Rare Tokens Degenerate All Tokens:Improving Neural Text Generation via Adaptive Gradient Gating for Rare Token Embeddings
摘要
最近的研究发现,大规模神经语言模型学到的Token embeddings(令牌嵌入)具有退化的各向异性和狭锥形状。这种现象被称为表示退化问题,它增加了令牌嵌入之间的整体相似性,对模型的性能产生了负面影响。虽然现有的方法通过观察这一问题引发的现象来解决退化问题,改善了文本生成的性能,但仍未探究导致退化问题的令牌嵌入训练动态。在本研究中,我们分析了令牌嵌入的训练动态,重点关注罕见令牌嵌入。我们证明了在训练阶段,罕见令牌嵌入的梯度特定部分是所有令牌退化问题的关键原因。基于这一分析,我们提出了一种新方法,称为自适应梯度门控(AGG)。AGG通过对罕见令牌嵌入的梯度特定部分进行门控来解决退化问题。语言建模、词语相似性和机器翻译任务的实验结果在定量和定性上验证了AGG的有效性。
“Token embeddings”(令牌嵌入)指的是将文本中的每个词或令牌(token)表示为一个向量的技术。在自然语言处理中,我们通常将文本分割成词或子词级别的令牌,并将每个令牌映射到一个固定维度的向量空间中。这样做的目的是将离散的文本数据转换为连续的向量表示,以便机器学习模型可以更好地处理和理解文本。
令牌嵌入的生成可以使用不同的方法,例如Word2Vec、GloVe和BERT等。这些方法可以根据上下文信息或其他语言模型来学习令牌之间的关系,并为每个令牌生成对应的向量表示。这些向量在向量空间中的相对位置和距离通常反映了令牌之间的语义相似度。
“各向异性”(anisotropy)指的是令牌嵌入在向量空间中呈现出不同的特性或方向性。如果令牌嵌入是各向同性的,那么它们在向量空间中的分布将是均匀的,没有明显的偏向或方向性。然而,如果令牌嵌入是各向异性的,它们在向量空间中的分布将呈现出不同的方向和形状,可能存在明显的偏向或倾斜。
“狭锥形状”(narrow-cone shape)表示令牌嵌入在向量空间中的分布形状类似于一个狭长的锥形。这意味着令牌嵌入在某些方向上的变化范围较小,而在其他方向上变化范围较大。换句话说,令牌嵌入在某个方向上更加集中和紧凑,而在其他方向上更加分散。
1 介绍
最近几年已经开发了多种不同的神经语言模型架构(Graves,2013;Bahdanau等,2015;Gehring等,2017;Vaswani等,2017)。尽管模型架构有所改进,但模型通常共享相同的输入和输出过程。它们将令牌嵌入作为输入进行处理,计算上下文特征,并随后将这些特征投影到输出的令牌的分类分布中。这个分类分布的权重是令牌嵌入矩阵(Merity等,2017;Yang等,2018;Press和Wolf,2017)。最近的研究发现,学习到的嵌入分布在一个共同的方向上存在偏差,从而导致了一个狭锥形的各向异性(Mu和Viswanath,2018;Ethayarajh,2019;Gao等,2019;Bi´s等,2021)。这种现象被Gao等人(2019)称为表示退化问题,**它增加了嵌入之间的整体相似性,并导致令牌嵌入的表达能力降低。**因此,模型很难学习令牌之间的语义关系并生成高质量的文本。现有研究针对这个问题提出了一些方法,这些方法基于退化问题引发的观察现象,对所有的令牌嵌入应用后处理或正则化技术(Mu和Viswanath,2018;Gao等,2019;Wang等,2019;Wang等,2020;Bi´s等,2021)。尽管这些工作改善了令牌嵌入和生成的文本的质量,但仍不清楚令牌嵌入在训练过程中是如何退化的。此外,对于那些语义关系训练良好的令牌嵌入,上述方法的过度正则化问题仍然存在,因为这些方法应用于所有的令牌嵌入。
在这项研究中,我们对令牌嵌入的训练动态进行了实证研究,重点关注低频率的令牌嵌入。通过观察基于出现频率分组的令牌嵌入的初始训练动态,我们假设罕见令牌嵌入的退化引发了其他令牌嵌入的退化。我们展示了仅在训练过程中冻结罕见令牌可以减轻整个退化问题,并且证明整个退化问题的主要原因是罕见令牌嵌入的梯度特定部分。这个梯度部分将当前训练样本中罕见令牌嵌入与非罕见目标的特征向量分开。基于这个分析,我们提出了一种新方法,自适应梯度门控(AGG)。AGG在每个训练步骤中动态分组罕见令牌,通过对仅与罕见令牌相关的梯度部分进行门控,解决了整个退化问题。由于AGG针对退化问题的主要原因,罕见令牌嵌入进行了优化,它可以避免其他解决退化问题的方法中常见令牌嵌入的过度正则化问题。我们在三个任务(语言建模、词语相似性和机器翻译)中评估了所提出的方法。AGG在所有任务中都优于基线和其他现有方法。此外,它与其他解决神经文本退化问题的方法兼容。通过定性研究,我们发现了我们的方法与学习嵌入的频率偏差问题(Gong等,2018;Ott等,2018)之间的相关性。
2 背景
2.1 神经语言模型的文本生成
神经语言生成模型将文本生成任务处理为条件语言建模,通常通过最小化训练数据的负对数似然来训练模型。假设有一个令牌词汇表 V = v 1 , . . . , v N V = {v_1, ..., v_N} V=v1,...,vN和对应的嵌入向量 w 1 , . . . , w N {w_1, ..., w_N} w1,...,wN,其中 w i w_i wi对应于令牌 v i v_i vi。在每个训练步骤中,模型获取一个小批量的输入和目标文本对 ( x , y ) (x, y) (x,y),其中 x i , y i ∈ V x_i,y_i ∈ V xi,yi∈V,而 y ∈ V T y ∈ V^T y∈VT。对于目标令牌 y t y_t yt的条件概率 P θ = ( y t ∣ h t ) P_θ=(y_t|h_t) Pθ=(yt∣ht),其中 h t h_t ht是由 ( x , y < t ) (x, y<t) (x,y<t)条件下生成文本第 t t t个位置的上下文特征向量, θ θ θ表示模型参数,定义如下:
P θ ( y t ∣ h t ) = e x p ( h t w I ( y t ) T ) ∑ l = 1 N e x p ( h t w l T ) ( 1 ) P_{\theta}(y_t|h_t)=\frac{exp(h_tw^T_{I(y_t)})}{\sum^{N}_{l=1}exp(h_tw^T_l)} (1) Pθ(yt∣ht)=∑l=1Nexp(htwlT)exp(htwI(yt)T)(1)
这里的 w w w是输出令牌嵌入,它在输出softmax层起到权重的作用,而 I ( y t ) I(y_t) I(yt)表示令牌 y t y_t yt的索引。对于输入和目标对 ( x , y ) (x, y) (x,y),负对数似然损失 L N L L L_{NLL} LNLL可以表示如下:
L N L L = − ∑ t = 1 T l o g P θ ( y t ∣ h t ) ( 2 ) L_{NLL}=-\sum^T_{t=1}logP_{\theta}(y_t|h_t) (2) LNLL=−t=1∑TlogPθ(yt∣ht)(2)
2.2 神经语言模型中的Embedding问题
最近对上下文嵌入空间的几何属性的研究观察到,嵌入向量的分布远非各向同性,并且占据相对狭窄的锥形空间(Mu和Viswanath,2018;Liu等,2019;Zhou等,2019;Ethayarajh,2019)。Gao等人(2019)将这种现象称为表示退化问题。这个退化问题导致令牌嵌入之间的余弦相似度整体增加,使得模型很难学习令牌之间的语义关系。Demeter等人(2020)证明,**当计算输出层的logits时,令牌嵌入的范数信息占主导地位,而特征向量的角度信息被忽略。**由于嵌入空间的这种结构性弱点,范数较小的嵌入总是被分配较低的概率,这减少了模型生成的文本的多样性。嵌入空间的各向异性仍然是预训练的大型语言模型的一个问题,而具有改善的各向同性嵌入空间的语言模型在下游任务中表现良好(Bi´s等,2021;Rajaee和Pilehvar,2021)。
在神经语言生成模型中,logits(逻辑值)是指在输出层之前的模型产生的原始预测结果。它们通常是未经归一化的分数或概率,用于表示每个可能的输出类别的得分。
对于文中提到的计算输出层logits时,可以理解为在模型生成的文本的每个位置 t t t上,通过计算特征向量 h t h_t ht与权重 w y t w_{y_t} wyt的点乘,加上偏置b,得到该位置上每个可能输出令牌 y t y_t yt的原始得分。这些原始得分经过softmax函数归一化后,才成为了输出层的概率分布,表示每个可能的输出令牌的概率。
"令牌嵌入的范数信息"指的是令牌嵌入向量的长度或大小。在向量空间中,向量的范数表示向量的大小或长度,通常使用L2范数(欧几里德范数)来计算。对于令牌嵌入向量,范数信息反映了该向量的大小或强度。
"特征向量的角度信息"指的是特征向量之间的夹角或方向性。在向量空间中,两个向量的角度表示了它们之间的相似度或差异程度。角度接近于0度意味着两个向量非常相似,而角度接近于90度意味着两个向量差异较大。
在论文中提到的特征向量的角度信息是指上下文特征向量(context feature vector)与生成文本中的某个位置的嵌入向量之间的夹角。这个角度信息可以用来衡量生成文本的每个位置与上下文的相似度或关联程度。论文指出,由于某些结构性缺陷,模型在计算logits时忽略了特征向量的角度信息,导致模型在生成文本时缺乏多样性。
尽管该问题在几项研究中进行了理论分析,现有方法都是基于问题导致的观察现象。为了减轻问题导致的现象,引入了嵌入向量的后处理方法(Mu和Viswanath,2018;Bi´s等,2021)或关于这些现象的正则化项(Gao等,2019;Wang等,2019;Wang等,2020;Zhang等,2020)。这些方法都应用于所有的令牌嵌入,因此对于语义关系训练良好的嵌入存在过度正则化的问题。此外,基于令牌嵌入的训练动态的方法在处理退化问题方面仍需进一步研究。
嵌入空间中的频率偏差是另一个问题。Ott等人(2018)对神经机器翻译中罕见令牌的低估进行了全面的研究。Gong等人(2018)观察到语言模型中的嵌入偏向于频率,并提出了对抗训练方案来解决这个问题。
"嵌入空间中的频率偏差"指的是在令牌嵌入空间中,**令牌的表示受到它们在训练数据中出现频率的影响,导致嵌入空间中的令牌分布不均衡。**具体而言,出现频率较高的令牌在嵌入空间中可能具有更大的范数(向量大小),而出现频率较低的令牌则可能具有较小的范数。这种现象使得模型在生成文本时更倾向于选择频率较高的令牌,导致生成结果中频率高的令牌更常见。
这种嵌入空间中的频率偏差可能会影响生成文本的多样性和平衡性。频率较低的令牌可能会在生成过程中被忽略或低概率选择,从而导致生成文本的质量下降或出现重复和偏向常见令牌的现象。
为了解决嵌入空间中的频率偏差问题,研究人员提出了各种方法,如采用对抗性训练机制、引入额外的平衡约束或优化目标等,以平衡各个令牌在生成过程中的重要性和概率分布,从而提高生成文本的多样性和质量。
3 实证研究:由低频token引导的Token Embedding训练动态
3.1 Embedding初始训练动态
为了分析令牌嵌入的训练过程,我们从头开始训练了一个Transformer语言模型,使用WikiText-103数据集。整个词汇表的令牌被分为三组:频繁、中等和罕见。根据在训练语料库中的出现频率,我们将30%的令牌分配给频繁组,50%的令牌分配给中等组,20%的令牌分配给罕见组。我们通过将嵌入投影到2D空间来可视化这些组的初始训练动态,使用奇异值分解(SVD)进行投影。如图1所示,罕见组首先退化,从整个嵌入分布中出现。随后,其他组也开始退化,跟随罕见组的退化。基于这一观察,我们假设罕见令牌嵌入的退化导致了非罕见令牌嵌入的退化。

