Redis概述_为什么要用NoSQL

单机Mysql的美好年代
在90年代,一个网站的访问量一般都不大,用单个数据库完全可以轻松应付。在那个时候,更多的都是 静态网页,动态交互类型的网站不多。

遇到问题:
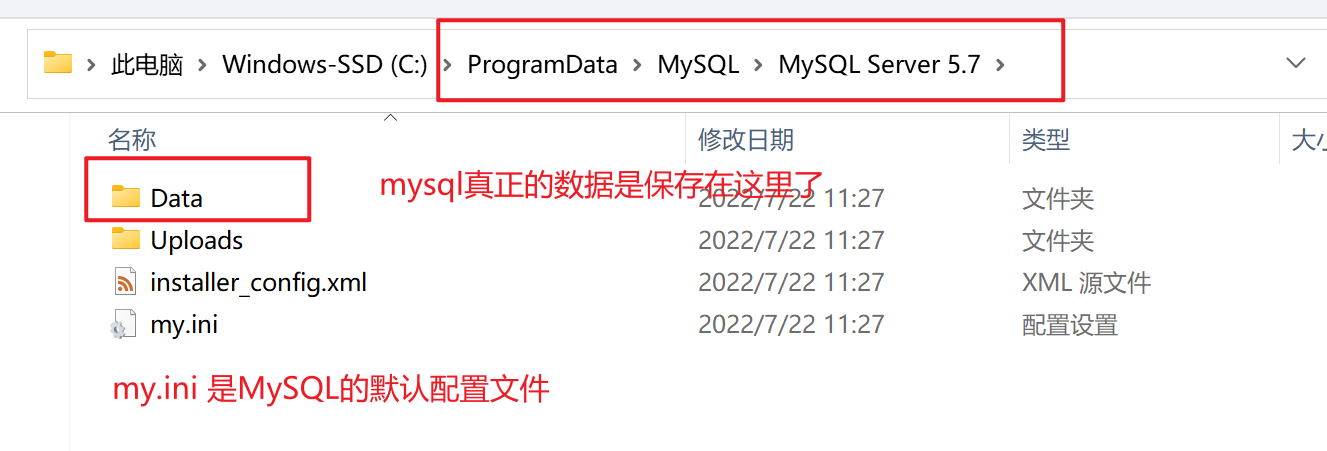
随着用户数的增长,Tomcat和数据库之间竞争资源,单机性能不足以支撑业务。
Tomcat与数据库分开部署
Tomcat和数据库分别独占服务器资源,显著提高两者各自性能。
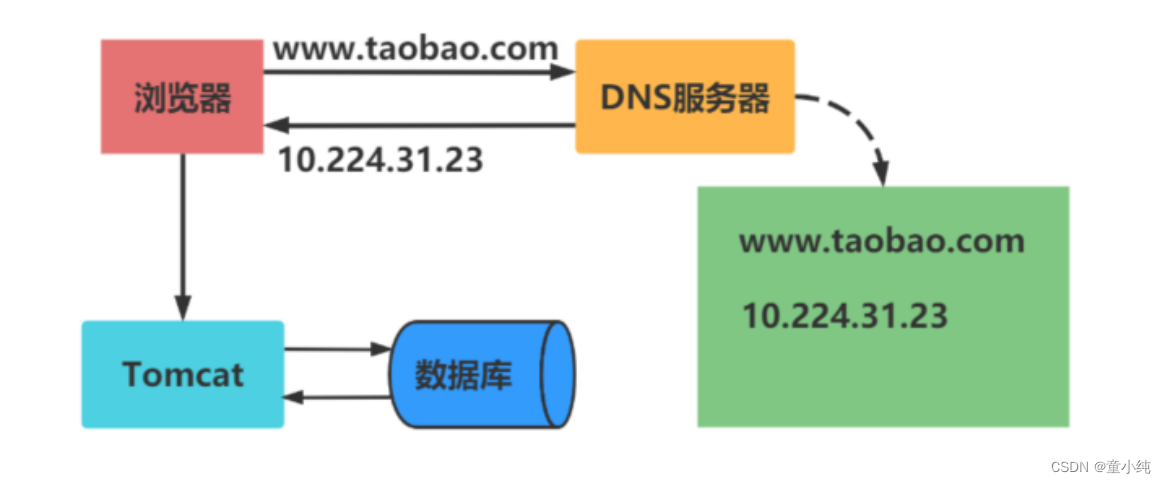
新的问题: 随着用户数的增长,并发读写数据库成为瓶颈。
引入本地缓存和分布式缓存
通过缓存能把绝大多数请求在读写数据库前拦截掉,大大降低数据库压力。其中涉及的技术包括:使用 memcached作为本地缓存,使用Redis作为分布式缓存。

