前言
Nacos的压测性能是非常好的,这里是Nacos官方的压测报告。3节点(CPU 16核,内存32G)规模集群,压测容量服务数可达60W,实例注册数达110W,集群运行持续稳定,达到预期;注册/查询实例TPS达到 13000 以上,接口达到预期;
这种性能对于绝大数大中小型企业来说,已经够用了。但是假设我们有一个场景,Nacos不单单是服务于集团公司内部,而是PaaS化了,业务在世界各地开花,那所需管理的服务实例,就不是小百万,而是达到了几百万 ,甚至千万等等。那么依靠Nacos现在开源版本是很难支持这种场景的。
Nacos注册中心集群原理
分布式CAP黄金定律不再赘述。Nacos中的配置中心其实没什么CP或AP,因为配置中心的数据是存在一个Mysql中的,只有注册中心的数据需要进行集群节点之间的同步,从而涉及到是CP还是AP,如果注册的节点是临时节点,那么就是AP,如果是非临时节点,那么就是CP,默认是临时节点。
Nacos支持CP+AP模式,即Nacos可以根据配置识别为CP模式或AP模式,默认是AP模式。
- 如果注册Nacos的client节点注册时ephemeral=true,那么Nacos集群对这个client节点的效果就是AP,采用distro协议实现
- 而注册Nacos的client节点注册时ephemeral=false,那么Nacos集群对这个节点的效果就是CP的,采用raft协议实现 (学过zookeeper的ZAB 肯定不会陌生raft)
根据client注册时的属性,AP,CP同时混合存在,只是对不同的client节点效果不同。Nacos可以很好的解决不同场景的业务需求。
distro 、 raft 这两种分布式一致性协议,具体细节我不在这里展开篇幅讲述,因为涉及的内容真的太多了~读者可以先去提前了解一下。本文只给出一点基础结论,以便形成全文连贯。
distro
在 Distro 协议的设计思想下,每个 Distro 节点都可以接收到读写请求。所有的Distro协议的请求场景主要分为三种情况:
- nacos每个节点是平等的都可以处理写请求,同时把数据同步到其他节点
- 每个节点只负责部分数据,定时发送自己负责的数据的校验值到其他节点来保持数据一致性
- 每个节点独立处理读请求,及时从本地发出响应
raft
raft 有master follower两种角色。master负责读写,follower只负责读,收到写请求会转发给master完成写。一次写操作,要经过半数follower写入成功ack应答,才能算完成一次成功的写操作。master、follower最终都拥有全量数据,达到数据一致性。
这里总结一下 ,不管是哪种协议实现,都有一个问题存在,那就是集群每个节点都拥有全量注册信息数据。那么问题就来了,
- 上述场景中如此庞大的服务实例数目,要多大的内存才能够呢?
- 增加新Nacos节点的时候,全量复制将是举步维艰,该如何尽快恢复集群健康以达到可以对外服务呢?
- 以后服务实例越来越多,怎么支持快速扩容呢?
按照现有开源的Nacos设计,很难满足。所以需要二开。
笔者的一种设计思想就是分布式化设计。像elasticsearch、redis那样的分布式设计思想。
分布式注册中心架构设计
将完整的庞大的注册表信息分布式存储。存储于集群中的各个Nacos节点中。每个节点存储一部分注册表信息。节点中划分主从两种角色,进行主从复制以及主从替换,使其具备高可用特征。如下图所示,一个6个节点,三组主从架构模式组成了分布式Nacos集群。
这样设计的优点