图1:在WikiText-103上训练的语言模型的标记嵌入的可视化。红色、绿色和蓝色的点代表罕见、中等和频繁的群体。(a)、(b)、©、(d)对每个训练步骤的可视化。
3.2 低频Token退化非低频Token
由于Transformer(Vaswani等,2017)是当前语言模型的代表,我们采用6层Transformer解码器模型结构进行对嵌入向量训练动态的实证研究。该模型在使用WikiText-103数据集(Merity等,2018)的语言建模任务中进行训练。有关模型和训练超参数配置的实验细节可以在附录B中找到。为了验证前一小节的假设,我们在训练过程中将稀有群组令牌嵌入冻结在初始状态,并将其与基准模型进行比较,其中所有嵌入都是使用负对数似然损失进行训练。此外,我们训练不同设置相对于冻结步骤的模型,并检查稀有令牌嵌入退化是否取决于何时开始训练稀有嵌入。
模型的性能通过两种方式进行评估;令牌嵌入的似然性和各向同性。困惑度(Bengio等,2000)被采用来评估模型似然性的性能。为了衡量令牌嵌入分布的各向同性,我们采用Arora等人(2016)中定义的分区函数
Z
(
a
)
=
∑
i
=
1
N
e
x
p
(
w
i
a
T
)
Z(a)=\sum^N_{i=1}exp(w_ia^T)
Z(a)=∑i=1Nexp(wiaT),其中
w
i
w_i
wi表示令牌
v
i
v_i
vi的嵌入向量,a表示一个单位向量。Arora等人(2016)中的引理2.1证明了如果嵌入向量是各向同性的,那么Z(a)是近似恒定的。基于这个属性,我们使用定义如下的
I
(
W
)
I(W)
I(W)来衡量嵌入矩阵W的各向同性。
I
(
W
)
=
m
i
n
a
∈
X
Z
(
a
)
m
a
x
a
∈
X
Z
(
a
)
(
3
)
I(W)=\frac{min_{a\in X}Z(a)}{max_{a\in X}Z(a)} (3)
I(W)=maxa∈XZ(a)mina∈XZ(a)(3)
其中
I
(
W
)
∈
[
0
,
1
]
I(W) ∈ [0, 1]
I(W)∈[0,1],
X
X
X表示
W
T
W
W^TW
WTW的特征向量集合(Mu和Viswanath,2018;Wang等,2020;Bi´s等,2021)。此外,我们测量稀有群组令牌嵌入与频繁群组令牌嵌入之间的相关性,以验证频繁群组的退化是否遵循稀有群组的退化。我们计算稀有群组嵌入和频繁群组嵌入之间的平均余弦相似度来衡量相关性。
表1显示了基准模型和冻结稀有令牌模型的比较。我们将基准模型表示为"MLE",将冻结方法表示为"Freeze"。令人惊讶的是,仅仅不训练稀有令牌嵌入,就使得频繁群组令牌的困惑度和整体I(W)得到了改善。图2说明了频繁和稀有令牌嵌入的I(W)的变化,包括不同冻结步骤设置下频繁和稀有令牌嵌入之间的相似度。每当稀有令牌嵌入开始训练时,它们的I(W)急剧下降,随后是频繁嵌入的I(W)下降和频繁嵌入与稀有嵌入之间相似度的增加。通过本小节的分析,我们证明整个退化问题可以通过仅在整个训练过程中处理稀有嵌入来解决。

