一、MyCat概述
Mycat是数据库中间件。
使用场景:
高可用性与Mysql读写分离
- 业务数据分级存储
- 大表水平拆分,
- 集群并行计算
- 数据库连接池
- 整合多个数据源整合
安装
下载地址:http://dl.mycat.org.cn
安装Mycat之前,需要安装Mysql、JDK,安装Mycat稳定版是1.6.7.1
下载好的安装包文件 (Mycat-xxx-linux.tar.gz),上传Linux服务器上,一般安装在/usr/local下,进行解压
tar -zxvf Mycat-xxx-linux.tar.gz
安装成功,进入mycat目录,能看到
- bin:命令文件
- catlet:空的,扩展
- conf:配置文件(server.xml,schema.xml,rule.xml等)
- lib:依赖的jar包
核心概念
分片
我们将存放同一个数据库中数据分散到多个数据库中,达到单台设备负载效果。当数据库量超过800万,需要做分片处理。
数据库切分:
- 垂直拆分:如果因为表多导致数据多,使用垂直切分,根据业务切分成不同的库;
- 横向拆分:如果因为单张表的数据量太大,使用水平切分。分库分表的顺序应该是先垂直分,后水平分。
垂直拆分:
- 垂直分表:大表拆小表,一般是表中的字段较多,将不常用的,数据较大,长度较长字段的拆分到“扩展表。
- 垂直分库:针对系统中的不同业务进行拆分,比如用户User一个库,商品Producet一个库,订单Order一个库。
切分后,放在多个服务器上。在高并发场景下,垂直分库一定程度上能够突破IO、连接数及单机硬件资源的瓶颈。
水平拆分:
- 水平分表:针对数据量大的单张表,按照某种规则(RANGE,HASH取模等),切分到多张表里面去。
但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈。不建议采用。 - 水平分库分表:将单表的数据切分到多个服务器上,每个服务器具有相应的库与表,只是表中数据集合不同。 切分规则:1.
从0到10000一个表,10001到20000一个表;2. HASH取模; 3. 地理区域。
逻辑库
Mycat是数据库中间件,可以被看做一个/多个数据库集群构成的逻辑库。然后下面的逻辑表,读写数据的表就是逻辑表。
ER表
表的记录与所有关联的父表记录存放同一个数据分片中,保证数据关联查询不会垮库操作。
全局表
类似于数据字典表,把这些冗余数据定义为全局表。
分片节点
数据切分,一个大表被分到不同的分片数据库上,每个表分片所在数据库就是分片节点。
分片主机
同一机器上存在多个分片数据库,这个分片节点所在的机器是节点主机。
常用命令
#启动、停止、查看状态
bin/mycat start
bin/mycat stop
bin/mycat status
#连接命令:连接端口号:8066
mysql -h (IP地址) -P 8066 -u root -p
连接管理命令:连接端口号:9066
mysql -h (IP地址) -P 9066 -u root -p
相关配置项及含义
配置server.xml
常用系统配置
- charset 值 utf8 字符集
- useSqlStat 值 0 1 开启实时统计 0 关闭
- sqlExecuteTimeout 值 1000 SQL语句超时时间
- processors 值1,2… 指定线程数量
- txIsolation 值1,2,3,4 事务的隔离级别
- serverPort值8066 使用端口号
- mangerPort 值9066 管理端口号
user 标签定义登录Mycat用户和权限:
<user name="mycat用户名2">
<property name="password">密码</property>
<property name="schemas">逻辑库名</property>
<property name="readOnly">true(是否只读)</property>
<property name="benchmark">1000(连接数,0代表不限制)</property>
<property name="usingDecrypt">1(是否加密,1加密)</property>
<!--权限设置-->
<privileges check="true">
<schema name="逻辑库名" dml="0000">
<table name="逻辑表" dml="0000"></table>
<table name="逻辑表" dml="0000-代表增改查删的权限,1代表有,0没有"></table>
</schema>
</privileges>
</user>
# 注意
# 设置了密码加密,需要在/lib目录下执行
java -cp Mycat-server-xxx.release.jar io.maycatutil.DecryptUtil 0:root:密码
# 然后得到加密的密码,然后在配置文件密码改成加密后的密码
firewall标签定义防火墙:
<firewall>
<!--白名单-->
<whitehost>
<host user="root" host="IP地址"></host>
</<whitehost>
<!--黑名单 这个用户有哪些SQl的权限-->
<blacklist check="true">
<property name="selelctAllow">true</property>
<property name="deleteAllow">false</property>
</<blacklist>
</firewall>
配置schema.xml
配置逻辑库、逻辑表、分片、分片节点。
- schema 逻辑库,可以有多个
- table 逻辑表,它属性:rult:分片规则名 type:类型(全局表、普通表)
- dataNode定义数据节点,不能重复
- dataHost 具体的数据库实例,节点主机
- database 定义分片所属的数据库
dataHost 标签节点主机:
- name 节点名称
- maxCon 最大连接数
- minCon 最小连接数
- balance 负载均衡类型 0,1,2,3
