文章目录
- 二维激光SLAM
- 简单框架
- 前端
- scan matching
- Submaps构建
- 后端
- 分支定界优化csm(CorrelativeScanMatch)
- 代码实现框架
Cartographer(论文名:Real-Time Loop Closure in 2D LIDAR SLAM)是目前二维激光SLAM中应用最广泛的,尤其在工业界,堪称工业神器。Cartographer由谷歌工程师所写,框架十分复杂,想要详细了解Cartographer框架和代码实现细节,我强烈推荐 无处不在的小土的Blog。
这里我只是帮助大家快速理解一下Cartographer的核心,我并不会按照论文顺序来讲,我的blog风格就是 浅显易懂,因此我对 理解框架最为看重。
二维激光SLAM
看这篇文章你至少应该之前就对二维激光SLAM有所了解(默认了解基础概念,前端/后端,滤波器/图优化)。其实二维SLAM一般来说就了解一下四个算法(gmapping,hector,karto,cartographer)。
- Gmapping是基于粒子滤波的算法,我会拿另一篇文章去讲,Gmapping之前都是基于滤波器的算法(EKF-SLAM,FastSLAM等),但是几乎可以这么说,基于滤波器的后端算法在二维激光SLAM中已经被淘汰了,有人这么说“Gmapping不是最好的SLAM算法,但他是特定时代下最优美的解决方法”,我觉得很有道理。
- Hector的核心就是使用了scan to map来进行前端的扫描匹配,简单而言就是用当前激光和累计出来的地图进行匹配,通过将激光投影到栅格上进行打分,然后使用高斯牛顿法求最优的位姿。
- karto主要贡献是引入了后端图优化,使用submap代替全局地图进行匹配和优化,但是表现不如cartographer(好像有人说karto其实效果也很好,只是代码实现不如carto,总是没谁用)。
- 简而言之,掌握cartographer约等于掌握了二维激光SLAM
简单框架
cartographer论文根本没有给出框架图,你可以这么理解,carto的作者并不认为自己的文章提出了什么新的框架,它只是整合了一些内容。因此,你可以简单地认为carto的框架其实就是前端+后端。前端使用了的基本和hector一样,就是scan to map(submap)。它的主要工作在后端,使用分支定界优化了CSM算法,然后构建了位姿和submap之间的约束图,使用SPA(一种利用图稀疏性来加速优化,这可以说是真正将图优化投入实际使用的算法,学习到一定深度了可以再去学习,总之是一种快速进行图优化的算法)进行优化。
前端
scan matching
就是前端,核心就是优化这个函数,
ξ
i
\xi_i
ξi就是当前扫到第i个点的局部坐标,
S
i
(
ξ
)
S_i(\xi)
Si(ξ)就是把这个点映射到全局坐标系下。
M
(
.
)
M(.)
M(.)就代表地图,如果被占据概率为1,那扫到1-1=0,自然不算残差,我们也就是希望每个激光点都扫到障碍物上。整个算法用高斯牛顿法优化,具体如何求导的可以去看hector,里面有详细写(其实就是图像求导)。
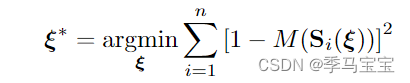
Submaps构建