注意:
缓存抗住了大部分的访问请求,随着用户数的增长,并发压力主要落在单机的Tomcat上,响应逐渐变慢。
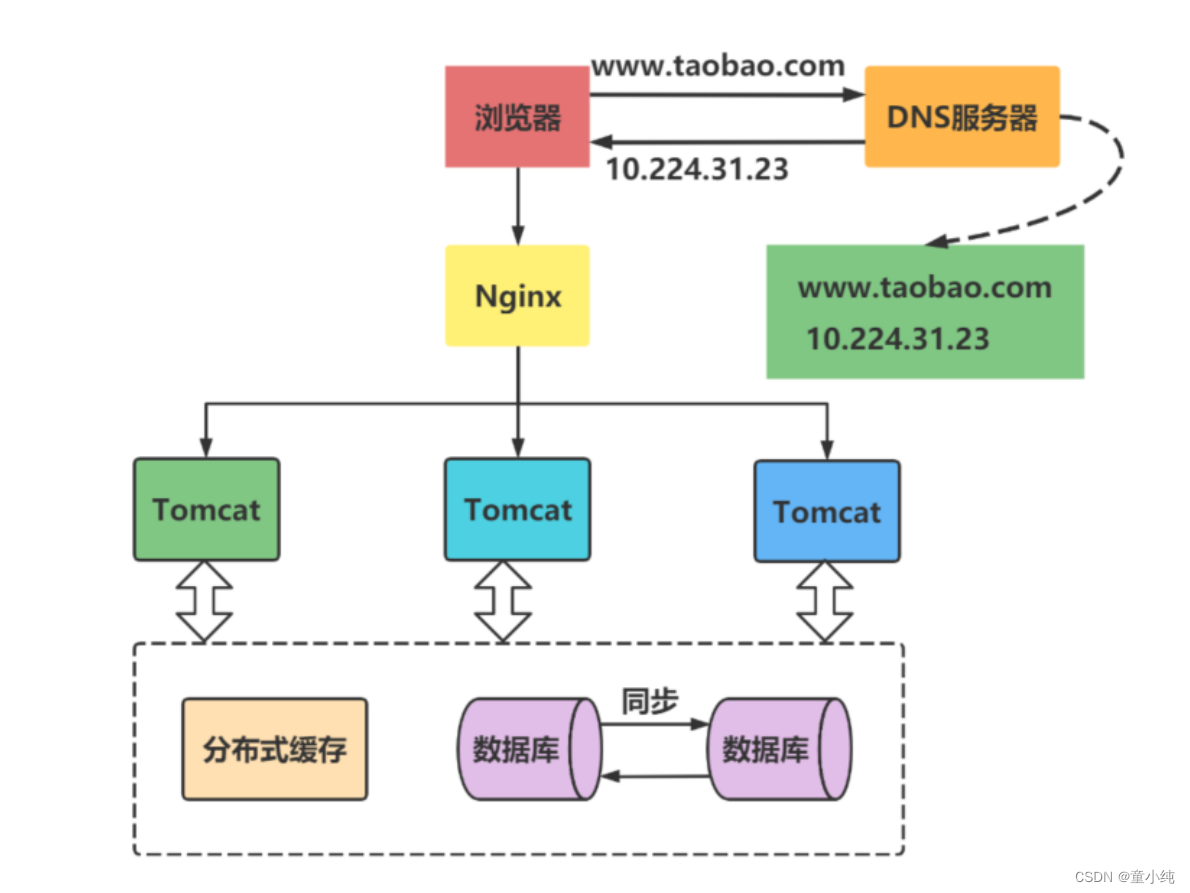
引入反向代理实现负载均衡
在多台服务器上分别部署Tomcat,使用反向代理软件(Nginx)把请求均匀分发到每个Tomcat中。

