文章目录
- 最小生成树
- 1.最小生成树概念
- 2.Kruskal算法
- 3.Prim算法
- 最短路径算法
- 单源最短路径--Dijkstra算法
- 单源最短路径--Bellman-Ford算法
- 多源最短路径--Floyd-Warshall算法
- LRUCache
- LRUCache实现
- 源码地址
最小生成树
1.最小生成树概念
连通图中的每一棵生成树,都是原图的一个极大无环子图,即:从其中删去任何一条边,生成树就不在连通;反之,在其中引入任何一条新边,都会形成一条回路。
若连通图由n个顶点组成,则其生成树必含n个顶点和n-1条边。因此构造最小生成树的准则有三条:
- 只能使用图中的边来构造最小生成树
- 只能使用恰好n-1条边来连接图中的n个顶点
- 选用的n-1条边不能构成回路
最小生成树,也就是图的生成树中权值最小的树。最小生成树的常用算法有Kruskal算法 和**Prim算法。**算法的思想都是贪心策略。
2.Kruskal算法
核心:贪心思想。
逐步选择当前图中的最小边,选择边构成生成树。要注意选择的边不能构成环。
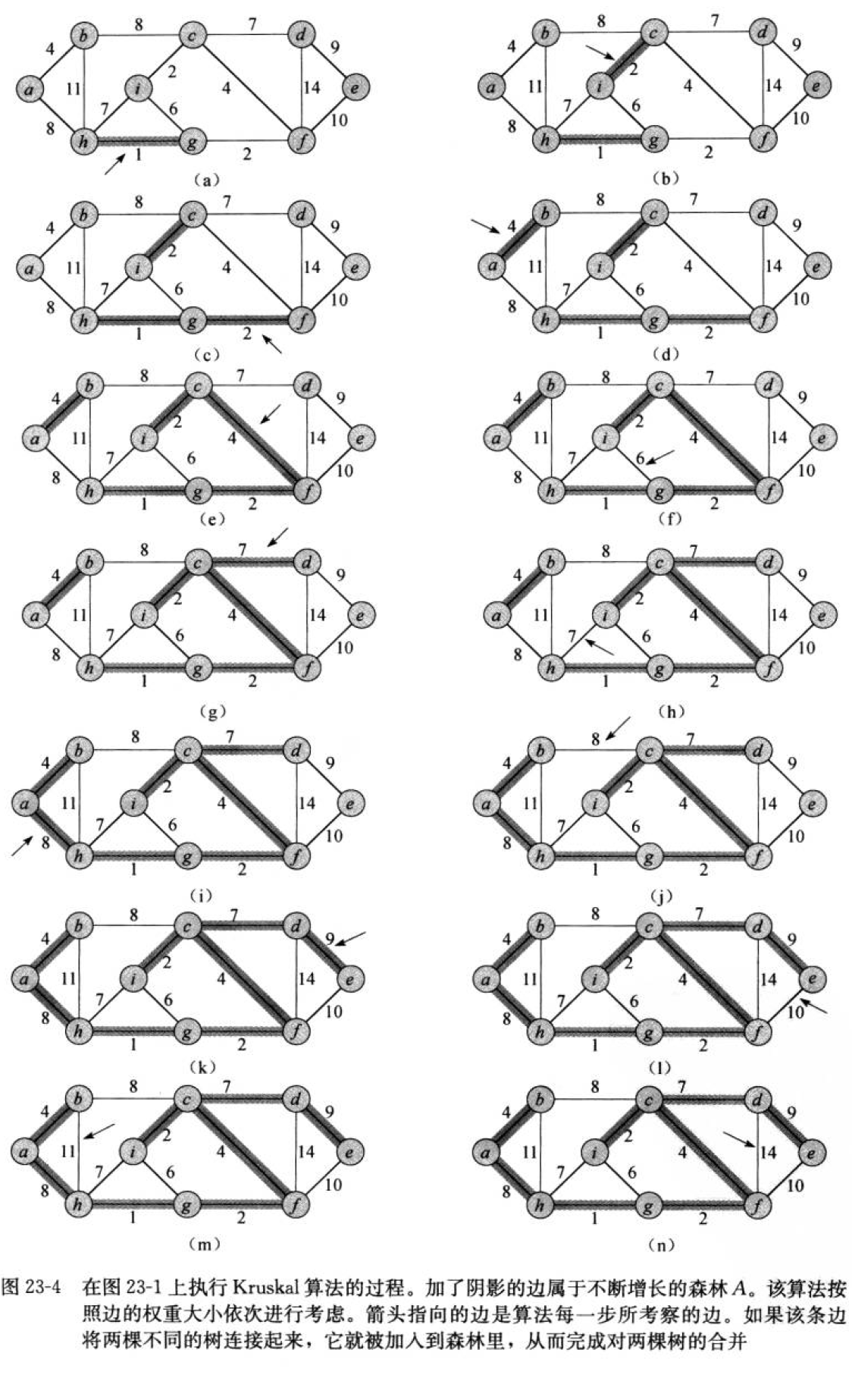
如何判断是否有环? 并查集
被选择的边的点合并到一共集合中。如果被选中的边两端的点已经在一共集合中,说明构成了环。
下面用图的邻接矩阵实现克鲁斯卡尔算法。
//克鲁斯卡尔算法
W Kruskal(self &minTree)
{
//构建一共只有点,没有边的图。后续最小生成树的边往图里面添加
size_t n = _vertexs.size();
minTree._vertexs = _vertexs;
minTree._indexmap = _indexmap;
minTree._matrix.resize(n);
for (int i = 0; i < n; i++)
{
minTree._matrix[i].resize(n, MAX_W);
}
//将所有的边,放入到一个优先级队列中
priority_queue<edge, vector<edge>, greater<edge>> minque;
for (size_t i = 0; i < n; i++)
{
for (size_t j = 0; j < n; j++)
{
//无向的,保证不重复的选择边
if (i < j && _matrix[i][j] != MAX_W)
{
//将边插入到优先级队列中
minque.push(edge(i, j, _matrix[i][j]));
}
}
}
//依次选边
W ret = W(); //总的权值
int edge_num = 0; //一共要选择n-1条边
//并查集判断是否有环
UnionFindSet<V> points;
//将图的点依次插入到并查集中
for (int i = 0; i < _vertexs.size(); i++)
{
