文章目录
- list插入元素和vector插入元素对比案例
- vector的做法
- list优化的做法
- 为什么时间复杂度相同还会有性能差异
std::list和std::vector是C++中的两种常见数据结构,它们在不同的使用场景下各有优势。
std::vector的内部实现是动态数组,它在连续的内存块中存储数据。这使得std::vector在访问元素时具有非常高的效率,因为可以直接通过索引来访问元素,时间复杂度为O(1)。然而,std::vector在插入和删除元素时可能需要移动大量的元素,特别是在非尾部进行插入或删除操作时,时间复杂度为O(n)。std::list的内部实现是双向链表,它在非连续的内存块中存储数据。这使得std::list在插入和删除元素时具有非常高的效率,因为你只需要修改相关节点的指针,无需移动其他元素,时间复杂度为O(1)。然而,std::list在访问元素时可能需要遍历整个链表,时间复杂度为O(n)。
如果主要的操作是插入元素insert操作,那么使用std::list会比使用std::vector更高效。
list插入元素和vector插入元素对比案例
leetcode406.根据身高重建队列
vector的做法
class Solution {
public:
//注意cmp接收的是两个一维数组,而不是二维数组
static bool cmp(vector<int>& P1,vector<int>& P2){
if(P1[0]>P2[0]) return true;//整体降序
if(P1[0]==P2[0]){
if(P1[1]<P2[1])
return true;//p1[0]相同的时候按照p1[1]升序
}
return false;
}
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
//先对所有的hi降序排序,因为本题的people中的变量是{a,b},所以需要自定义sort cmp
sort(people.begin(),people.end(),cmp);
//定义新的二维数组作为输出
vector<vector<int>>result;
//开始遍历排序后的people
for(int i=0;i<people.size();i++){
//因为此时已经排序完毕,所以[6,1]直接插入到下标为1的地方,[5,0]直接插入下标为0的地方
int position=people[i][1];//people[i][1]就代表着第i个集合people的第二个元素!
//元素放到对应的二维结果数组里
result.insert(result.begin()+position,people[i]);
}
return result;
}
};

list优化的做法
class Solution {
public:
static bool cmp(vector<int>& P1,vector<int>& P2){
if(P1[0]>P2[0]) return true;
if(P1[0]==P2[0]){
if(P1[1]<P2[1])
return true;
}
return false;
}
vector<vector<int>> reconstructQueue(vector<vector<int>>& people) {
sort(people.begin(),people.end(),cmp);
//结果数组类型修改为list<vector<int>>
list<vector<int>>result;
//遍历排序后的people
for(int i=0;i<people.size();i++){
int position=people[i][1];
//找到position位置之后,定义迭代器再插入
list<vector<int>>::iterator it = result.begin();
//注意这里insert的写法,先寻找插入位置
while(position--){
it++;
}
//while结束之后找到插入位置
result.insert(it,people[i]);
}
//把结果转换为vector<vector<int>>,相当于构造新的二维vector
return vector<vector<int>>(result.begin(),result.end());
}
};

其直观上来看数组的insert操作是O(n)的,整体代码的时间复杂度是O(n^2)。
链表的insert查找+插入也是O(n),整体代码时间复杂度是一样的。
为什么时间复杂度相同还会有性能差异
对于普通数组,一旦定义了大小就不能改变,例如int a[10];,这个数组a至多只能放10个元素,改不了的。
对于动态数组,就是可以不用关心初始时候的大小,可以随意往里放数据,那么耗时的原因就在于动态数组的底层实现。
那么动态数组为什么可以不受初始大小的限制,可以随意push_back数据呢?
首先vector的底层实现也是普通数组。
vector的大小有两个维度一个是size一个是capicity,size就是我们平时用来遍历vector时候用的,例如:
for (int i = 0; i < vec.size(); i++) {
}
而capicity是vector底层数组(就是普通数组)的大小,capicity不一定=size。
当insert数据的时候,如果已经大于capicity,capicity会成倍扩容,但对外暴漏的size其实仅仅是+1。
那么既然vector底层实现是普通数组,怎么扩容的?
就是重新申请一个二倍于原数组大小的数组,然后把数据都拷贝过去,并释放原数组内存。
举一个例子,如图:
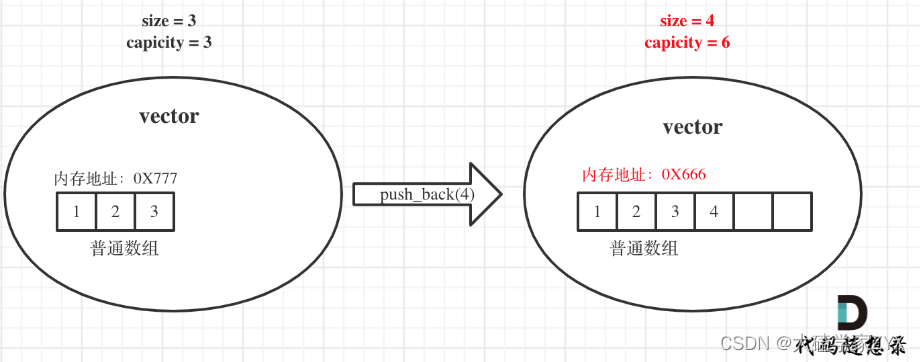
原vector中的size和capicity相同都是3,初始化为1 2 3,此时要push_back一个元素4。
那么底层其实就要申请一个大小为6的普通数组,并且把原元素拷贝过去,释放原数组内存,注意图中底层数组的内存起始地址已经变了。
同时也注意此时capicity和size的变化,是成倍改变的!
而在本案例中,我们使用vector来做insert的操作,此时大家可会发现,虽然表面上复杂度是O(n2),但是,其底层都不知道额外做了多少次全量拷贝了,所以算上vector的底层拷贝,整体时间复杂度可以认为是O(n^2 + t × n)级别的,t是底层拷贝的次数。
所以,虽然插入操作的理论时间复杂度没有改变,但 在实践中,由于std::list不需要移动元素,所以实际运行时间会更短。这就是为什么使用std::list后代码运行时间减少的原因。
参考:
代码随想录-vector和list差别解释