normalization : 文档规范化
先切词,然后规范化.
规范化要规范哪些内容?
大小写; 标点符号; 时态; 复数;
规范化主要是为了匹配更精准
character filter : 字符过滤器. 标点符号
分词之前的预处理,过滤无用字符
-
HTML Strip Character Filter
:html_strip
- 参数:escaped_tags 需要保留的html标签
-
Mapping Character Filter:type mapping
-
Pattern Replace Character Filter:type pattern_replace
> normalization 通过分词器把单词分词然后规范化 查看具体分词器效果
```json
GET _analyze
{
"text": "the computer Apple is the best Tools, Teacher's notebood",
"analyzer": "english"
}
GET _analyze
{
"text": "the computer Apple is the best Tools",
"analyzer": "standard"
}
```
- HTML strip 过滤html标签
- mapping 映射替换的标点符号等
- pattern Replace 正则替换
- 分词器在创建时指定
DELETE test_idx_analyzer1
PUT test_idx_analyzer1
{
"settings": {
// 这里是分析器 不是分词器; 分词器可以包含设置过滤器和分词器
"analysis": {
// 这个有四种类型具体看官方文档
"char_filter": {
// 分词器名称
"test_char_filter1": {
// 指定具体的类型, 具体类型看官方文档,
"type": ["html_strip"],
"escaped_tags": ["a"]
}
},
"analyzer": {
"test_analyzer1": {
"tokenizer": "keyword",
"char_filter": "test_char_filter1"
}
}
}
}
}
```html
<p> I'm so <a>Happy</a></p>
```
GET test_idx_analyzer1/_analyze
{
"analyzer": "test_analyzer1"
, "text": "<p> I'm so <a>Happy</a></p>"
}
### mapping
DELETE test_idx_analyzer3
PUT test_idx_analyzer3
{
"settings": {
// 这里是分析器 不是分词器; 分词器可以包含设置过滤器和分词器
"analysis": {
// 这个有四种类型具体看官方文档
"char_filter": {
"test_mapping_filter1": {
"type": "mapping",
"mappings":[
"滚 => *",
"蛋 => x"
]
}
},
"analyzer": {
"test_analyzer2": {
"tokenizer": "keyword",
"char_filter": ["test_mapping_filter1"]
}
}
}
}
}
GET test_idx_analyzer3/_analyze
{
"analyzer": "test_analyzer2"
, "text": "滚蛋球"
}
### Pattern replace
### pattern replace
DELETE test_idx_analyzer3
PUT test_idx_analyzer3
{
"settings": {
// 这里是分析器 不是分词器; 分词器可以包含设置过滤器和分词器
"analysis": {
// 这个有四种类型具体看官方文档
"char_filter": {
"test_mapping_filter1": {
"type": "pattern_replace",
"pattern": "(\\d{3})(\\d{4})(\\d{4})",
"replacement": "$1***$2"
}
},
"analyzer": {
"test_analyzer2": {
"tokenizer": "keyword",
"char_filter": ["test_mapping_filter1"]
}
}
}
}
}
GET test_idx_analyzer3/_analyze
{
"analyzer": "test_analyzer2"
, "text": "12345677890"
}
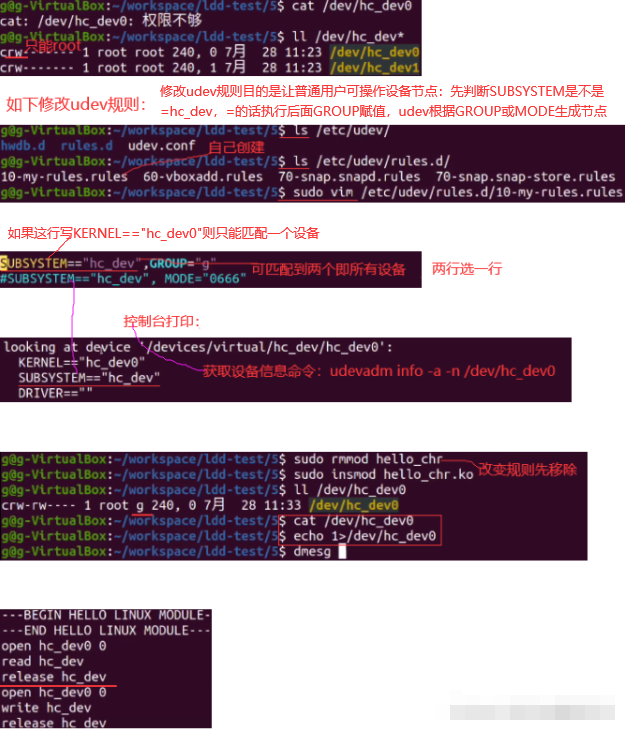
tokenizer : 分词器
安装IK分词器
IK地址:
https://github.com/medcl/elasticsearch-analysis-ik/blob/master/README.md
分词器安装目录
es_home/plugins/ik
分词器安装方式
// 此例子可能需要安装插件, 插件安装有单独一节进行讲解见后
每个节点同义词文件都要同步吗?是的
// ik每个node都要安装; 如果版本不对有两种办法
- 手动编译安装
- 相近的版本可以直接修改版本
如何手动安装?
