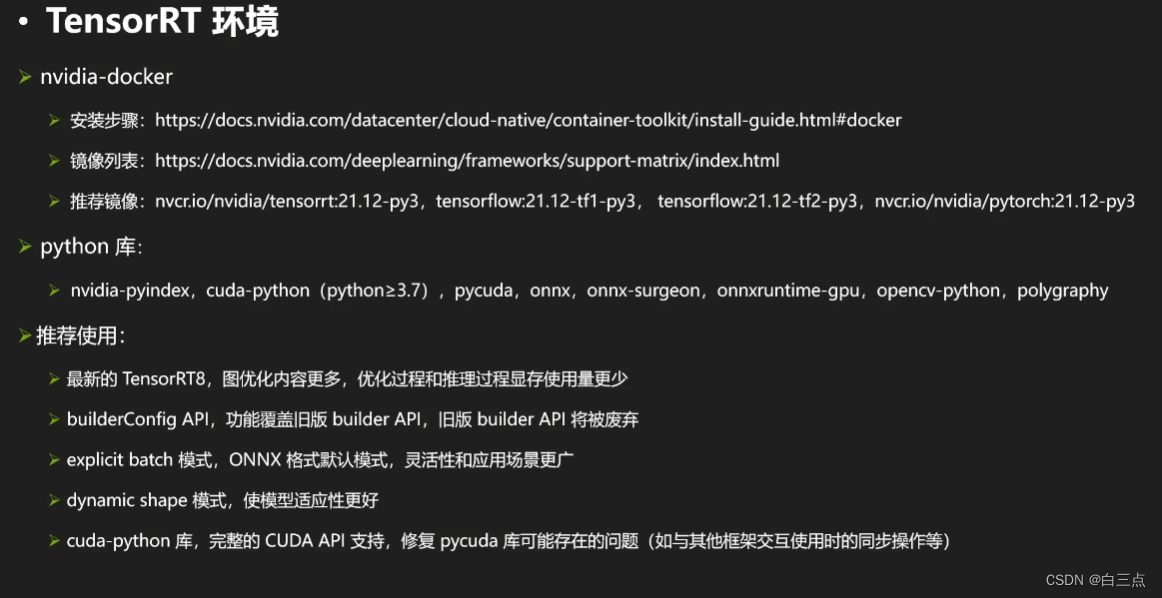
TensorRT用于高效实现已经训练好的深度学习的模型的推理过程的SDK,能使DL模型有更快的推理速度和更高的吞吐量。官方提供Python和C++两种接口,形式基本一致且相互对应。
1 ✨ TensorRT介绍
🍟1.1 TensorRT的工作
分为两个时期(构建期和运行期):
| name | description |
|---|---|
| 模型解析/建立 | 加载 Onnx等其他格式的模型/使用原生API搭建模型 |
| 计算图优化 | 横向层融合(Conv),纵向层融合(Conv+add +ReLU) |
| 节点消除 | 去除无用层,节点变换(Pad,Slice,Concat,Shuffle) |
| 多精度支持 | FP32/ FP16 / INT8 / TF32(可能插入reformat节点) |
| 优选kernel/format | 硬件有关优化 |
| 导入plugin | 实现自定义操作 |
| 现存优化 | 显存池复用 |
| name | description |
|---|---|
| 运行时环境 | 对象生命期管理,内存显存管理,异常处理 |
| 序列化/反序列化 | 推理引擎保存为文件或从文件中加载 |
🌭1.2 TensorRT流程
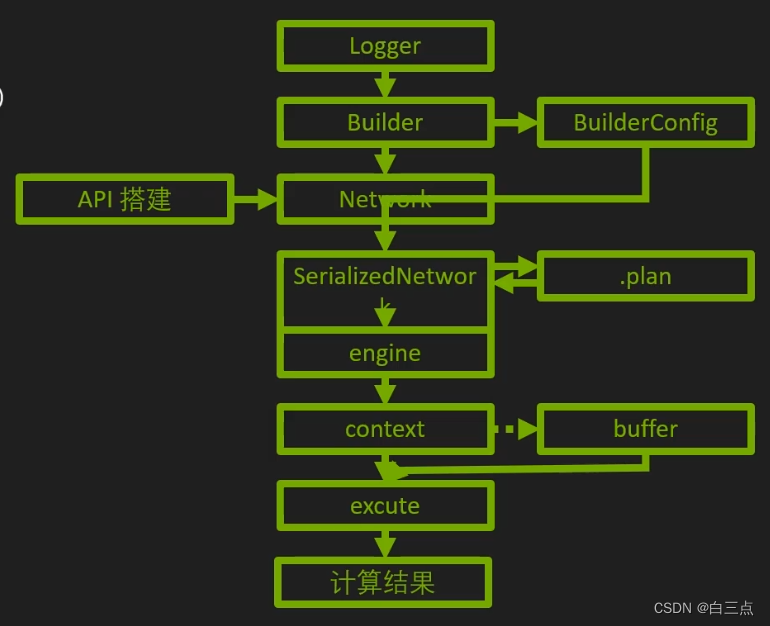