新的挑战:
反向代理使应用服务器可支持的并发量大大增加,但并发量的增长也意味着更多请求穿透到数据库,单机的数据库最终成为瓶颈。
数据库读写分离
由于数据库的写入压力增加,Memcached只能缓解数据库的读取压力。读写集中在一个数据库上让数 据库不堪重负,大部分网站开始使用主从复制技术来达到读写分离,以提高读写性能和读库的可扩展 性。Mysql的master-slave模式成为这个时候的网站标配了
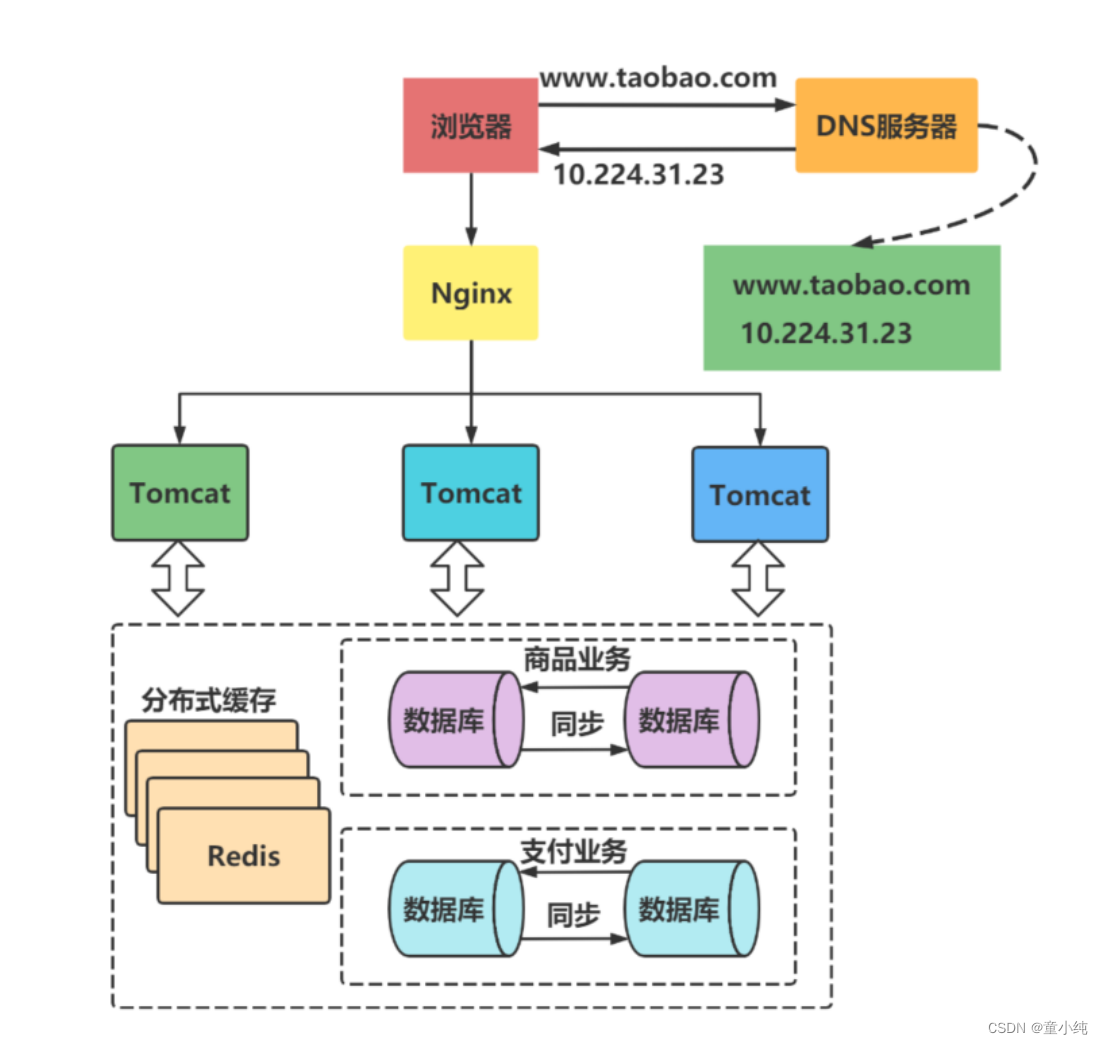
新的挑战:
业务逐渐变多,不同业务之间的访问量差距较大,不同业务直接竞争数据库,相互影响性能。
数据库按业务分库
把不同业务的数据保存到不同的数据库中,使业务之间的资源竞争降低,对于访问量大的业务,可以部署更多的服务器来支撑。
为什么用NoSQL
用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL数据库的发展也却能很好的处理这些大的数据。

