视频链接:
https://www.bilibili.com/video/BV1t54y1C7ra/?vd_source=b425cf6a88c74ab02b3939ca66be1c0d
yolov3 spp
spp:空间金字塔池化
trick:实现的小技巧,方法。(
up:Bag of Freebies里有很多trick,还有mix up
弹幕:也列举了许多有用的适合yolo的tricks
Bag of freebies YOLOv4论文里的2.2章节
)
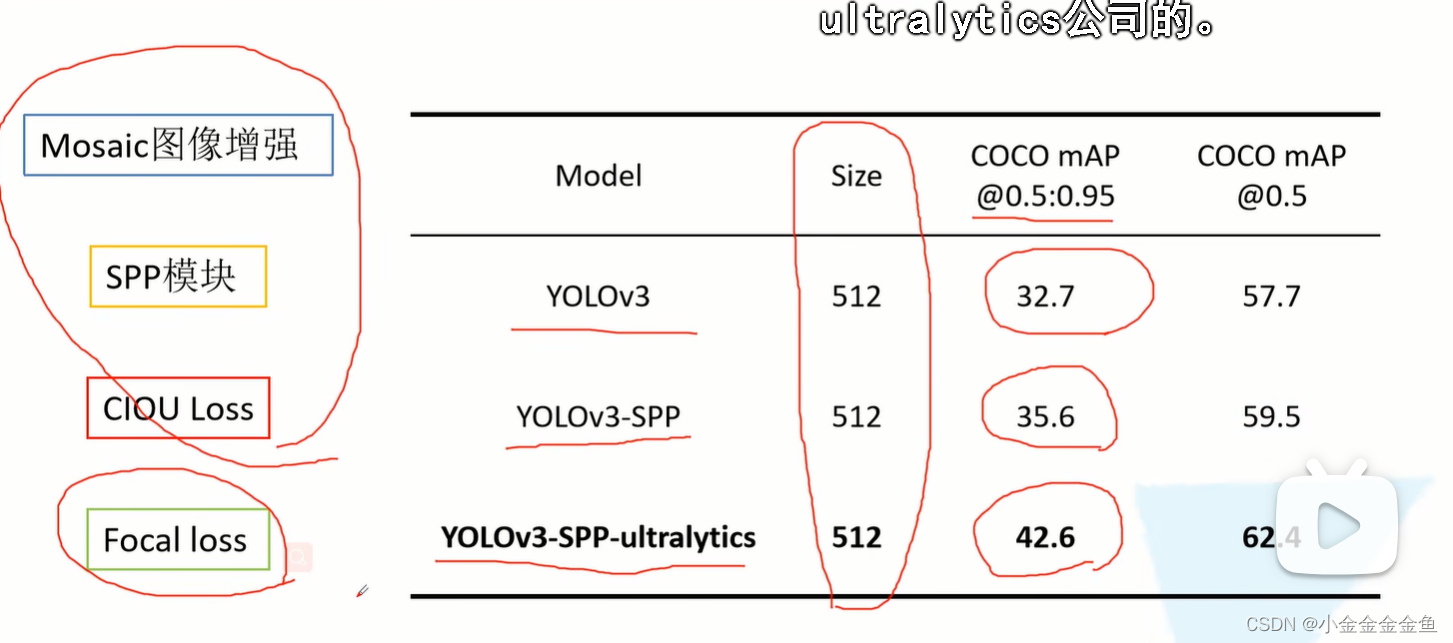
Mosaic图像增强
yolov4中也用的mosaic
之前遇到的图像增强:图像水平翻转、随机裁剪、亮度色度饱和度的调整……
Mosaic图像增强:将多张图片拼接在一起,对网络进行训练。默认使用4张图片进行拼接。
如果要使用BN层的话,batch size尽可能设置的大一些。BN层主要去求每一个特征层的均值和方差,batch size越大,求得的均值和方差就越接近于整个数据集的均值和方差,效果就会越好。
但是由于训练设备受限,GPU无法一次性训练这么多图片。如果将多张图片拼接在一起输给网络,则可以变相增加网络的batch size,一张(由四张图像拼接而成的)图像包含这四张图像的均值和方差信息。
SPP模块
YOLOV3 SPP网络结构跟YOLOV3基本上相同。
