目录
一、netty执行流程
二、EventLoop
1、事件循环对象EventLoop
2、事件循环对象组EventLoopGroup
3、io任务
4、分工细化
5、handler执行中如何换的group
三、Channel
1、常用方法
2、channelFuture
3、为什么要异步
四、Future & Promise
1、jdk future
2、netty future
3、promise
五、Handler & Pipeline
1、用法
2、为什么要有handler
3、outHandler
六、ByteBuf
1、创建
2、直接内存 & 堆内存
3、池化 & 非池化
4、组成
5、写入和扩容和读取
6、内存回收
7、零拷贝
slice
duplicate
copy
compose
一、netty执行流程
下面是新版用netty写的客户端和服务器端的通信
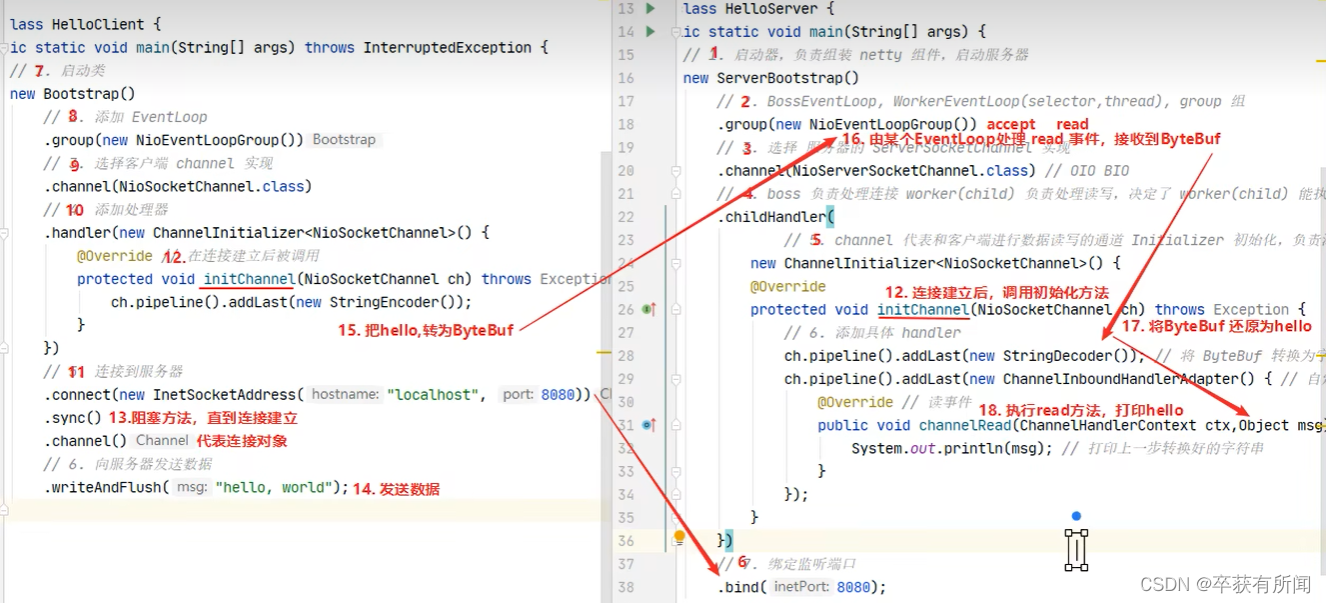
先创建了启动器类,然后添加组件,添加EventLoopGroup(内部会有个选择器在不断循环看看有没有新的事件,一开始关心accept事件看有没有连接),然后选择一个serverSocker的实现,这里选了NIO的实现,然后就是添加处理器,这个处理器是连接建立好后执行的,所以只是先添加初始化器,建立连接后才会执行。最后就是绑定端口。
创建启动器类,创建客户端的eventLoopGroup,然后写客户端的channel实现,添加处理器,这个处理器也是建立完连接后才执行的,连接服务器监听端口,连接后服务端就会监听到然后服务端的处理器内就会处理,就会掉用初始化方法,然后这个客户端就会往下运行了,他就能拿到channel对象,然后就能发送数据了,发送数据就会走到handler里面了,在netty里面收发数据都要走
handler,把hello字符串转为byteBuf,就可以把byteBuf的数据发出去,然后服务端接受,如果断接受到服务端handler会把这个byteBuf转化为hello
提示:
- channel可以理解为数据的通道
- msg可以理解为流动的数据,最开始输入是byteBuf,经过pipeline的加工,会变成其他数据类型对象,最后输出又变成ByteBuf
- 把handler理解为数据的处理工序:工序有多道,合在一起就是pipeline,pipeline负责发布事件(读、读取完成..)传播给每个handler,每个handler对自己感兴趣的事情进行处理(重写了相应事件处理方法);handler分inbound和outbound两类,输入为入栈处理器,输出为出栈处理器
- eventLoop理解为处理数据的工人