points.insert(_vertexs[i]);
}
while (!minque.empty())
{
edge min = minque.top();
minque.pop();
//判断是否成环
if (!points.InSet_index(min._srci, min._dsti))
{
//添加边
minTree._addedge(min._srci, min._dsti, min._w);
points.Union(min._srci, min._dsti);
edge_num++;
ret += min._w;
}
}
//判断边是否选完
if (edge_num != n - 1)
{
return W();
}
return ret;
}
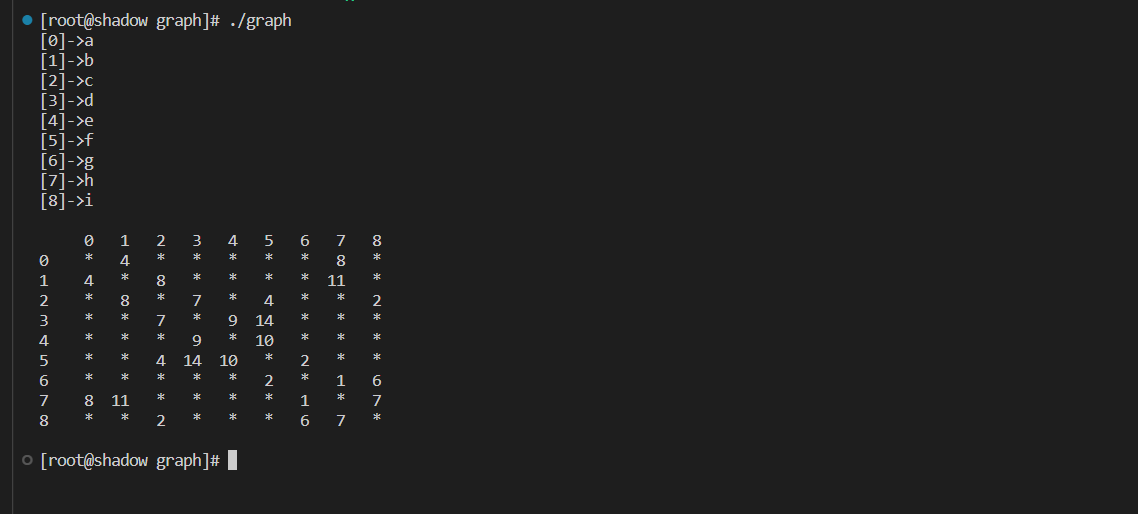
测试克鲁斯卡尔算法
void leaset_tree()
{
const char* str = "abcdefghi";
matrix::Graph<char, int> g(str, strlen(str));
g.addedge('a', 'b', 4);
g.addedge('a', 'h', 8);
// g.AddEdge('a', 'h', 9);
g.addedge('b', 'c', 8);
g.addedge('b', 'h', 11);
g.addedge('c', 'i', 2);
g.addedge('c', 'f', 4);
g.addedge('c', 'd', 7);
g.addedge('d', 'f', 14);
g.addedge('d', 'e', 9);
g.addedge('e', 'f', 10);
g.addedge('f', 'g', 2);
g.addedge('g', 'h', 1);
g.addedge('g', 'i', 6);
g.addedge('h', 'i', 7);
//构建一颗最小生成树
matrix::Graph<char, int> mintree;
g.Kruskal(mintree);
mintree.Print();
}
3.Prim算法
Prim算法是从给定的结点出发,依次从被选择集合出发的点选择最小的边,被选中边的点加入到被选择集合中。

下面用图的邻接矩阵实现克鲁斯卡尔算法。
W Prim(self &minTree, const V &src)
{
size_t n = _vertexs.size();
int srci = GetVertexIndex(src);
minTree._vertexs = _vertexs;
minTree._indexmap = _indexmap;
minTree._matrix.resize(n);
for (size_t i = 0; i < n; ++i)
{
minTree._matrix[i].resize(n, MAX_W);
}
