MobileNet
文章目录
- MobileNet
- 单词
- 重要
- 不重要
- 摘要
- MobileNetV1
- Motivation
- 深度可分离卷积
- 逐通道卷积(Depthwise Convolution)
- 逐点卷积(Pointwise Convolution)
- 参数对比
- 计算量对比
- V2
- Inverted Residuals
- Linear Bottlnecks
- Model Architecture
- 总结:
参考学习资料:http://124.220.164.99:8090/archives/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E4%B9%8B%E5%9B%BE%E5%83%8F%E5%88%86%E7%B1%BB%E4%B9%9Dmobilenet%E7%B3%BB%E5%88%97v1v1v3#3.-model-architecture
单词
重要
depthwise separable convolutions 深度可分离卷积
hyper-parameter 超参数
不重要
ubiquitous 无处不在的
optimizing 优化
摘要
We present a class of efficient models called MobileNets for mobile and embedded vision applications. MobileNets are based on a streamlined architecture that uses depthwise separable convolutions to build light weight deep neural networks. We introduce two simple global hyper-parameters that efficiently trade off between latency and accuracy. These hyper-parameters allow the model builder to choose the right sized model for their application based on the constraints of the problem. We present extensive experiments on resource and accuracy tradeoffs and show strong performance compared to other popular models on ImageNet classification. We then demonstrate the effectiveness of MobileNets across a wide range of applications and use cases including object detection, finegrain classification, face attributes and large scale geo-localization.
我们提出了一类有效的模型,称为MobileNets,用于移动和嵌入式视觉应用。MobileNets 基于流线型架构,该架构使用深度可分离卷积来构建轻量级深度神经网络。我们引入了两个简单的全局超参数,可以有效地权衡延迟和准确性。这些超参数允许模型构建器根据问题的约束为其应用程序选择正确的大小模型。我们对资源和准确性权衡进行了广泛的实验,并在 ImageNet 分类上展示了与其他流行模型相比的强大性能。然后,我们展示了MobileNets在广泛的应用程序和用例中的有效性,包括对象检测、细粒度分类、人脸属性和大规模地理定位。
MobileNetV1
Motivation
-
The general trend has been to make deeper and more complicated networks in order to achieve higher accuracy. However, these advances to improve accuracy are not necessarily making networks more efficient with respect to size and speed. In many real world applications such as robotics, self-driving car and augmented reality, the recognition tasks need to be carried out in a timely fashion on a computationally limited platform.
-
总体趋势是制作更深、更复杂的网络,以达到更高的精度。然而,提高准确性的这些进步并不一定使网络在大小和速度方面更有效。在许多现实世界的应用中,如机器人、自动驾驶汽车和增强现实,识别任务需要在计算有限的平台上及时执行。
卷积神经网络(CNN)已经普遍应用在计算机视觉领域,并且已经取得了不错的效果。但是,近几年来CNN在ImageNet竞赛的表现可以看到,为了追求分类准确度,模型深度越来越深,模型复杂度也越来越高,如深度残差网络(ResNet)其层数已经多达152层。然而,在某些真实的应用场景如移动或者嵌入式设备,如此大而复杂的模型是难以被应用的。
首先是模型过于庞大,面临着内存不足的问题,其次这些场景要求低延迟,或者说响应速度要快,想象一下自动驾驶汽车的行人检测系统如果速度很慢会发生什么可怕的事情。所以,研究小而高效的CNN模型在这些场景至关重要,至少目前是这样,尽管未来硬件也会越来越快。
目前的研究总结来看分为两个方向:一是对训练好的复杂模型进行压缩得到小模型,也就是业界常说的模型量化;二是直接设计小模型并进行训练。不管如何,其目标在保持模型性能(accuracy)的前提下降低模型大小(parameters size),同时提升模型速度(speed, low latency)。
本文的主角MobileNet系列的网络属于后者,是Google最近提出的一种小巧而高效的CNN模型,其在accuracy和latency之间做了折中。下面对MobileNet做详细的介绍。
-
This paper describes an efficient network architecture and a set of two hyper-parameters in order to build very small, low latency models that can be easily matched to the design requirements for mobile and embedded vision applications.