git clone https://github.com/medcl/elasticsearch-analysis-ik
cd elasticsearch-analysis-ik
git checkout tags/{version}
mvn clean
mvn compile
mvn package
拷贝和解压release下的文件: #{project_path}/elasticsearch-analysis-ik/target/releases/elasticsearch-analysis-ik-*.zip 到你的 elasticsearch 插件目录, 如: plugins/ik 重启elasticsearch
相近的版本可以直接修改版本
vim plugin-descriptor.properties
修改
elasticsearch.version=your_version
> 如果修改plugin-descriptor.properties里的版本号不行的话,还有elasticsearch-analysis-ik-xxx.jar内pom.properties里的版本号。
常见分词器
- standard analyzer:默认分词器,中文支持的不理想,会逐字拆分。
- pattern tokenizer:以正则匹配分隔符,把文本拆分成若干词项。
- simple pattern tokenizer:以正则匹配词项,速度比pattern tokenizer快。
- whitespace analyzer:以空白符分隔 Tim_cookie
自定义分词器:custom analyzer
char_filter:内置或自定义字符过滤器 。
token filter:内置或自定义token filter 。
tokenizer:内置或自定义分词器。
中文分词器IK
IK分词器
安装和部署
- ik下载地址:https://github.com/medcl/elasticsearch-analysis-ik
- Github加速器:https://github.com/fhefh2015/Fast-GitHub
- 创建插件文件夹 cd your-es-root/plugins/ && mkdir ik
- 将插件解压缩到文件夹 your-es-root/plugins/ik
- 重新启动es
- 主词库:main.dic
- 英文停用词:stopword.dic,不会建立在倒排索引中
- 特殊词库:
- quantifier.dic:特殊词库:计量单位等
- suffix.dic:特殊词库:行政单位
- surname.dic:特殊词库:百家姓
- preposition:特殊词库:语气词
- 自定义词库:网络词汇、流行词、自造词等
扩展IK词库
修改IKAnalyzer.cfg.xml中自定义词库的路径,路径原则上可以随便放,管理是跟ik放一起,建一个custome目录

token filter : 令牌过滤器
停用词、时态转换、大小写转换、同义词转换、语气词处理等。比如:has=>have him=>he apples=>apple the/oh/a=>干掉
处理大小写
// why get not PUT
// I miss the keyword _analyze,why? cannot understand better?
// this way is operate exists index to do query
GET /test_index02/_analyze
{
"tokenizer": "standard",
"filter": {
"type": "condition",
"filter": "uppercase",
"script": {
"source": "token.getTerm().length() < 5"
}
},
"text": ["abdsfs sdf dsfdsf dsf dsfdsf sd fds fds f dsf sd f dsf sd fs df sdf dsfdsfdsfs dfdsfds"]
}
token_filter同义词替换
-
定义同义词词典文件 格式
src1,src2 => target -
vim analysis/synonyms.txt Mengdiudiu,mengdiudiu => MDO -
同步到目录 es_home/config/analysis/your_dict.txt
-
如何验证是否生效:
-
DELETE test_index01 PUT /test_index01 { "settings": { "index": { "analysis": { "analyzer": { "test_index01_synonym": { "tokenizer": "whitespace", "filter": [ "test_index01_synonym" ] } }, "filter": { "test_index01_synonym": { "type": "synonym", "synonyms_path": "analysis/synonyms.txt" } } } } } } GET /test_index01/_analyze { "text": "Mengdiudiu", "analyzer": "test_index01_synonym" }
第二种方式
DELETE test_index02
PUT /test_index02
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"test_index02_search_synonyms": {
"tokenizer": "whitespace",
"filter": [ "test_index02_graph_synonyms" ]
}
},
"filter": {
"test_index02_graph_synonyms": {
"type": "synonym_graph",
"synonyms_path": "analysis/synonyms.txt"
}
}
}
}
}
}
GET /test_index02/_analyze
{
"text": "Mengdiudiu",
"analyzer": "test_index02_search_synonyms"
}
自定义切词器,分析器
DELETE test_index03
PUT /test_index03
{
"settings": {
"analysis": {
"char_filter": {
// 自定义char_filter: 转换单词
"test_myfilter03": {
"type": "mapping",
"mappings": ["& => and", "| => or"]
}
// 可以定义多个char_filter,其余的是否可以定义多个可以尝试
},
"filter": {
// 自定义过滤器: 过滤停用词
"test_mystop01":{
"type": "stop",
"stopwords": ["is", "the"]
}
},
"tokenizer": {
// 自定义切词器
"test_mytokenizer01":{
"type": "pattern",
"pattern": "[.,!? ]"
}
},
"analyzer": {
// 自定义分析器
"test_myanalyzer01": {
// 分词器类型,自定义
"type": "custom",
"char_filter": ["test_myfilter03"],
"tokenizer": "test_mytokenizer01",
"filter": ["test_mystop01","lowercase"]
}
}
}
}
}
GET test_index03/_analyze
{
// 使用自定义的analyzer
"analyzer": "test_myanalyzer01",
"text": "is,the.New? Apple! & |"
}
常用分词器
中文分词器
已定义分词器
词库热更新
如果每次更新词库都要重启服务这是生产环境无法忍受的.
所以现在支持热更新;
使用方式就是配置IK config文件的remote_ext_dict的url地址进行热更新(默认是location)
具体的热更新见IK github说明
https://github.com/medcl/elasticsearch-analysis-ik
热更新的坑
- 你本地启动的服务只是告诉es要不要更新,并不是由这个服务返回最新内容,即最终reload操作还是es node从自己本地目录去加载
- node 对应的停用词文件, 分词文件必须有,理由见第一条.
- 停用词和分词文件目录一定要放对plugins/ik/config/custome, 一定要在ik的config内,它是相对这里的, 其他地方不生效,除非配置绝对路径
- 正更新流程是这样的: 修改各个node本地文件-> 三方服务告诉es需要更新->es reload本地文件