1. 单机Mysql的架构,随着用户数的增长,并发读写数据库成为瓶颈如何解决。
引入本地缓存和分布式缓存
2. 单机Tomcat压力大,响应逐渐变慢如何解决。 引入反向代理实现负载均衡
Redis概述_什么是NoSQL

什么是NoSQL

结构化数据和非结构化数据


NoSQL的四大分类

KV型NoSql(代表----Redis)
KV型NoSql顾名思义就是以键值对形式存储的非关系型数据库,是最简单、最容易理解也是大家最熟悉 的一种NoSql,因此比较快地带过。

注意:
KV型NoSql最大的优点就是高性能,利用Redis自带的BenchMark做基准测试,TPS可达到10万的级别,性能非常强劲。
列式NoSql(代表----HBase)
列式NoSql,大数据时代最具代表性的技术之一了,以HBase为代表。
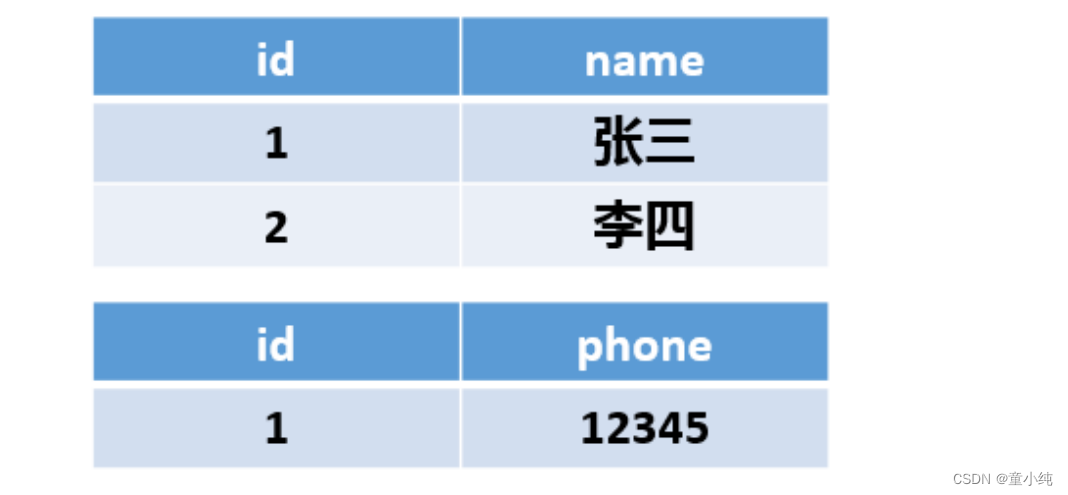
关系行数据库数据

注意:
看到每行有name、phone、address三个字段,这是行式存储的方式,且可以观察id = 2的这条数 据,即使phone字段没有,它也是占空间的。
列式数据库数据

文档型NoSql(代表----MongoDB)
什么是文档型NoSql呢,文档型NoSql指的是将半结构化数据存储为文档的一种NoSql,文档型NoSql通 常以JSON或者XML格式存储数据。

注意:
关系型数据库是按部就班地每个字段一列存,在MongDB里面就是一个JSON字符串存储。
搜索型NoSql(代表----ElasticSearch)

