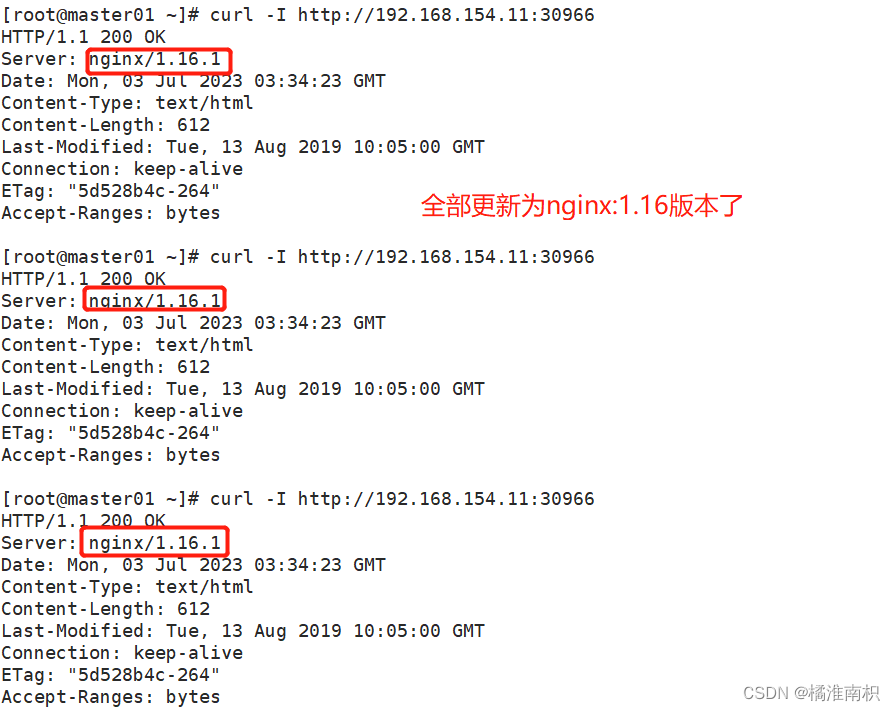
“ 太长不看总结版:LLM大模型的本质在于计算某个词汇后面应该跟着哪些词汇的概率。当问题给定了特定的限定范围后,它能够找到一条相对明确的计算路径,从一系列概率分布中挑选出所需的答案。否则,它会根据最常见且最高概率的组合方式生成回答内容。”

01
—
缘起
在前面文章中:被卖到 2w 的 ChatGPT 提示词 Prompt 你确定不想要吗?
点燃创作灵感:Prompt 实践指南揭秘!让 ChatGPT 更智能的六种策略(上),我们曾提到,在向大模型提问时,告诉它扮演一个领域专家的角色,它的回答会更有针对性。
但为什么会这样呢?为什么大模型本质上只是预测词汇出现的概率就能让它输出问题的答案呢?
为了寻找这个问题的答案,找到了一篇科普文章,详细解释了大模型的工作原理和它为何能够发挥作用。文章以简明的方式科普了大模型的工作原理,让我们一起来探索吧!
原文地址(英文)在这里,有兴趣的朋友可以看原文:
https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/
原文比较长,我把它将分为三部分逐次向大家科普,以下为翻译的内容,“我”为原作者,“注”为我的理解。
02
—
只需一次添加一个单词
ChatGPT 可以自动生成一些读起来就像人类书写的文本一样的东西,它是如何做到的呢?为什么它有效?
我在这里的目的是粗略地概述 ChatGPT 内部正在发生的事情,然后探索为什么它可以很好地生成我们认为有意义的文本。虽然会提到一些工程细节,但我不会深入探讨它们。(这里所说的本质同样适用于其他当前的“大型语言模型”[LLM] 和 ChatGPT。)
首先要解释的是,ChatGPT 从根本上一直试图做的是,对迄今为止所获得的任何文本进行“合理的延续”。
“合理”的意思是“在看过人类已经写在数十亿个网页上的内容之后,可能期望会继续写些什么内容,等等。”
假设我们有这么一句话:“人工智能最好的是它的能力(The best thing about AI is its ability to)”。想象一下,扫描数十亿页的人类书写文本(例如在网络上和数字化书籍中)并找到该文本的所有实例,然后统计这句话接着出现词汇的次数。
ChatGPT 有效地做了类似的事情,除了它不查看文字文本;它寻找某种意义上“意义匹配”的事物。最终的结果是,它生成了一个可能跟随的单词的排名列表,以及“概率”:

值得注意的是,当 ChatGPT 做类似写文章之类的事情时,它本质上只是一遍又一遍地询问“给定到目前为止的文本,下一个单词应该是什么?”,并且每次都添加一个单词。(更准确地说,它添加了一个“标记”,它可能只是单词的一部分,这就是为什么它有时可以“组成新单词”。)
在每一步它都会得到一个带有概率的单词列表。但它实际上应该选择哪一篇来添加到它正在写的文章(或其他内容)中呢?人们可能认为它应该是“排名最高”的单词(即被分配最高“概率”的单词)。
但这就是一点 voodoo (注:指某种奇怪,无法科学解释的现象)开始蔓延的地方。因为出于某种原因——也许有一天我们会对它有一个科学式的理解——如果我们总是选择排名最高的单词,我们通常会得到一个非常好的单词。 “平淡”的文章,似乎从来没有“表现出任何创造力”(甚至有时逐字重复)。但如果有时(随机)我们选择排名较低的单词,我们会得到一篇“更有趣”的文章。
(注:这也是为什么多数情况下,我们会觉得大语言模型回答问题的时候过于官方正式,风格有点像翻译腔,如果不用指定的提示词。)
事实上,这里存在随机性,这意味着如果我们多次使用相同的提示,我们每次都可能得到不同的文章。而且,为了与 voodoo 的思想保持一致,有一个特殊的所谓“温度(temperature)”参数,它决定了排名较低的单词的使用频率,对于论文生成,事实证明 0.8 的“温度”似乎是最好的。(值得强调的是,这里没有使用“理论”;这只是在实践中发现有效的数值。例如,“温度”的概念之所以存在,是因为碰巧使用了统计物理学中熟悉的指数分布,但不存在“物理”联系)
在这里,我是使用更简单的GPT-2 系统来解释大语言模型是怎么工作的。该系统具有一个很好的功能,即它足够小,可以在标准台式计算机上运行。因此,对于我展示的基本上所有内容,提供了 Wolfram 语言代码,您可以立即在计算机上运行它们。
例如,以下是如何获取上面的概率表。首先,我们必须检索底层的“语言模型”神经网络:
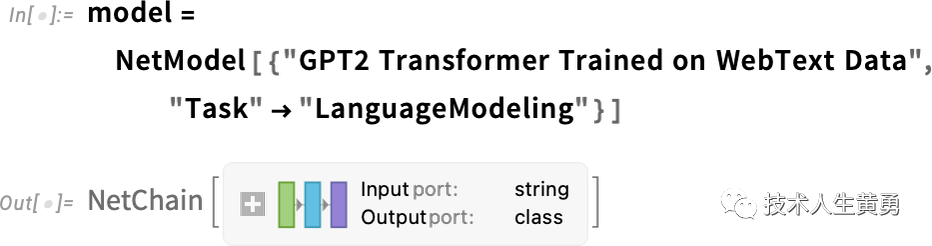
稍后,我们将深入研究这个神经网络,并讨论它是如何工作的。但目前我们可以将这个“网络模型”作为黑盒应用到我们的文本中,并根据模型所说的概率来询问前 5 个单词:

获取该结果并将其放入显式格式化的“数据集”中:

如果重复“应用模型”,会发生以下情况 - 在每一步添加具有最高概率的单词(在此代码中指定为模型的“决策”):
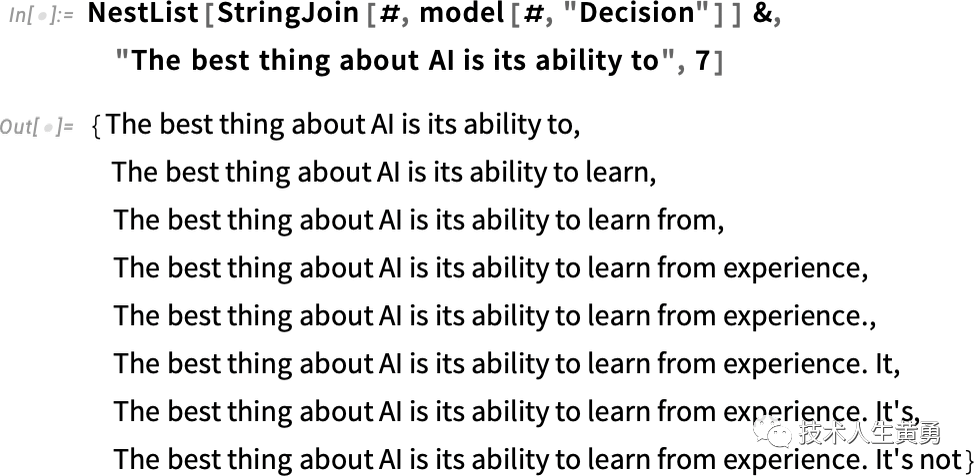
如果一个人持续更长时间会发生什么?在这种(“零温度”)情况下,结果很快就会变得相当混乱和重复:

但是,如果不是总是选择“顶部”单词,而是有时随机选择“非顶部”单词(“随机性”对应于“温度”0.8)呢?再次可以构建文本:

每次这样做时,都会做出不同的随机选择,并且文本也会不同 - 正如以下 5 个示例所示:

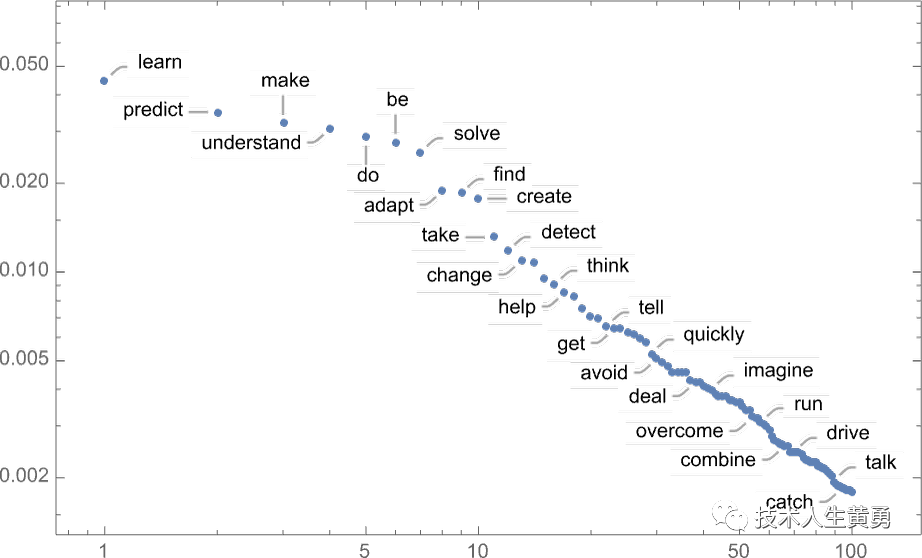
值得注意的是,即使在第一步,也有很多可能的“下一个单词”可供选择(温度为 0.8),尽管它们的概率下降得很快(这个对数图上的直线对应于n –1 “幂律”衰减,这是语言一般统计的特征):
那么如果这个句子持续继续下去会发生什么呢?这是一个随机的例子。它比开始单词(temperature=0)的情况要好,但仍然有点奇怪:

这是使用简单的 GPT-2 模型(2019 年起)完成的。使用更新、更大的 GPT-3 模型,结果会更好。这是使用相同“提示”生成的开始单词(temperature=0),但是还是有一点奇怪:

这是“temperature=0.8”下的随机示例:

03
—
概率从何而来?
ChatGPT 总是根据概率选择下一个单词,这些概率从何而来?
让我们从一个更简单的问题开始。让我们考虑一次生成一个字母(而不是单词)的英语文本。我们如何计算出每个字母的概率应该是多少?
(注:很多年前,有人就根据字母的出现的概率开发了一款用于检查拼写错误的软件,微软将其用于 Office 办公软件系列中,效果比之前用规则检查的方法好很多。)
我们能做的最简单的事情就是获取英文文本样本,并计算其中不同字母出现的频率。例如,这对维基百科关于“猫”的文章中的字母进行计数:

这对“狗”也有同样的作用:

结果相似,但不一样(“o”无疑在“dogs”文章中更常见,因为毕竟它出现在“dog”一词本身中)。尽管如此,如果我们采用足够大的英语文本样本,我们可以期望最终得到至少相当一致的结果:

如果我们只是生成具有这些概率的字母序列,我们会得到以下示例:

我们可以通过添加空格将其分解为“单词”,就好像它们是具有一定概率的字母一样:

我们可以通过强制“单词长度”的分布与英语中的一致来更好地制作“单词”:

我们在这里没有碰巧得到任何“实际的单词”,但结果看起来稍微好一些。然而,为了更进一步,我们需要做的不仅仅是随机挑选每个字母。例如,我们知道如果我们有一个“q”,那么下一个字母基本上必须是“u”。
这是字母本身的概率图:
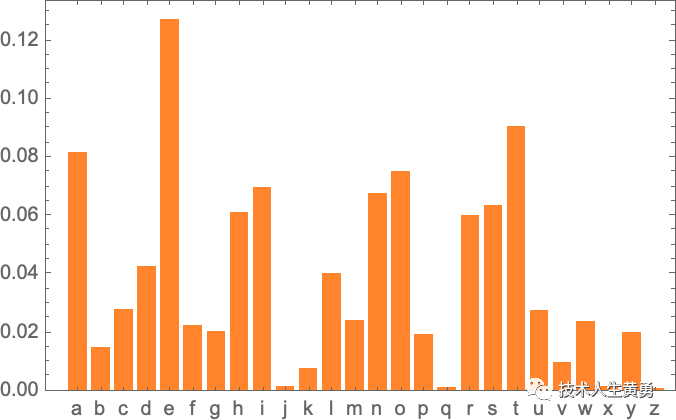
下面的图显示了典型英语文本中字母对(“2-grams”)的概率。可能的第一个字母显示在整个页面上,第二个字母显示在页面下方:
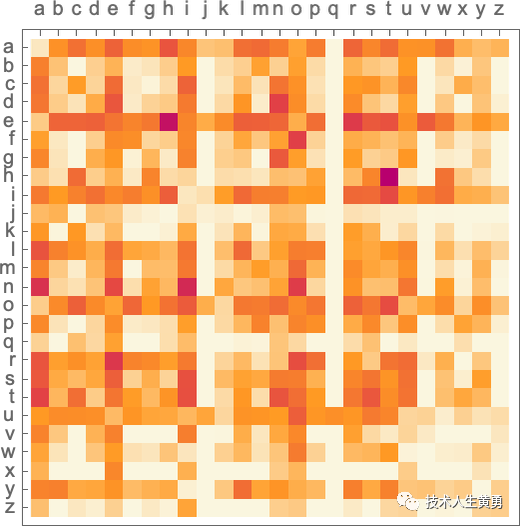
例如,我们在这里看到,除了“u”行之外,“q”列是空白的(零概率)。好的,现在我们不再一次生成一个字母的“单词”,而是使用这些“2-gram”概率一次查看两个字母来生成它们。这是结果的示例,其中恰好包含一些“实际单词”:
有了足够多的英文文本,我们不仅可以对单个字母或字母对(2-grams)的概率进行很好的估计,而且还可以对较长的字母序列进行估计。如果我们生成n元语法概率逐渐变长的“随机词”,我们会看到它们逐渐变得“更现实”:

但现在让我们假设(或多或少像 ChatGPT 一样)我们正在处理整个单词,而不是字母。英语中大约有 40,000 个合理常用的单词。通过查看大量的英语文本语料库(比如几百万本书,总共有几千亿个单词),我们可以估计每个单词的常见程度。使用它,我们可以开始生成“句子”,其中每个单词都是独立随机挑选的,其出现在语料库中的概率相同。这是我们得到的示例:

毫不奇怪,这是无稽之谈。那么我们怎样才能做得更好呢?就像字母一样,我们不仅可以开始考虑单个单词的概率,还可以考虑单词对或更长n元语法的概率。成对进行此操作,以下是我们得到的 5 个示例,所有情况都从单词“cat”开始:

它变得稍微“看起来更明智”了。我们可能会想象,如果我们能够使用足够长的n元语法,我们基本上会“得到一个 ChatGPT”——从某种意义上说,我们会得到一些东西,可以生成具有“正确的整体文章”的文章长度的单词序列。概率”。但问题是:目前还没有足够的英文文本来推断这些概率。
网络爬行中可能有几千亿个单词;数字化的书籍中可能还有数千亿字。但对于 40,000 个常见单词,即使可能的 2-gram 数量也已经是 16 亿个,而可能的 3-gram 数量则达到 60 万亿个。因此,即使从现有的文本中我们也无法估计所有这些的概率。当我们写到20个字的“论文片段”时,可能性的数量比宇宙中的粒子数量还多,所以从某种意义上说,它们永远不可能全部写下来。
所以,我们能做些什么?最重要的想法是建立一个模型,让我们能够估计序列出现的概率——即使我们从未在我们所查看的文本语料库中明确看到过这些序列。ChatGPT 的核心正是所谓的“大语言模型”(LLM),它的构建是为了很好地估计这些概率。
04
—
什么是模型?
假设想知道(正如伽利略在 1500 年代末所做的那样)从比萨斜塔每一层投下的炮弹需要多长时间才能落地。
可以在每种情况下进行测量并制作结果表格。或者可以做理论科学的本质:建立一个模型,给出某种计算答案的程序,而不仅仅是测量和记住每个案例。
假设我们有(有点理想化的)炮弹从不同楼层落下所需时间的数据:
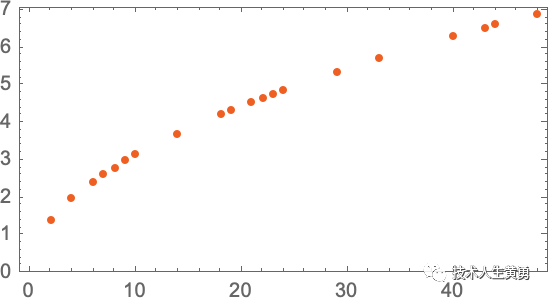
我们如何计算从没有明确数据的地板上掉下来需要多长时间?在这种特殊情况下,我们可以使用已知的物理定律来解决这个问题。但假设我们拥有的只是数据,而我们不知道管辖这些数据的基本法律是什么。然后我们可能会做出一个数学猜测,比如也许我们应该使用直线作为模型:
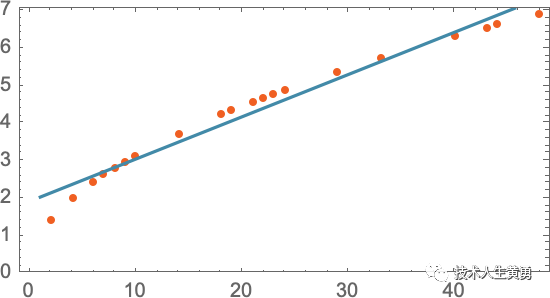
我们可以选择不同的直线。但这是平均最接近我们给出的数据的一个。从这条直线我们可以估算出任何楼层的跌落时间。
我们怎么知道在这里尝试使用直线?在某种程度上我们没有。这只是数学上简单的东西,我们已经习惯了这样一个事实:我们测量的大量数据结果与数学上简单的东西非常吻合。我们可以尝试一些数学上更复杂的东西——比如a + b x + c x 2——然后在这种情况下我们做得更好:
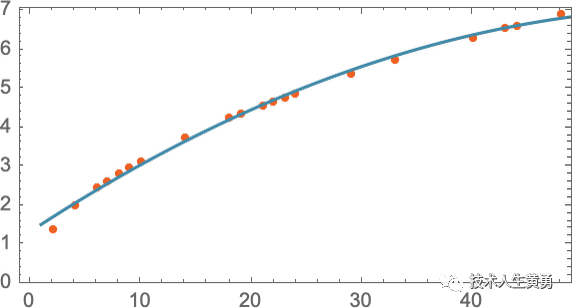
不过,事情也可能会变得很糟糕。就像这是我们可以用a + b / x + c sin( x )做的最好的事情:

永远不存在“无模型模型”。使用的任何模型都有一些特定的底层结构 - 然后是一组特定的“可以转动的旋钮”(即可以设置的参数)来适应实际的数据。就 ChatGPT 而言,使用了大量此类“旋钮”——实际上,有 1750 亿个。
但值得注意的是,ChatGPT 的底层结构——“仅仅”有那么多参数——足以建立一个模型,“足够好”地计算下一个单词的概率,从而为我们提供合理的论文长度的文本片段。
05
—
模仿人的模型
我们上面给出的例子涉及为数据建立一个模型,该模型本质上来自简单的物理学——几个世纪以来我们都知道“简单的数学适用”。
但对于 ChatGPT,我们必须建立一个由人脑产生的人类语言文本模型。对于类似的事情,我们(至少现在)还没有“简单数学”之类的东西。
那么它的模型会是什么样子呢?
在讨论语言之前,我们先讨论另一个模仿人的任务:识别图像。作为一个简单的例子,让我们考虑数字图像(一个经典的机器学习示例):
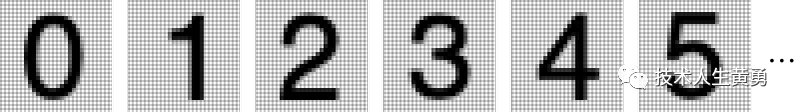
我们为每个数字建立一堆样本图像:

然后,为了查明我们作为输入给出的图像是否对应于特定数字,我们可以与我们拥有的样本进行显式的逐像素比较。但作为人类,我们似乎确实做得更好——因为我们仍然可以识别数字,即使它们是手写的,并且有各种修改和扭曲:
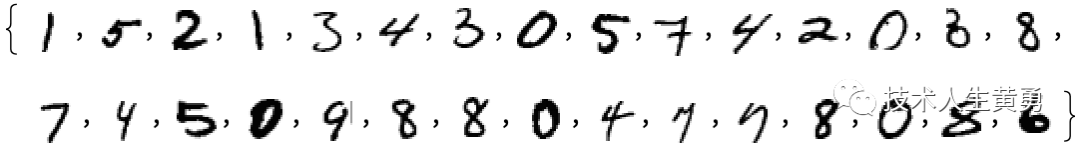
当我们为上面的数值数据创建模型时,我们能够获取给定的数值x ,然后计算特定的a和b的a + bx。因此,如果我们将这里每个像素的灰度值视为某个变量x i,是否存在所有这些变量的某个函数——在评估时——告诉我们图像的数字是多少?事实证明,构造这样的函数是可能的。毫不奇怪,但它并不是特别简单。一个典型的例子可能涉及五十万次数学运算。
但最终的结果是,如果我们将图像的像素值集合输入到这个函数中,就会得到一个数字,指定我们拥有图像的哪个数字。稍后,我们将讨论如何构造这样的函数以及神经网络的思想。但现在让我们将该函数视为黑匣子,我们在其中输入手写数字的图像(作为像素值数组),然后得到这些对应的数字:
但这里到底发生了什么?假设我们逐渐模糊一个数字。有一段时间我们的函数仍然“识别”它,这里是“2”。但很快它就“失去了它”,并开始给出“错误”的结果:

但为什么我们说这是“错误”的结果呢?在这种情况下,我们知道我们通过模糊“2”获得了所有图像。但如果我们的目标是建立一个人类在识别图像方面可以做什么的模型,那么真正要问的问题是,如果人类看到其中一张模糊图像而不知道它来自哪里,他会做什么。
如果我们从函数中得到的结果通常与人类所说的一致,那么我们就有了一个“好模型”。重要的科学事实是,对于这样的图像识别任务,我们现在基本上知道如何构建执行此操作的函数。
我们可以“从数学上证明”它们有效吗?嗯,不能。
因为要做到这一点,我们必须对人类所做的事情有一个数学理论。拍摄“2”图像并更改一些像素。我们可能会想象,只有几个像素“不合适”,我们仍然应该将图像视为“2”。但这应该走多远呢?这是人类视觉感知的问题。是的,对于蜜蜂或章鱼来说,答案无疑会有所不同,对于假定的外星人来说,答案也可能完全不同。
(注:当我明白大模型的统计学原理后,也就明白为什么 ChatGPT 的token 是连问题带回答一起计算的字数。因为大模型并不知道答案是什么,它是把问题的词汇后面最有可能出现的词汇呈现出来。)
下期预告:ChatGPT 真正发挥作用的是什么?
学习AI过程中,寻找过不少资料来学习人工智能是怎么工作的,也包括机器学习等范畴的内容,觉得这篇写得深入浅出,我能看明白,所以在这里推荐给朋友们。
人工智能的发展经历了多个技术路线的演进,过去的发展技术路线如下:
符号推理(Symbolic Reasoning):在上世纪50年代和60年代,人工智能的早期研究主要集中在符号推理上。这种方法使用逻辑规则和符号表示来模拟人类的推理过程。
专家系统(Expert Systems):在上世纪70年代和80年代,专家系统成为人工智能的主流技术。专家系统利用专家的知识和规则来解决特定领域的问题。
机器学习(Machine Learning):在上世纪80年代末和90年代,机器学习开始引起广泛关注。机器学习通过从数据中学习模式和规律来进行预测和决策。包括监督学习、无监督学习和强化学习等技术。
神经网络(Neural Networks):神经网络是一种受到人脑神经元结构启发的模型,它能够通过大规模的训练数据进行模式识别和分类。然而,在上世纪90年代,神经网络的发展进入了低谷。
深度学习(Deep Learning):深度学习是指使用深层神经网络进行机器学习的技术。通过引入更深的神经网络结构和更强大的计算资源,深度学习在近年来取得了巨大的突破,并在图像识别、语音识别和自然语言处理等领域取得了显著成果。
除了上述技术路线外,还有其他的人工智能技术和方法,例如进化算法、自然语言处理、计算机视觉等。随着技术的不断演进和融合,人工智能正不断推动着科技和社会的进步。
往期热门文章推荐:
终于部署成功!GPU 云环境搭建 ChatGLM2-6B 坎坷路
ChatGLM2-6B 初体验
两个把 ChatGPT 利用到极致的技巧
拥抱未来,学习 AI 技能!关注我,免费领取 AI 学习资源。
![浑元太极马老师和小薇-UMLChina建模知识竞赛第4赛季第7轮[更新]](https://img-blog.csdnimg.cn/img_convert/0f27fb17e3b58db862752129a20e347d.png)