唯一不同之处在于,YOLOV3 SPP在Darknet-53与第一个预测特征层前加上了一个SPP模块。
(spp最开始是用在分类模型的)
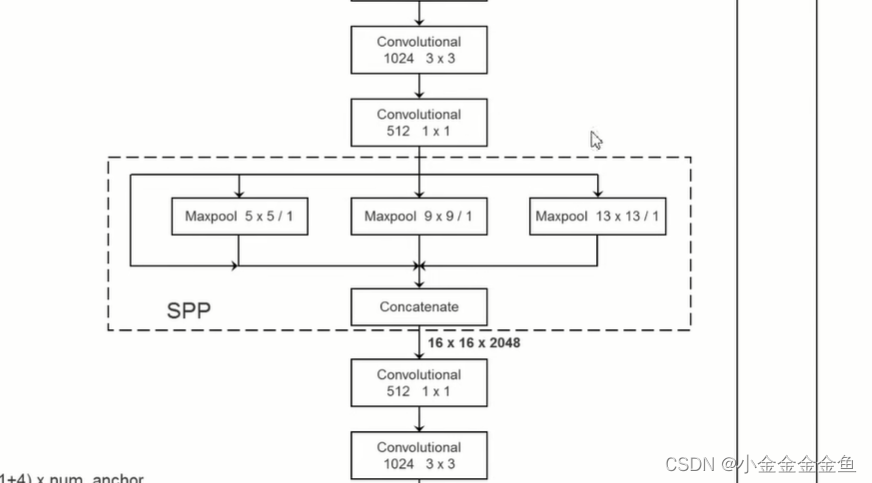
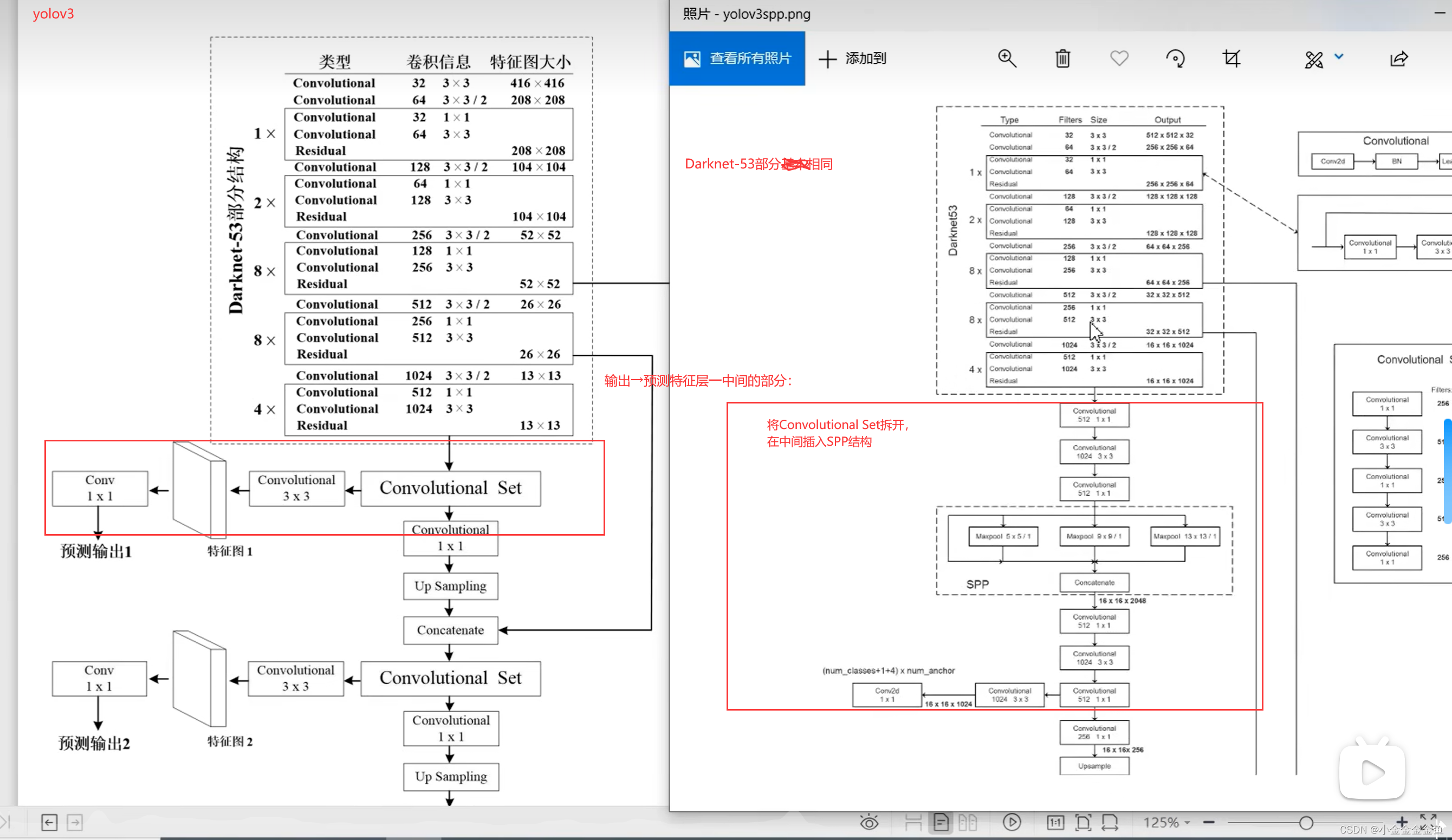
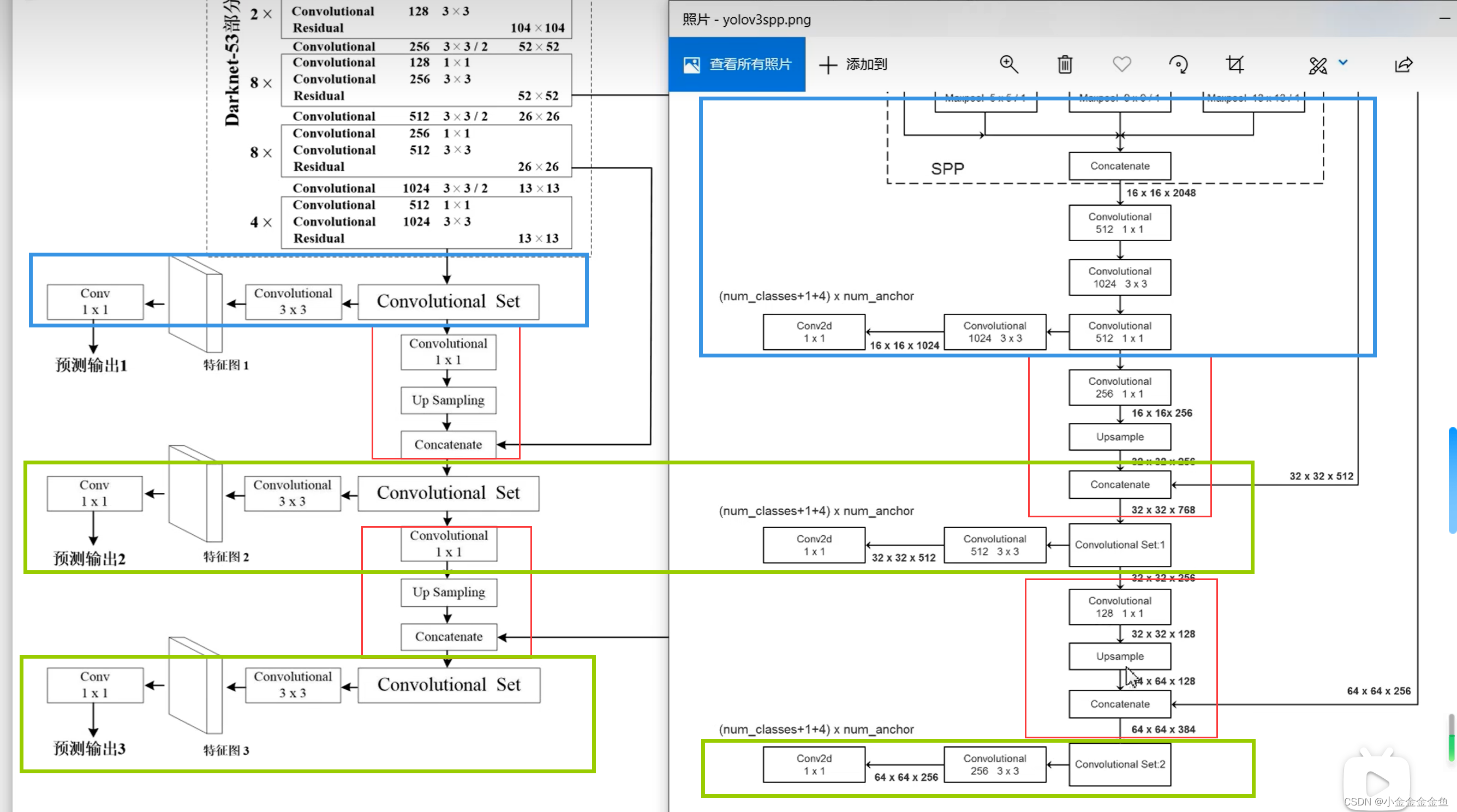
图上的输入是512x512的RGB图像
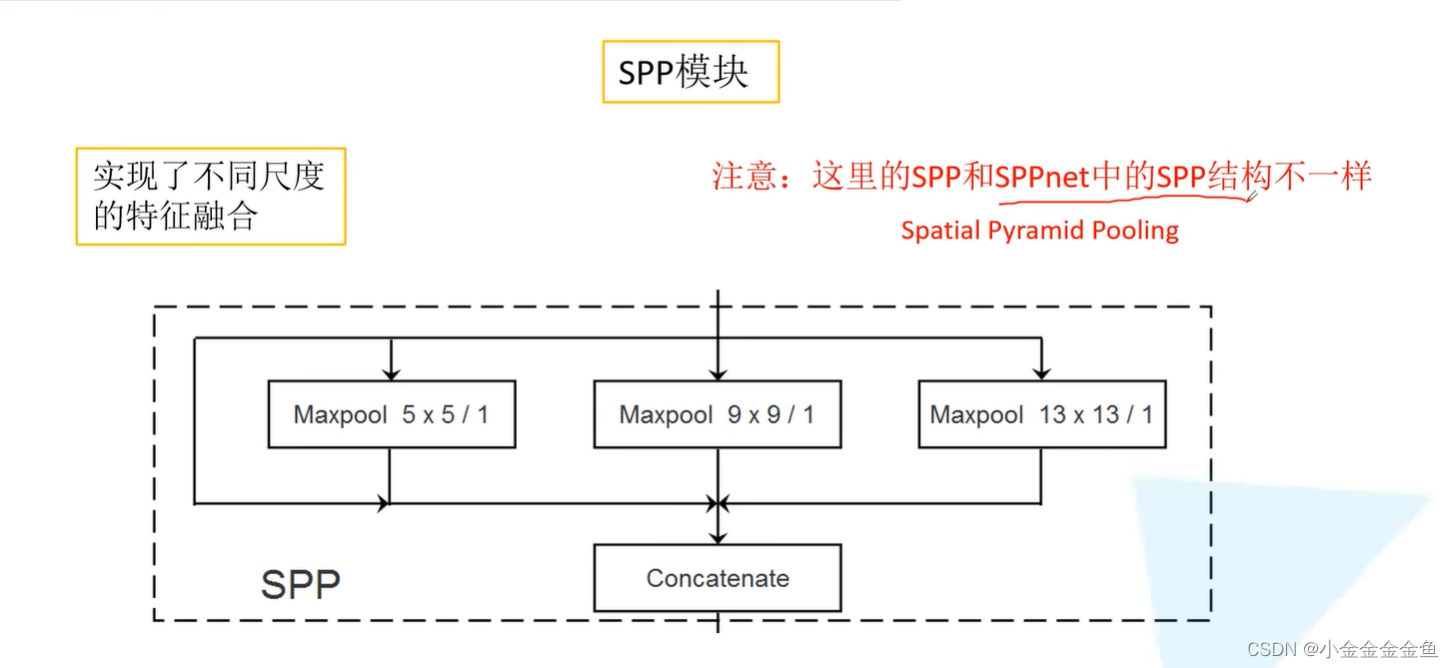
YOLO v3网络中的SPP结构只是借鉴于SPPnet中的SPP结构,二者不同。
第1个分支:由输入直接接到输出。
第2个分支:池化核大小为5x5的最大池化下采样
第3个分支:池化核大小为9x9的最大池化下采样
第4个分支:池化核大小为13x13的最大池化下采样
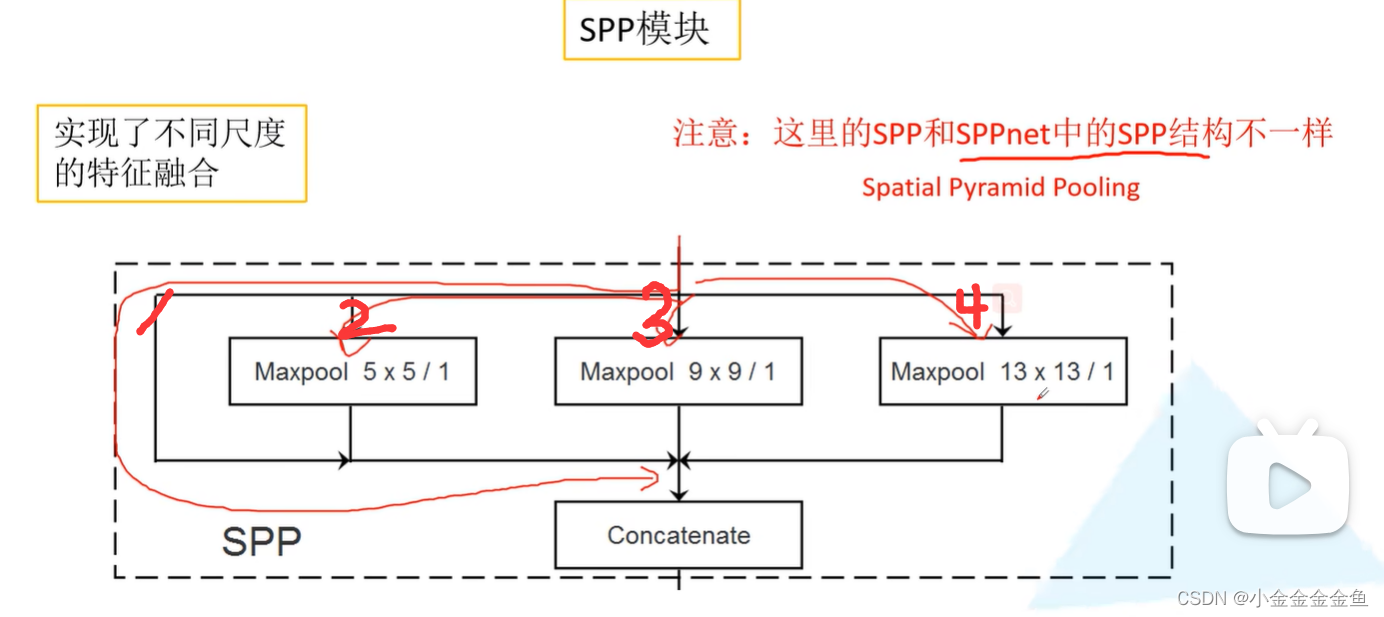
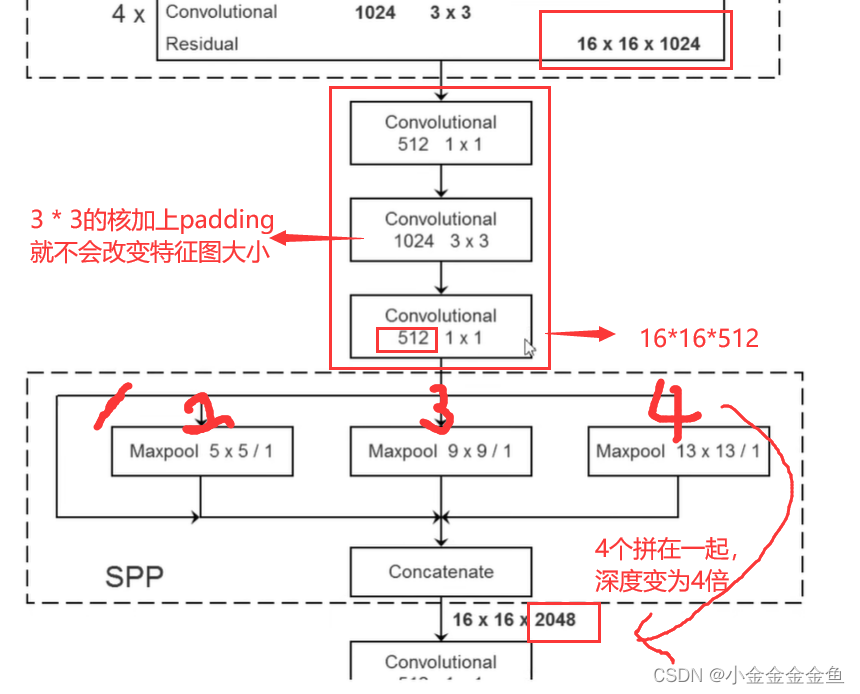
池化步距=1
在做池化之前都对特征矩阵进行padding填充,填充后进行最大池化下采样后特征图的高度宽度深度没有发生变化,都是一模一样的。
(不是步长为1的都不变 是因为采用了填充 最终池化后的特征图大小没变)
此时对它们进行特征拼接,就实现了不同尺度的特征融合。
这个看似简单的结构对算法造成了很大的提升。
为什么只在第一个预测特征层前加了SPP结构,其他的地方不加呢?