传统关系型数据库主要通过索引来达到快速查询的目的,但是在全文搜索的场景下,索引是无能为力 的,like查询一来无法满足所有模糊匹配需求,二来使用限制太大且使用不当容易造成慢查询,搜索型 NoSql的诞生正是为了解决关系型数据库全文搜索能力较弱的问题,ElasticSearch是搜索型NoSql的代表产品。

关系型数据库和非关系型数据及其区别
关系型数据库


非关系型数据库



1. 为什么使用NoSQL技术说法正确的是_____。 解决数据量大,种类繁多出现性能问题
2. 如下针对NoSQL特点不正确的是_____。 支持事务
Redis概述_当下NoSQL经典应用
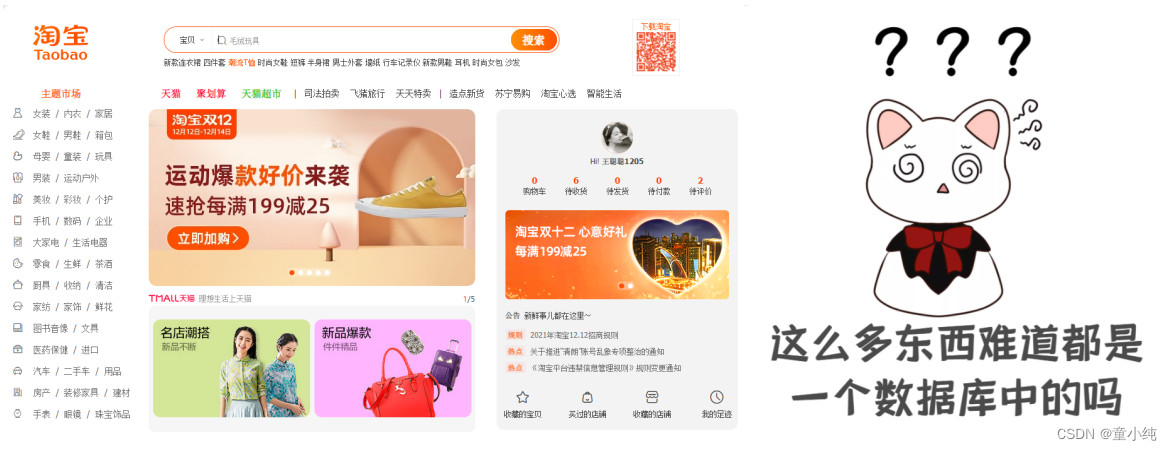
当下应用是SQL和NoSQL一起使用

淘宝商品信息如何存放

商品基本信息
名称、价格、出厂信息、生产厂商,商家信息等, 关系型数据库就可以解决。
注意:
淘宝内部用的Mysql是里面的大牛自己改造过的。
商品描述、详情、评论

