1.贡献
本文的task还是在synthetic的data上训练,在real data上测试,并且之前的方法主要是先将synthetic的data风格转化成real的风格,再训练,来减轻domain的gap带来的问题,但是之前的这样做存在几个问题,第一,风格迁移本身会对原来的synthetic image造成除了色调以外的结构上的变化,以至于导致其跟对应的gt存在一些mis align的问题,第二,风格迁移会造成对细节的破坏,尤其是密集场景,失去细节是比较严重的问题,第三,real data中存在一些synthetic data里没有的背景元素,这是风格迁移无法弥补的
第一第二都是风格迁移本身的问题,本文借鉴了structure跟texture分离的思想,结合structure跟texture去重建,以求获得更好的风格迁移效果,然后在对synthetic风格迁移到real上之后,再进行普通的counting的training,获得初步的counting 模型。第三是由于没法在real data上训练的问题,本文提出了利用假标签的方法,实现在real data上的训练,假标签来源于利用初步的counting模型real data上测试,然后根据预测结果去制作假标签,再在real data上用假的gt去fine-tune模型。
我觉得本文最大的亮点不是前面的风格迁移的改进,而是后面这种假标签思想吧。
2.方法

(一)概述
本文是一个三阶段的过程,第一个阶段是风格迁移,利用了cycle-gan,目的是为了将Source domain,也就是synthetic的image风格转化为real的风格,以便缩小两个domain的差距,
第二个阶段是在完成风格迁移的synthetic data上初步训练一个counting 模型
第三个阶段是利用初步训练的模型对real data预测一个结果,根据结果制作假的gt,再用假的gt fine-tune模型
(2)第一阶段——风格迁移
本文的风格迁移借鉴了将structure feature跟texture feature分离的思想,即结构信息,比如人的形状等式domain无关的,而背景,颜色,整体风格等texture信息是domain相关的,因此可以用一个公共的encoder去提取structure feature,而texture feature要用不同的encoder去提取,在一篇分割的论文中《All about Structure: Adapting Structural Information across Domains for Boosting Semantic Segmentation》,也运用了此类思想,不同的是,本文只有一个公共的提取structure feature的encoder,即Gc,而domain相关的texture feature默认各自的decoder会自行添加,所以少了提取texture feature的encoder。
两个decoder分别根据structure feature fs去重建原图,或者实现风格迁移。Istos就是从Source domain重建出来的图片,因为它用了source domain的structure feature,又用了目标为source domain的decoder,即Gtos,所以为重建任务,而target domain的structure feature与Gtos结合,就可以输出synthetic风格的real image,即Ittos
为了让structure feature实现domain 无关,对于这个feature加了一个discriminator,来区分feature来自哪个domain,对于重建任务,用了重建的loss,即Lrec,然后对于风格迁移部分,用的是perceptual loss以及adversarial loss去约束,adversial loss对应的dsicriminator是一个全卷积的网络,输出为输入分辨率的1/4,然后计算pixel-level的bce loss,以下是adversarial loss

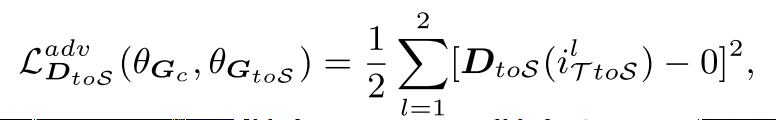
重建的loss Lrec如下:

风格迁移的perceptual loss参见论文《Perceptual Losses for Real-Time Style Transfer and Super-Resolution》
(3)第二阶段——在synthetic data上初步训练counting model
第一阶段完成风格迁移后,在迁移后的synthetic data上用MSE loss训练counting 模型,其实第一阶段和第二阶段是联合训练的,总的loss如下:
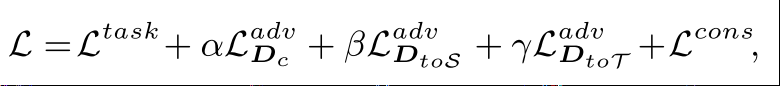
其中Ltask就是训练counting用的MSE loss,Lcons就是上面所说的风格迁移中用的perceptual loss,α=0.01,β=0.1,γ=0.1
(4)第三阶段——制作pseudo gt,fine-tune模型
先用阶段二训练得到的模型去预测real data,获得预测结果,然后对预测结果,每个点处以该点为中心,以一个kxk大小的窗口范围与一个标准的高斯分布比较相似度,来表示该点处存在一个人的可能性,计算方法如下:
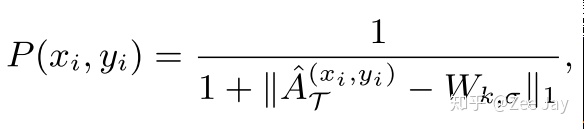
本文称为通过以上方式获得的一张图为probablity map,每个点代表了该点处存在一个标准高斯核的可能性,即该点处存在一个人的可能性。这里的W就是一个标准的高斯核。
然后对于probability map,迭代地找出N个可能为人的点,N为初步预测的density map的求和值,算法过程如下:

核心的思想就是不断寻找probablity map中的最大值,然后用一个标准高斯核去填充该点区域,就跟平时制作counting 的gt一样。
这样制作完pesudo gt后,就结合real data fine-tune一下模型。
3.实验
(1)模型结构

其中的C就是counting model,其他都是generator或者discriminator
(2)消融研究

IFS-a,就是风格迁移部分没有对于Gc的feature-level的discriminator,即无法确保structure feature是domain不变的,然后没有用假标签fine-tune模型
IFS-b,用了本文完整的风格迁移方案,但是没有用假标签fine-tune
IFS-b+GPR-a,直接用阶段二模型的预测结果fine-tune,没有用假标签
IFS-b+GPR-b,阶段二模型预测结果只做了pesudo label后,再fine-tune

(3)与之前的domain adaption的方法比较

由于之前这个方向的work比较少,基本上只能跟作者自己之前的work比较了
(4)风格迁移的结果


4.评论
其实本文算是作者在自己之前CVPR2019的work提出的数据集的进一步利用和方法上的改进吧,structure和texture feature分离的思想也不是最新的,最大的创新点是根据density map制作pesudo label的思想,这个思想可以用来做一些density map预测结果的refine,似乎就挺好用的,值得尝试