可以但是没必要。
spp1只加了一个SPP层,
spp3在每个预测特征层前都加了一个SPP层。
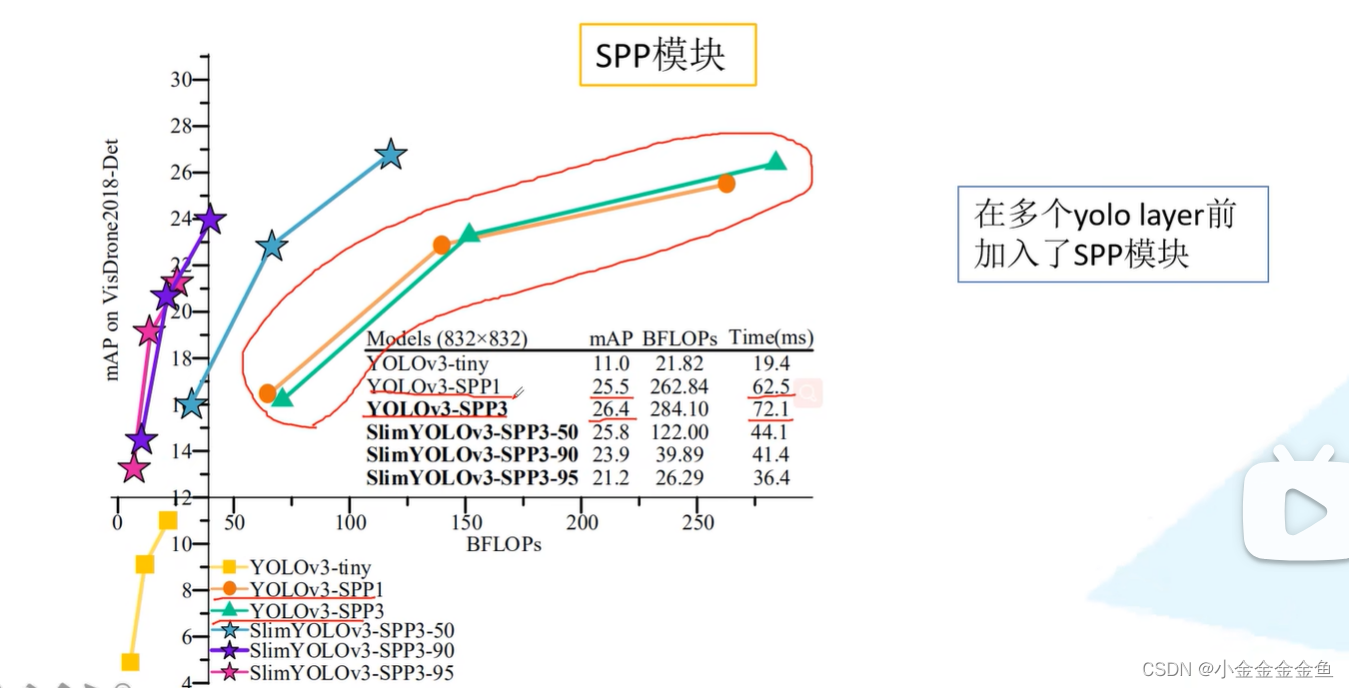
可发现在输入图像尺度比较小的时候,spp1的优势比spp3大,随着输入网络的尺度增大……
mAP提升不大,推理速度变慢。
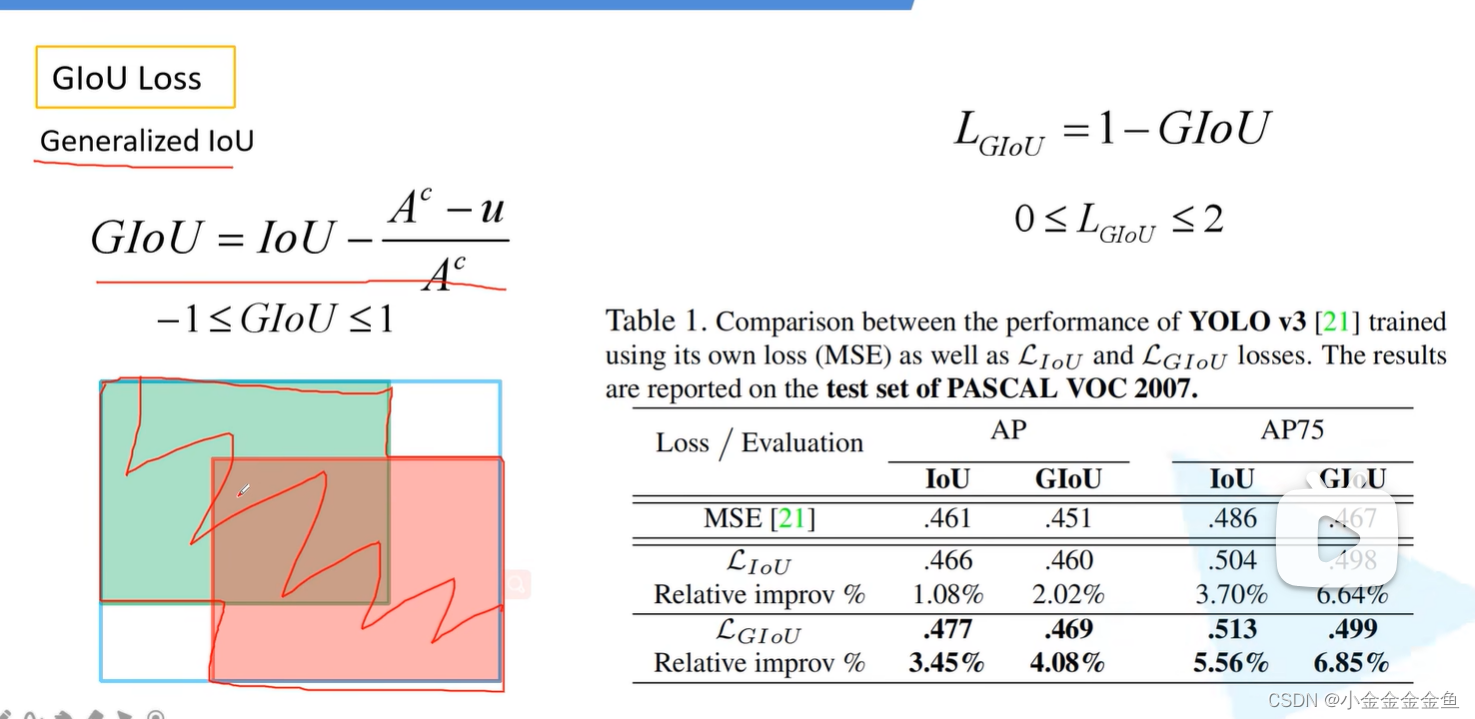
CIoU Loss
yolov3定位损失:差值平方(L2损失,MSE损失)
IoU:交并比
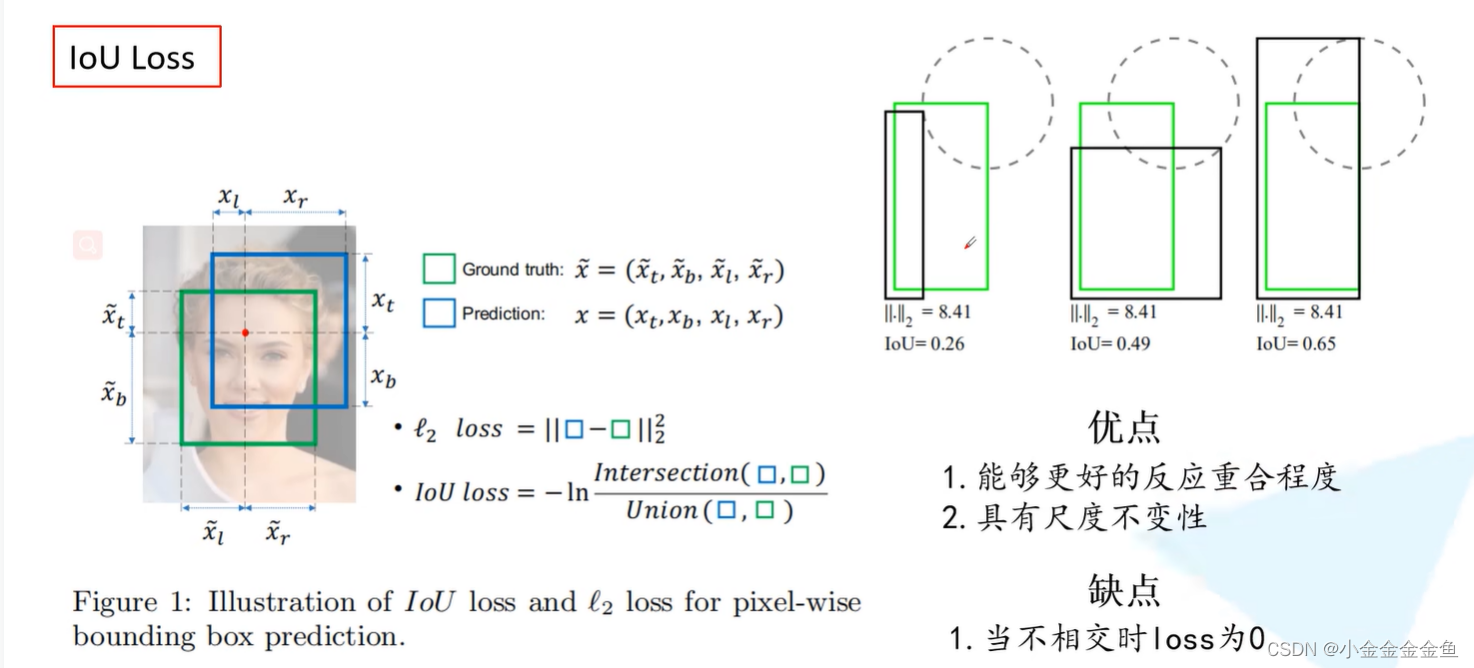
右上角的图展示了三种矩形框重合的实例。绿色为gt。
可以发现最右矩形框的预测效果较好,但是L2损失一样,而IoU不同。说明L2损失不能很好地反应目标边界框的重合程度。
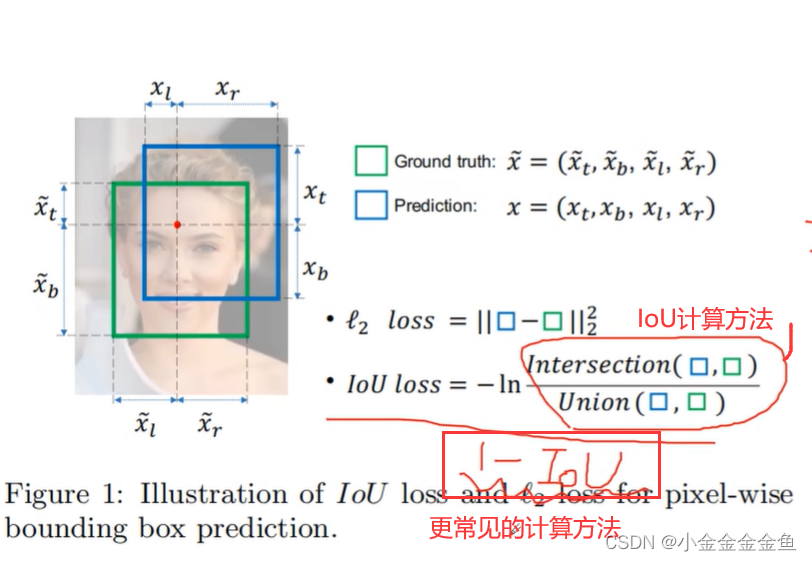

尺度不变性:无论重叠的两个均方大小,重合程度与均方无关
边框不相交的话,无法通过这种方法计算loss。(感觉图里算错了,好像是无穷大,不是0)
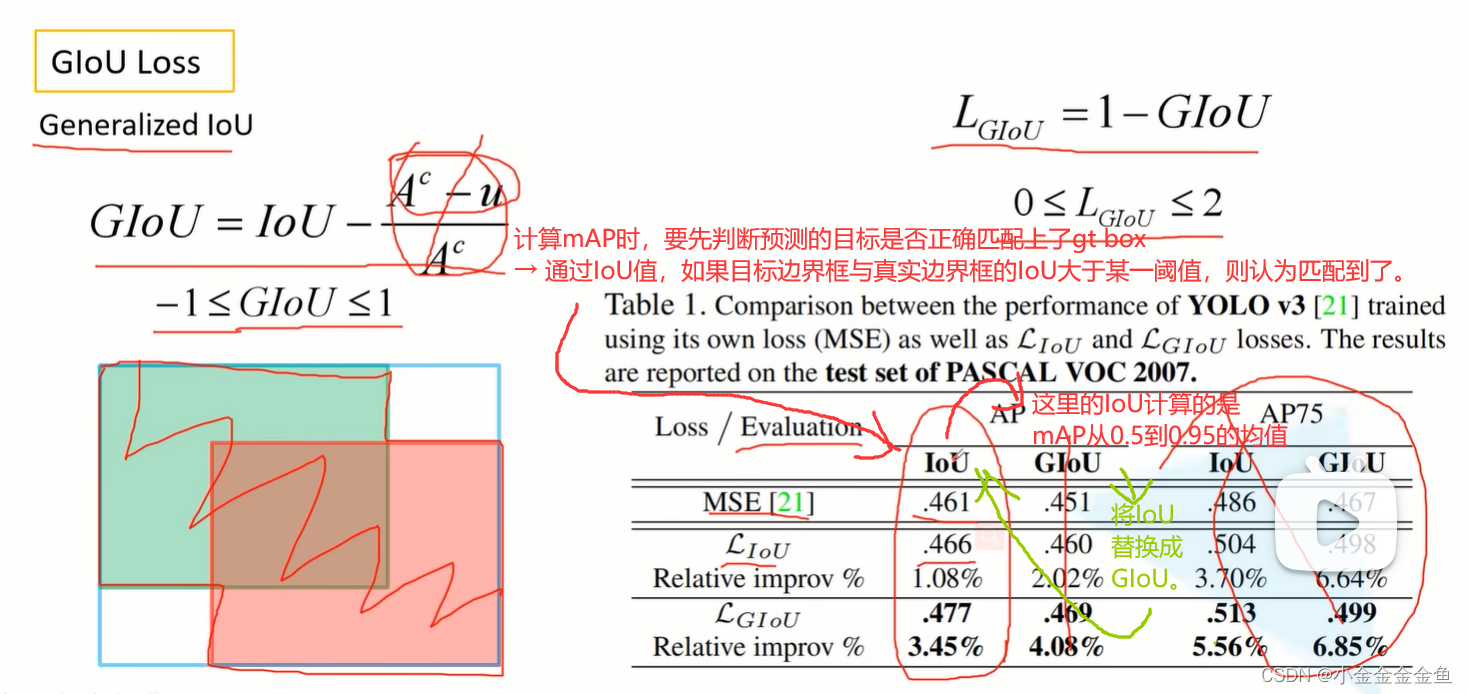
绿:真实目标边界框,
红:网络预测的边界框,
蓝:将上面两个边界框用最小的矩形框柱。
Ac:蓝框面积
u:红绿边界框并集面积
当红绿边界框完美重合在一起,GIoU=IoU-0=1
红绿相距无穷远时,IoU=0,GIoU=0-1=-1
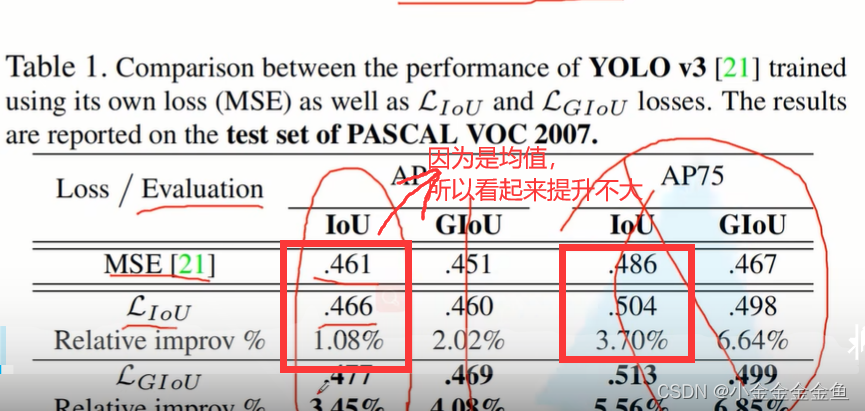
缺点:
当两个目标边界框高度宽度一样的、处于水平或者垂直相交时候

两个问题:收敛慢、回归的不准确
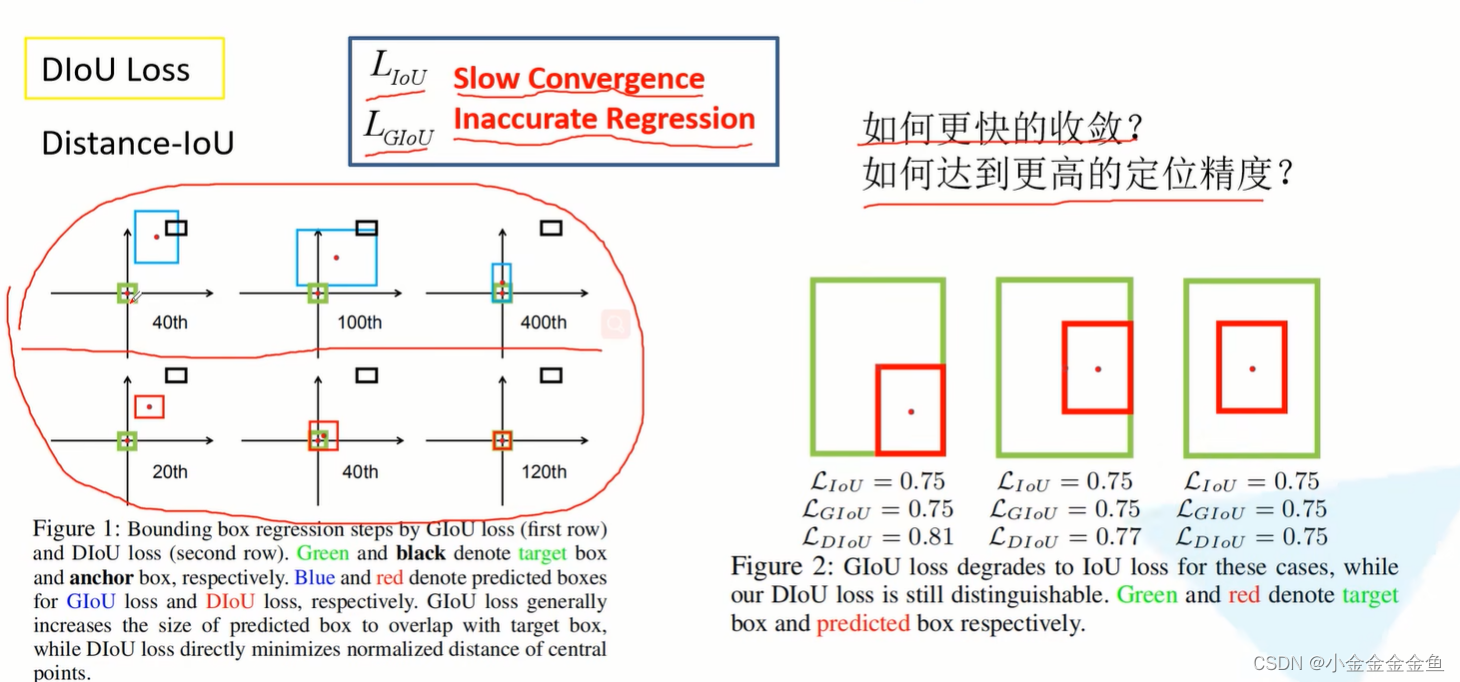
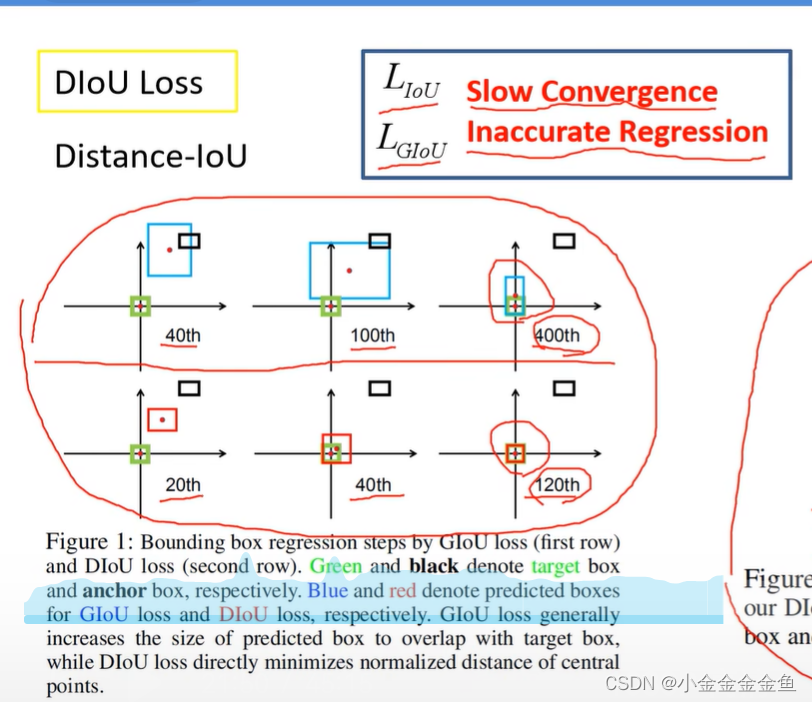
第一行:使用GIoU训练网络,让目标边界框尽可能回归到真实边界框上(蓝色和绿色重合在一起)。
黑色:anchor (或default box)
绿色:真实框
蓝色:预测的框
第二行:DIoU。更快,更好。
重合位置不一样,不同Loss的值:
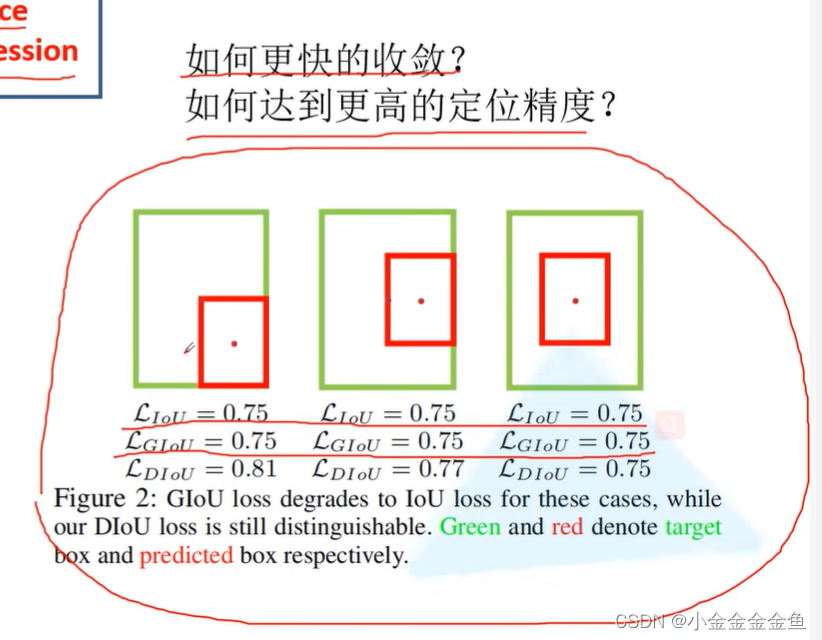
DIoU,重合位置√
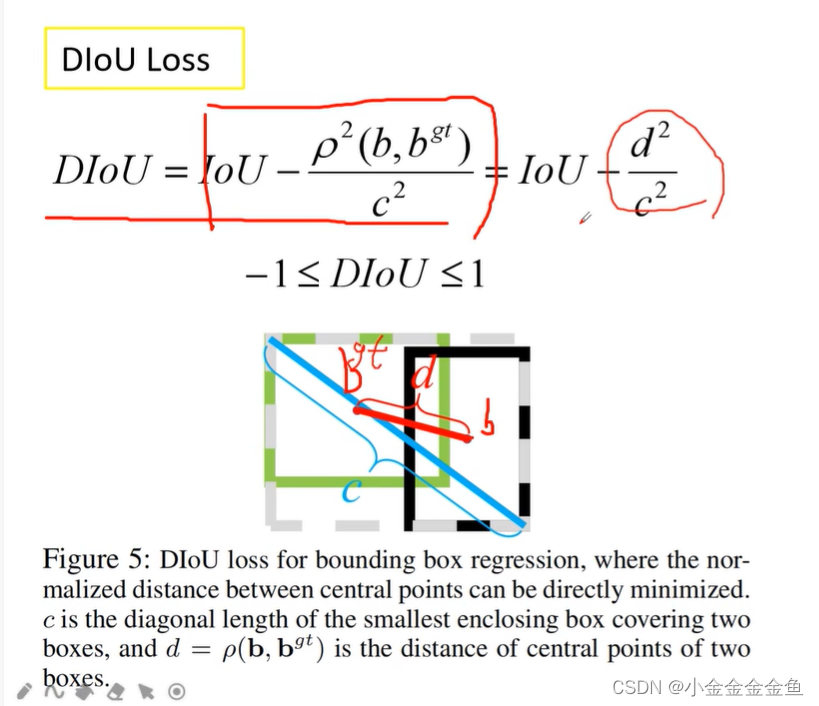
ρ:b个bgt之间的欧氏距离(距离的平方),也就是d
b:预测边界框的中心坐标。
bgt:真实目标边界框中间点的坐标。
c:这两个目标边界框的最小外接矩形的对角线的长度
当两个目标边界框完美重合在一起时,d=0
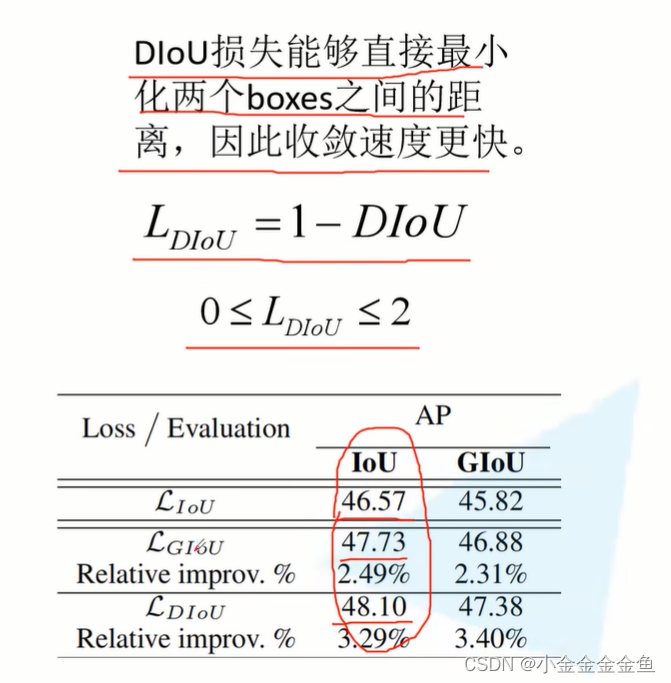
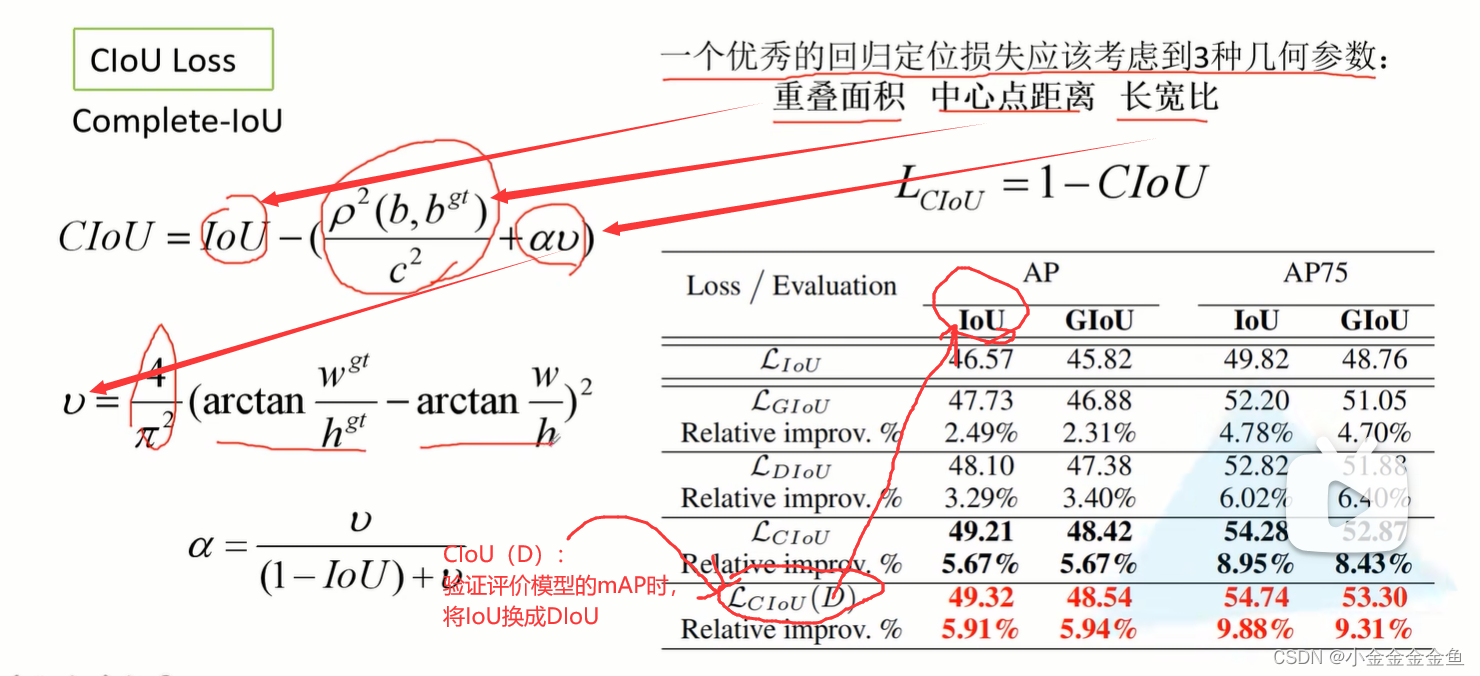
将IoU换成DIoU比较合理,因为IoU无法评价两个目标边界框的重合关系。
现在有很多都用DIoU替换IoU进行评价。

(
弹幕:总之改进的损失就是让预测框尽可能接近标注框
)
对于G、D、CIoU的具体损失效果如何,需要在训练过程中自己尝试实现。
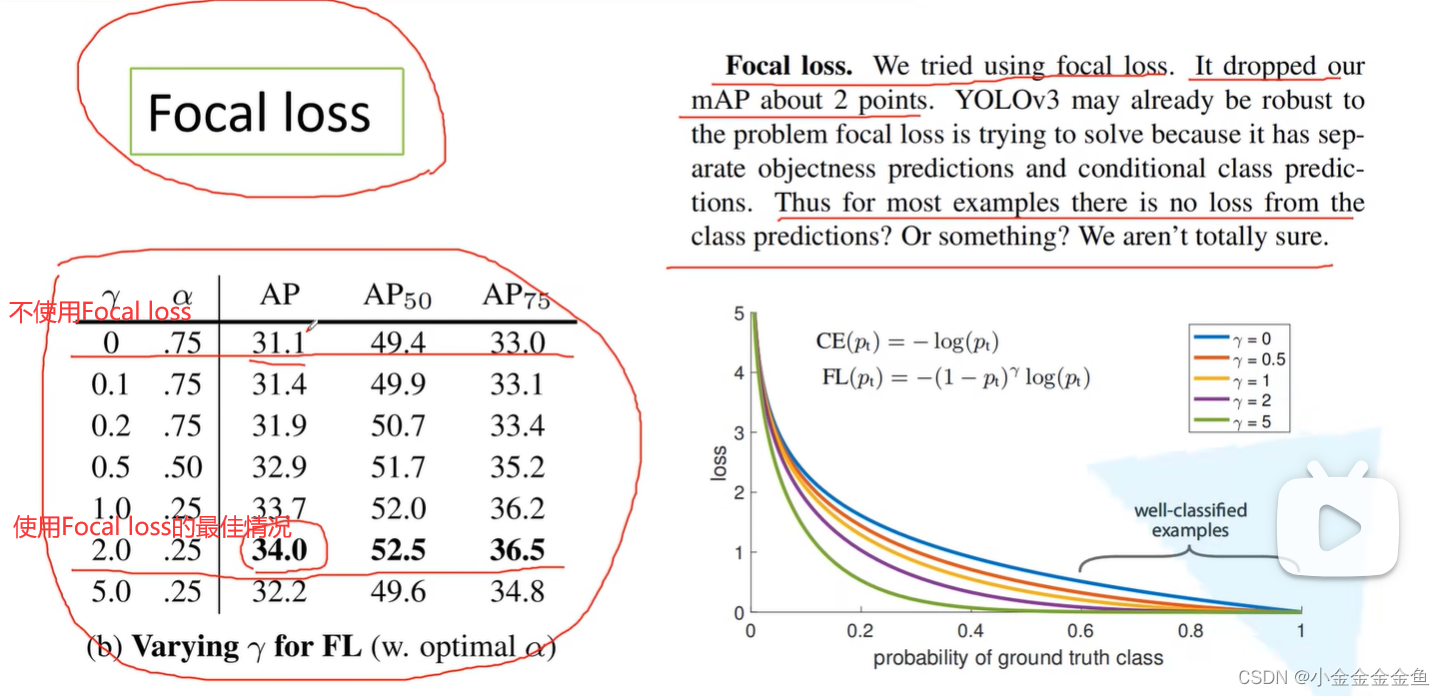