- writeType写操作分发方式 0:读写操作都是第一台writeHost 1:随机发送writeHost 上
- switchType 数据库切换测试 -1.1,2,3
writeHost 、readHost标签读写主机:
- host 实例主机标识
- url 数据库连接地址
- weight 权重
- usingDecrypt 密码加密 0否1是
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="逻辑库名" checkSQLschema="false" sqlMaxLimit="100">
<!-- name:这张表进行分库,使用数据节点 -->
<table name="逻辑表" dataNode="数据节点d1,数据节点d2,数据节点d3" rule="分片规则"></table>
</schema>
<!-- dataNode:数据结点 dataHost:主机名 database:分库的名字的数据库名字 -->
<dataNode name="数据节点d1" dataHost="host1" database="数据库1" />
<dataNode name="数据节点d2" dataHost="host2" database="数据库1" />
<dataNode name="数据节点d3" dataHost="host3" database="数据库1" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100" >
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="地址1:3306" user="root" password="123123"></writeHost> </dataHost>
...
</mycat:schema>
配置rule.xml
定义拆分表的规则
tableRule 标签:
- name 分片名称
- rule 分片具体算法
- columns 分片列名
- algoorithm 算法方法名
function 标签:
- name 算法名称
- class 具体类
<tableRule name="mod_rule">
<rule>
<columns>customer_id</columns>
<algorithm>mod-long</algorithm>
</rule>
...
</tableRule>
<!--函数算法,这个算法是根据选中的字段进行取模的规则进行拆分-->
<function name="mod-long" class="io.mycat.route.function.PartitionByMod" >
<property name="count">2</property>
</function>
配置sequence.xml
原有的主键自增不满足集群中主键唯一约束,mycat提供全局序列,保证全局唯一。
- 本地文件方式
- 数据库方式
- 本地时间戳
- 其他方式
- 自增长主键
分片
**架构演变:**单机数据库-由于越来越多的请求,我们将数据库进行读写分离,主机负责写,从机负责读,从库可以水平扩展,所以更多的读请求不成问题。当数据量增大后,写请求越来越多,就需要用到分库分表,对写操作进行切分。
**单库太大:**单个数据库处理能力有限;解决方法:切分成更多更小的库
**单表太大:**CRUD都成问题;索引膨胀,查询超时;解决方法:切分成多个数据集更小的表。
分库分表的方式方法:
分为 垂直切分 和 水平切分,如果因为表多导致数据多,使用垂直切分,根据业务切分成不同的库;如果因为单张表的数据量太大,使用水平切分。分库分表的顺序应该是先垂直分,后水平分。
垂直拆分
演示:当一个数据库数据量很大,对这些表进行分片处理,把一个数据库拆分多个数据库,分为用户库、订单库、信息表…
步骤1:
准备3个数据库实例,分别创建属于自己的库(用户库、订单库…)
配置server.xml (配置用户、字符集、逻辑库名)
<user name="mycat用户名">
<property name="password">密码</property>
<property name="schemas">逻辑库名</property>
</user>
步骤2:
配置schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="逻辑库名" checkSQLschema="false" sqlMaxLimit="100">
<table name="用户表1" dataNode="d1" primaryKey="主键ID"></table>
<table name="用户表2" dataNode="d1" primaryKey="主键ID"></table>
<table name="用户表3" dataNode="d1" primaryKey="主键ID"></table>
<table name="字典表1" dataNode="dn1,dn2" type="global" ></table>
<table name="订单表1" dataNode="d2" primaryKey="主键ID"></table>
<table name="订单表2" dataNode="d2" primaryKey="主键ID"></table>
<table name="订单表3" dataNode="d2" primaryKey="主键ID"></table>
</schema>
<dataNode name="d1" dataHost="host1" database="用户库" />
<dataNode name="d2" dataHost="host2" database="订单表" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100" >
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="地址1:3306" user="root" password="123123"></writeHost> </dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100" >