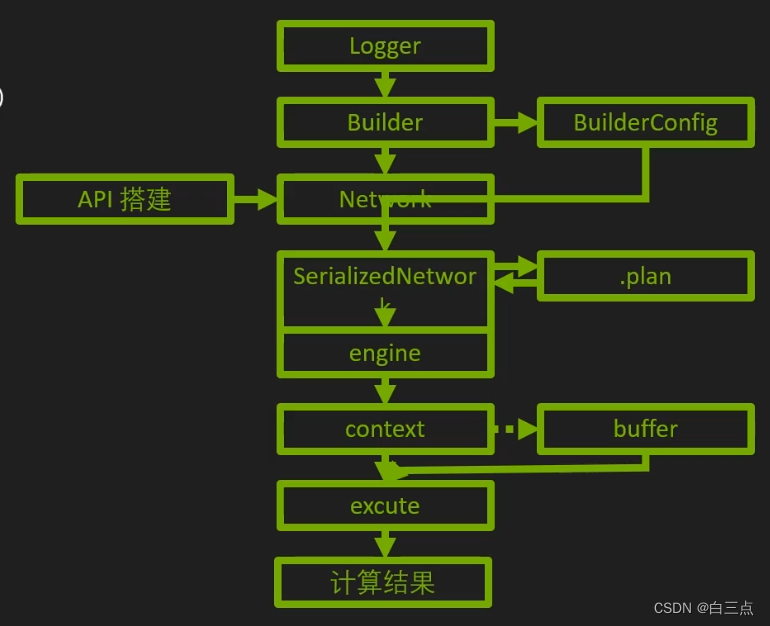
构建期:
- 创建logger(日志记录器)
- 建立Builder(引擎构建器,包含计算图属性信息)和BuilderConfig(Builder相关选项)
- 创建Network(计算图具体内容),网络主体。
- 生成SerializedNetwork(网络的TRT内部表示)
运行期:
5. 建立Engine(模型计算核心)和Context(类比进行)
6. Buffer(数据内存、显存)相关准备(Host端+device端)
7. Buffer拷贝 Host to Device
8. 执行推理(Execute)
9. Buffer拷贝 Device to Host
10.善后工作
🍿1.3 模型转化(DL Network=>TRT Network)
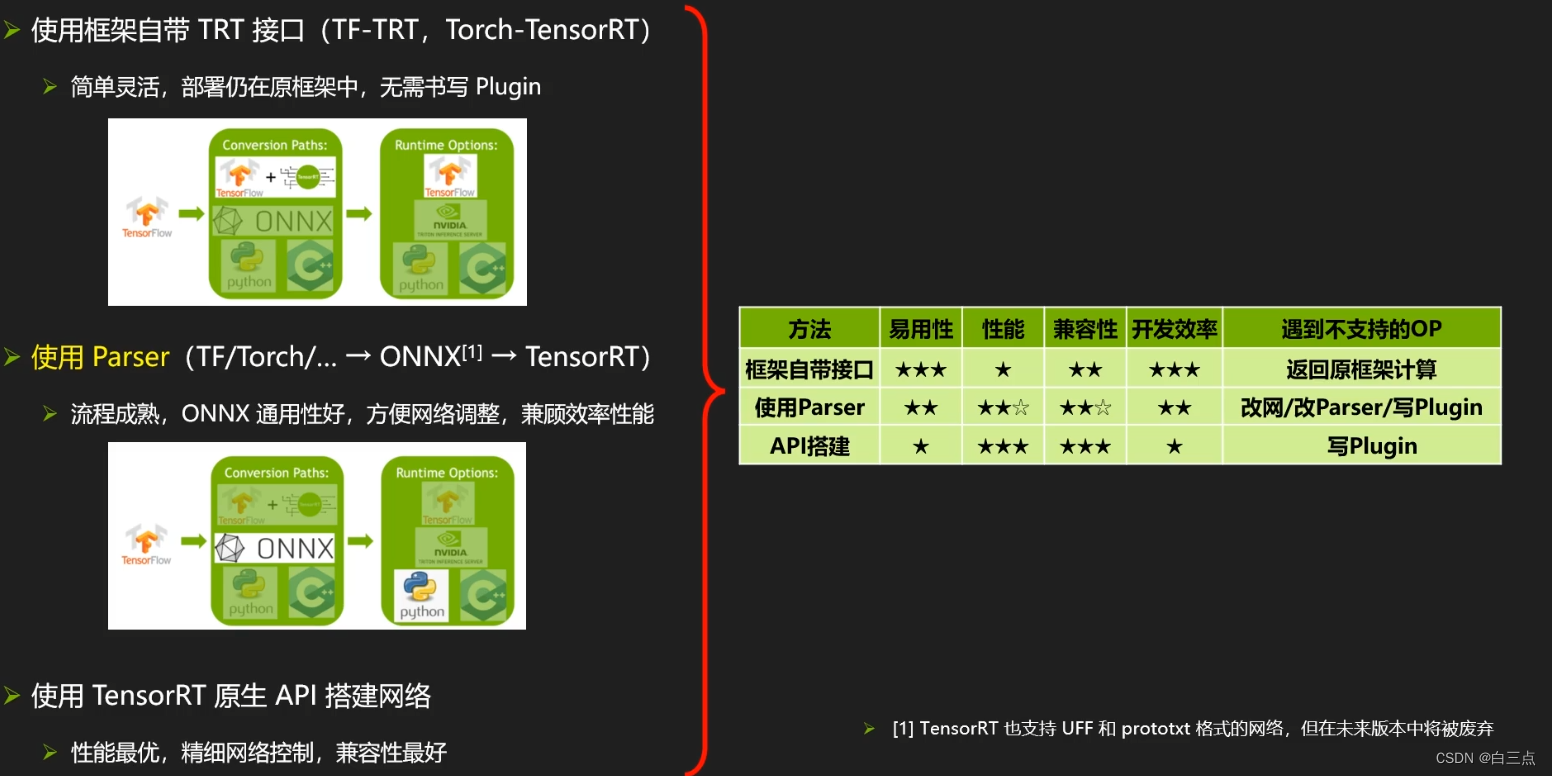
三种方案:
- 使用框架自带的TRT接口。简单灵活,部署仍在原框架中,无需书写Plugin,但是牺牲了一定的性能。
- 使用Paser(推荐)。流程成熟,ONNX通用性好,方便网络调整,兼顾效率性能。
- 使用TensorRT原生API搭建网络。性能最优,精细网络控制,兼容性最好,但是应用性和开发效率较低。
✨ 2 API介绍