vector<bool> choice(n, false);
vector<bool> nochoice(n, true);
priority_queue<edge, vector<edge>, greater<edge>> minque;
choice[srci] = true;
nochoice[srci] = false;
for (size_t i = 0; i < n; i++)
{
if (_matrix[srci][i] != MAX_W)
{
minque.push(edge(srci, i, _matrix[srci][i]));
}
}
size_t edge_num = 0;
W total = W(); //返回值
while (!minque.empty())
{
edge min = minque.top();
minque.pop();
//判断当前的边是否合法
if (choice[min._dsti])
{
// do nothing
}
else
{
//将当前边添加到图中
minTree._addedge(min._srci, min._dsti, min._w);
choice[min._dsti] = true;
nochoice[min._dsti] = false;
edge_num++;
total += min._w;
if (edge_num == n - 1)
{
break;
}
for (size_t i = 0; i < n; i++)
{
if (nochoice[i] && _matrix[min._dsti][i] != MAX_W)
{
minque.push(edge(min._dsti, i, _matrix[min._dsti][i]));
}
}
}
}
if (edge_num != n - 1)
{
return W();
}
return total;
}
测试Prim算法
void leaset_tree()
{
const char* str = "abcdefghi";
matrix::Graph<char, int> g(str, strlen(str));
g.addedge('a', 'b', 4);
g.addedge('a', 'h', 8);
// g.AddEdge('a', 'h', 9);
g.addedge('b', 'c', 8);
g.addedge('b', 'h', 11);
g.addedge('c', 'i', 2);
g.addedge('c', 'f', 4);
g.addedge('c', 'd', 7);
g.addedge('d', 'f', 14);
g.addedge('d', 'e', 9);
g.addedge('e', 'f', 10);
g.addedge('f', 'g', 2);
g.addedge('g', 'h', 1);
g.addedge('g', 'i', 6);