多文件信息描述类,IO读写性能变差不能使用Mysql数据库,使用MongDB。
商品的图片

分布式文件系统:
1. 淘宝自己的TFS
2. Google的GFS
3. Hadoop的HDFS
4. 阿里云的OSS
商品关键字

搜索引擎 elasticsearch 或者 ISerach
商品热门的波段信息
内存数据库 Redis Tair Memache

发现问题
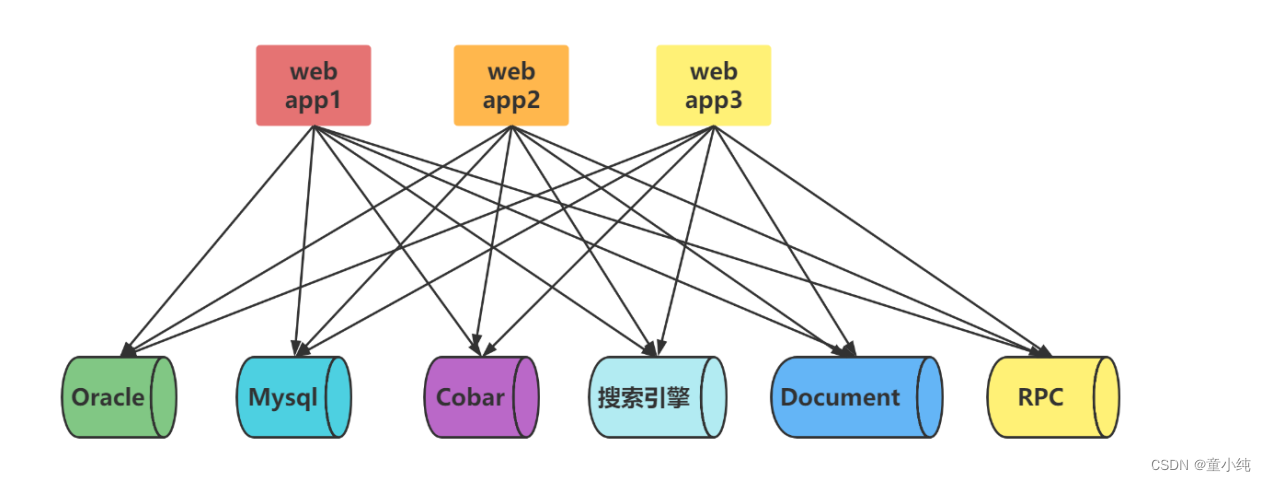

解决问题
UDSL统一数据服务平台
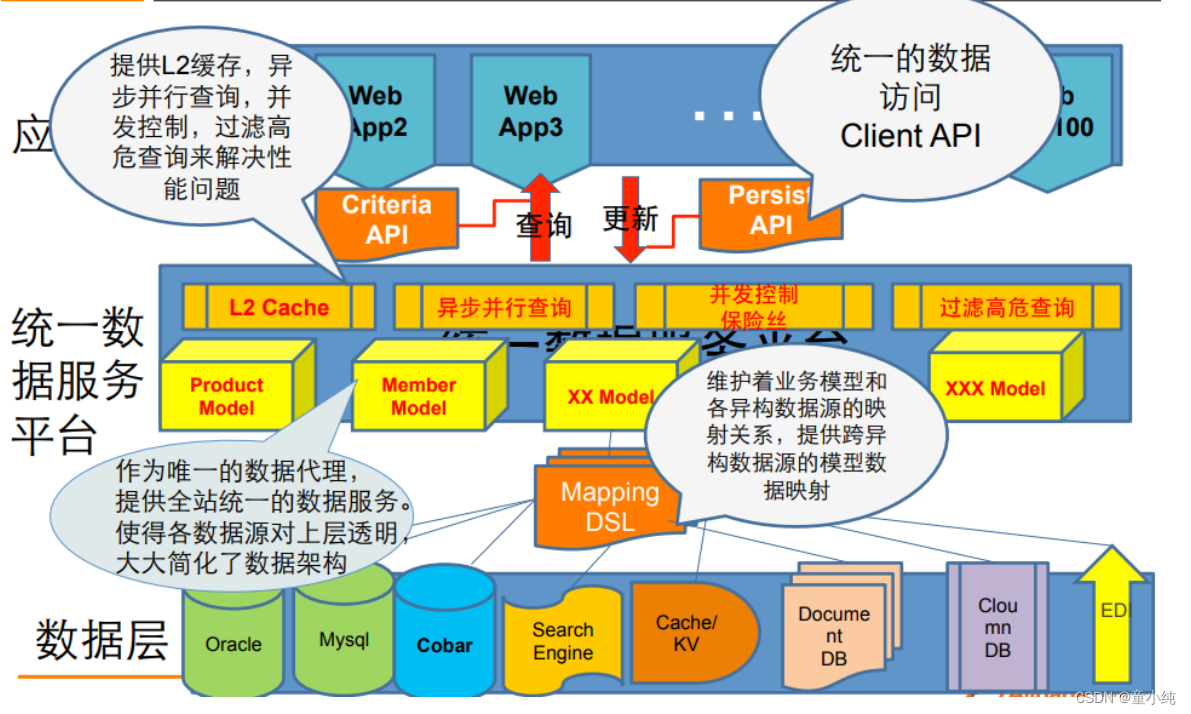
UDSL热点缓存设计

1. 淘宝第五代架构升级解决_____问题。语言多不兼容
Redis概述_Redis是什么

Redis是什么
Redis是一个使用ANSI C编写的开源、包含多种数据结构、支持网络、基于内存、可选持久性的键值对存储数据库。

谁在用Redis

1. Redis是____。 分布式缓存
2. Redis采用的是_____的存储形式。 键值对
Redis安装_Linux下安装Redis

下载地址
Redis官方网址:https://redis.io/
下载Redis

redis-6.2.4.tar.gz上传至CentOS并解压,解压后得到redis-6.2.4目录
解压命令:
tar -zxvf redis-6.2.4.tar.gz
安装GCC
安装C语言编译环境
yum install -y gcc
通过使用 gcc --version 命令打印 GCC 版本,来验证 GCC 编译器是否被成功安装:
gcc --version
安装Redis
编译Redis
在redis-6.2.4目录下执行:
make
安装Redis
在redis-6.2.4目录下执行:
make install
安装目录: /usr/local/bin
服务启动
前台启动:/usr/local/bin下执行
./redis-server后台启动
修改redis.conf文件
daemonize yes #由no改为yes启动服务
./redis-server ../redis.conf客户端启动
/usr/local/bin下执行
./redis-cliping命令可以检测服务器是否正常(服务器返回PONG)
127.0.0.1:6379> ping PONG