-
本文描述了一种高效的网络架构和一组两个超参数,以构建非常小的、低延迟的模型,可以很容易地与移动和嵌入式视觉应用的设计要求相匹配
深度可分离卷积
MobileNetV1之所以轻量,与深度可分离卷积的关系密不可分。

如上图所示,模型推理中卷积操作占用了大部分的时间,因此MobileNetV1使用了深度可分离卷积对卷积操作做了进一步的优化,具体解释如下:
常规卷积操作
对于5x5x3的输入,如果想要得到3x3x4的feature map,那么卷积核的shape为3x3x3x4;如果padding=1,那么输出的feature map为5x5x4,如下图:
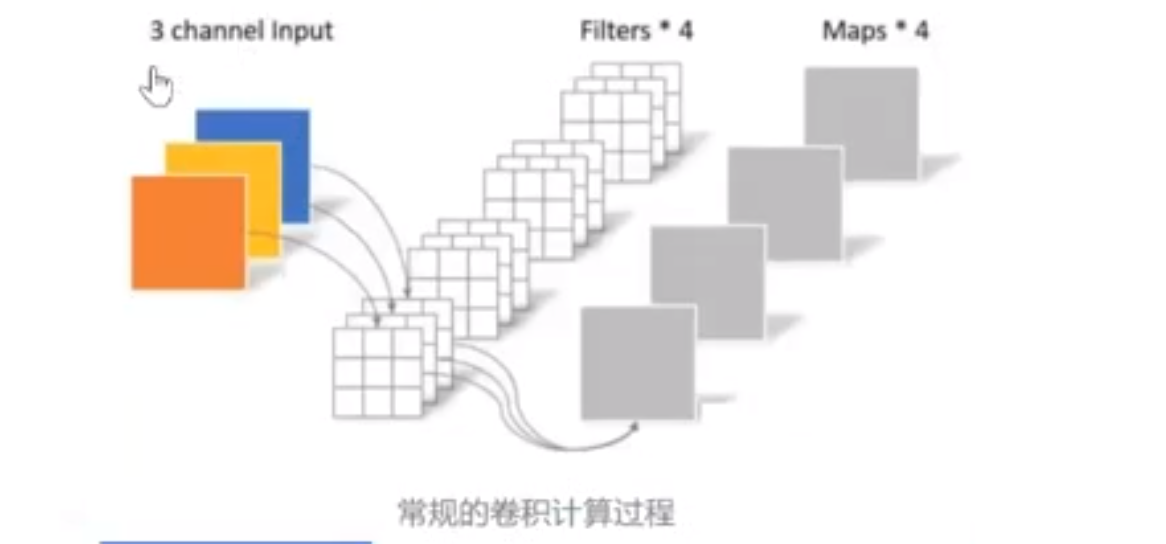
卷积层共4个Filter,每个Filter包含一个通道数为3(与输入信息通道相同),且尺寸为3×3的kernel。因此卷积层的参数数量可以用如下公式来计算(即:卷积核W x 卷积核H x 输入通道数 x 输出通道数):
N_std = 3 × 3 × 3 × 4= 108
计算量可以用如下公式来计算(即:卷积核W x 卷积核H x (图片W-卷积核W+1) x (图片H-卷积核H+1) x 输入通道数 x 输出通道数):
C_std = 3 * 3 * (5 - 3 + 1) * (5 - 3 + 1) * 3 * 4 = 972
深度可分离卷积 主要是两种卷积变体组合使用,分别为逐通道卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。
逐通道卷积(Depthwise Convolution)
Depthwise Convolution的一个卷积核只有一个通道,输入信息的一个通道只被一个卷积核卷积,这个过程产生的feature map通道数和输入的通道数完全一样,如下图所示:

一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution每个卷积核只负责计算输入信息的某一个通道。卷积核的数量与输入信息的通道数相同。所以一个三通道的图像经过运算后一定是生成了3个Feature map。卷积核的shape即为:(卷积核W x 卷积核H x 输入通道数)。
此时,卷积部分的参数个数计算如下( 卷积核W x 卷积核H x 输入通道数),即:
N_depthwise = 3 × 3 × 3 = 27
我感觉公式肯定和上面都是一样的,那这里少乘了一个输出通道数,那就说明输出通道数是1?????????