- 一个工人是可以管理多个channel的io操作,并且一旦工人负责了某个channel,就要负责到底(绑定)
- 工人既可以执行io操作,也可以进行任务处理,每个工人有任务队列,队列可以放多个channel待处理的任务,任务分为普通任务和定时任务
- 工人按照pipeline顺序,一次按照handler的规划处理数据,可以为每道工序指定不同工人
二、EventLoop
1、事件循环对象EventLoop
Eventoop本质是一个单线程执行器(同时维护了一个selector),里面有run方法处理Channel上源源不断的io事件,他的继承关系比较复杂(接口可以多继承):
- 因为他是个执行器可以处理任务和定时任务,所以继承自java JUC的ScheduledExecutorService因此包含了线程池中的所有的方法
- 另一条线是继承自nett自己的OrderedEventExecutor,提供了boolean inEventLoop(Thread thread)判断一个线程是否属于此eventLoop,还提供了parent方法来看自己属于哪个eventLoopGroup执行器组
2、事件循环对象组EventLoopGroup
EventLoopGroup是一组EventLoop,Channel一般会调用EventLoopGroup的register方法绑定其中一个eventLoop,后续这个channel上的io都由此eventLoop来处理((保证了io事件处理时的线程安全)
继承自netty自己的EventExecutorGroup,实现了iterable接口便利eventLoop,另外有next方法获取集合中的下一个eventLoop
构造器:线程数是怎么初始化的?进源码发现他是如果没有输入默认是0,然后当为0的时候,就去读配置的netty默认参数,没有参数就把数量设置为cpu核心数*2
next方法:如果一共只有两个线程,那么他就是轮训的next,第一次1第二次2第三次又1了,让任务分工比较均衡。
执行普通任务:直接调用group的next方法拿到eventLoop后直接调用线程池方法执行任务就行
group.next().execute(()->{ //任务 });执行定时任务:调用线程池的scheduleAtFixedRate方法传入参数实现
group.next().scheduleAtFixedRate(()->
//要执行的任务
},0,1,TimeUint.SECONDS);3、io任务
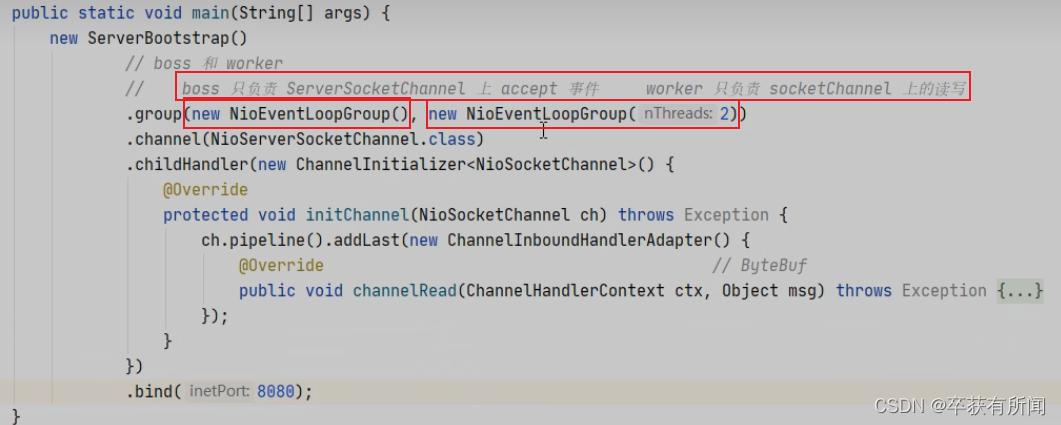
每个工人轮流处理channel,但工人与channel之间进行了绑定,我们客户端1绑定了线程之后后面都是线程1去处理他的消息,客户端2绑定线程2后面都是线程2来处理他的消息