表1:每个令牌组的复杂性和I (W)。PPL越低更好,I (W)越高更好。
PPL是指Perplexity(困惑度),它是一种用于评估语言模型性能的指标。在自然语言处理领域,语言模型的目标是根据给定的上下文,预测下一个词或句子的概率分布。困惑度是对语言模型的预测能力的度量,它衡量了模型在给定数据集上的预测效果。
困惑度的计算基于交叉熵(Cross Entropy),它衡量了模型的预测分布与实际分布之间的差异。困惑度是交叉熵的指数函数,通常用于表示模型对给定数据集中的样本的平均不确定性或混乱程度。较低的困惑度表示模型能够更好地对给定的上下文进行预测,因此具有更好的语言建模性能。

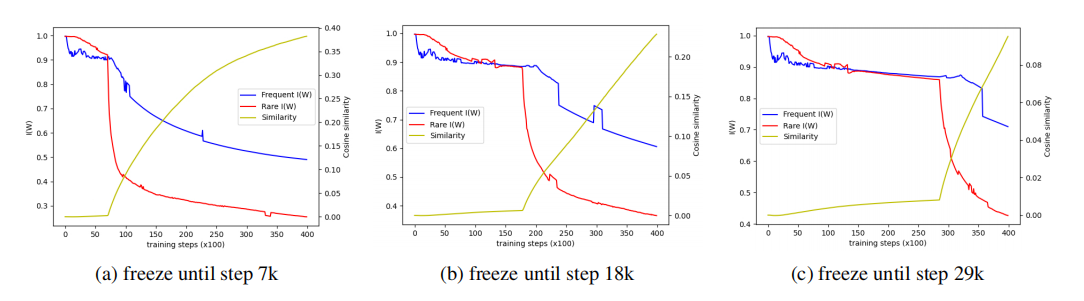
图2:在冻结罕见令牌的训练直到特定的训练步骤时,罕见组和频繁组的I (W)图和罕见嵌入和频繁嵌入之间的平均余弦相似度。
3.3 寻找退化问题的主要原因:从梯度开始
对于来自训练样本的T个上下文特征向量 h i ( i ∈ [ 1 , T ] ) h_i(i ∈ [1, T]) hi(i∈[1,T]),稀有令牌嵌入 w r w_r wr的负对数似然损失梯度计算如下。

部分a的目标是将 w r w_r wr与目标令牌为 v r v_r vr的特征向量拉近。这是因为在训练的过程中,我们期望模型能够更好地预测或者识别稀有令牌。 h i h_i hi是上下文特征向量, y i y_i yi是对应的目标令牌,如果 y i = v r y_i=v_r yi=vr,那么我们就希望在给定 h i h_i hi的条件下,模型能够输出 r r r的概率 p r ∣ i p_{r|i} pr∣i更高。也就是说,模型在看到上下文 h i h_i hi的情况下,更可能预测出目标令牌是 v r v_r vr。因此, w r w_r wr应该更接近于 h i h_i hi,即对 w r w_r wr的梯度是正的,代表着 w r w_r wr应该向着 h i h_i hi的方向更新。所以,部分a的梯度是 ∑ y i = v r ( p r ∣ i ) h i \sum_{y_i=v_r}(p_{r|i})h_i ∑yi=vr(pr∣i)hi。
这是一个类似于“吸引力”的概念,即使得模型能够更好地预测出稀有的令牌。在许多NLP任务中,尤其是在处理稀有令牌的时候,这是一个非常重要的步骤,因为稀有令牌往往带有大量的信息,但是由于它们的出现频率较低,如果不采取特别的策略,模型很可能会忽略这些令牌,从而影响最终的性能。
部分b的目标是将 w r w_r wr与目标令牌不是稀有令牌的特征向量分开。这是因为如果目标令牌 y j y_j yj不属于稀有令牌词汇组 V r V_r Vr,那么我们希望在给定特征向量 h j h_j hj的条件下,模型输出 r r r的概率 p r ∣ j p_{r|j} pr∣j更低。也就是说,模型在看到上下文 h j h_j hj的情况下,更不可能预测出目标令牌是 v r v_r vr。因此, w r w_r wr应该更远离 h j h_j hj,即对 w r w_r wr的梯度是负的,代表着 w r w_r wr应该向着远离 h j h_j hj的方向更新。因此,部分b的梯度是 ∑ y j ∉ V r p r ∣ j h j \sum_{y_j\notin V_r}p_{r|j}h_j ∑yj∈/Vrpr∣jhj。
部分c的目标是将 w r w_r wr与目标令牌是稀有令牌的特征向量分开。这可能看起来有些不直观,因为我们在部分a中试图让 w r w_r wr靠近目标令牌是 v r v_r vr的特征向量。然而,这个步骤是为了防止模型过于倾向于预测稀有令牌,因为过度的倾向可能会导致模型在面对非稀有令牌时的预测性能下降。通过将 w r w_r wr与目标令牌是稀有令牌的特征向量分开,我们可以平衡模型对于稀有令牌和非稀有令牌的处理能力。因此,部分c的梯度是 ∑ y k ∈ V r p r ∣ k h k \sum_{y_k\in V_r}p_{r|k}h_k ∑yk∈Vrpr∣khk。
其中 y i y_i yi表示 h i h_i hi的目标令牌, V r V_r Vr是稀有令牌词汇组, p r ∣ i p_{r|i} pr∣i表示给定 h i h_i hi的条件概率,取出token为r的概率值,即 [ s o f t m a x ( h i W T ) ] r [softmax(h_iW^T)]_r [softmax(hiWT)]r。我们将 w r w_r wr的梯度分为3个部分进行公式(4)中的计算。**部分(a)将 w r w_r wr与目标令牌为 v r v_r vr的特征向量拉近。部分(b)将 w r w_r wr与目标令牌不是稀有令牌的特征向量分开。部分(c)将 w r w_r wr与目标令牌是稀有令牌的特征向量分开。**作为前一小节分析的延伸,我们在训练过程中使用不同的设置来冻结梯度的这些部分,以确定退化问题的主要原因。换句话说,根据不同的设置,在训练阶段将不用于嵌入训练的特定梯度部分从计算图中分离出来。这可以通过Pytorch的detach()函数(Paszke等,2019)轻松实现。除了要冻结的部分外,所有模型和训练配置与前面的部分相同。
表2呈现了本小节实验的结果。我们使用三种设置来冻结稀有令牌的梯度部分。由于部分 (a)是训练令牌嵌入与目标对齐所必需的关键组成部分,所有设置都激活了部分(a)。我们注意到,当激活部分(b)(仅冻结部分(c))时,I(W)下降,稀有令牌的PPL相对于冻结部分(b)时增加了近10倍。因为激活部分(c)对于PPL和I(W)没有负面影响,我们得出结论,**公式(4)中的部分(b)是退化问题的根本原因。**通过本节的分析,我们证明通过主要处理将稀有令牌嵌入与非稀有特征向量分开的梯度部分,可以在很大程度上解决退化问题。