g.addedge('h', 'i', 7);
//构建一颗最小生成树
matrix::Graph<char, int> mintree;
g.Prim(mintree,'a');
mintree.Print();
}

最短路径算法
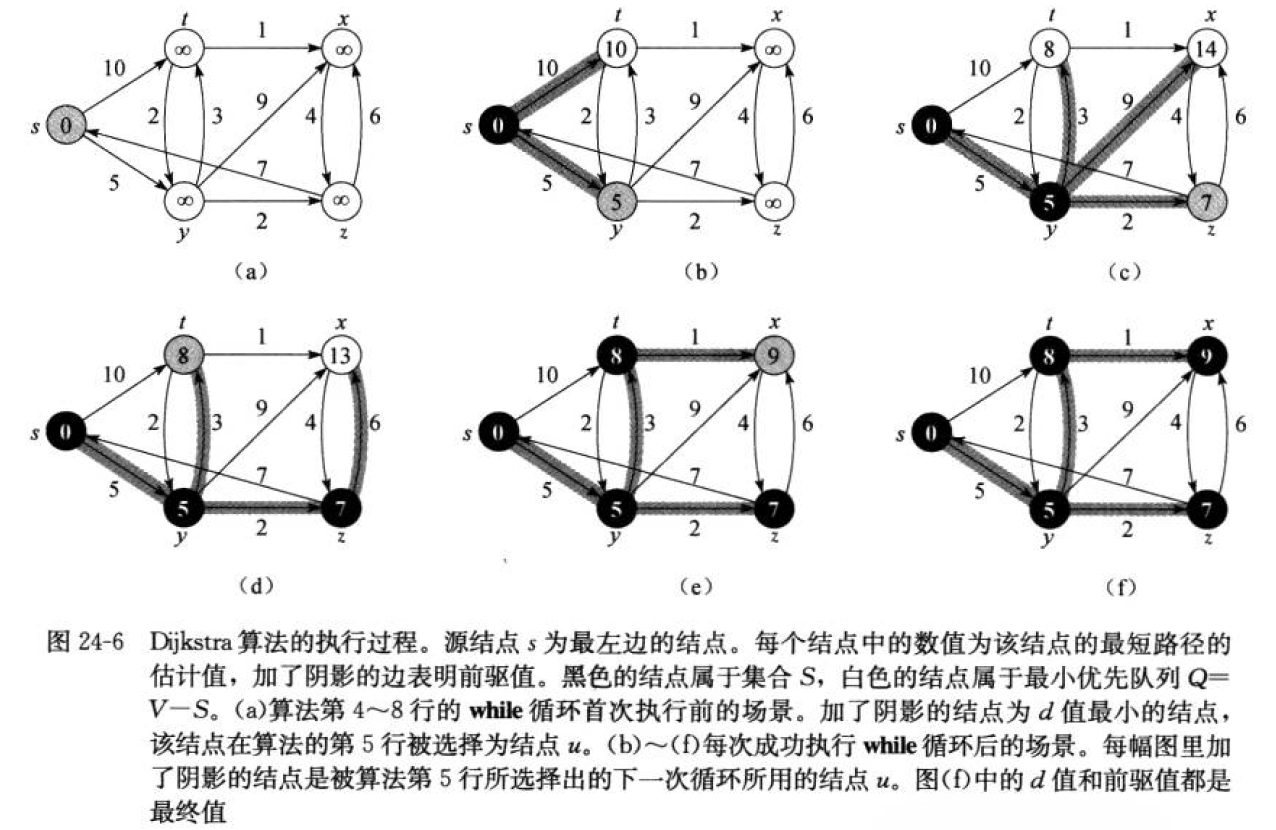
单源最短路径–Dijkstra算法
也叫做单源最短路径算法,解决一个点到其余个点顶点的最短路径

首先需要写出邻接矩阵

使用dis数组存储源顶点(1号顶点)到其余个顶点的距离

具体思路
从初始的dis数组中找到最小值为2,那么1->2顶点的最短路径就成为了确定值,值为1。
从顶点2开始出发,可以到达的顶点为2->3,2->4;其中如果中顶点2进行"中转",那么1->2->3的路径为1(1->2的最短路径)+9(2->3的路径)为10,小于1->3的距离12,所以将dis数组中1->3的值变为10;对2->4进行同样的处理1->4的最短路径更新为4。

在现在的dis数组中,确定的顶点有2;而第一次松弛后除去到顶点2的最短路径为1->4(路径长度为4),顶点4为确定值。从4开始出发
- 可以到达的顶点有3,5,6;将顶点4作为"中转"进行第二轮的松弛
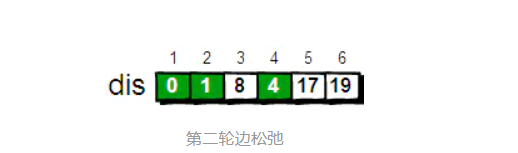
现在的确定的顶点为2,4;剩下顶点的最短路径为1->3,顶点3为最短路径,变为确定值;
进行下一轮的松弛

最终的松弛结果为:

dis数组中存放了到各顶点的最短路径
// Dijkstra是单源最短路算法,可以计算给定点到其他点的最短路
void Dijkstra(const V &src, vector<W> &dist, vector<int> &parentindex)
{
// dist,记录到i点的当前最短路是多少
int srci = GetVertexIndex(src);
size_t n = _vertexs.size();
dist.resize(n, MAX_W);
parentindex.resize(n, -1);
parentindex[srci] = srci;
vector<bool> visited(n, false);
//先对dist数组进行初始化
/*
for(size_t i=0;i<n;i++){
if(_matrix[srci][i]!=MAX_W){
dist[i]=_matrix[srci][i];
}
}
visited[srci]=true;
*/
dist[srci] = 0;
//寻找最短的路径,每一轮对其中一个点进行松弛处理,一共要进行n轮
for (size_t i = 0; i < n; i++)
{
//记录这一轮的最小路径和最小节点
int min_index = 0;
W min_num = MAX_W;
//先找到当前一轮的最小值和最小节点
for (size_t j = 0; j < n; j++)
