目录
引言
逻辑回归的理论基础
逻辑回归的实践
实战案例:银行营销预测
超越逻辑回归
引言
我们在上一篇文章中讨论了线性回归模型,探讨了如何利用它来解决连续变量预测的问题。今天,我们将转向一种新的模型——逻辑回归,它用于处理二元分类问题。
逻辑回归是一种统计学中的基础方法,用于解决分类问题,尤其是在预测一个结果为二分类的情况。例如,一个电子邮件是否是垃圾邮件?一个用户是否会点击一个广告?一个患者是否患有某种疾病?这些都是逻辑回归可以帮助我们解决的问题。
逻辑回归虽然名字里有“回归”,但它实际上是一种分类算法,而不是回归算法。这是因为逻辑回归模型的输出是一个介于0和1之间的概率,我们可以通过选择一个阈值(如0.5),将这个概率转化为一个二元类别。
尽管逻辑回归和线性回归有一些相似之处(比如,它们都是参数模型,都可以使用梯度下降等优化方法),但它们之间也存在一些重要的区别。首先,线性回归是用于解决回归问题(预测一个连续的输出),而逻辑回归是用于解决分类问题(预测一个离散的输出)。其次,逻辑回归使用逻辑函数(或称为Sigmoid函数)来将线性函数的输出转化为一个概率。
逻辑回归模型的理解和应用将会对你在学习更深层次的机器学习算法,如神经网络和深度学习有很大帮助,因为这些更复杂的模型在某种程度上都基于逻辑回归或者其思想。
在接下来的文章中,我们将深入探讨逻辑回归的理论基础,通过Python代码进行实践,以及通过一个实战案例来进一步理解逻辑回归的应用。
逻辑回归的理论基础
让我们首先了解一下逻辑函数,也叫做Sigmoid函数。这是一种常用于将任意实数映射到0和1之间的函数。Sigmoid函数的公式如下:
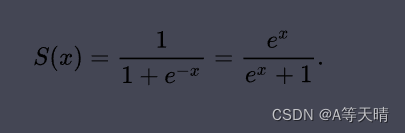
其中,z 是任意实数。Sigmoid函数的图像呈S形,当 z 趋向正无穷时,函数值趋向1;当 z 趋向负无穷时,函数值趋向0。
逻辑回归模型的基础是线性回归模型。对于一个具有 p 个特征的样本,我们可以建立一个线性回归模型:
y = β0 + β1*x1 + β2*x2 + ... + βp*xp + ε
然而,由于我们需要预测的是一个概率(介于0和1之间),我们不能直接使用线性回归模型的输出。这时候,我们就需要使用逻辑函数来将线性回归的输出转化为一个概率。于是,我们得到了逻辑回归模型的公式:
P(y=1|x) = 1 / (1 + e^(-(β0 + β1*x1 + β2*x2 + ... + βp*xp)))
在这个公式中,P(y=1|x) 表示给定特征 x 的条件下,类别 y 为1的概率。β0, β1, ..., βp 是模型的参数,我们的目标是学习这些参数,使得模型的预测概率尽可能接近真实的类别。
在训练模型的过程中,我们需要定义一个损失函数,来衡量模型的预测概率与真实类别之间的差距。对于逻辑回归模型,我们通常使用对数损失函数(log loss),公式如下:
L = -1/N * ∑(y*log(p) + (1-y)*log(1-p))
在这个公式中,y 是真实的类别,p 是预测的概率,N 是样本的数量。我们的目标是最小化损失函数,也就是找到一组参数,使得损失函数的值最小。
为了最小化损失函数,我们通常使用梯度下降法。这是一种迭代的优化算法,通过不断地更新参数的值,使得损失函数沿着梯度的负方向下降,最终达到一个局部最小值。
在每一次迭代中,我们根据当前的参数计算损失函数的梯度,然后按照这个梯度的方向更新参数的值。参数的更新公式如下:
β = β - η * ∇L
在这个公式中,β 是当前的参数,η 是学习率(一个正的实数,用于控制更新的步长),∇L 是损失函数的梯度。
例如,假设我们有一个简单的逻辑回归模型,只有一个特征 x 和一个参数 β。给定一个样本(x=2, y=1),当前的参数值 β=0.5,学习率 η=0.1。我们可以先计算模型的预测概率 p:
p = 1 / (1 + e^(-(0.5*2))) = 0.76
然后,我们可以计算损失函数的值:
L = -(1*log(0.76) + (1-1)*log(1-0.76)) = 0.27
接着,我们可以计算损失函数的梯度(对 β 求导):
∇L = (p - y) * x = (0.76 - 1) * 2 = -0.48
最后,我们可以更新参数的值:
β = β - η * ∇L = 0.5 - 0.1 * -0.48 = 0.548
通过多次迭代,我们可以找到一组参数,使得损失函数达到最小值。这就是逻辑回归模型的基本理论,以及梯度下降法在逻辑回归中的应用。
在接下来的部分,我们将用Python代码来实现这些理论,让理论与实践相结合。
逻辑回归的实践
在将数据喂入逻辑回归模型之前,我们需要对数据进行一些预处理,这包括类别特征的编码和特征的缩放。
如果数据中包含类别特征(例如颜色、品牌等),我们需要将这些特征转化为数值,因为模型只能处理数值数据。最常用的方法是独热编码(One-Hot Encoding),例如,特征“颜色”有“红色”,“蓝色”,“绿色”三种取值,我们可以将这个特征转化为三个二元特征:“颜色_红色”,“颜色_蓝色”,“颜色_绿色”,取值为0或1。
特征的缩放是指将所有的特征转化到同一尺度上。这是因为如果特征的尺度差距过大,可能会影响模型的训练。最常用的方法是标准化(Standardization),也就是将特征的值转化为均值为0,标准差为1的分布。
在Python的sklearn库中,我们可以使用LabelEncoder和OneHotEncoder进行类别特征的编码,使用StandardScaler进行特征的缩放。
from sklearn.preprocessing import LabelEncoder, OneHotEncoder, StandardScaler
# 类别特征编码
le = LabelEncoder()
ohe = OneHotEncoder()
x[:, 0] = le.fit_transform(x[:, 0])
x = ohe.fit_transform(x).toarray()
# 特征缩放
sc = StandardScaler()
x = sc.fit_transform(x)
创建和训练逻辑回归模型非常简单,我们只需要使用sklearn的LogisticRegression类即可。
from sklearn.linear_model import LogisticRegression
# 创建模型
model = LogisticRegression()
# 训练模型
model.fit(x, y)
在模型训练完成后,我们需要评估模型的性能。对于二元分类问题,我们可以使用混淆矩阵,准确率,精确率,召回率,F1得分等指标。sklearn的metrics模块提供了这些指标的计算函数。
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
# 预测
y_pred = model.predict(x)
# 计算评估指标
cm = confusion_matrix(y, y_pred)
accuracy = accuracy_score(y, y_pred)
precision = precision_score(y, y_pred)
recall = recall_score(y, y_pred)
f1 = f1_score(y, y_pred)
最后,我们可以使用交叉验证进行模型选择和调参。sklearn的model_selection模块提供了交叉验证的函数。
from sklearn.model_selection import cross_val_score
# 交叉验证
scores = cross_val_score(model, x, y, cv=5)
# 输出交叉验证的结果
print("Accuracy**: %.2f (+/- %.2f)" % (scores.mean(), scores.std() * 2))
这段代码会执行5次交叉验证,每次将数据集划分为5份,其中4份用于训练,1份用于测试。交叉验证可以帮助我们更准确地评估模型的性能,因为它考虑了数据分布的不同情况。
在实际应用中,我们还可以通过交叉验证来选择最优的模型和调整模型的参数。例如,我们可以创建多个不同的模型,然后比较它们的交叉验证得分,选择得分最高的模型。我们也可以对一个模型的参数进行调整,看看哪组参数可以得到最高的交叉验证得分。
这就是逻辑回归模型的实践部分。下一部分,我们将通过一个实战案例,来演示如何在实际问题中应用逻辑回归模型。
实战案例:银行营销预测