表2:梯度部分冻结实验中各标记组的复杂性和I (W)。
4 方法
4.1 动态低频Token组
为了处理前一节中研究的稀有令牌嵌入的特定梯度部分,我们需要正确地对稀有令牌进行分组。一种简单的方法是根据训练语料库中的出现频率对稀有令牌进行分组,如前一节所述。然而,这种静态分组方法不够优化,因为模型通常是通过小批量训练进行训练的。在最近的批次样本中,出现频率较低的稀有令牌的组合在小批量训练中是可变的。因此,有必要根据最近批次样本中的令牌出现情况动态地对稀有令牌进行分组。
为了考虑最近批次样本中的令牌出现情况,我们引入令牌计数器内存,用于记忆在前K个训练步骤中每个令牌出现的次数。对于K个内存, [ m 1 , . . . , m K ] [m_1,...,m_K] [m1,...,mK],其中$m_t ∈ R^N 表示在大小为 N 的词汇表中每个令牌在第 t 个先前训练步骤中的出现次数。内存在初始阶段被设置为零向量。在每个训练步骤中,令牌出现情况 表示在大小为N的词汇表中每个令牌在第t个先前训练步骤中的出现次数。内存在初始阶段被设置为零向量。在每个训练步骤中,令牌出现情况 表示在大小为N的词汇表中每个令牌在第t个先前训练步骤中的出现次数。内存在初始阶段被设置为零向量。在每个训练步骤中,令牌出现情况a ∈ R^N 被计算为所有 K 个内存的求和: 被计算为所有K个内存的求和: 被计算为所有K个内存的求和:a = ∑^K_{t=1} m_t 。基于 a ,我们根据以下方法确定是否将令牌 。基于a,我们根据以下方法确定是否将令牌 。基于a,我们根据以下方法确定是否将令牌v_i 归入稀有令牌组 归入稀有令牌组 归入稀有令牌组V_r$。
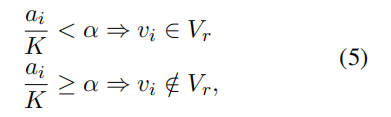
其中 a i a_i ai是a的第i个分量, α α α是我们方法中的超参数,用于控制整个词汇表中稀有令牌的比例。在本研究中,我们将K设置为训练阶段一个时期(epoch)中的迭代步骤数。
4.2 对于低频Token的自适应梯度门控策略
在每个训练步骤中动态分组低频token后,我们需要处理稀有令牌嵌入的特定梯度部分,以解决所有嵌入的退化问题。为了仅控制稀有令牌嵌入的梯度,我们引入了一个梯度门控方法用于参数x。我们定义 x ˜ x^˜ x˜为一个张量,其值与x相同,但与当前训练图分离。这意味着 x ˜ x^˜ x˜被视为常数,因此,关于 x ˜ x^˜ x˜的梯度不存在。实际上,可以使用PyTorch的detach()函数(Paszke等,2019)从x轻松获得 x ˜ x^˜ x˜。有了 x ˜ x^˜ x˜,我们可以按以下方式对x的梯度进行门控。