Focal Loss
有人说有用,有人说没用。
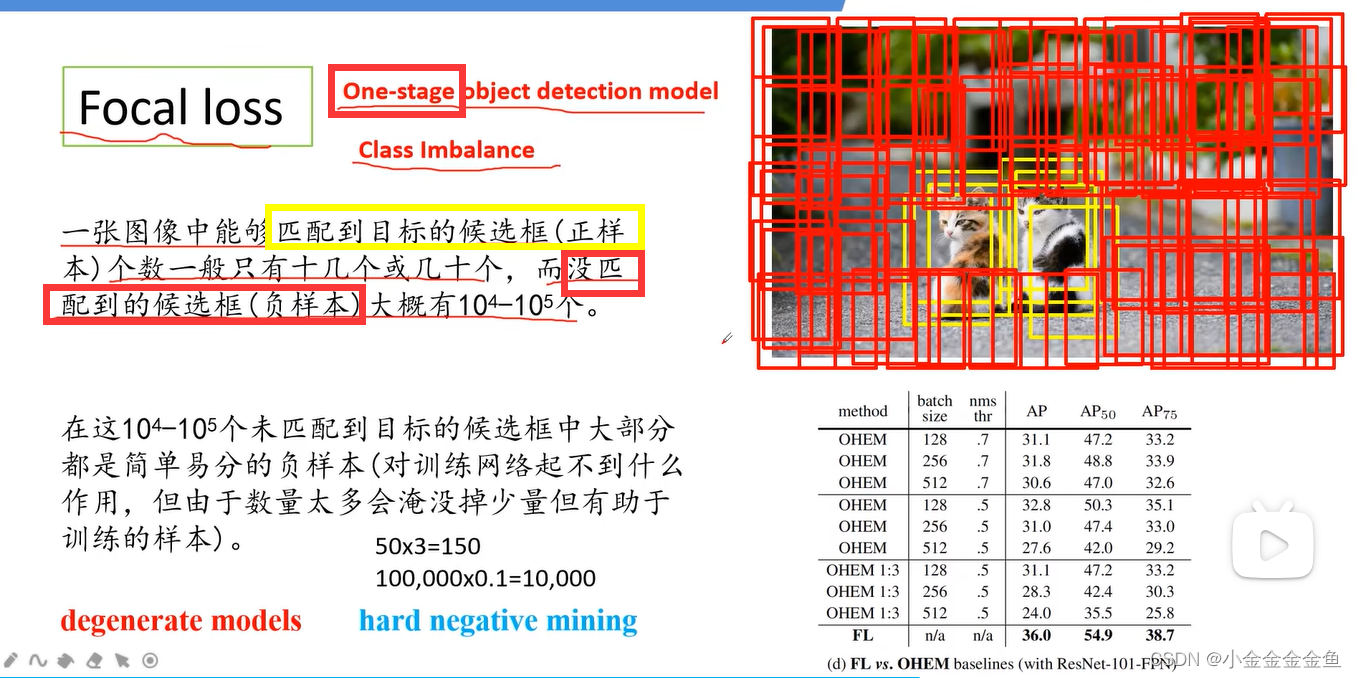
主要针对One-stage模型,但是这些模型都会面临正负样本不平衡的情况。
红:没有匹配到目标。
黄:匹配到目标。
那为什么two-stage的目标检测网络就没听过什么不平衡的问题?
因为它分两步走,第一阶段肯定存在类别分布不均衡的情况,但最终结果是通过第二阶段的检测来确定目标的最终坐标和是否为目标。

degenerate models:假设匹配到50个正样本,贡献的损失为3,总贡献150。负样本每个损失0.1,但由于数量太多,总贡献10000的损失,远远多于正样本的损失。所以直接使用所有样本训练网络的话,模型效果会变差。
hard negative mining:之前讲的网络中:筛选正负样本。并不会使用所有的负样本,而是使用损失比较大的负样本来训练网络。
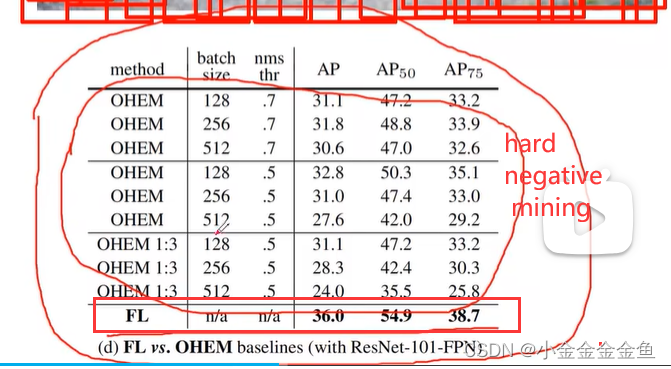
可以看到Focal Loss的提升效果较为明显。

α:用来平衡正负样本的权重。

但是α没法区分哪些是容易的样本,哪些是困难的样本。所以提出一个损失函数,降低简单样本的权重,可以聚焦于训练难以区分的负样本。
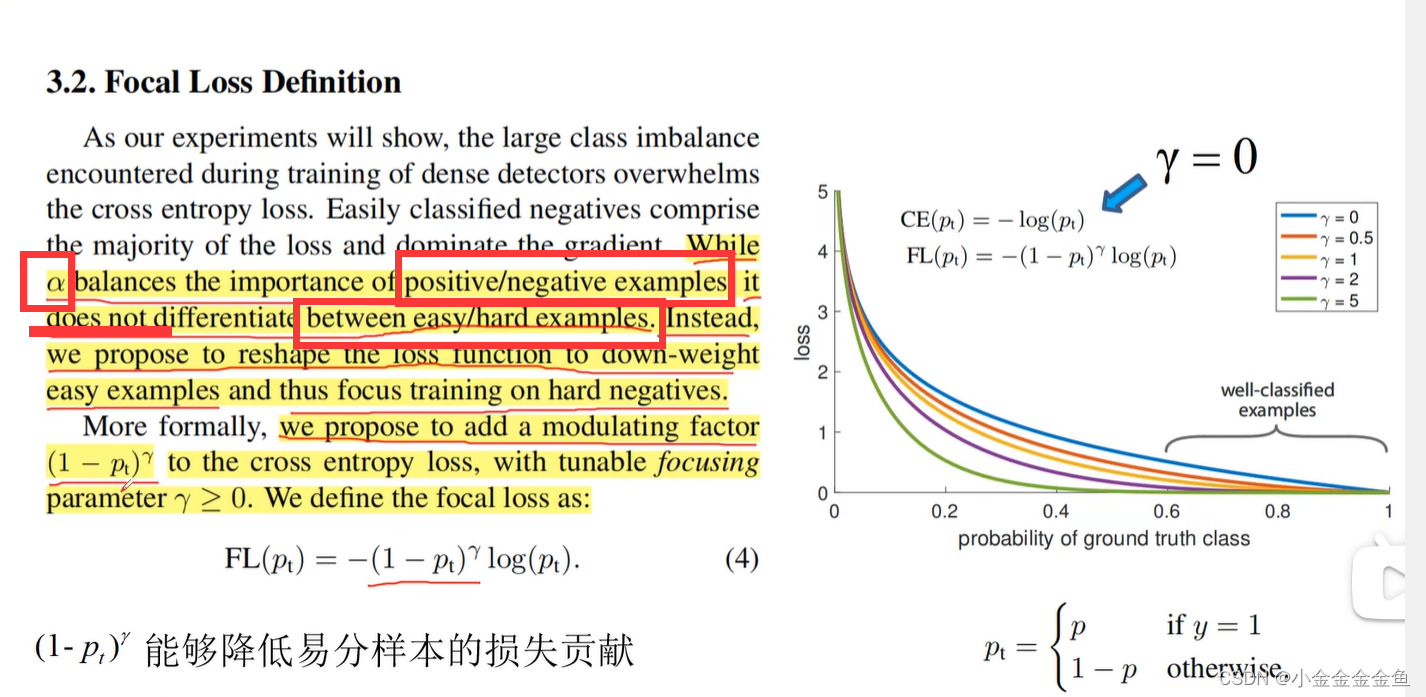
引入(1-pt)的γ次方。
右图横坐标:pt。
正样本:=p,希望这个p越大,预测的越准确;
负样本=1-pt,希望这个1-p越小越好(p越大越好)。
则不管正负样本,都希望pt越大越好。