Redis安装_Docker下安装Redis

下载最新Redis镜像
docker pull redis
注意:
可以用docker pull redis命令下载最新版本的Redis镜像,也可 以用“docker pull redis:标签”命令下载指定版本的Redis。
启动Redis容器
docker run -itd --name myFirstRedis -p 6379:6379
redis:latest观察Redis启动效果
docker logs myFirstRedis
注意: 如果直接在Linux等环境上启动Redis服务器,就能直接看到启动后的效果。
查看Redis的版本
先确保myFirstRedis容器处于Up状态。进入容器的命令行交互窗口。
docker exec -it myFirstRedis /bin/bash
redis-server --versionRedis服务器和客户端
Redis是基于键值对存储的NoSQL数据库,其中的数据是存储在 Redis服务器里的。和传统的MySQL数据库服务器相似,一个Redis服务器可以同多个客户端创建连接。
docker exec -it myFirstRedis /bin/bash
redis-cli
Redis安装_基本知识

默认16数据库
Redis是一个字典结构的存储服务器,一个Redis实例提供了多个用来存储数据的字典,客户端可以指定 将数据存储在哪个字典中。 这与在一个关系数据库实例中可以创建多个数据库类似(如下图所示),所以可以将其中的每个字典都 理解成一个独立的数据库。

Redis默认支持16个数据库,可以通过调整Redis的配置文件redis/redis.conf中的databases来修改这一 个值,设置完毕后重启Redis便完成配置。

Redis 使用的到底是多线程还是单线程?
因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。
IO多路复用技术

redis 采用网络IO多路复用技术来保证在多连接的时候, 系统的高吞吐量。
大白话解释
假设你是一个机场的空管, 你需要管理到你机场的所有的航线, 包括进港,出港, 有些航班需要放到 停机坪等待,有些航班需要去登机口接乘客。
最简单的做法,就是你去招一大批空管员,然后每人盯一架飞机, 从进港,接客,排位,出港,航线监 控,直至交接给下一个空港,全程监控。