其中, x g a t e d x_{gated} xgated是一个新的参数,其值与x相同,g ∈ [0, 1] 是一个门控张量。当 x g a t e d x_{gated} xgated作为输入传递给函数f(·)时,x的梯度由g门控制。
正如我们在第3节中所描述的,公式4的部分(b)应该是主要要处理以解决退化问题。为了处理公式4的部分(b),给定第i个位置的上下文特征向量hi,我们引入一个门控向量 g 1 ∈ R N g_1 ∈ R^N g1∈RN,如下所示。
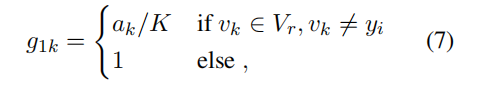
其中, g 1 k g_{1k} g1k表示 g 1 g1 g1的第k个分量。g1控制稀有令牌嵌入与目标与其不同的非稀有特征向量之间的远离程度。此外, g 1 g1 g1的每个分量都基于每个稀有令牌的稀有程度 a k a_k ak计算,因此,对于公式4的部分(b),梯度门控对于每个稀有令牌都是自适应的。
尽管公式4的部分©会将嵌入向量从目标为其他稀有令牌的特征向量中推离,但在第3节中,我们并未将其视为退化问题的原因。然而,对于某些情况,当稀有令牌使其他稀有令牌退化时,部分©也会导致退化问题的出现。为了解决这个问题,在本文中我们将稀有令牌组中的多个稀有程度近似为两个级别:‘较不常见’和‘非常不常见’。我们根据整个稀有令牌的平均出现次数定义了这两个稀有程度水平:如果令牌出现次数 a k a_k ak小于 a r a_r ar的均值,其中 r ∈ V r r ∈ V_r r∈Vr,那么对应的令牌就是非常不常见的稀有令牌。对于非常不常见的稀有令牌嵌入,公式4的部分©会将它们从目标为较不常见的稀有令牌的特征向量中推离,而这些较不常见的稀有令牌相对于它们来说相对频繁。这意味着部分©在上述情况下起到了部分(b)的作用,成为了退化问题的原因。因此,我们需要处理非常不常见的稀有令牌的公式4的部分©。为了处理非常不常见的稀有令牌嵌入的公式4的部分©,我们引入了另一个门控向量 g 2 ∈ R N g2 ∈ R^N g2∈RN,如下所示。

其中, g 2 k g_{2k} g2k是 g 2 g_2 g2的第k个分量, a r ¯ a^¯_r ar¯是 r ∈ V r r ∈ V_r r∈Vr中 a r a_r ar的均值。 g 2 g_2 g2控制非常不常见的稀有令牌嵌入与目标与其不同的较不常见特征向量之间的远离程度。此外, g 2 g_2 g2的每个分量都基于每个非常不常见稀有令牌的稀有程度 a k a_k ak计算,因此,对于公式4的部分©,梯度门控对于每个非常不常见稀有令牌都是自适应的。
为了计算 h i h_i hi的损失,我们计算三个logits, z i 0 . z i 1 和 z i 2 z_i^0.z_i^1和z_i^2 zi0.zi1和zi2,如下:
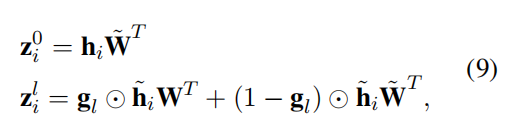
其中 W W W表示一个Embedding矩阵, l = 1 , 2 l=1,2 l=1,2。因为我们的方法仅处理Embedding的梯度,我们计算关于 h i h_i hi的梯度 z i 0 z^0_i zi0,该梯度不需要门控,最后,第i个位置的负对数似然损失 L i L_i Li计算如下。

其中 p I ( y i ) ∣ i m = [ s o f t m a x ( z i m ) ] I ( y i ) p_{I(y_i)|i}^m=[softmax(z_i^m)]_{I(y_i)} pI(yi)∣im=[softmax(zim)]I(yi), m = 0 , 1 , 2 m=0,1,2 m=0,1,2, 1 ( ⋅ ) 1(·) 1(⋅)表示指示函数。关于稀有令牌嵌入的梯度 ∇ w r L i ∇_{w_r}L_i ∇wrLi 的推导详见附录A。
注:空心1表示一个集合中的一个特定元素。
5 实验
我们在多个任务上评估了我们的方法,包括语言建模、词语相似度和机器翻译。在语言建模任务中,我们专注于验证生成文本的多样性。我们在词语相似度任务中测试了标记之间语义关系的学习能力。最后,我们在机器翻译任务中评估生成文本的质量。在下面的所有实验结果中,我们采用了最先进的模型架构作为基准线,以充分展示我们方法的有效性。附录B中提供了实验的每个细节,如模型超参数和训练配置,以确保可复现性。
5.1 语言模型
实验设置
我们使用了WikiText-103数据集进行实验,这是一个具有大约1.03亿个单词和26万个词汇量的语言建模任务的显着大的数据集(Merity等人,2018)。数据集中的文本是基于字节对编码(Sennrich等人,2016)进行预处理的。我们采用GPT-2中等规模的架构(Radford等人,2019)作为基准模型,该模型由24个Transformer解码器层组成。由于我们的方法涉及学习标记嵌入,我们从头开始训练模型,最多进行5万次迭代,并根据验证集的困惑度进行评估。
对于超参数搜索,我们在语言建模任务中选择α ∈ {0.01, 0.02, 0.03, 0.04, 0.05}作为AGG方法的参数。AGG的超参数敏感性在附录D中给出。我们使用三个定量指标来评估我们的方法:困惑度(Perplexity)、Uniq和I(W)。困惑度与生成文本的可能性相关,它量化对下一个标记的预测困难程度。Uniq(Welleck等人,2020)量化了唯一下一个标记预测的数量,衡量了标记的多样性。如第3节所述,I(W)衡量了标记嵌入空间的各向同性。
结果
我们在表3中呈现了我们在测试集上的结果。我们将基准方法表示为’MLE’,将我们的方法表示为’AGG’。我们为第3节中定义的每个标记组衡量了困惑度和Uniq。如表3所示,AGG在中等和罕见的标记组上改进了整体指标,同时保持了常见标记组的性能。这表明我们的方法不仅改善了罕见标记嵌入的质量,还改善了非罕见标记嵌入的质量。特别是对于罕见标记组,困惑度得分显著降低,唯一预测的数量超过了人类分布。所有标记嵌入的I(W)都增加了超过基准线的2倍。附录C中列出了每个频率组嵌入的I(W)的实验结果。表5展示了MLE基准和AGG生成的文本示例。附录F中还提供了其他生成文本的示例。

