题目描述:
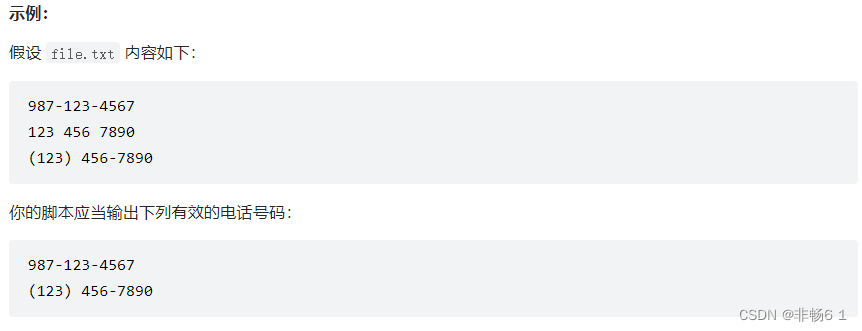
给定一个包含电话号码列表(一行一个电话号码)的文本文件 file.txt,写一个单行 bash 脚本输出所有有效的电话号码。
你可以假设一个有效的电话号码必须满足以下两种格式: (xxx) xxx-xxxx 或 xxx-xxx-xxxx。(x 表示一个数字)
你也可以假设每行前后没有多余的空格字符。
分析:
题目的核心是匹配符合规则的字符串,因为规则比较单一,所以使用正则表达式来检索符合要求的字符串即可。
其中的规律列出来,找出固定的字符位置与可变字符的规律

需要用正则表达式中的普通字符、特殊字符、限定符、定位符来描述对应的规律(如上图所示)
使用正则表达式描述规律:
特殊字符:勿忘加上转义符'\'
限定字符:限定字符出现的次数,掌握它也就get了精华,麻麻再也不用担心我读不懂漂亮的表达式了。
定位符:稍加理解,就能get到的好技巧
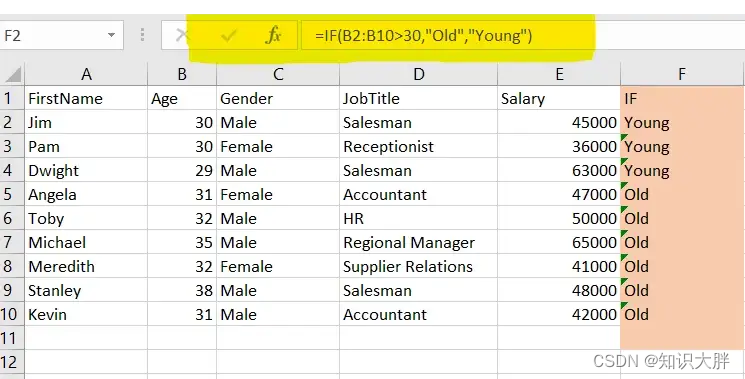
表达 (xxx) xxx-xxxx
^\([0-9][0-9][0-9]\) [0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]$使用限定符来限定数字出现的次数,优化为如下表达
^\([0-9]{3}\) [0-9]{3}-[0-9]{4}$ 
表达 xxx-xxx-xxxx
^[0-9][0-9][0-9]-[0-9][0-9][0-9]-[0-9][0-9][0-9][0-9]$优化
^[0-9]{3}-[0-9]{3}-[0-9]{4}$同时表示xxx-xxx-xxxx和 (xxx) xxx-xxxx
使用特殊字符()和|。用()来标记一个表达式,使用|来指明两项之间的任意选择。
xxx-xxx-xxxx和 (xxx) xxx-xxxx
^([0-9]{3}-|\([0-9]{3}\) )[0-9]{3}-[0-9]{4}$grep与awk
grep -P '^([0-9]{3}-|\([0-9]{3}\) )[0-9]{3}-[0-9]{4}$' file.txtawk '/^([0-9]{3}-|\([0-9]{3}\) )[0-9]{3}-[0-9]{4}$/' file.txtgawk '/^([0-9]{3}-|\([0-9]{3}\) )[0-9]{3}-[0-9]{4}$/' file.txt快速查看表
特殊字符表达