我们的案例来自一个银行的营销活动。这个银行进行了一次电话营销活动,目标是推广一种定期存款产品。我们有关于客户的一些信息,如年龄,职业,婚姻状况等,以及他们在电话营销活动中的反应(是否订购了定期存款)。我们的目标是构建一个模型,预测客户是否会订购这种定期存款产品。
首先,我们需要读取并分析数据。我们假设数据存储在CSV文件中,可以使用pandas库来读取数据。
import pandas as pd
# 读取数据
df = pd.read_csv('bank.csv')
# 查看数据前5行
print(df.head())
接着,我们需要对数据进行预处理。这包括将类别特征转化为数值,以及特征的缩放。同时,我们也需要将数据划分为训练集和测试集。
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.model_selection import train_test_split
# 类别特征编码
le = LabelEncoder()
for column in df.columns:
if df[column].dtype == 'object':
df[column] = le.fit_transform(df[column])
# 特征缩放
sc = StandardScaler()
df = sc.fit_transform(df)
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(df.drop('y', axis=1), df['y'], test_size=0.2)
下一步,我们创建并训练逻辑回归模型,然后评估模型的性能。
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 创建模型
model = LogisticRegression()
# 训练模型
model.fit(x_train, y_train)
# 评估模型
y_pred = model.predict(x_test)
print('Accuracy: %.2f' % accuracy_score(y_test, y_pred))
在这个案例中,准确率可能并不是一个好的评估指标,因为可能会有严重的类别不平衡问题(订购和不订购的客户数量相差很大)。在这种情况下,我们可以使用精确率,召回率和F1得分等指标。
最后,我们可以解读模型的参数,以及模型结果的业务解读。例如,模型的参数可以告诉我们各个特征对结果的影响程度。如果一个特征的参数值很大,那么这个特征对结果的影响就很大。我们还可以使用模型结果来优化银行的营销策略,例如,优先联系那些模型预测为会订购的客户。
超越逻辑回归
虽然逻辑回归是一个强大的分类工具,但它也有自己的局限性。例如,它假设特征和对数几率之间有线性关系,这可能并不总是成立。此外,逻辑回归可能不适用于处理复杂的非线性数据模式和高度互动的特征。在这些情况下,我们可能需要考虑使用更强大的模型,如支持向量机(SVM),随机森林等。
支持向量机(SVM)是一种强大的分类模型,它可以处理线性和非线性分类问题。SVM通过寻找一个决策边界,最大化正负样本之间的距离,从而实现分类。对于非线性问题,SVM通过引入核函数,将数据映射到更高维的空间,使得在新的空间中数据可线性分隔。
随机森林是一种基于决策树的集成学习方法。它通过创建多个决策树,并将它们的预测结果进行投票或平均,来达到更好的预测性能。随机森林可以自动地处理特征交互,并且对于特征的缩放和分布不敏感,这使得它在很多问题上都表现出色。
逻辑回归与这些模型相比,有一些优势和劣势。一方面,逻辑回归的输出可以解释为概率,这使得它的结果更易于理解和解释。它的训练和预测速度也往往比SVM和随机森林要快。另一方面,SVM和随机森林通常可以在更复杂的问题上获得更好的预测性能。
总的来说,逻辑回归、SVM、随机森林以及其他许多机器学习模型,各有各的优势和使用场景。选择哪种模型,取决于我们的具体任务,数据特性,以及我们对模型性能和解释性的要求。




![[ 云计算 | AWS ] IAM 详解以及如何在 AWS 中直接创建 IAM 账号](https://img-blog.csdnimg.cn/ed181100df55439aa74eba1c99996a04.png)