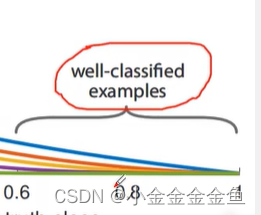
很容易分类的样本,没有必要在它们上面放置很大的权重。
γ变大 → 曲线下降快 → 采取相同pt概率的时候,采用Focal Loss,γ越大,易分样本的权重就越来越小。但也不是γ越大越好(γ=5时,pt=0.4时的权重也很小,这样不对)。
Focal Loss核心:

对于这里的α:
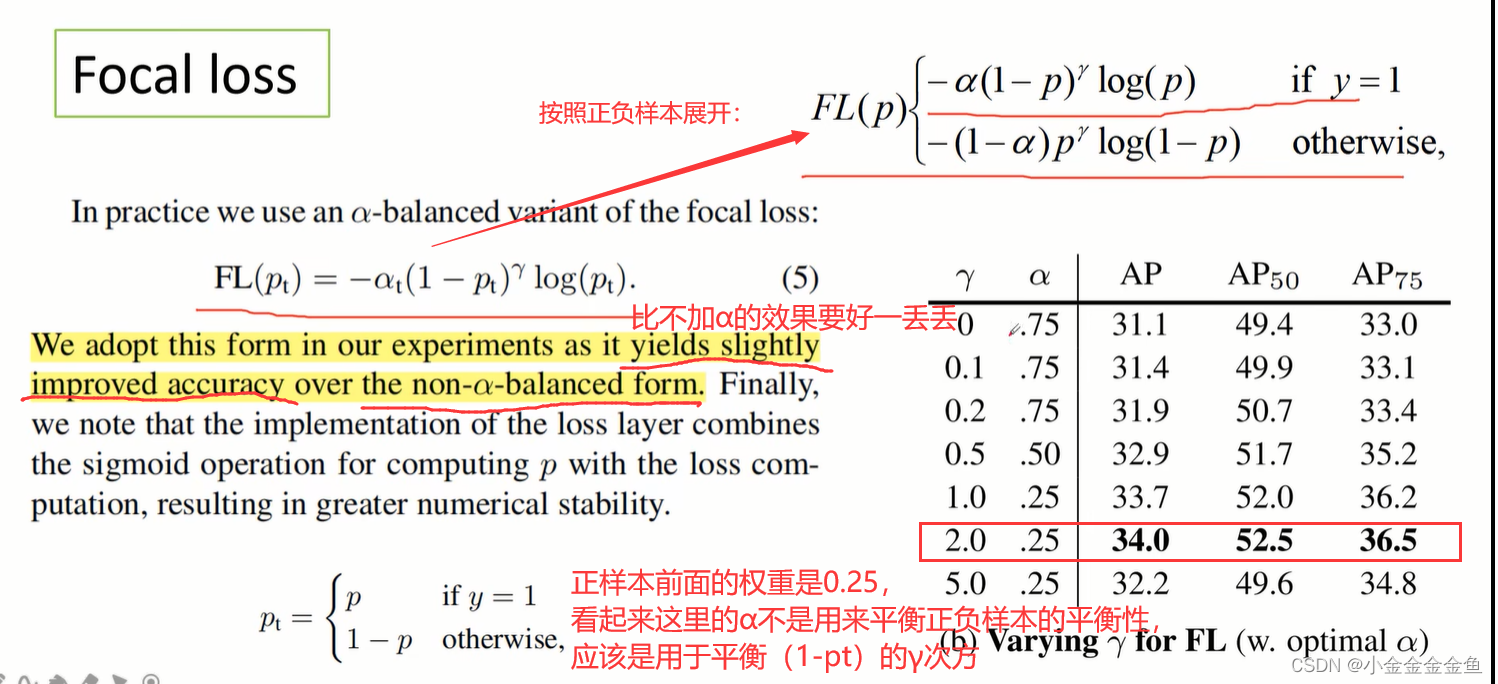
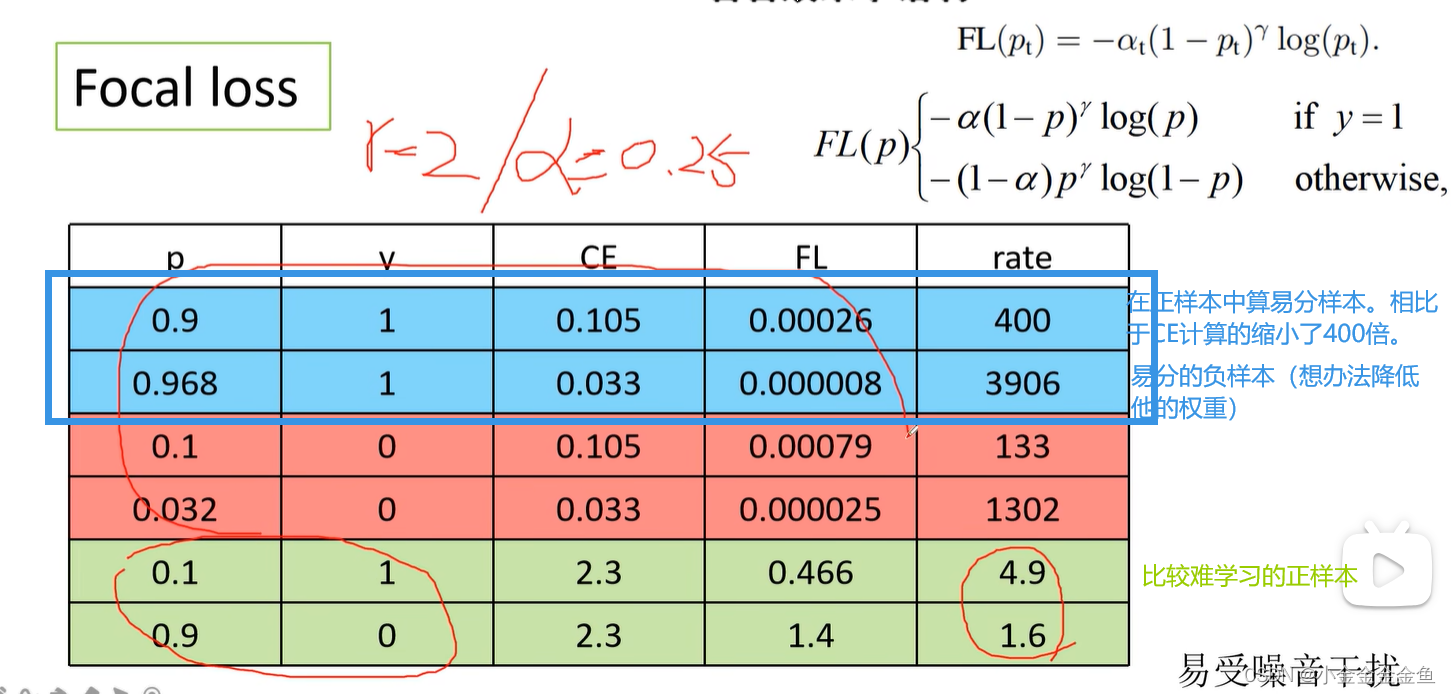
p:预测的目标概率。(不是pt)
y:所对应的真实标签。1:正样本;0:负样本。
CE:针对二分类的交叉熵损失。
FL:Focal loss。
rate:采用CE计算的损失与采用FL计算的损失的比值。
(
弹幕:
绿色样本少量,红蓝样本较多,值乘数量求和后,绿色样本的损失会更大,能起到均衡作用;
弹幕:
实际上训练时负样本预测0.9是非常少的,而正样本预测0.1会很多,Focal Loss是聚焦于学习困难样本,正样本就属于困难样本,所以可以达到自动平衡正负样本的效果;
弹幕:
实际上训练时负样本预测0.9的是非常少的,而正样本预测0.1会很多,所以也可以达到平衡正负样本的效果,不能单看这个数值,也要看数量;
弹幕:
对于容易分的 就使劲降低,难分的 就降少点,总体来讲难分降低的低于易分降低的,最终达到重视难分样本到效果;
)
使用的时候可能要花功夫调参,调的不好的话,效果可能确实没有直接使用传统的CE、hard negative mining好。