但输出通道数应该为3才对啊,那我认为应该是输入通道为1,输出通道为3
但是看图片中的卷积层就很好算了,3 * 3 * 1的卷积核,一共有3个,所以参数量是 3 * 3 * 3
计算量为( 卷积核W x 卷积核H x (图片W-卷积核W+1) x (图片H-卷积核H+1) x 输入通道数)即:
C_depthwise = 3 x 3 x (5 - 3 + 1) x (5 - 3 + 1) x 3 = 243
Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法在通道维度上扩展或压缩Feature map的数量。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的features的相关性。**简而言之,虽然减少了计算量,但是失去了通道维度上的信息交互。**因此需要Pointwise Convolution来将这些Feature maps进行组合生成新的Feature maps。
逐点卷积(Pointwise Convolution)
Pointwise Convolution的运算与常规卷积运算非常相似,其实就是1X1的卷积。它的卷积核的尺寸为 1×1×M,M为上一层输出信息的通道数。所以这里Pointwise Convolution的每个卷积核会将上一步的feature maps在通道方向上进行加权组合,生成新的feature map。有几个卷积核就有几个输出多少个新的feature maps。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RwcD6dnx-1687935902408)(https://gitee.com/aure0219/typora-img/raw/master/202306271443269.png)]
由于采用的是1×1卷积的方式,此步中卷积涉及到的参数个数可以计算为(1 x 1 x 输入通道数 x 输出通道数):
N_pointwise = 1 × 1 × 3 × 4 = 12
计算量则为(1 x 1 x 特征层W x 特征层H x 输入通道数 x 输出通道数):
C_pointwise = 1 × 1 × 3 × 3 × 3 × 4 = 108