限定符表达
题目描述:
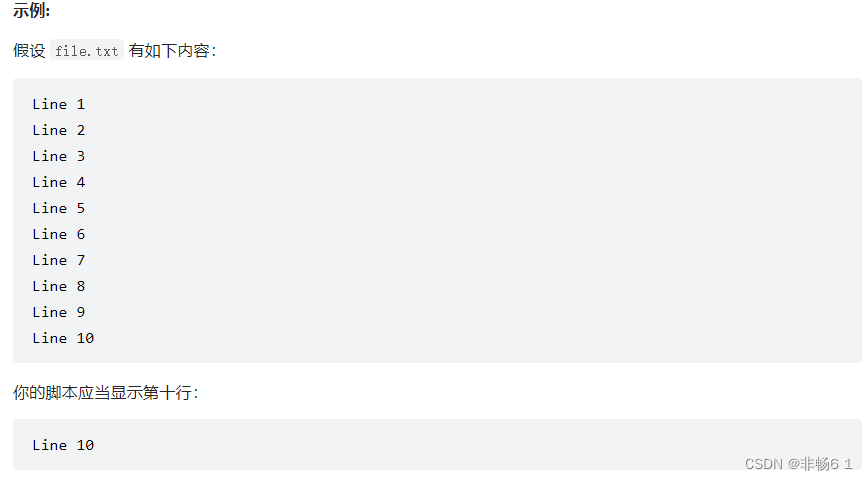
给定一个文本文件 file.txt,请只打印这个文件中的第十行
说明:
1. 如果文件少于十行,你应当输出什么?
2. 至少有三种不同的解法,请尝试尽可能多的方法来解题。
分析:
tail -n +10 与 tail -n 10 不一样,-n +10 表示从第 10 行开始显示,若文件不足 10 行则什么也不会输出;-n 10 表示显示最后的 10 行。
代码:
tail -n +10 file.txt | head -1题目描述:

编写一个 SQL 删除语句来 删除 所有重复的电子邮件,只保留一个id最小的唯一电子邮件。
以 任意顺序 返回结果表。 (注意: 仅需要写删除语句,将自动对剩余结果进行查询)
查询结果格式如下所示。

分析:
表与它自身在电子邮箱列中连接起来
SELECT p1.*
FROM Person p1,
Person p2
WHERE
p1.Email = p2.Email
;找到其他记录中具有相同电子邮件地址的更大 ID。所以我们可以像这样给 WHERE 子句添加一个新的条件。
SELECT p1.*
FROM Person p1,
Person p2
WHERE
p1.Email = p2.Email AND p1.Id > p2.Id
;
已经得到了要删除的记录,所以我们最终可以将该语句更改为 DELETE
DELETE p1 FROM Person p1,
Person p2
WHERE
p1.Email = p2.Email AND p1.Id > p2.Id
题目描述:
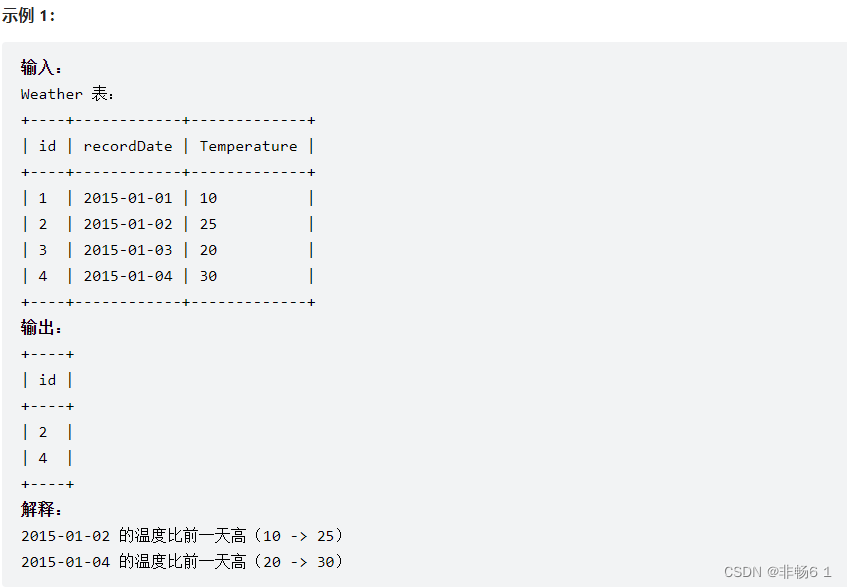
编写一个 SQL 查询,来查找与之前(昨天的)日期相比温度更高的所有日期的 id 。
返回结果 不要求顺序 。
查询结果格式如下例。
代码:
select cur.id
from Weather cur
inner join Weather pre
where DATEDIFF(cur.recordDate, pre.recordDate) = 1 AND cur.temperature > pre.temperature;