Focal loss易受噪声干扰,所以训练集中尽可能标注正确。fl可能会根据标注错误的样本疯狂学习,导致模型效果越来越差。
yolov3 spp 代码
使用简介
up在yolo3代码的基础上进行修改,并简化了训练过程(移除了一些效果不大的trick)

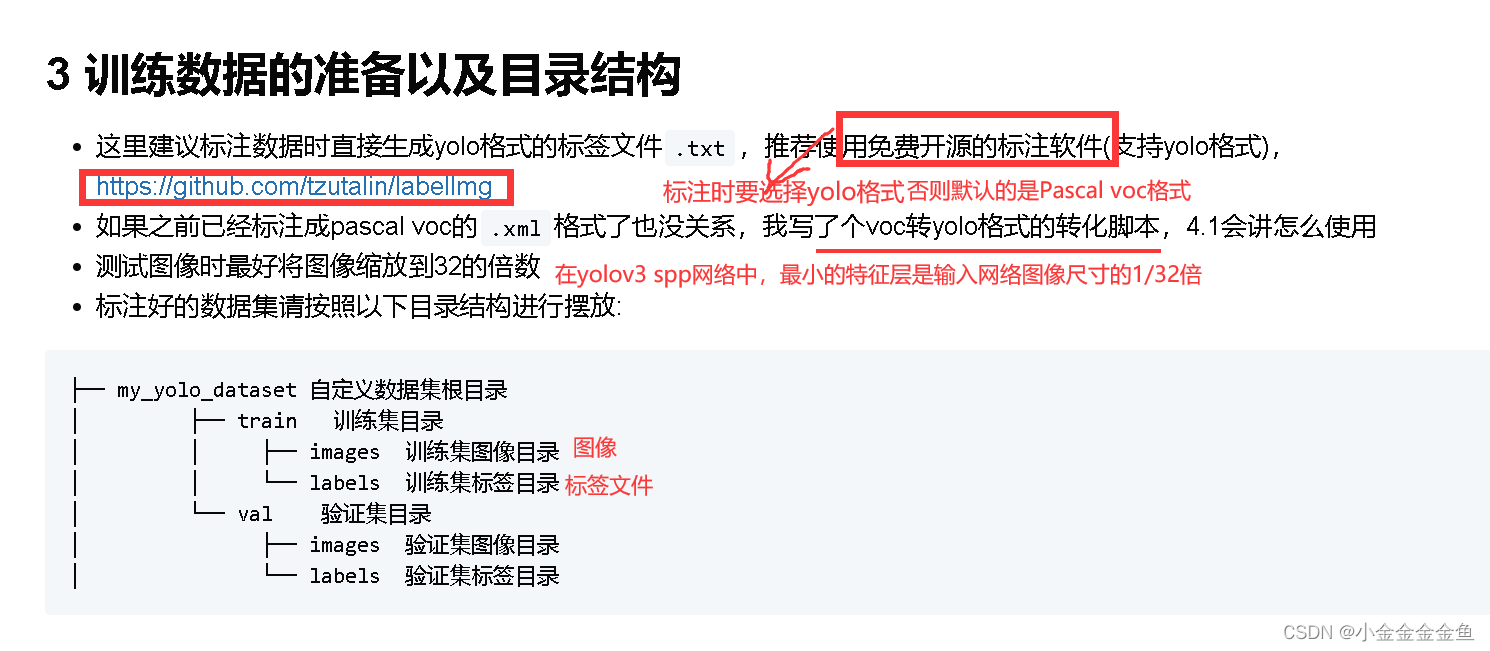
原作者文档中写了如何去训练自己的数据集:
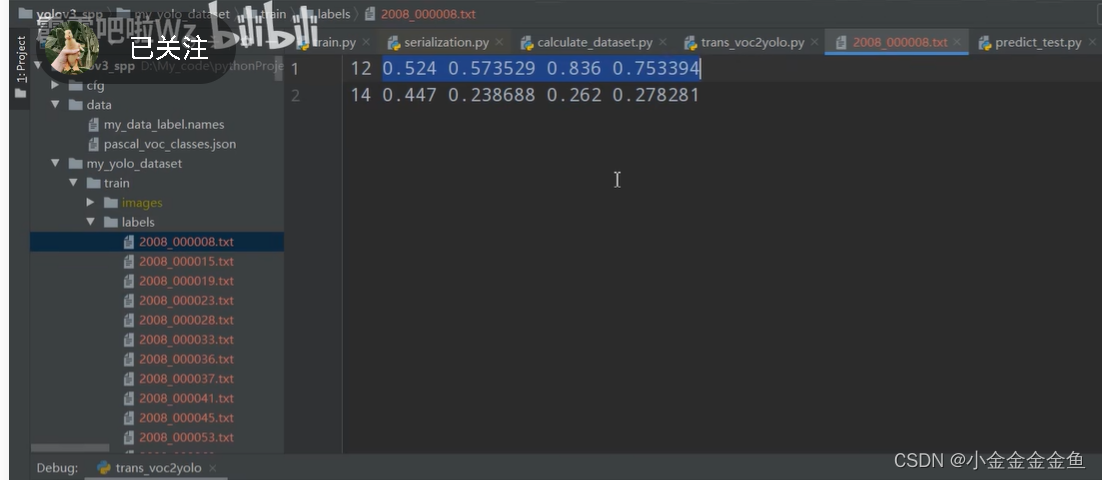
1.首先将数据标注成Darknet format(yolo格式)

每个txt文件就对应一张图片的信息,每一行表示一个目标。
第一个数字:目标索引(如0:人类)
后四个数字:目标边界框的相对坐标
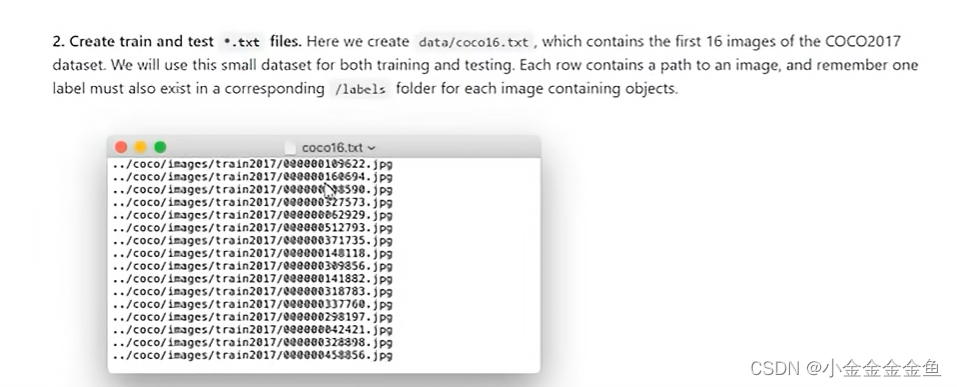
2.创建txt文件:train.txt文件和test.txt文件。
txt文件中存储的是所有训练/验证时使用到的图片的路径。
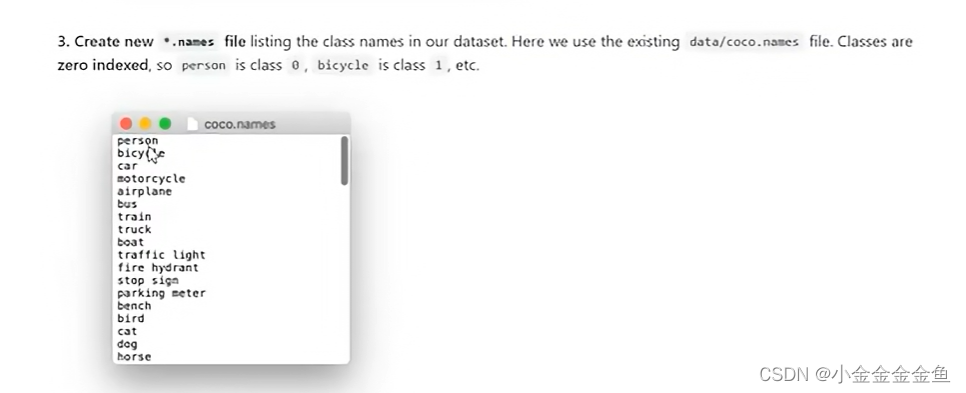
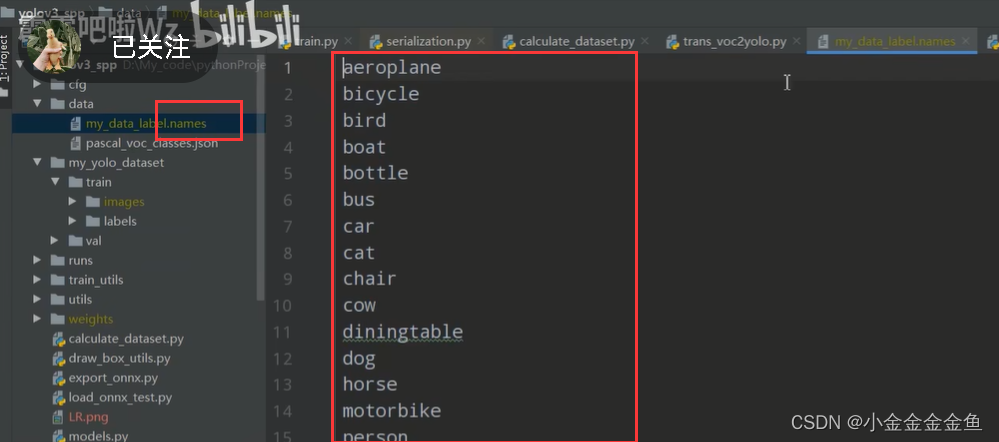
3.以.names结尾的标签文件。
存储所有类别的信息,一个类别对应一行。
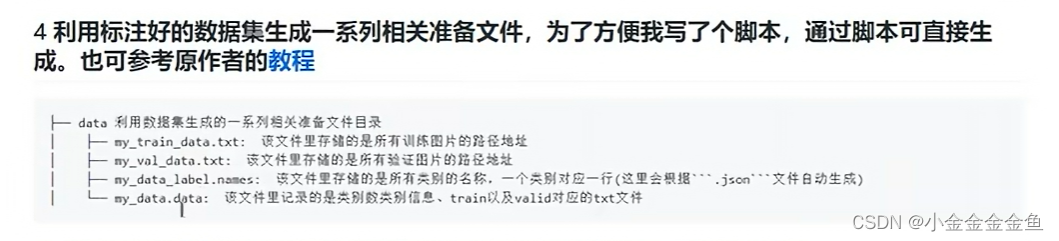
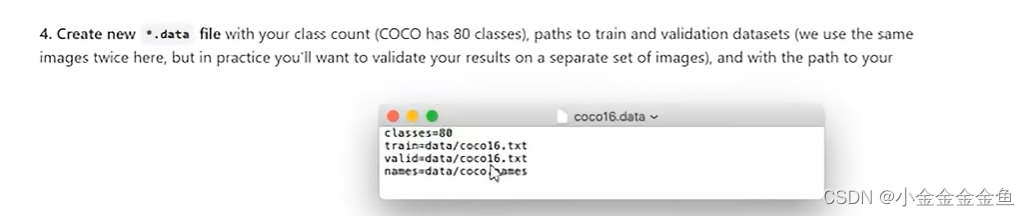
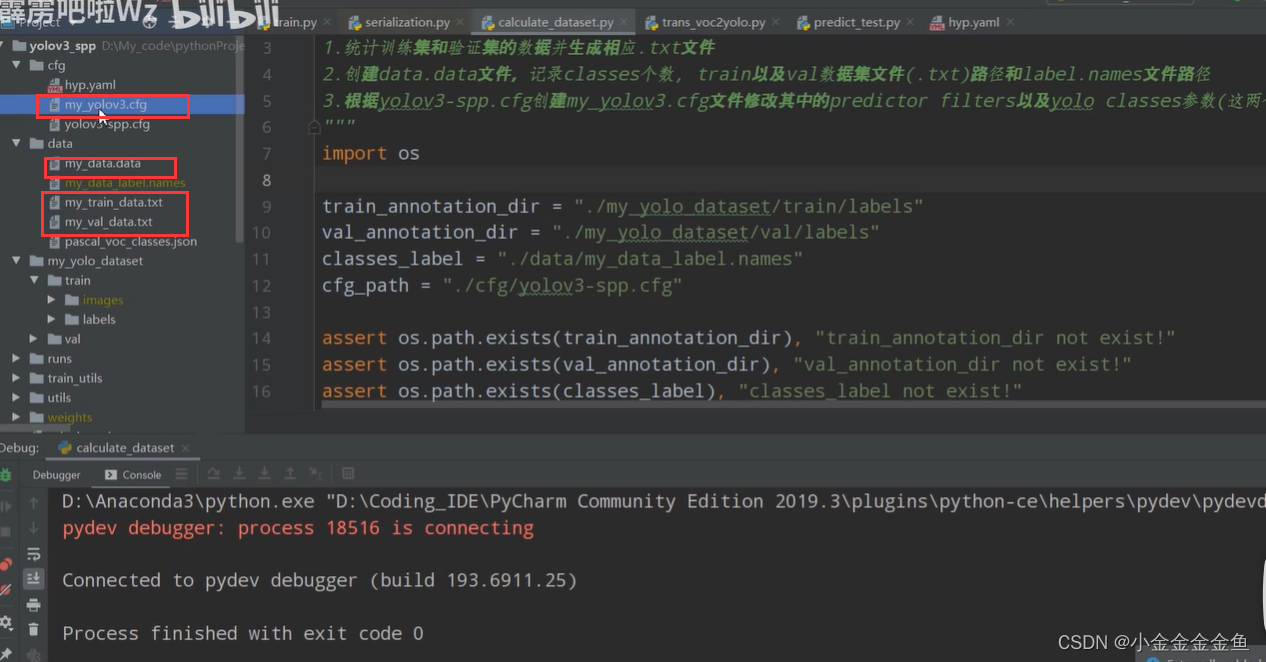