- 支持横向扩展
- 提高性能,数据分布在多个node,即多台服务器上,所有的操作,都会在多台机器上并行分布式执行,提高了吞吐量和性能。
接下来我们来详细思考一下读写怎么设计?
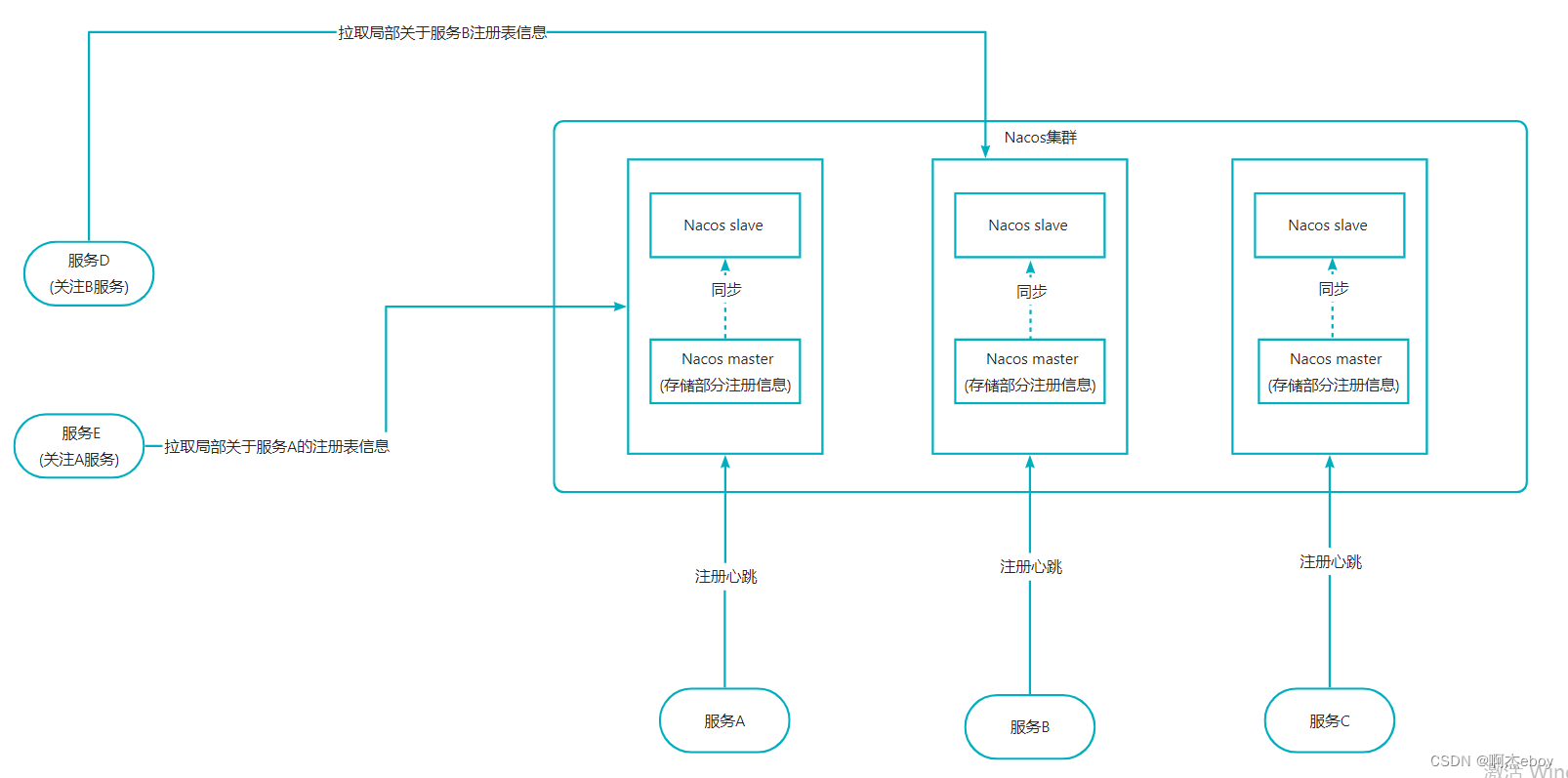
写
服务进行注册时,根据当前服务实例信息,封装成instance信息
- 客户端hash选择一个 node 发送请求过去,这个 node 就是 coordinating node(协调节点)。
- coordinating node 对 instance中的服务名进行路由,将请求转发给对应的 node。
- 实际的 node 处理请求,然后将数据同步到 salve node。
coordinating node 如果发现 master node 和所有 salve node 都搞定之后,就返回响应结果给客户端。
读
- 客户端发送请求到任意一个 node,成为 coordinate node。
- coordinate node 对 服务名 进行哈希路由,将请求转发到对应的 node,此时可以使用 读写分离等选择在 master node以及其所有 salve node 中轮询算法选择一个,让读请求负载均衡。
- 接收请求的 node 返回 注册表信息 给 coordinate node。
- coordinate node 返回 注册表信息 给客户端。
新增节点
新增节点,必然会影响现有的hash路由,导致协调节点不能准确转发给拥有实际注册表的节点。所以新增节点,集群必须先经过一段短暂的时间用于将现有注册表信息归一重新划分到各个节点上。这个过程有点类似再hash。扩容再hash可以有两种方式:
- 常规hash。在形成的扩容后,将旧hash表hash迁移到新的hash表去,直到迁移完毕,以新的hash表对外服务。
- 渐进式hash。新旧hash同时存在,共同对外服务,同时一边数据hash迁移。直到迁移完毕,回收旧hash表。Redis hash结构就用到了这个方式。
节点崩溃
分布式集群下,节点崩溃有三种场景:
- 主从架构下的从节点宕机崩溃
- 主从架构下的主节点宕机崩溃
- 主从架构下的主从节点同时崩溃
第一种场景,没有影响,基于高可用机制,不管宕机多少个从节点,还有主节点可以提供服务。
第二场景,有一点点影响,因为基于主节点可写,在从节点重新选主晋升主节点前,服务不可写。直到从从节点晋升主节点后,集群恢复正常。主从替换时间很小,所以影响有一点点。
第三种场景,这种情况要分两种情况来说:
- 对于集群自身来说,影响较大,这意味着hash路由到这一组node 节点不可读写,丧失服务能力。
- 对于基于注册中心的应用来说,因为nacos客户端维护了注册表缓存,意味着理想情况下,依旧可以保持应用正常运行。



![[附源码]Python计算机毕业设计Django在线图书销售系统](https://img-blog.csdnimg.cn/a0839601941e431fa30505e675ed36e0.png)



![[附源码]Python计算机毕业设计Django疫情期间小学生作业线上管理系统](https://img-blog.csdnimg.cn/31597253376a4e3084e85db5cdd0d6e4.png)

![[附源码]Python计算机毕业设计Django智能家电商城](https://img-blog.csdnimg.cn/71c136aab6b3465a8d2c8bf67061f916.png)