{
if (!visited[j] && dist[j] < min_num)
{
min_num = dist[j];
min_index = j;
}
}
//当前的点为确定点
visited[min_index] = true;
//松弛处理
for (size_t j = 0; j < n; j++)
{
if (!visited[j] && dist[min_index] + _matrix[min_index][j] < dist[j] && _matrix[min_index][j] != MAX_W)
{
dist[j] = dist[min_index] + _matrix[min_index][j];
parentindex[j] = min_index;
}
}
}
}
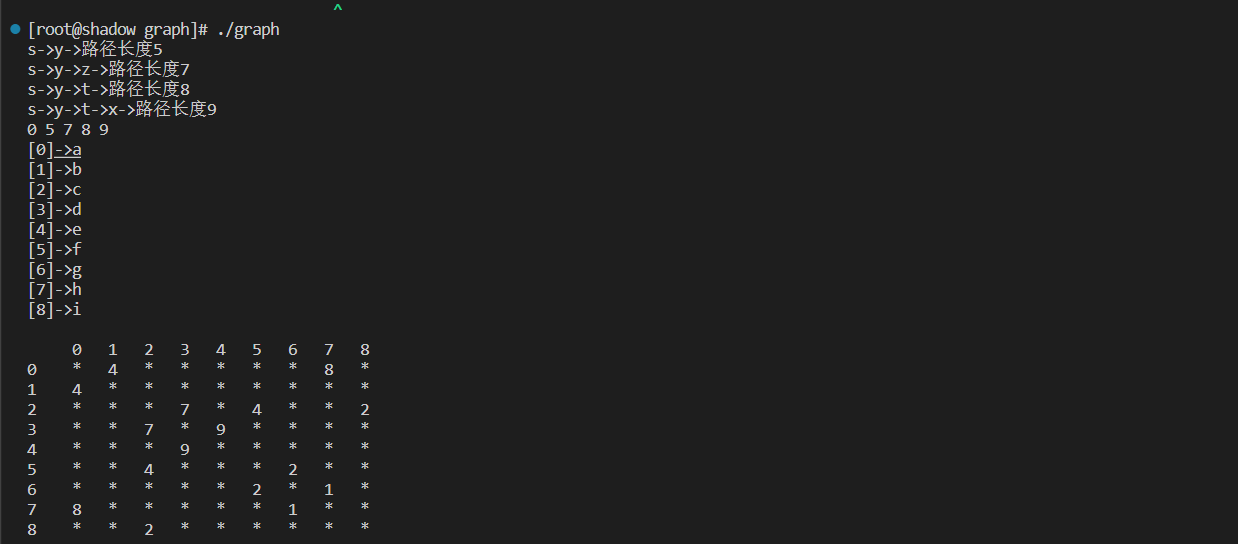
测试接口
void TestGraphDijkstra()
{
const char* str = "syztx";
matrix::Graph<char, int,MAX, true> g(str, strlen(str));
g.addedge('s', 't', 10);
g.addedge('s', 'y', 5);
g.addedge('y', 't', 3);
g.addedge('y', 'x', 9);
g.addedge('y', 'z', 2);
g.addedge('z', 's', 7);
g.addedge('z', 'x', 6);
g.addedge('t', 'y', 2);
g.addedge('t', 'x', 1);
g.addedge('x', 'z', 4);
vector<int> dist;
vector<int> parentPath;
g.Dijkstra('s', dist, parentPath);
g.PrintShortPath('s', dist, parentPath);
for (auto& d : dist) {
cout << d << " ";
}
cout << endl;
}
Dijkstra算法存在的问题是不支持图中带负权路径,如果带有负权路径,则可能会找不到一些路
径的最短路径。
单源最短路径–Bellman-Ford算法
bellman—ford算法可以解决负权图的单源最短路径问题。它的优点是可以解决有负权边的单源最短路径问题,而且可以用来判断是否有负权回路。它也有明显的缺点,它的时间复杂度 O(N*E) (N是点数,E是边数)普遍是要高于Dijkstra算法O(N²)的。像这里如果我们使用邻接矩阵实现,那么遍历所有边的数量的时间复杂度就是O(N^3),这里也可以看出来Bellman-Ford就是一种暴力求解更新 。
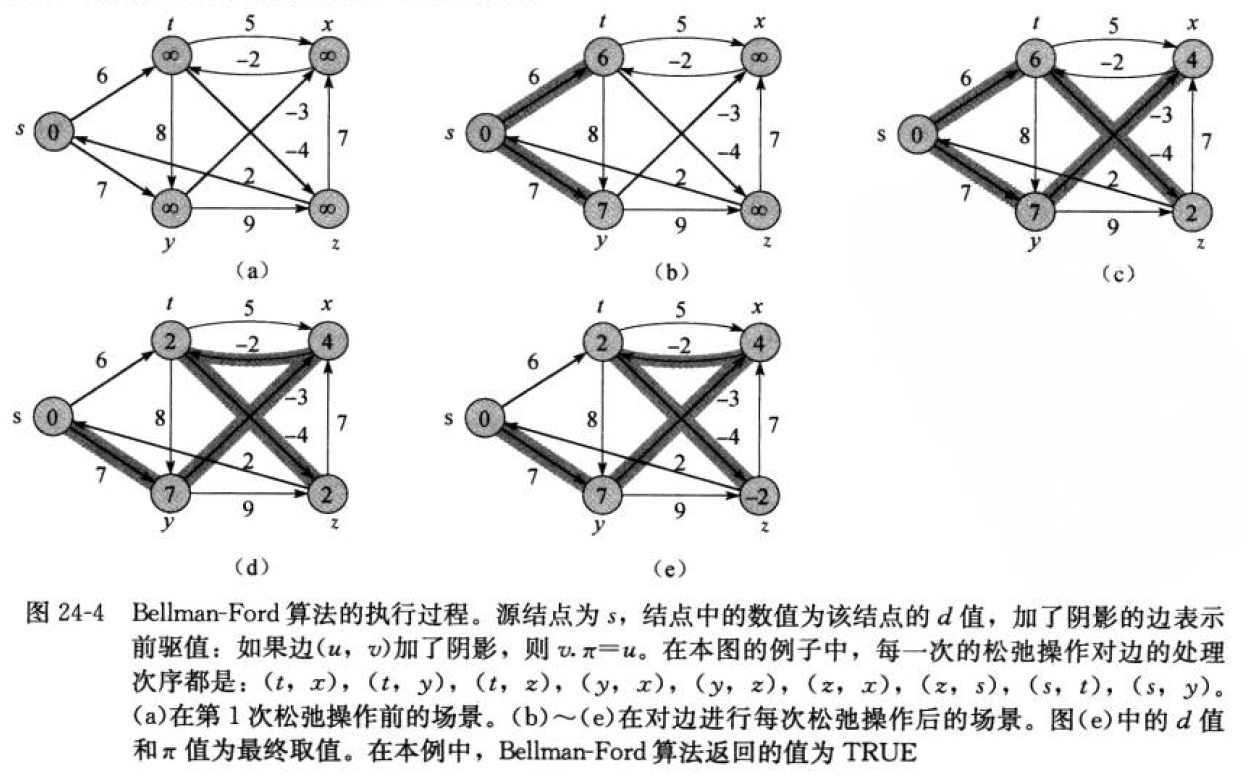