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="地址2:3306" user="root" password="123123"></writeHost> </dataHost>
</mycat:schema>
步骤3:
在不同的数据库创建数据,如果有字典表,把字典表分别在不同的数据库进行创建,避免垮库查询
备份命令:mysqldump -uroot -pitcast 库名 表名 > 文件名
把备份出的字典表数据,分别在其他数据库里创建,并配置schema.xml,增加全局表(global)
字典表和关联子表配置
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<table name="customer" dataNode="dn2" ></table>
<table name="orders" dataNode="dn1,dn2" rule="mod_rule">
<!-- childTable:关联子表 primaryKey:子表主键 joinKey:关联字段 parentKey:父表的关联字段-->
<childTable name="orders_detail" primaryKey="id" joinKey="order_id" parentKey="id" />
</table>
<!--例如字典表,需要在host1 host2 主键都创建,type:定义global 全局表 -->
<table name="dict_order_type" dataNode="dn1,dn2" type="global" ></table>
</schema>
<dataNode name="dn1" dataHost="host1" database="数据库1" />
<dataNode name="dn2" dataHost="host2" database="数据库2" />
启动Mycat,配置完成。
水平拆分
将同一个表中数据按某种规则拆分到多台数据库主机上。
演示:当一个张表数据量很大,对这些表进行分片处理,拆分3台数据库主机上。
步骤1:
准备3个数据库实例,分别创建属于自己的库(用户库)
配置server.xml (配置用户、字符集、逻辑库名)
步骤2:
配置schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="逻辑库名" checkSQLschema="false" sqlMaxLimit="100">
<table name="用户表1" dataNode="d1,d2,d3" primaryKey="主键ID" rule="mod_rule(取模分片)">
</table>
</schema>
<dataNode name="d1" dataHost="host1" database="用户库" />
<dataNode name="d2" dataHost="host2" database="用户库" />
<dataNode name="d3" dataHost="host3" database="用户库" />
<dataHost name="host1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100" >
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="地址1:3306" user="root" password="123123"></writeHost> </dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100" >
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="地址2:3306" user="root" password="123123"></writeHost> </dataHost>
<dataHost name="host3" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100" >
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="地址3:3306" user="root" password="123123"></writeHost> </dataHost>
</mycat:schema>
步骤3:
配置rule.xml
<tableRule name=“mod_rule“>
<rule>
<columns>customer_id</columns>
<algorithm>mod-long</algorithm>
</rule>
...
</tableRule>
<!--函数算法,这个算法是根据选中的字段进行取模的规则进行拆分-->
<function name=“mod-long” class=“io.mycat.route.function.PartitionByMod” >
<property name="count">3</property>
</function>
步骤4:
启动Mycat,在Mycat下创建表结构,然后其他数据库也就创建表结构数据。
进行测试,我们创建一些数据,然后根据分片规则,在对应的数据库创建对应的数据。
分片规则:
- mod-long 取模分片
- auto-sharding-long 范围分片
配置 autopartition-long.txt文件 # M=10000 k=1000 0-500M=0 500M-1000M=1 1000M-1500M=2
- sharding-by-intfile 枚举分片 本规则适合省份、状态拆分数据
<tableRule name=“sharding-by-intfile“>
<rule>
<columns>status</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name=“hash-int” class=“io.mycat.route.function.ParitionByFileMap” >
