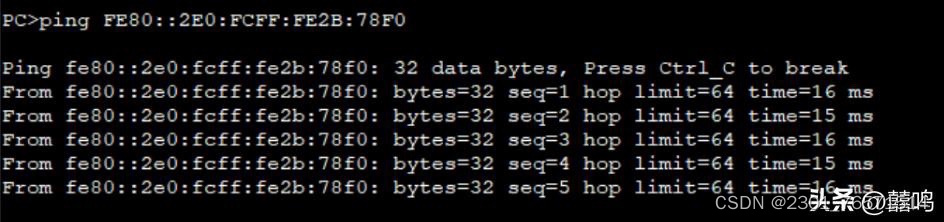
目录
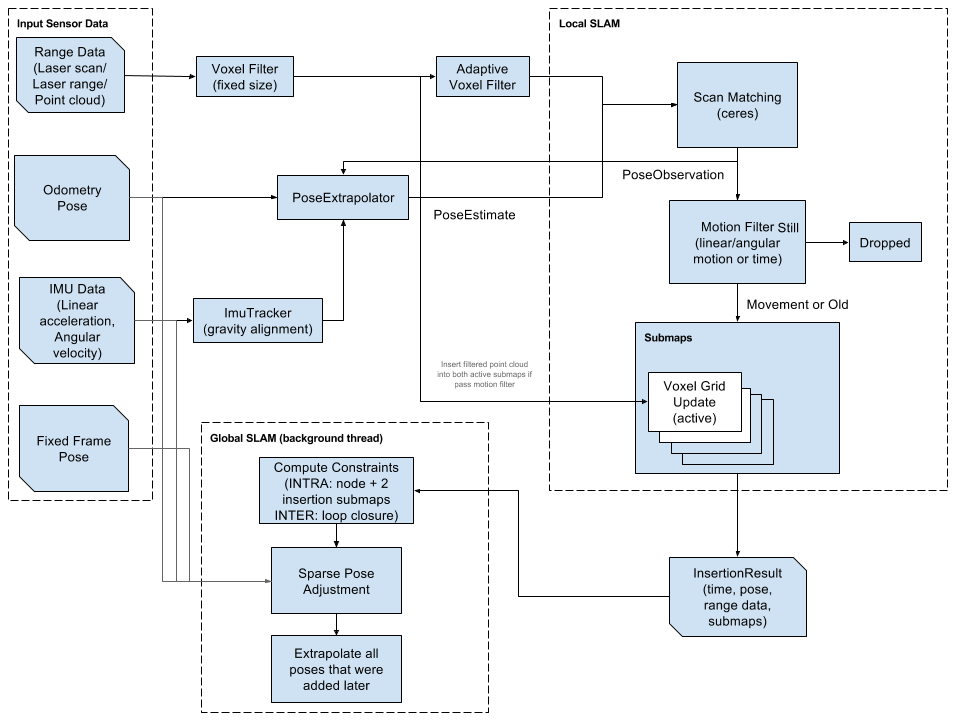
LLM 适配器(LLM Adapter)
Embedding 生成器(Embedding Generator)
缓存管理器(Cache Manager)
相似性评估器 (Similarity Evaluator)
后期处理器(Post Processors)
所以整个 GPTCache 系统共包含五个主要组件:

LLM 适配器(LLM Adapter)
适配器将 LLM 请求转换为缓存协议,并将缓存结果转换为 LLM 响应。由于想让 GPTCache 变得更加透明(这样用户无需额外研发,便可将其轻松集成到我们的系统或其他基于 ChatGPT 搭建的系统中),所以适配器应该方便轻松集成所有 LLM,并可灵活扩展,从而在未来集成更多的多模态模型。
目前,我们已经完成了 OpenAI 和 LangChain 的适配器。未来,GPTCache 的接口还能进一步扩展,以接入更多 LLM API。

Embedding 生成器(Embedding Generator)
Embedding 生成器可以将用户查询的问题转化为 embedding 向量,便于后续的向量相似性检索。为满足不同用户的需求,我们在当下支持两种 embedding 生成方式。第一种是通过云服务(如 OpenAI、Hugging Face 和 Cohere 等)生成 embedding 向量,第二种是通过在 ONNX 上使用本地模型生成 embedding 向量。
后续,GPTCache 还计划支持 PyTorch embedding 生成器,从而将图像、音频文件和其他类型非结构化数据转化为 embedding 向量。
缓存管理器(Cache Manager)
缓存管理器是 GPTCache 的核心组件,具备以下三种功能:
缓存存储,存储用户请求及对应的 LLM 响应向量存储,存储 embedding 向量并检索相似结果逐出管理,控制缓存容量并在缓存满时根据 LRU 或 FIFO 策略清除过期数据缓存管理器采用可插拔设计。最初,团队在后端实现时使用了 SQLite 和 FAISS。后来,我们进一步扩展缓存管理器,加入了 MySQL、PostgreSQL、Milvus 等。
逐出管理器通过从 GPTCache 中删除旧的、未使用的数据来释放内存。必要时,它从缓存和向量存储中删除数据。但是,在向量存储系统中频繁进行删除操作可能会导致性能下降。所以,GPTCache 只会在达到删除阈值时触发异步操作(如构建索引、压缩等)。

相似性评估器 (Similarity Evaluator)
GPTCache 从其缓存中检索 Top-K 最相似答案,并使用相似性评估函数确定缓存的答案是否与输入查询匹配。
GPTCache 支持三种评估函数:精确匹配(exact match)、向量距离(embedding distance)和 ONNX 模型评估。
相似性评估模块对于 GPTCache 同样至关重要。经过调研,我们最终采用了调参后的 ALBERT 模型。当然,这一部分仍有改进空间,也可以使用其他语言模型或其他 LLM(如 LLaMa-7b)。对于这部分有想法的小伙伴可以联系我们!
后期处理器(Post Processors)
后期处理器整理最终响应返回给用户。它可以返回最相似的响应或根据请求的温度参数调整响应的随机性。如果在缓存中找不到相似的响应,后期处理器则会将请求转发给 LLM 来生成响应,同时生成的响应将被存储在缓存中。

![[AJAX]原生AJAX——服务端如何发出JSON格式响应,客户端如何处理接收JSON格式响应](https://img-blog.csdnimg.cn/2c23e9e2336341c3a70eded9223e4f10.png)