void Bellman_Ford(const V &src, vector<W> &dist, vector<int> &pPath)
{
size_t n = dist.size();
size_t srci = GetVertexIndex(src);
dist.resize(n, MAX_W);
pPath.resize(n, -1);
dist[srci] = W();
for (size_t k = 0; k < n - 1; ++k)
{
bool exchange = false;
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
// srci->i + i->j < srci->j 则更新路径及权值
if (_matrix[i][j] != MAX_W && dist[i] + _matrix[i][j] < dist[j])
{
dist[j] = dist[i] + _matrix[i][j];
pPath[j] = i;
exchange = true;
}
}
}
if (exchange = false)
{
break;
}
}
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
// 检查有没有负权回路
if (_matrix[i][j] != MAX_W && dist[i] + _matrix[i][j] < dist[j])
{
return false;
}
}
}
}
多源最短路径–Floyd-Warshall算法
弗洛伊德算法是一种纯暴力算法,每次以K为中转转,更新结点i到结点j的最大路径。

//弗洛伊德算法是一种纯暴力算法
void FloydWarshall(vector<vector<W>> &vvDist, vector<vector<int>> &vvpPath)
{
size_t n = _vertexs.size();
vvDist.resize(n);
vvpPath.resize(n);
for (size_t i = 0; i < n; ++i)
{
vvDist[i].resize(n, MAX_W);
vvpPath[i].resize(n, -1);
}
//初始化
for (size_t i = 0; i < n; i++)
{
for (size_t j = 0; j < n; j++)
{
if (_matrix[i][j] != MAX_W)
{
vvDist[i][j] = _matrix[i][j];
vvpPath[i][j] = i;
}
if (i == j)
{
vvDist[i][j] = W();
}
}
}
//弗洛伊德算法
//依次以K结点为中转站更新最短路径
for (size_t k = 0; k < n; k++)
{
for (size_t i = 0; i < n; i++)
{
for (size_t j = 0; j < n; j++)