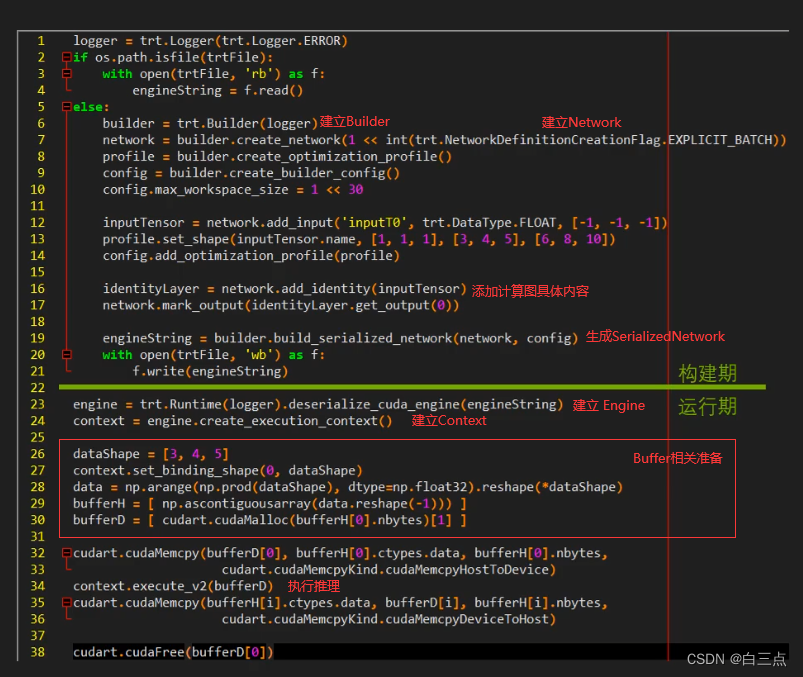
🧂2.1 logger(日志记录器)
"""
trt.Logger.VERBOSE:可选参数,产生不同等级的日志,由详细到简略分别为VERBOSE,INFO,WARNING,ERROR,INTERNAL_ERROR
"""
logger = trt.Logger(trt.Logger.VERBOSE)
通常使用VERBOSE和INFO两个,可获得网络优化过程和接口信息。
🥓 2.2 Builder(引擎构建器)以及BuilderConfig
Builder:
builder = trt.Builder(logger)
builder.max_batch_ size = 256,指定最大Batch Size(Static Shape模式下使用)
BuilderConfig:
config = builder.create_builder_config()
常用属性有:
| name | description |
|---|---|
🥚2.3 Network(网络具体构造)
"""
param:`1 <<int(tensorrt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)`,使用Explicit Batch模式。
"""
network = builder.create_network()