经过Pointwise Convolution之后,由四个卷积核输出了4张Feature map,与常规卷积的输出维度相同。
参数对比
回顾一下,常规卷积的参数个数为:
N_std = 4 × 3 × 3 × 3 = 108
Depthwise Separable Convolution的参数由两部分相加得到:
N_depthwise = 3 × 3 × 3 = 27
N_pointwise = 1 × 1 × 3 × 4 = 12
N_separable = N_depthwise + N_pointwise = 39
相同的输入,同样是得到4张Feature map,Separable Convolution的参数个数是常规卷积的约1/3。因此,在参数量相同的前提下,采用Depthwise Separable Convolution的神经网络层数可以做的更深。
计算量对比
回顾一下,常规卷积的计算量为:
C_std = 3 * 3 * (5 - 3 + 1) * (5 - 3 + 1) * 3 * 4 = 972
Depthwise Separable Convolution的参数由两部分相加得到:
C_depthwise = 3 x 3 x (5 - 3 + 1) x (5 - 3 + 1) x 3 = 243
C_pointwise = 1 × 1 × 3 × 3 × 3 × 4 = 108
C_separable = C_depthwise + C_pointwise = 351
相同的输入,同样是得到4张Feature map,Separable Convolution的计算量也是常规卷积的约1/3。因此,在计算量相同的情况下,Depthwise Separable Convolution可以将神经网络层数可以做的更深。

第二层是逐通道卷积,第三层是逐点卷积,两个加起来是深度可分离卷积
s1代表步长为1,s2代表步长为2
V2
原始论文:MobileNetV2: Inverted Residuals and Linear Bottlenecks。
V2 中主要用到了 Inverted Residuals 和 Linear Bottlnecks。
Inverted Residuals