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">0</property>
<property name="defaultNode">0 (默认的节点)</property>
</function>
# partition-hash-int.txt 1=0 2=1 3=2 # 根据状态status字段进行拆分,值1为第一个数据库,值2为第二个数据库,值3为第三个数据库
- auto-sharding-rang-mod 范围分片(先进行范围分片,计算分组,再进行组内求模)
<tableRule name=“auto-sharding-rang-mod“>
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule>
<function name=“rang-mod” class=“io.mycat.route.function.PartitionByRangeMod” >
<property name="mapFile">autopartition-range-mod.txt</property>
<property name="defaultNode">0 (默认的节点)</property>
</function>
# autopartition-range-mod.txt 0-500M=1 500M1-200M=2 # M=10000 2是2个节点
- sharding-by-long-hash 固定分片hash算法
- sharding-by-prefixpattern 字符串hash求模范围算法
- sharding-by-murmur 一致性hash算法
# 有效解决分布式数据的拓容问题,均匀的分散到数据库节点上
<tableRule name=“sharding-by-murmur“>
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<function name=“murmur” class=“io.mycat.route.function.PartitionByMurmurHash” >
<property name="seed">0</property>
<property name="count">3(要分片的数据库节点)</property>
<property name="virtualBucketTimes">160</property>
</function>
- sharding-by-date 日期分片算法
- sharding-by-month 自然月分片算法
全局序列:
一旦分库,在不同机器上部署mysql,新增数据,表的主键可能出现相等状况,为了避免这个设置全局序列。
- 本地文件:不推荐,一旦mycat挂了,本地文件也访问不到。
- 数据库方式:利用数据库一个表来进行计数累加。mycat会预加载一部分号段到mycat的内存中,这样大部分读写序列都是在内存中完成的。如果内存中的号段用完了 mycat会再向数据库要一次。
- 时间戳方式:默认的,但是时间戳格式长,性能不好。
- 自主生成:根据业务逻辑组合,需要改Java代码。
设置数据库方式:
# 1.创建表
CREATE TABLE MYCAT_SEQUENCE (
NAME VARCHAR(50) NOT NULL,
current_value INT NOT NULL,
increment INT NOT NULL DEFAULT 100,
PRIMARY KEY(NAME)
) ENGINE=INNODB;
# 2.创建3个函数
DELIMITER $$
CREATE FUNCTION mycat_seq_currval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)
DETERMINISTIC
BEGIN
DECLARE retval VARCHAR(64);
SET retval="-999999999,null";
SELECT CONCAT(CAST(current_value AS CHAR),",",CAST(increment AS CHAR)) INTO retval FROM
MYCAT_SEQUENCE WHERE NAME = seq_name;
RETURN retval;
END $$
DELIMITER;
DELIMITER $$
CREATE FUNCTION mycat_seq_setval(seq_name VARCHAR(50),VALUE INTEGER) RETURNS VARCHAR(64)
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = VALUE
WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END $$
DELIMITER;
DELIMITER $$
CREATE FUNCTION mycat_seq_nextval(seq_name VARCHAR(50)) RETURNS VARCHAR(64)
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment WHERE NAME = seq_name;
RETURN mycat_seq_currval(seq_name);
END $$
DELIMITER;
# 3 插入序列的表,初始化MYCAT_SEQUENCE数据
字段1:全局序列名字,字段2:多少号开始,字段3:一次性给多少
SELECT * FROM MYCAT_SEQUENCE
INSERT INTO MYCAT_SEQUENCE(NAME,current_value,increment) VALUES ('ORDERS', 400000,100);
# 4 更改mycat配置:
修改这个文件:sequence_db_conf.properties
把要改的表,如order表改成 = dn1 结点
# 5 更改server.xml文件:
把下面的类型改成1 的类型是数据库方式,更改完进行重启
...