我们可以对eventLoopGroup的职责进行细分,像之前一样分为boss和worker,让boss负责accept事件,worker负责socketChannel的读写。
4、分工细化
如果有某个handler的耗时比较长,最好不要让他占用worker的读写,所以我们要再做一次细分
多创建一个独立的EventLoopGroup,然后再出handler里面去选择那些handler用哪个group去处理

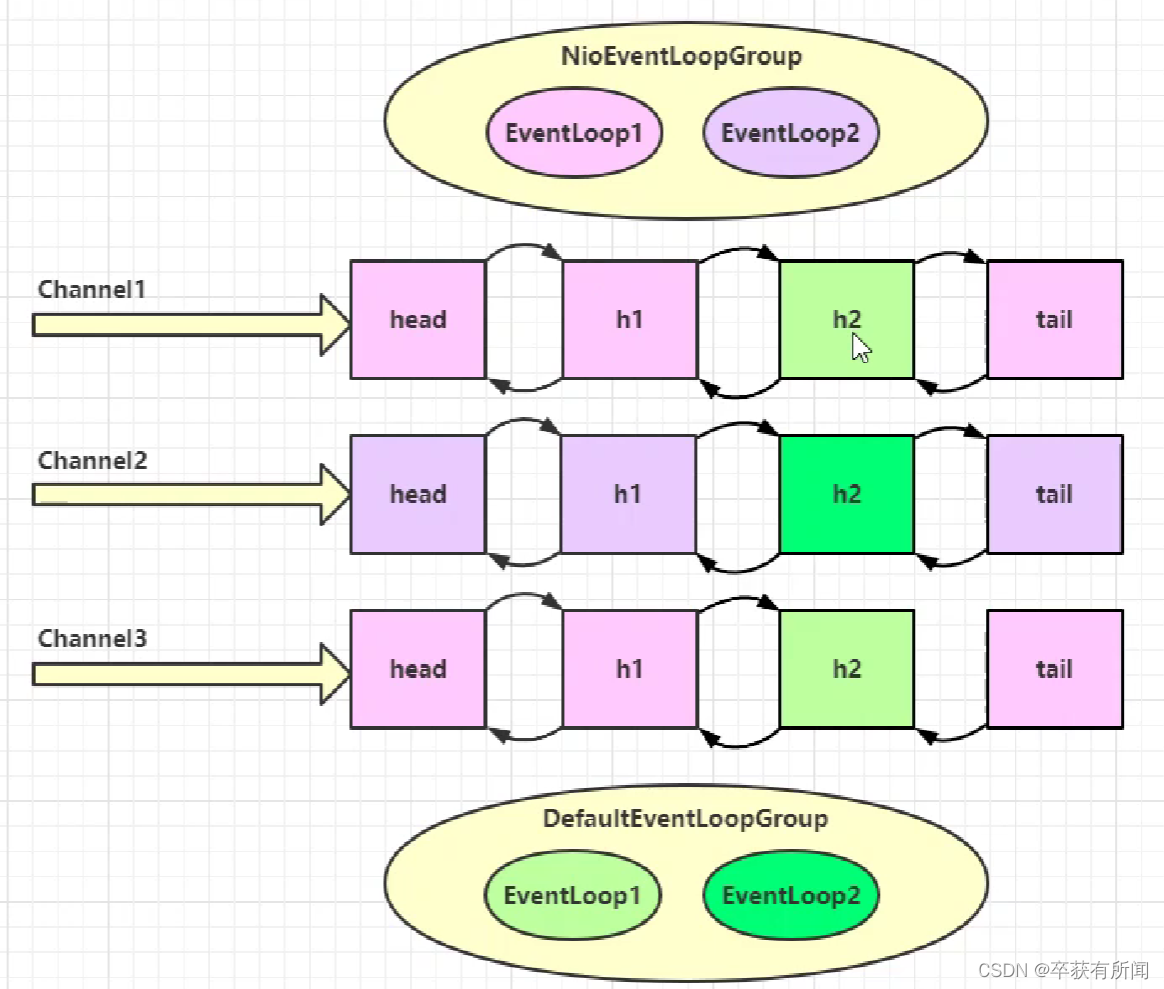
如上图,如果你已经绑定了,那么下次你总会用那个已经绑定的线程处理,如果你换了别的group也是一样的,执行到了对应的handler之后也是用对应的group的线程处理。
5、handler执行中如何换的group
假如还是拿上图距离,我们有四个handler,我们把上面粉色叫NIO线程,下面叫普通线程。
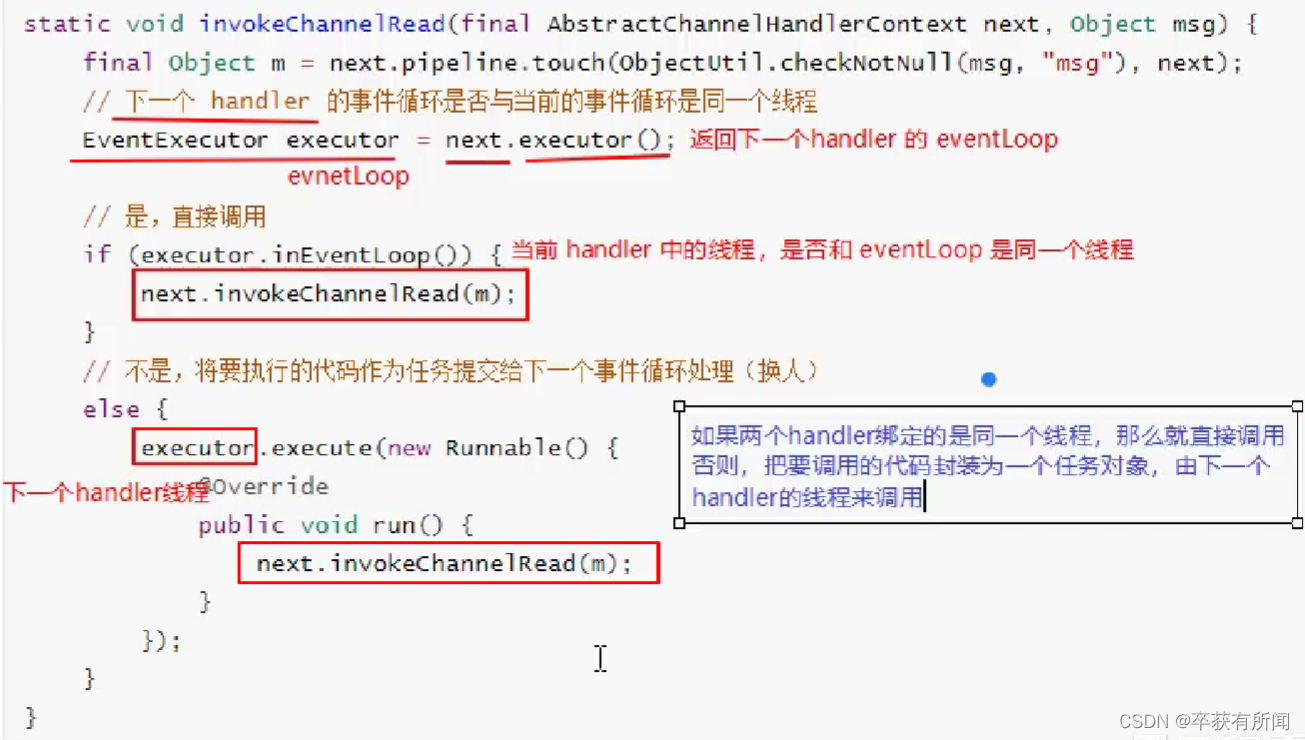
当我们第一个执行完在调用下一个handler时候会执行invokeChannelRead方法,进入了会找到下个handler,然后调用executor返回下一个handler的eventLoop,然后判断一下当前handler中的线程是否跟刚才的eventLoop是同一个线程,如果成立就让下个handler是同一个线程直接调用;如果不是说明是换了普通线程,粉色变绿色的,进入else,还是要调用下一个handler的事件,但是他是交给下一个handler的线程调用,绿色线程来调用。
三、Channel
1、常用方法
Channel的主要作用:
- close()可以用来关闭channel
- closeFuture()用来处理channel的关闭
- sync方法作用是同步等待channel关闭
- 而addListener方法是异步等待channel关闭
- pipeline()方法添加处理器
- write()方法将数据写入,然后要调用flush才会发出去
- writeAndFlush()方法将数据写入并刷出
2、channelFuture
我们客户端代码这个connect返回值就是channelFuture,sync()和channel()都是他的方法。
这个connect方法是异步非阻塞的,也就是说调用connect方法的线程是不关心结果的,是另一个线程去做的,主线程去调用,connect是nio线程。如果我们去掉sync方法,我们异步建立连接需要一些时间,但是主线程是不阻塞的直接执行获取连接和写入,这个时候就是个没有建立好的连接,写入肯定是没有数据的。