我们看到 V1 的网络结构还是非常传统的直桶模型(没有旁路),但是 ResNet在模型中引入旁路并取得了很好的效果,因此到了 V2 的时候,作者也想引入进来,这就有了我们要探讨的问题了。
首先我们看下ResNet BottleNeck Block。下图可以看到,采用 1x1 的卷积核先将 256 维度降到 64 维,经过 3x3 的卷积这后,然后又通过 1x1 的卷积核恢复到 256 维。

我们要把 ResNet BottleNeck Block 运用到 MobileNet 中来的话,如果我们还是采用相同的策略显然是有问题的,因为 MobileNet 中由于逐通道卷积,本来 feature 的维度就不多,如果还要先压缩的话,会使模型太小了,所以作者提出了 Inverted Residuals,即先扩展(6倍)后压缩,这样就不会使模型被压缩的太厉害。 下图对比了原始残差和反转残差结构:

Linear Bottlnecks
Linear Bottlnecks 听起来很高级,其实就是把上面的 Inverted Residuals block 中的 bottleneck 处的 ReLU 去掉。
那为什么要去掉呢?而且为什么是去掉最后一个1X1卷积后面的 ReLU 呢?因为在训练 MobileNet V1 的时候发现最后 Depthwise 部分的 kernel 训练容易失去作用,最终再经过ReLU出现输出为0的情况。作者发现是因为ReLU 会对 channel 数较低的张量造成较大的信息损耗,因此执行降维的卷积层后面不会接类似于ReLU这样的非线性激活层。说人话就是:1X1卷积降维操作本来就会丢失一部分信息,而加上 ReLU 之后那是雪上加霜,所以去掉 ReLU 缓一缓。
n_dim = 10
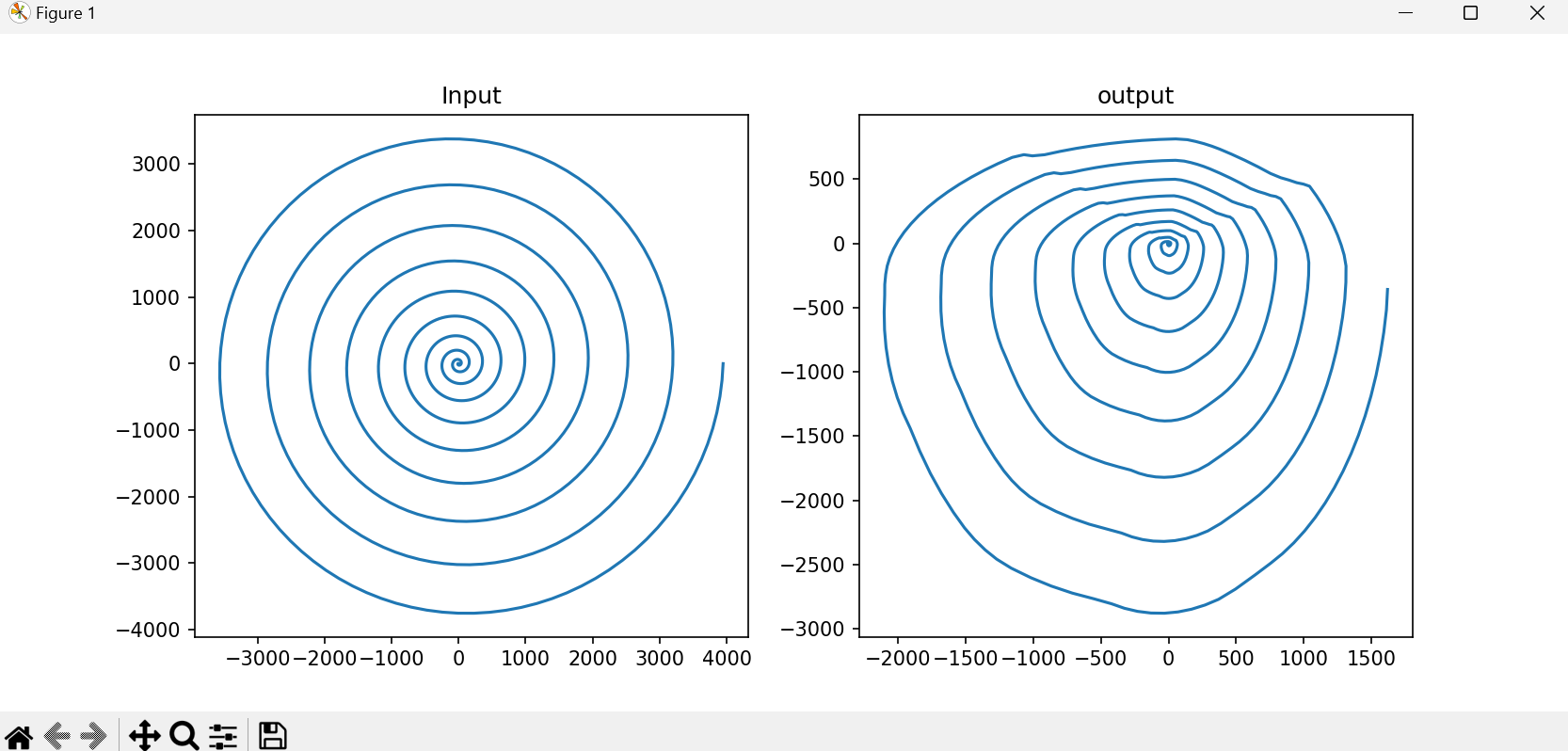
n_dim = 5

n_dim = 2
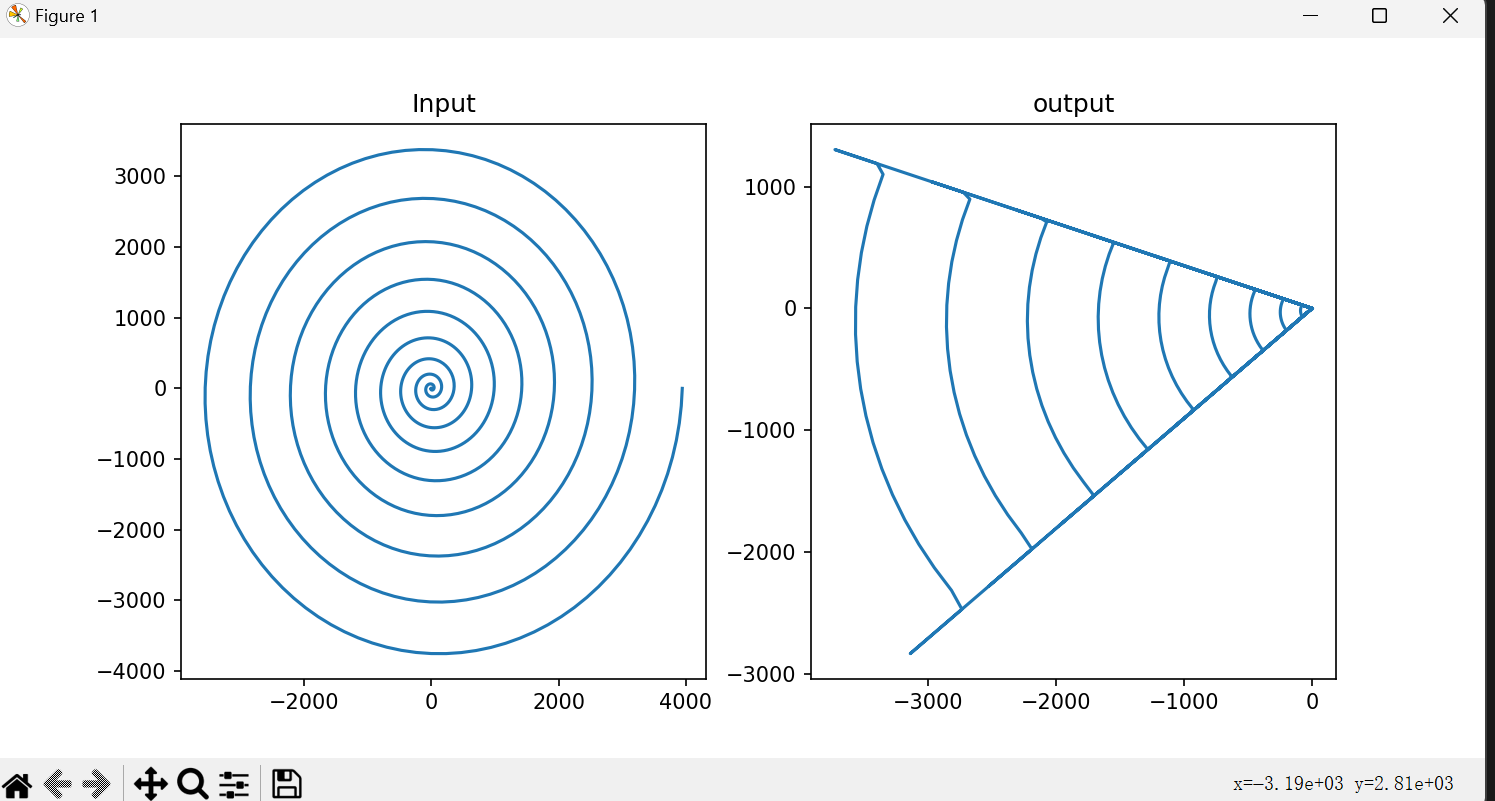
结论就是当n_dim越小,通过矩阵的逆得到的螺旋图与原图差的越多
把最后一个relu函数去掉后,发现输出的就与原图一样了

test.py代码:
import numpy as np
import matplotlib.pyplot as plt
m_dim = 1000
n_dim = 2
##创建螺旋图