<property name="sequnceHandlerType">1</property>
# 6 执行新增操作 增加要用的序列
insert into `orders`(id,amount,customer_id,order_type) values(
next value for MYCATSEQ_ORDERS
,1000,101,102);
性能监控
Mycat-web
帮助我们统计任务和配置管理任务。可以统计SQL并分析慢SQL和高频SQL,为优化SQL提供依据。
安装 Mycat-web
步骤1:
安装Mycat-web之前,需要安装JDK,zookeeper,官方地址:http://zookeeper.apache.org
安装zookeeper:下载好的安装包文件 (zookeepe-xxx.tar.gz),上传Linux服务器上,一般安装在/usr/local下,进行解压
tar -zxvf zookeeper-xxx.tar.gz
解压完,在当前目录(/usr/loca/zookeeper)创建data目录,切换到conf目录下,修改配置文件 zoo_sample.cfg 重命名为 zoo.cfg,修改完进行编辑这个文件
dataDir=/usr/loca/zookeeper/data
启动zookeeper
bin/zkServer.sh start
步骤2:
安装Mycat-web ,下载地址:http://dl.mycat.org.cn
选择mycat-web目录下文件进行下载,下载好的安装包文件,上传Linux服务器上,一般安装在/usr/local下,进行解压
tar -zxvf Mycat-web-xxx-linux.tar.gz
解压完,在当前目录(/usr/loca/mycat-web),如果多个,启动程序:
sh start.sh
启动程序,访问http://ip地址:8082/mycat,通过这个网址进行监控Mycat。
步骤3:
配置Mycat,打开网址,菜单栏 - mycat服务管理 - 新增 (新增要监控的Mycat)注意:管理端口9066 服务端口8066
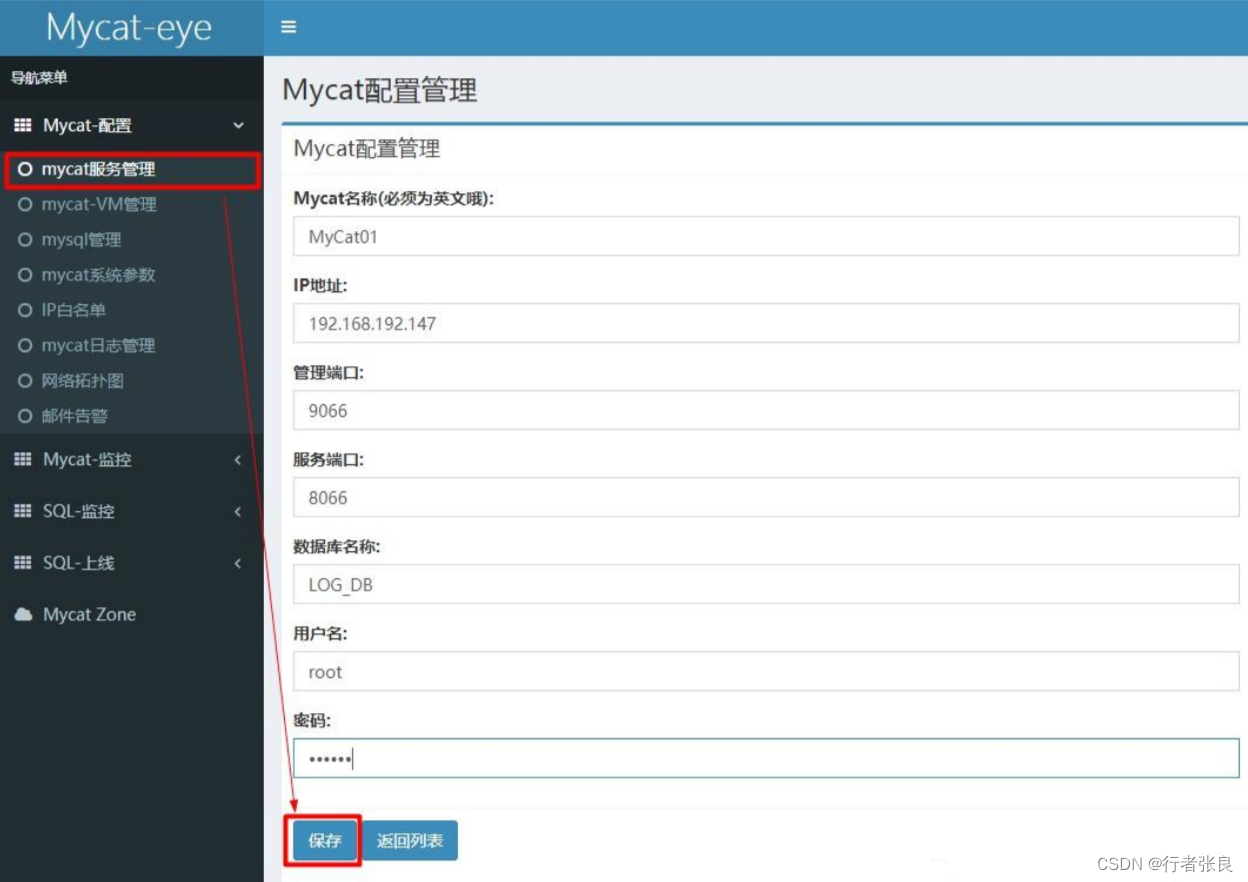
二、配置读写分离
1、一主一从配置读写分离
首先配置数据库的主从复制,详见:https://blog.csdn.net/hualinger/article/details/131292136
步骤1 更改server.xml文件:
设置mycat的用户名和密码,schemas部分设置mycat的逻辑库名。
...
