邀请过用户2有10次,而邀请过用户3有5次,那我们则可以认为用户1与用户3的关系比用户2的密切,因此我们简单的采用了累加。
上述的计算用户关系权重的过程中,我们另外也引入了两个参数pw(默认为30)和nw(默认为15),来防止正向和反向关系计算导致的权重过大,影响效果。 - 然后,我们基于用户的一阶邻居来求二阶邻居的权重。
这里对二阶邻居的权重进行简化,只将次数这个因素纳入计算,其他的计算类似于一阶邻居权重的计算。计算初期二阶邻居的权重也会被初始化远小于一阶邻居,因为我们认为用户的一阶邻居比二阶邻居要重要。 - 最后,我们将一阶邻居和二阶邻居合并,基于他们的权重进行排序,得到预测结果。
3. 参数设置
时间因子(tc):100
正向关系权重阈值(pw):30
反向关系权重阈值(nw):15
4. 方法分析
在该任务中,我们采用了基于启发式的特征工程方法,该方法捕捉到的特征信息更加全面,运行速度快,无需训练,端到端直接运行。
- 尝试了一系列的深度学习方法之后,通过实验结果(可视化)和理论分析发现,大多数的深度学习方法基于节点嵌入的相似性来获得结果,然而没有显式地捕捉很重要的特征,比如说交互的时间以及交互的次数,即使将这些因素纳入深度模型的建模之中,也很难学习到有效的表示。
因此,基于启发式的特征工程方法可以。