表3:在WikiText-103语言建模任务中,每个标记组比较MLE基线和AGG的实验结果。
Uniq是一种用于衡量生成文本多样性的指标。它是由Welleck等人于2020年提出的,用于评估生成模型生成的下一个标记(token)的独特性。Uniq的值表示生成文本中不同预测标记的数量。
在生成文本任务中,一个理想的模型应该能够产生多样性的输出,而不仅仅是重复相同的标记。Uniq指标通过计算生成文本中唯一预测标记的数量来量化这种多样性。较高的Uniq值表示生成的文本更加多样化,而较低的Uniq值可能意味着生成的文本较为单一或缺乏多样性。

表5:在WiKi-103测试集上生成的文本和每个文本的uniq令牌。以50个BPE令牌作为前缀,模型将生成100个下一个BPE令牌的延续。
兼容性
神经文本退化问题是神经文本生成模型中的另一个问题,即模型生成的文本很少与人类的词分布相匹配。现有的解决此问题的方法侧重于通过在原始负对数似然损失上添加辅助损失来增加生成文本的多样性(Welleck等人,2020)。尽管Welleck等人(2020)和AGG都试图解决有关多样性的相同问题,但AGG可以与现有的文本退化问题的方法兼容,因为AGG不会改变MLE训练中损失函数的形式。表4呈现了关于不适性训练(Welleck等人,2020)和AGG融合的实验结果。我们将不适性训练表示为UL。从表4中可以看出,当UL和AGG融合时,产生了超过各自增益的协同效应。这表明AGG与解决文本生成中其他问题的方法是兼容的。

表4:在WikiText-103语言建模任务中,比较UL和UL+AGG的实验结果。
不适性训练(Unlikelihood Training)是一种用于解决神经文本生成模型中文本退化问题的方法。在神经文本生成中,文本退化指的是生成的文本与人类语言的表达方式相比,缺乏自然度和多样性。
不适性训练的目标是通过训练模型来降低生成文本中不自然或低频的词序列的概率,从而提高生成文本的自然度和多样性。具体而言,该方法引入了一个额外的损失函数,该损失函数衡量了生成文本中低频或不自然词序列的概率。通过将这个不适性损失与原始的负对数似然损失结合起来,模型可以被迫更好地匹配人类的词分布,避免生成过于平凡或不连贯的文本。
不适性训练是为了解决神经文本生成中的文本退化问题而提出的一种方法,与AGG方法相比,它们都致力于提高生成文本的多样性。在上述论文中,研究人员尝试将不适性训练和AGG方法结合起来,以期产生更好的效果,并证明了AGG方法在解决文本生成中其他问题时的兼容性。
5.2 词语相似度
实验设置
我们使用四个词语相似性数据集(MEN、WS353、RG65和RW)评估AGG和基准模型之间的标记语义关系(Bruni等人,2014;Agirre等人,2009;Rubenstein和Goodenough,1965;Luong等人,2013)。我们通过Spearman等级相关系数来测试给定两个单词在嵌入空间中的相似性是否与真实情况一致。我们采用余弦距离来计算嵌入之间的相似性。对于词语相似性任务,我们使用在语言建模任务中使用WikiText-103数据集训练的相同模型。
结果
表6呈现了词语相似性任务评估的结果。从该表中可以观察到,我们的方法在整体数据集上优于基准模型。尽管AGG只处理罕见标记的训练,但所有标记之间的语义关系也得到了良好的学习。有关标记之间语义对齐的定性研究见附录E。

表6:模型在四个单词相似度数据集上的性能(斯皮尔曼的γ×100)。
5.3 机器翻译
实验设置
我们使用了标准WMT 2014数据集,其中包含了450万个英语到德语的句对。根据字节对编码(Sennrich等人,2016),源语言和目标语言的句子被编码为37,000个共享标记。我们采用Transformer的两个版本(Vaswani等人,2017)作为应用我们方法的基准模型:base和big。模型配置与Vaswani等人(2017)的提议相同。为了评估生成文本的质量,我们使用BLEU分数(Papineni等人,2002),这是机器翻译任务的标准度量指标。
结果
表7展示了我们的方法和其他方法在BLEU分数方面的比较。对于base和big基准模型,在机器翻译任务上,我们的方法分别实现了1.4和1.41的BLEU分数改进。此外,我们的方法在处理表示退化问题方面优于先前所有其他报告相同任务的工作的BLEU分数。这些结果证明了AGG在生成文本质量方面的有效性。虽然其他解决退化问题的方法针对所有标记嵌入,而AGG的目标——罕见标记嵌入是基于对标记嵌入训练动态的分析进行优化的。由于这种差异,我们的方法可以避免对频繁标记嵌入的过度正则化问题,这是与其他方法相比AGG的主要优势。附录E提供了关于源语言和目标语言之间标记的跨语言语义对齐的定性研究。