<user name="mycat用户名">
<property name="password">密码</property>
<property name="schemas">TESTDB</property>
</user>
步骤2 更改schema.xml 文件:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="逻辑库名" checkSQLschema="false" sqlMaxLimit="100">
<table name="表1" dataNode="dn1" primaryKey="主键ID"></table>
</schema>
<dataNode name="dn1" dataHost="host1" database="数据库名" />
<!-- dataHost:主机名 balance: 负载均衡类型 0 不开启 1 双主双从 2 随机分发 3 主写从读 -->
<dataHost name="host1" maxCon="1000" minCon="10" balance="3" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100" >
<heartbeat>select user()</heartbeat>
<!-- 配置写主机 host:写主机名字,url:主机的地址 user:主机的用户名 password:主机密码 -->
<writeHost host="hostm1" url="192.168.67.1:3306" user="root" password="123123">
<!-- 配置从机 读库(从库)的配置 -->
<readHost host="hosts1" url="192.168.67.131:3306" user="root" password="123123">
</readHost>
</writeHost>
</dataHost>
</mycat:schema>
步骤3 配置Mycat日志:
在/usr/local/mycat/conf配置,修改log4j2.xml
<asyncRoot level="debug" includeLocation="true">...<asyncRoot>
日志修改为debug模式
步骤4 启动Mycat
# 方式1 - 控制台启动 :去mycat/bin 目录下 执行 mycat console
[root@... bin]# ./mycat console
# 方式2 - 后台启动 :去mycat/bin 目录下 mycat start
[root@... bin]# ./mycat start
如果启动失败,报错域名解析失败
解决:修改 /etc/hosts ,在 127.0.0.1 后面增加你的机器名,修改后,重启服务 service network restart
启动成功,登录MyCat:
# 后台管理的窗口:
mysql -uroot -p 密码 -h 192.168.67.131 -P 9066
# 数据窗口窗口:
mysql -uroot -p 密码 -h 地址 -P 8066
# 登录后,查询库
show databases;
配置完成,进行演示,
在/usr/local/mycat/log查看日志信息,方便看走的哪个数据库
tail -f mycat.log # 查看日志
2、双主双从配置读写分离
首先配置数据库的主从复制,4个数据库,2主机,2从机。详见:https://blog.csdn.net/hualinger/article/details/131292136
步骤1 配置读写分离
通过Mycat配置读写分离,更改server.xml文件:
设置mycat的用户名和密码,schemas部分设置mycat的逻辑库名。
步骤2 更改schema.xml 文件:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="逻辑库名" checkSQLschema="false" sqlMaxLimit="100">
<table name="表1" dataNode="dn1" primaryKey="主键ID"></table>
</schema>
<dataNode name="dn1" dataHost="host1" database="数据库名" />
<!-- dataHost:主机名 balance: 负载均衡类型 0 不开启 1 双主双从 2 随机分发 3 主写从读 -->
<!-- writeType 0写操作在第一主机,如果挂掉,会连接第二主机 1随机发送主机上 -->
<!-- writeType -1不自动切换 1自动切换 2基于心跳状态决定-->
<dataHost name="host1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100" >
<heartbeat>select user()</heartbeat>
<!-- 配置写主机 host:写主机名字,url:主机的地址 user:主机的用户名 password:主机密码 -->
<writeHost host="hostm1" url="主机1:3306" user="root" password="123123">
<readHost host="hosts1" url="从机1:3306" user="root" password="123123">
</readHost>
</writeHost>
<writeHost host="hostm2" url="主机2:3306" user="root" password="123123">
<readHost host="hosts2" url="从机2:3306" user="root" password="123123">
</readHost>
</writeHost>
</dataHost>
</mycat:schema>
步骤4 配置Mycat日志:
在/usr/local/mycat/conf配置,修改log4j2.xml
...
<asyncRoot level="debug" includeLocation="true">...<asyncRoot>
日志修改为debug模式
步骤5 启动Mycat
# 方式1 - 控制台启动 :去mycat/bin 目录下 执行 mycat console
[root@... bin]# ./mycat console
# 方式2 - 后台启动 :去mycat/bin 目录下 mycat start
[root@... bin]# ./mycat start
启动成功,登录MyCat,配置完成,进行演示。
检查Mycat的主从复制是否正常,主机1创建数据,从机1。主机2 都有复制成功。