那么要怎么防止这种异步非阻塞的连接影响写入呢?
1、用sync方法同步处理结果,他会调用sync的时候阻塞住,当nio线程等连接建立好才会向下运行
2、使用addListene(回调对象) 方法异步处理结果,他不是阻塞等待,而是直接把等待和后面的全部都交给别的线程去执行了

我现在要输入q就关闭连接,怎么做?

我们就在客户端写入这里判断,如果为q就close关闭,然后处理之后的操作。但是这样会有问题,就是这个close其实也是异步非阻塞的,所以调用close还没关闭的时候,主线程不管了直接执行善后工作,所以会出现还没关闭就只想完之后的操作的情况,所以还是用下面这种方法解决
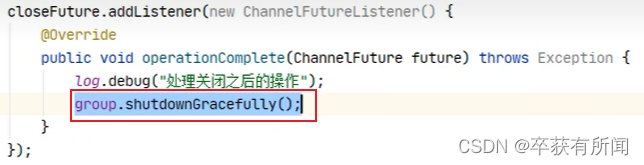
两种方案,用closeFuture方法返回ChannelFuture。一种sync同步,一种是addlist异步回调,

最后客户单的关闭还需要把group中的线程都优雅的停下来,还没处理完的处理完,没发完的发完,这样才能停止,调用这个shutdownGracefully就会把group线程都停下来
3、为什么要异步
假如有4个医生给病人看病,每个病人花20分钟,而且医生看病过程以病人为单位的,一个病人看完了,才能看到下一个病人,假设病人远远不断来,4个医生一天工作8小时,处理病人数为4*8*3=96

研究发现,看病可以细分为四个步骤,拆分后每个步骤需要5分钟

因此可以做下面优化,医生234分别等待5 10 15分钟开始执行,只要病人源源不断来,他们就能满负荷工作,处理病人的能力提高了4*8*12效率几乎是原来的四倍

如上图,原本医生1一个小时只能处理3个病人,现在一个小时可以处理12个挂号,这样效率就提升了很多,每个医生的效率都几乎提升了4倍,但是他们切换可能要时间,病人在换病室可能需要时间,病人的看病时间长了但总体效率提升了
四、Future & Promise
异步处理的时候,经常用到这两接口
首先说明netty中的future是集成jdk中的future的,promise对netty的futrue进行了扩展
- jdk的future只能同步等待任务结束,才能的大哦结果
- netty中的future可以同步等待任务结束得到结果,也可以异步方式得到结果,但都是等任务结束
- netty的promise觉得要等任务结束才得到结果比较被动,所以扩展了为可以脱离了任务独立存在,只作为两个线程间传递结果的容器

1、jdk future
jdk中的线程池搭配使用一般,future其实就是用来多线程获取其他线程返回结果的,jdk这个get方法是阻塞的,他主线程会等待子线程执行完成拿到返回值才能get到。

2、netty future
netty的future其实也是继承jdk的所以基本上写法一样,但是他多了异步处理回调的方式,他主线程调用完后直接不管了,其他线程执行完再掉用回调方法执行回调里面的操作完成。