就是使用静态二值贝叶斯滤波器进行的地图更新,推导大家可以自己去找(比如看概率机器人),小土写的很好。简单来说就是在得到位姿之后,利用射出去的激光来更新地图。
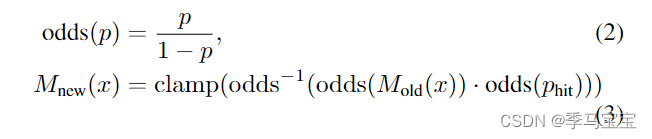
当submap中插入数据到一定量时候,这张submap就算完成了,传入后端不再更新,开启一张新的submap开始建图。核心是它当作短期内构建的submap是准确的。
后端
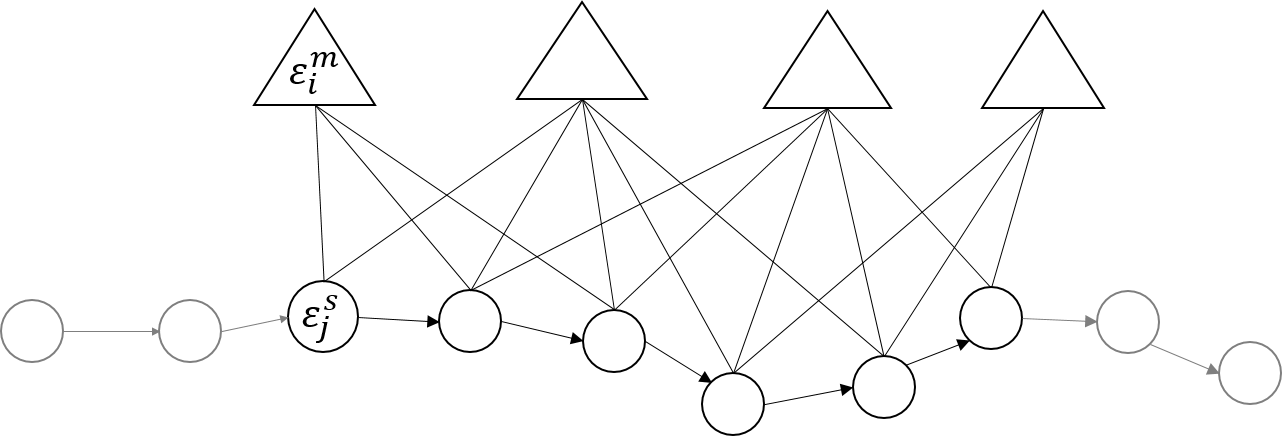
后端核心就是构建一张位姿约图,下面圆代表一个个位姿,上面三角代表一张张submap,每个位姿态可能观测到很多张submap,那么之间就可以构建一个约束。之前前端使用简单的scan matching方法构建的约束精度不够,后端使用csm进行像素级别的匹配。
分支定界优化csm(CorrelativeScanMatch)
其实csm就是一个暴力搜索,二维位姿其实就是 { x , y , θ } \{x,y,\theta\} {x,y,θ}三个变量,我们在初值附近套三重循环暴力搜索,给每个组合算一个分数,取最高的。csm还可以同时处理回环,某帧激光和很久之前一张submap匹配分数非常高的时候,就是找到回环了,也增加约束。
显然,这种算法复杂度很高。其实我们很容易想到一种简单的算法(我瞎想的,便于理解),假设一开始x搜索范围之[-10,10],步长为1,搜一百次,取分数最高的10次,这10次分数都在[-1,1]之间,那我改步长为0.1搜索新的区间。这样肯定比[-10,10]直接以0.1为步长搜索快。
在这个问题中,作者使用了不同分辨率的地图进行匹配(其实和我瞎想的是一个意思),并证明了粗分辨率找到的最优得分是细节分辨率的上界。因为有了这个条件,我们可以使用分枝定界来优化搜索过程,其实就是剪枝的思想,你在粗分辨率的情况下找到的位姿还不如之前细分辨率得到的结果,那没必要在这个位姿下搜索更细的分辨率了。
代码实现框架
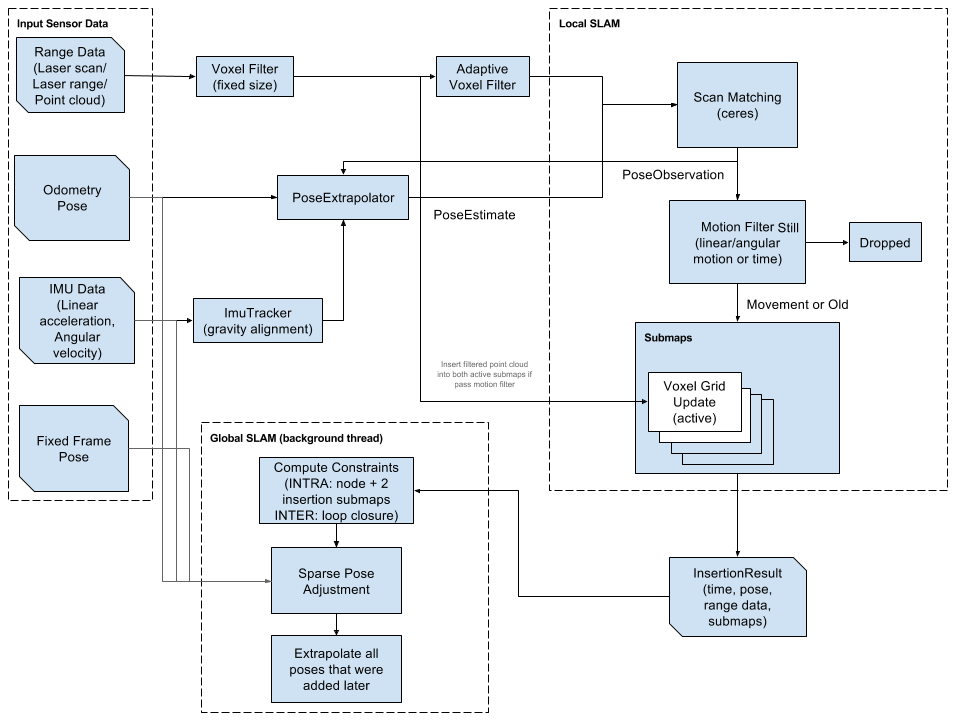
众所周知,SLAM论文只包含了全部内容的20%,剩下80%要在代码中找到答案。下面这张图才是算法在实现时候的真实框架。
首先最左边是输入,Range Data(激光数据),Odometry(里程计),IMU(惯导),Fixed Frame Pose(GPS一类全局定位)。
Range Data首先会经过Voxel filter(体素滤波,用于点云降采样),而IMU和Odom会先经过一个PoseExtraplator(主要用于IMU位姿解算,推导很复杂,PoseExtraplator同时接受Scan Matching的数据,因为传感器是增量式的,应该在之前更新完的位姿上再跟新目前位姿)。过完滤波的Range Data利用PoseEstimate(传感器估计的位姿) 作为初值计算和上一帧相对运动。后面不产生运动的匹配被drop了,可以理解为关键帧吧。一段连续帧被构建成submap,当这个submap完成后被送入后端,即Global SLAM。
后端就是使用分支定界优化的csm计算位姿和submaps之间的约束关系(包含回环,因为位姿和之前的submap很近的时候也会被拿去扫描匹配),构建约束图,然后如果有全局传感器也加入约束图,一起使用SPA优化,最后得到准确的位姿和图。