def create_spiral(m_dim):
x=[]
y=[]
for theta in np.linspace(0,20*np.pi,m_dim):
r = ((theta)**2)
x.append(r*np.cos(theta))
y.append(r*np.sin(theta))
return np.array([x,y])
def relu(input):
return np.maximum(input,0)
def show_image(image,title,column):
[x,y] = image
plt.subplot(1,2,column)
plt.title(title)
plt.plot(x,y)
# plt.show()
input = create_spiral(m_dim)
show_image(input,"Input",1)
T = np.random.rand(n_dim, 2) - 0.5 #(-0.5,0.5)
layer_out = np.dot(T,input) #w*x 即权重*x 模拟神经网络
layer_output = relu(layer_out)
T_ni = np.linalg.pinv(T) ##计算T的逆矩阵
out = np.dot(T_ni,layer_out) ##out = T^(-1) * y
show_image(out,"output",2)
plt.show()
Model Architecture
完整的MobileNetV2的网络结构参数如下:
t代表反转残差中第一个1X1卷积升为的倍数;c代表通道数;n代表堆叠bottleneck的次数;s代表DWconv的幅度(1或2)。不同的步幅对应了不同的模块

总结:
MobileNetV2最大的贡献就是改进了通道数较少的网络运用残差连接的方式:设计了反转残差(Inverted Residuals)的结构。另外,提出了Linear Bottlnecks的模型设计技巧。







![浑元太极马老师和小薇-UMLChina建模知识竞赛第4赛季第7轮[更新]](https://img-blog.csdnimg.cn/img_convert/0f27fb17e3b58db862752129a20e347d.png)