3、promise

五、Handler & Pipeline
ChannelHandler用来处理Channel上的各种事件,分为入站,出站两种,所有ChannelHandler被连成一串就是Pipeline流水线
- 入站处理器通常指ChannelInboundHandlerAdapter的子类,主要用来读取客户端数据,写回结果
- 出站处理器通常是ChannelOutboundHandlerAdapter子类,主要对写回结果进行加工
1、用法
我们就在initChannel方法里面调用channel的pipeline方法拿到ChannelPipeline,然后调用addLast添加处理器handler直接new匿名内部类完成
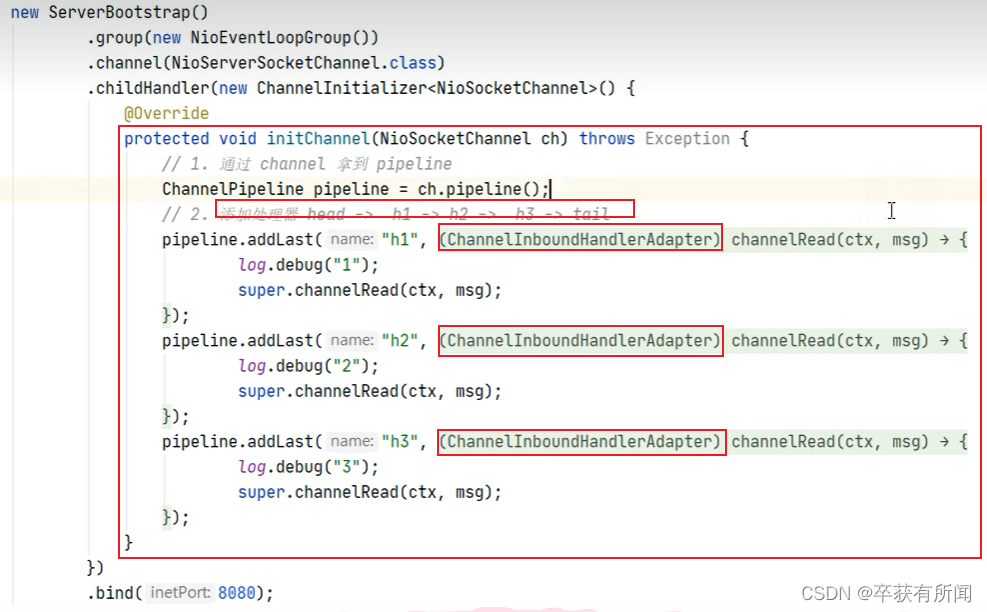
入站处理器是有数据发送过来就会触发,是顺序执行的,先h1到h2到h3,我们如果再加3个出栈处理器呢?

出站处理器只有在我们往channel里面写数据的时候才会触发,所以我们上面要write一下然后他的出站执行顺序是反过来的,先h6再h5

2、为什么要有handler
为什么我们要设置这么多个handler让他执行呢?
我们可以用他来加工传输过程中封装的消息,我们拿到消息先把byteBuf转换位字符串用h1,然后用h2把字符串转为对象,然后h3再写出对象

3、outHandler
我们出站处理器必须要往channel里面写入才会执行,其中也有一些情况,我们用ctx来调用write方法是从当前这个处理器往前找,如果有出站处理器out就执行那个处理器,后面才有前面没有就不会执行一个。如果我们是调用ch的write方法,那么他会从tail往前找,就代表执行全部有的出站处理器,这里要注意一下。