表7:不同方法的BLEU评分比较。
6 AGG的分析
6.1 消融实验
在我们的方法AGG中,我们引入了两个门向量 g 1 g_1 g1和 g 2 g_2 g2来处理罕见和非常罕见标记嵌入的梯度。我们对这些门向量进行了实验。表8呈现了与MLE和AGG进行对比的消融研究的结果。当从AGG中排除g1(标记为’no g1’)时,Uniq和I(W)显著降低,因为g1是梯度门控的关键组件。当从AGG中排除g2(标记为’no g2’)时,Uniq和I(W)略微降低。因此,我们注意到g2对于非常罕见标记嵌入的梯度门控是重要的。
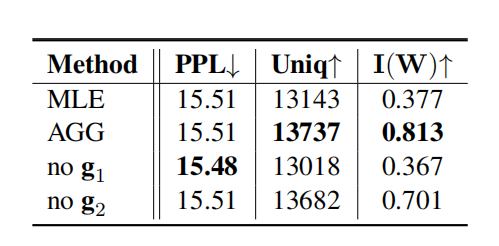
表8:AGG门控机制的消融研究。
此外,我们还对AGG的罕见标记分组方法进行了分析。图4展示了在使用WikiText-103数据集训练模型的初始1000个训练步骤期间罕见标记组的大小。如图所示,在初始训练阶段,罕见标记组的大小波动较大。我们期望这种分组方法能够确定当前训练步骤的最佳罕见标记组。表9呈现了关于动态分组的消融研究结果。为了排除AGG中的动态分组,我们在1个时期后固定了罕见标记组。对于这种静态分组的AGG方法,下一个标记的多样性(Uniq)和标记嵌入空间的各向同性(I(W))性能较动态分组的AGG差。

图4:在使用WikiText-103数据集进行训练的初始1k步中,罕见标记组的大小。
“Normalized singular value”(标准化奇异值)是指在矩阵奇异值分解(Singular Value Decomposition,SVD)中,将奇异值归一化处理后得到的值。在SVD中,一个矩阵可以表示为三个矩阵的乘积:U、S、V^T,其中U和V是正交矩阵,而S是一个对角矩阵,对角线上的元素即为奇异值。

表9:关于AGG动态分组的消融术研究。
6.2 可视化
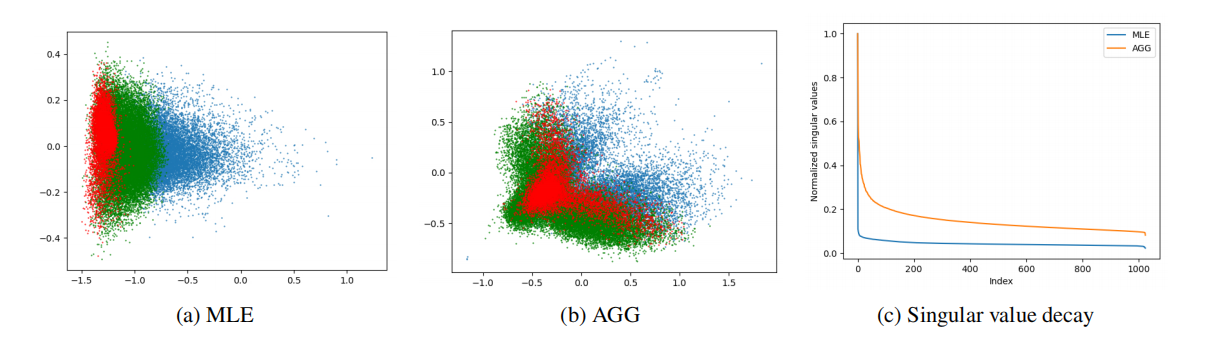
图3: (a),(b) Token嵌入可视化的基线模型和WikiText-103语言建模任务上的AGG。红、绿、蓝点代表罕见、中、频繁的组;©MLE和AGG的归一化奇异值。
图3(a)和(b)展示了基准MLE和我们方法的嵌入空间的可视化。从图中可以看出,应用AGG方法恢复了标记嵌入空间的各向同性。此外,我们观察到应用AGG时,每个标记组所占据的区域并不是不相交的。对于基准模型,罕见组和频繁组所占据的区域是不相交的,这被称为嵌入的频率偏差问题(Gong等人,2018)。通过对嵌入空间可视化的分析,我们注意到操纵罕见标记嵌入的训练可以缓解频率偏差问题。图3(c)展示了MLE和AGG的嵌入矩阵的标准化奇异值的绘图。AGG的奇异值呈现出缓慢衰减的特点,表明嵌入空间呈现出各向同性的分布。
7 总结
在本研究中,我们分析了与学习嵌入的表示退化问题相关的标记嵌入的训练动态,重点关注罕见标记。基于这些分析,我们提出了一种自适应梯度门控方法,通过仅处理罕见标记嵌入的训练来解决这个问题。在文本生成的各个任务中进行的实验和定性研究证明了我们方法的有效性。除了我们研究中应用的对罕见标记稀有性的两级近似之外,未来的工作可以考虑解决多级稀有性的问题,这是一个有趣的研究方向。








![浑元太极马老师和小薇-UMLChina建模知识竞赛第4赛季第7轮[更新]](https://img-blog.csdnimg.cn/img_convert/0f27fb17e3b58db862752129a20e347d.png)