{
if (vvDist[i][k] != MAX_W && vvDist[k][j] != MAX_W && vvDist[i][k] + vvDist[k][j] < vvDist[i][j])
{
vvDist[i][j] = vvDist[i][k] + vvDist[k][j];
vvpPath[i][j] = vvpPath[k][j];
}
}
}
}
//打印节点
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
if (vvDist[i][j] == MAX_W)
{
// cout << "*" << " ";
printf("%3c", '*');
}
else
{
// cout << vvDist[i][j] << " ";
printf("%3d", vvDist[i][j]);
}
}
cout << endl;
}
cout << endl;
for (size_t i = 0; i < n; ++i)
{
for (size_t j = 0; j < n; ++j)
{
// cout << vvParentPath[i][j] << " ";
printf("%3d", vvpPath[i][j]);
}
cout << endl;
}
cout << "=================================" << endl;
}
以下面的图进行测试

void TestFloydWarShall()
{
const char *str = "12345";
matrix::Graph<char, int,MAX,true> g(str, strlen(str));
g.addedge('1', '2', 3);
g.addedge('1', '3', 8);
g.addedge('1', '5', -4);
g.addedge('2', '4', 1);
g.addedge('2', '5', 7);
g.addedge('3', '2', 4);
g.addedge('4', '1', 2);
g.addedge('4', '3', -5);
g.addedge('5', '4', 6);
vector<vector<int>> vvDist;
vector<vector<int>> vvParentPath;
g.FloydWarshall(vvDist, vvParentPath);
// 打印任意两点之间的最短路径
for (size_t i = 0; i < strlen(str); ++i)
{
g.PrintShortPath(str[i], vvDist[i], vvParentPath[i]);
cout << endl;
}
}

LRUCache
LRU是Least Recently Used的缩写,意思是最近最少使用,它是一种Cache替换算法。
什么是Cache(缓存)?