怎么解决
这个东西叫flight progress strip. 每一个块代表一个航班,不同的槽代表不同的状态,然后一个空管员可 以管理一组这样的块(一组航班),而他的工作,就是在航班信息有新的更新的时候,把对应的块放到 不同的槽子里面。
结论
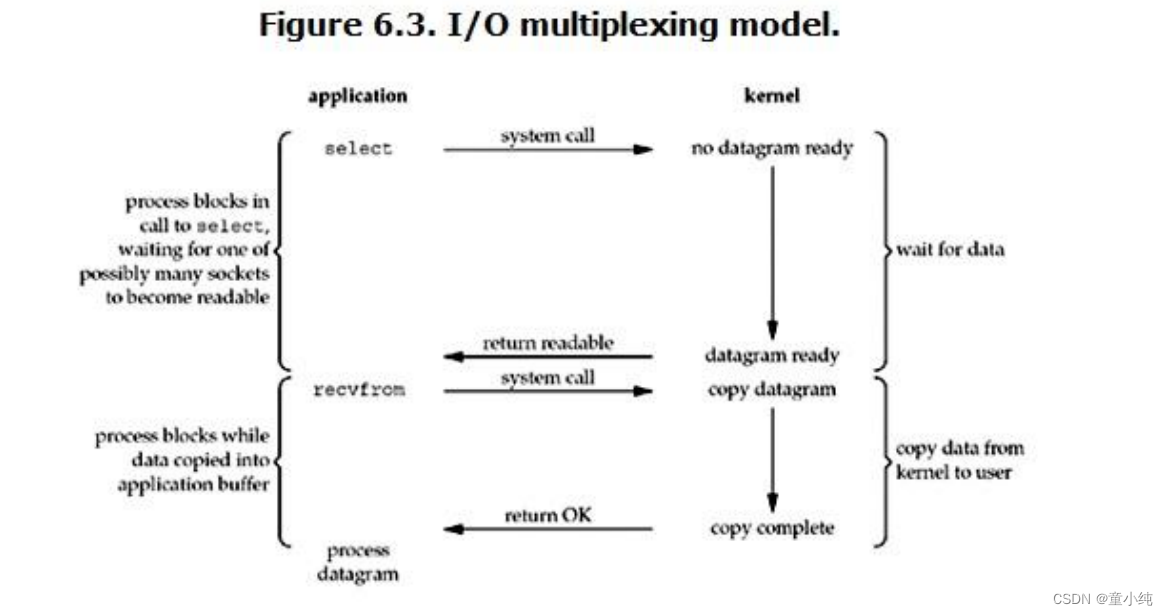
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程 高效的处理多个连接请求(尽量减少网络IO的时间消耗),且Redis在内存中操作数据的速度非常快(内存内的操作不会成为这里的性能瓶颈),主要以上两点造就了Redis具有很高的吞吐量。
切换数据库
语法结构:
select number示例:
# 默认使用 0 号数据库 redis 127.0.0.1:6379> SET db_number 0 OK # 使用 1 号数据库 redis 127.0.0.1:6379> SELECT 1 OK
清空当前库
Redis Flushdb 命令用于清空当前数据库中的所有 key。
语法结构:
127.0.0.1:6379> FLUSHDB示例:
127.0.0.1:6379> FLUSHDB
通杀全部库
Redis Flushall 命令用于清空整个 Redis 服务器的数据(删除所有数据库的所有 key )。
语法结构:
redis 127.0.0.1:6379> FLUSHALL示例:
# 清空所有数据库的所有 key redis 127.0.0.1:6379>flushall OK
为什么默认端口6379
意大利的一位广告女郎名字叫Merz全名Alessia Merz。
1. Redis采用____模型。 多路I/O复用
2.Redis默认_____数据库。16
Redis数据类型_key键
keys
查看当前库中所有的key 。
语法结构:
keys *
示例:
keys *
新版本也进行了替代:
root@6c068b3fbf29:/data# redis-cli --scan "u*" "user1" "user"


exists
判断某个key是否存在,返回1表示存在,0不存在。
语法结构:
exists key示例:
#查看k1是否存在,如果存在返回1 exists k1 # 查看k1 k2 k3是否存在,如果k1 k2存在,k3不存在,则返回2 exists k1 k2 k3

type
查看当前key 所储存的值的类型。返回当前key所储存的值的类型,如string 、list等。
语法结构:
type key示例:
type k1
del
删除已存在的key,不存在的 key 会被忽略。
语法结构:
del key示例:可以设置多个key,返回删除成功的个数。

expire
给key设置time秒的过期时间。设置成功返回 1 。 当 key 不存在返回 0。
语法结构:
expire key time示例:
# 给k1设置10秒后过期 expire k1 10
ttl
以秒为单位返回 key 的剩余过期时间。
语法结构:
ttl key示例:
ttl k1

persist
移除给定 key 的过期时间,使得 key 永不过期。
语法结构:
persist key示例:
persist k1

1. Redis技术中查看当前库中所有的key的命令_____。 keys
2. Redis技术中如何删除已存在的key。del






![[附源码]Python计算机毕业设计Django疫情物资管理系统](https://img-blog.csdnimg.cn/adde5e3965a348309855f50bfb5f8e89.png)