六、ByteBuf
1、创建
要用ByteBufAllocator来创建,他的容量是可以动态扩容的,构造器可以制定初始容量,如果没有指定默认为256字节。
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(10);2、直接内存 & 堆内存
可以用下面代码来创建池化基于堆的ByteBuf
ByteBuf buffer = ByteBufAllocator.DEFAULT.heapBuffer();可以用下面代码来创建池化基于直接内存的ByteBuf
ByteBuf buffer = ByteBufAllocator.DEFAULT.directBuffer();- 直接内存的创建和销毁代价高昂,但读写性能搞少一次内存复制,适合配合池化功能一起用
- 直接内存对GC压力小,这部分内存不受JVM垃圾回收器管理,但也要注意及时主动释放
3、池化 & 非池化
池化的最大意义在于看重用ByteBuf,优点有:
- 没有池化,每次都得创建新的ByteBuf实例,这个操作直接内存代价高昂,就算堆内存也会增加GC压力
- 有了池化可以重用实例,并采用与jemalloc类似的内存分配算法提升分配效率
- 高并发时,池化功能更节省内存,减少内存溢出的可能
池化功能默认就是开启的,可以通过下面系统变量设置
-Dio.netty.allocator.type = {unpooled|pooled}4、组成
ByteBuf由四部分组成,最开始读写指针都在0位置,容量是自己设置的,不给也会默认256,最大容量默认是整数的最大值,容量到最大容量这个区域叫可扩容部分

5、写入和扩容和读取
写入的方法

我们先初始化10哥字节大小的buffer然后写入8个字节,这个时候继续写超过就会触发扩容了
扩容规则:
- 如果写入后数据大小为没超过512,则选择下一个16的整数倍,比如写入后大小为12,扩容后位16
- 如果写入后超过512,则选下一个2的n次方,比如写513则扩容后位1024
- 如果扩容超过int的最大值就会报错
读取:读取根之前的ByteBuffer差不多,也有个markReaderIndex方法标记当前位置,然后开始读,之后在resetReaderIndex又可以回到那个位置重新读取,还有一种方法实现这种功能就是get开头的方法可以指定读取的下标
6、内存回收
由于netty中对外内存的ByteBuf实现,堆外内存最好的手动来释放,而不是等GC来回收
- UnpooledHeapByteBuf使用的是JVM内存,让JVM自己管理等GC回收就好了
- UnpooledDirectByteBuf使用就是直接内存,需要主动调用特殊方法来回收内存
- PooledByteBuf和他的子类使用了池化机制,需要更复杂的规则来回收内存,还回内存池
Netty提供了统一的接口来实现内存回收,每个ByteBuf都实现了ReferenceCounted接口(他也是采用引用计数的方式来确定对象是否应该被回收)
- 刚开始每个ByteBuf对象的初始计数是1
- 调用release方法计数-1,如果为0,ByteBuf内存就会被回收
- 调用retain方法计数+1,避免调用者没有用完之前,其他handler即使用调用release回收
- 当计数为0,底层内存会被回收,这时即使ByteBuf对象还在,各个方法均无法正常使用
那么谁来调用release呢?
因为有pipeline的存在,一般需要将ByteBuf传递给下一个handler处理,如果再finally中直接release了,就没传递性了,当然如果这个handler已经完成了bytebuf的实名后面无需传递就可以他来release,所以能否释放完全看他是不是最后一个用的处理器

7、零拷贝
slice
方法是零拷贝的体现之一,比如我现在要对原本的ByteBuf做数据的读写操作,但是这样可能要创建个新的处理要拷贝。用slice就可以对原始ByteBuf进行切片成多个slice切片,切片后的多个slice并没有发生内存复制,还是使用原始的ByuteBuf内存,切片后的ByteBuf维护独立的read和write指针


注意:
- 切片后会对容量限制了,比如就上面图片这种拆分切片,如果我直接扩容往f1添加字节,那后面f2原本的位置怎么办?所以是不允许多增加的
- 如果你对原本的那个没切分前的ByteBuf做了release操作释放内存,就可能影响到每个切片,切片就不能用了,因为他们是共享的内存。如果不想因为这个被影响就需要用到那个切片完之后就让他的引用计数+1,retain方法,这也是retain方法的正确用法之一
duplicate
duplicate也是零拷贝的方法之一,就好比截取了原始ByteBuf的所有内容,并且没有max capacity的限制,也就是原始的ByteBuf共同用一块底层内存,只是读写指针是独立的

copy
还有copy方法,但是这种会将底层数据进行深拷贝,因此无论读写,都与原来的无关
compose
compose就与slice相反,他就是把多个片段组合成一个整体,也不会放生数据的拷贝,但是他同样要注意release问题,要防止片段内存被释放掉。