狭义的Cache指的是位于CPU和主存间的快速RAM, 通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术。 广义上的Cache指的是位于速度相差较大的两种硬件之间, 用于协调两者数据传输速度差异的结构。除了CPU与主存之间有Cache, 内存与硬盘之间也有Cache,乃至在硬盘与网络之间也有某种意义上的Cache── 称为Internet临时文件夹或
网络内容缓存等。
Cache的容量有限,因此当Cache的容量用完后,而又有新的内容需要添加进来时, 就需要挑选并舍弃原有的部分内容,从而腾出空间来放新内容。LRU Cache 的替换原则就是将最近最少使用的内容替换掉。其实,LRU译成最久未使用会更形象, 因为该算法每次替换掉的就是一段时间内最久没有使用过的内容。
CPU三级缓存机制

LRUCache实现
LRU Cache要保证获取和置换都是O(1)操作。常用方法是使用双向链表和哈希表的搭配 。双向链表存储Key-value键值对。Hash表中存放Key和链表结点的映射关系。
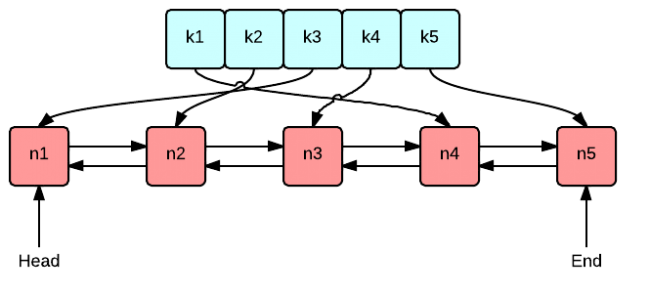
class LRUCache{
public:
LRUCache(int capacity)
:capacity_(capacity)
{}
int get(int key){
auto it=mp.find(key);
//如果有该数据,就加入到头位置
if(it!=mp.end()){
//得到链表的迭代器
auto list_iter=it->second;
pair<int,int> listvalue=*list_iter;
data.erase(list_iter);
data.push_front(listvalue);
mp[key]=data.begin();
return listvalue.second;
}
//如果没有数据,返回-1
else{
return -1;
}
}
void set(int key,int value){
auto it=mp.find(key);
if(it!=mp.end()){
//如果已经有了key,更新数据,然后将其放在最前面
auto list_iter=it->second;
pair<int,int> list_value=*list_iter;
list_value.second=value;
data.erase(list_iter);
data.push_front(list_value);
//更新Hash表
mp[key]=data.begin();
}
//如果没有key,就需要判断容量
//如果当前数量超过容量,就删除最后一个,负责之间在头添加即可
else{
if(data.size()>=capacity_){
auto list_back=data.back();
mp.erase(list_back.first);
data.pop_back();
}
//向头部添加make_pair(key,value);
data.push_front(make_pair(key,value));
mp[key]=data.begin();
}
}
//插入
private:
unordered_map<int,list<pair<int,int>>::iterator> mp;
//List存放一共K-Value类型的数据
list<pair<int,int>> data;
size_t capacity_;
};
146. LRU 缓存 - 力扣(LeetCode)
源码地址
Graph和LRUCache · 影中人/test - 码云 - 开源中国 (gitee.com)
![[附源码]Python计算机毕业设计Django疫情物资管理系统](https://img-blog.csdnimg.cn/adde5e3965a348309855f50bfb5f8e89.png)







![[附源码]Python计算机毕业设计SSM基于与协同过滤算法的竞赛项目管理(程序+LW)](https://img-blog.csdnimg.cn/b702f4506e8748f0bc8d53e6698b6076.png)