4.创建.data文件。
包含类别个数,训练集所对应的txt文件、验证集所对应的txt文件(步骤2里面的那个)
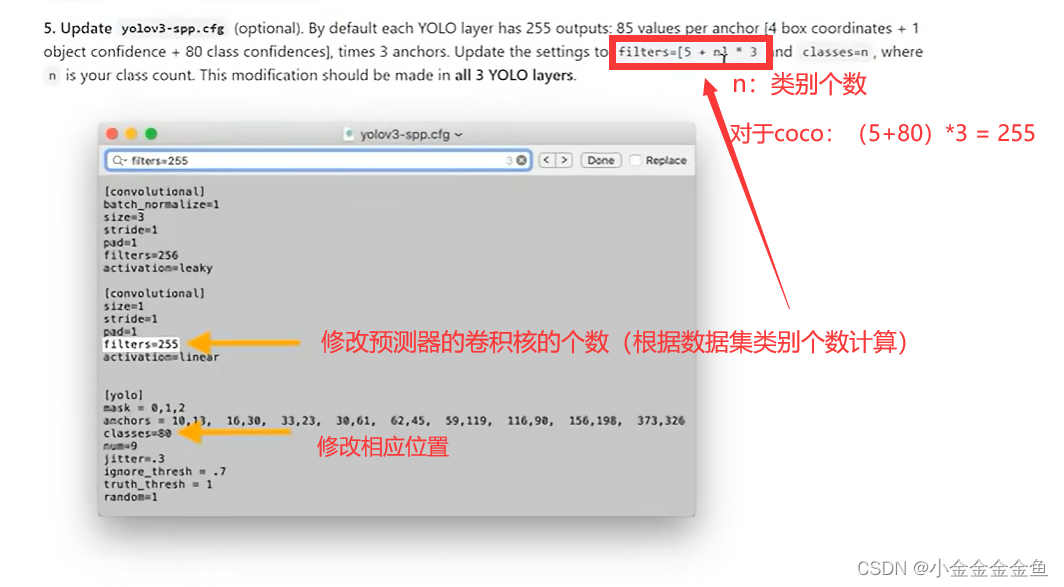
5.更新yolov3-spp.cfg文件
修改预测器的卷积核的个数(根据数据集类别个数计算)
6.更新超参数
建议保持默认
trans_voc2yolo.py
up已经写好了:trans_voc2yolo.py
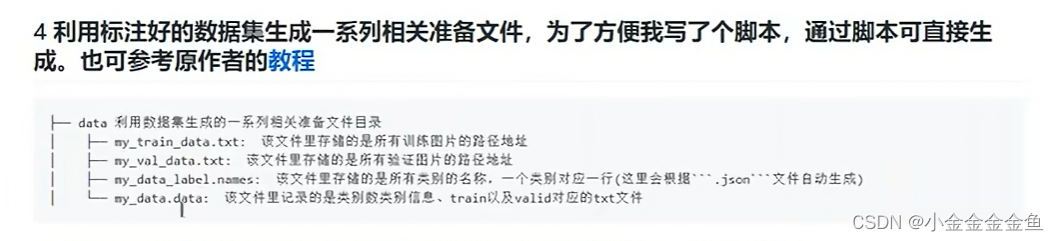
PASCOL VOC --> YOLO格式
voc_root:voc文件目录
save_file_root:转换后把相应的标注文件保存在哪里
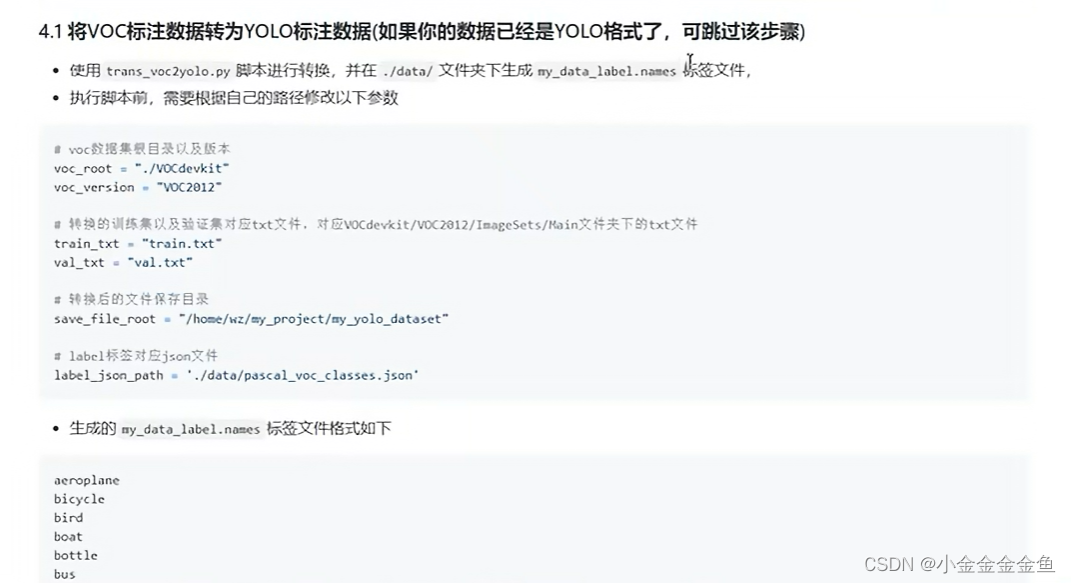
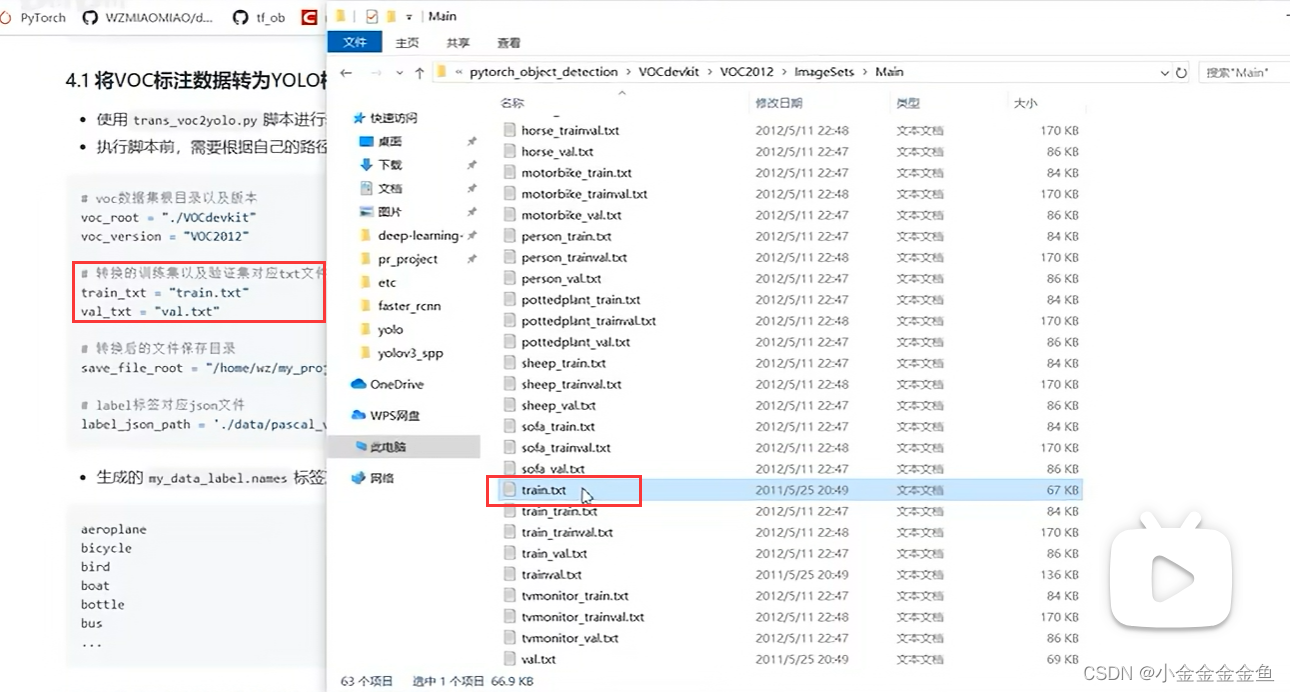
改一下这些就可以运行了
(弹幕:注意这个代码默认所有的图片中都有标注信息,但实际上有的图片并没有标注目标)
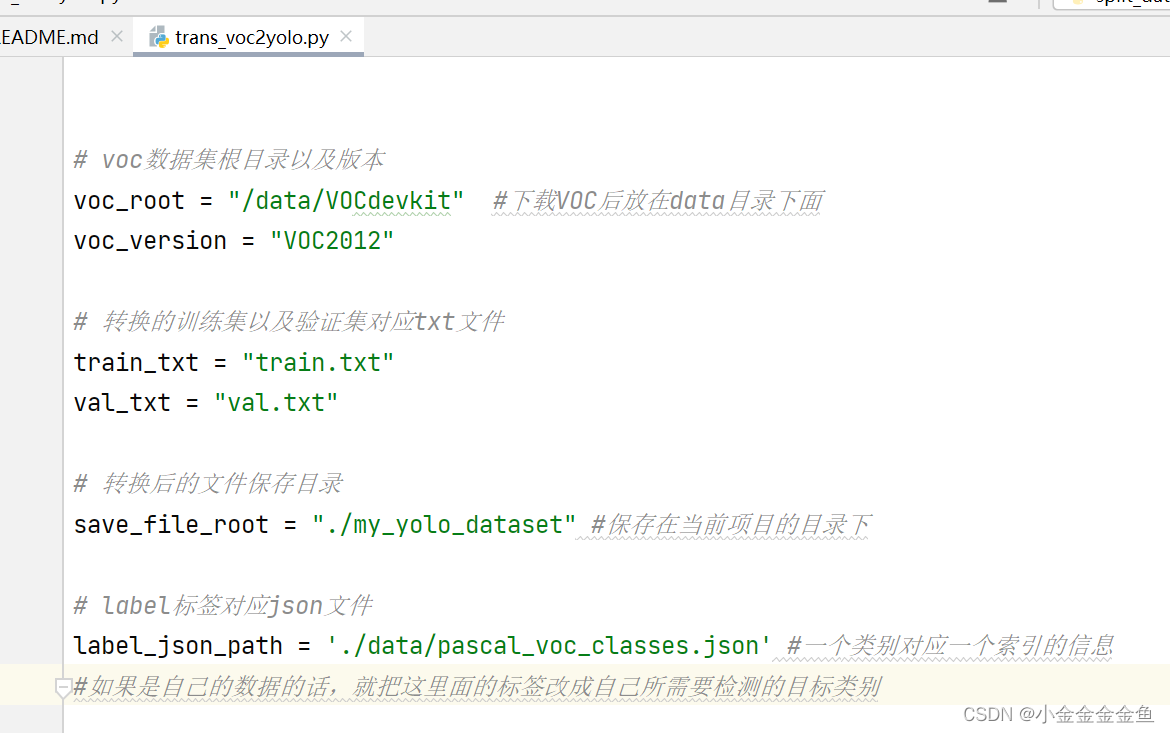
运行之后:
转化标签文件到指定的目录下、生成.names文件
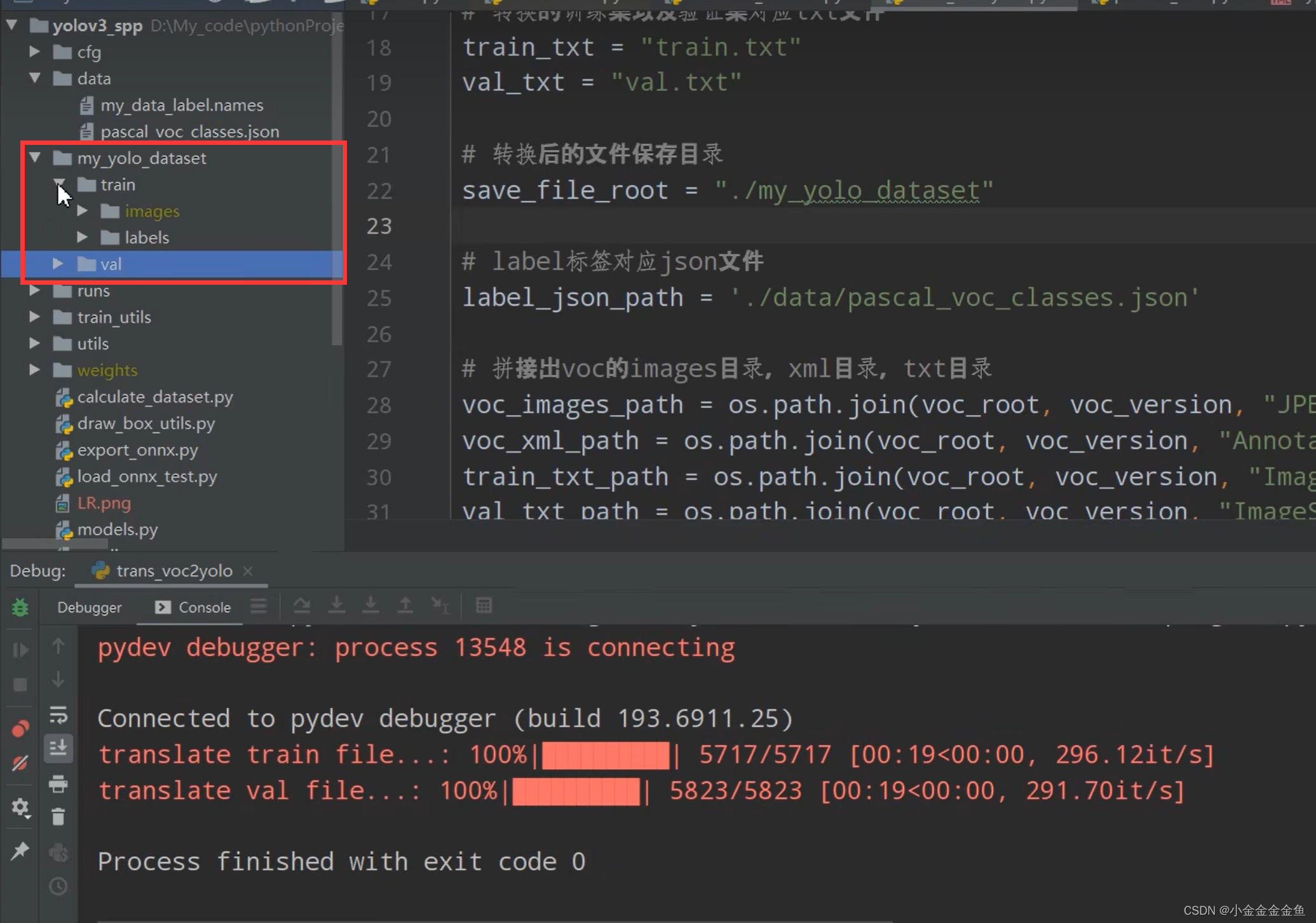
calculate_dataset.py
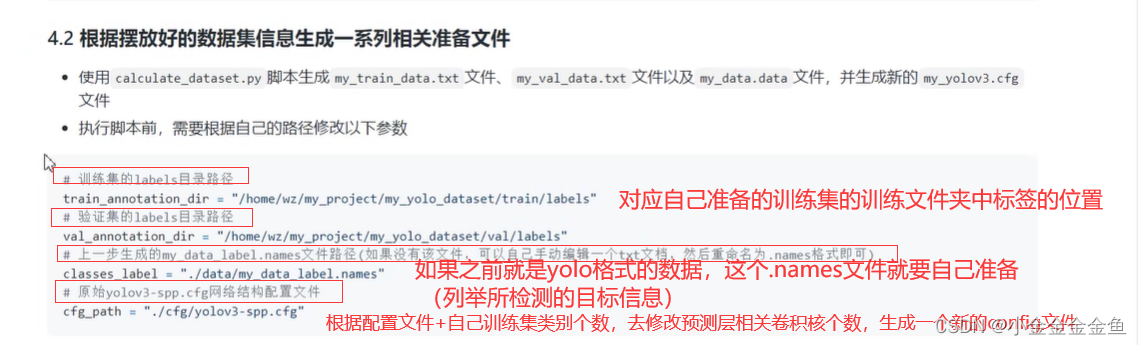
运行后:
注意路径问题,我觉得最好改成绝对路径
7 把下载好的预训练权重放在weights文件夹下
train .py
有时间再补上