常用方法:
| name | description |
|---|---|
| network.add_input( ‘oneTensor’ ,trt.float32,(3,4,5)) | 标记网络输入张量 |
| network.add_input( ‘oneTensor’ ,trt.float32,(3,4,5)) | 添加layer |
| network.mark_output(convLayer.get_output(O)) | 标记网络输出张量 |
🍿2.4 生成Engine
serializedNetwork = builder. build_serialized_network(network, config) # SerializedNetwork(TRT内部表示)
engine = trt.Runtime(logger).deserialize_cuda_engine(serializedNetwork)

什么是binding:

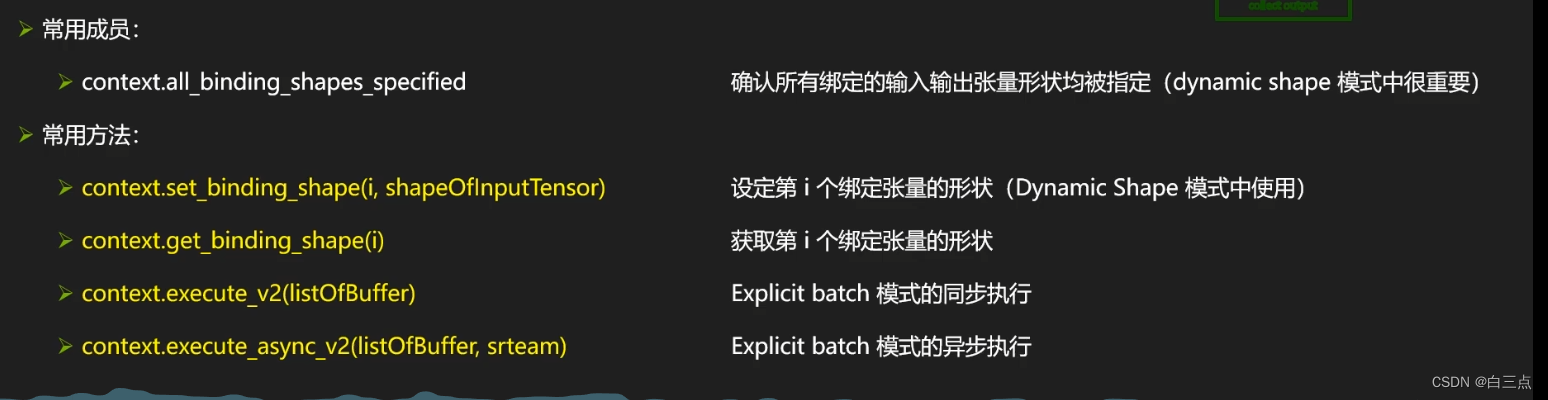
可以用context.get_binding_shape(2)或context.get_binding_shape(3)获取网络信息
🤣2.5 生成Context
context = engine.create_execution_context()
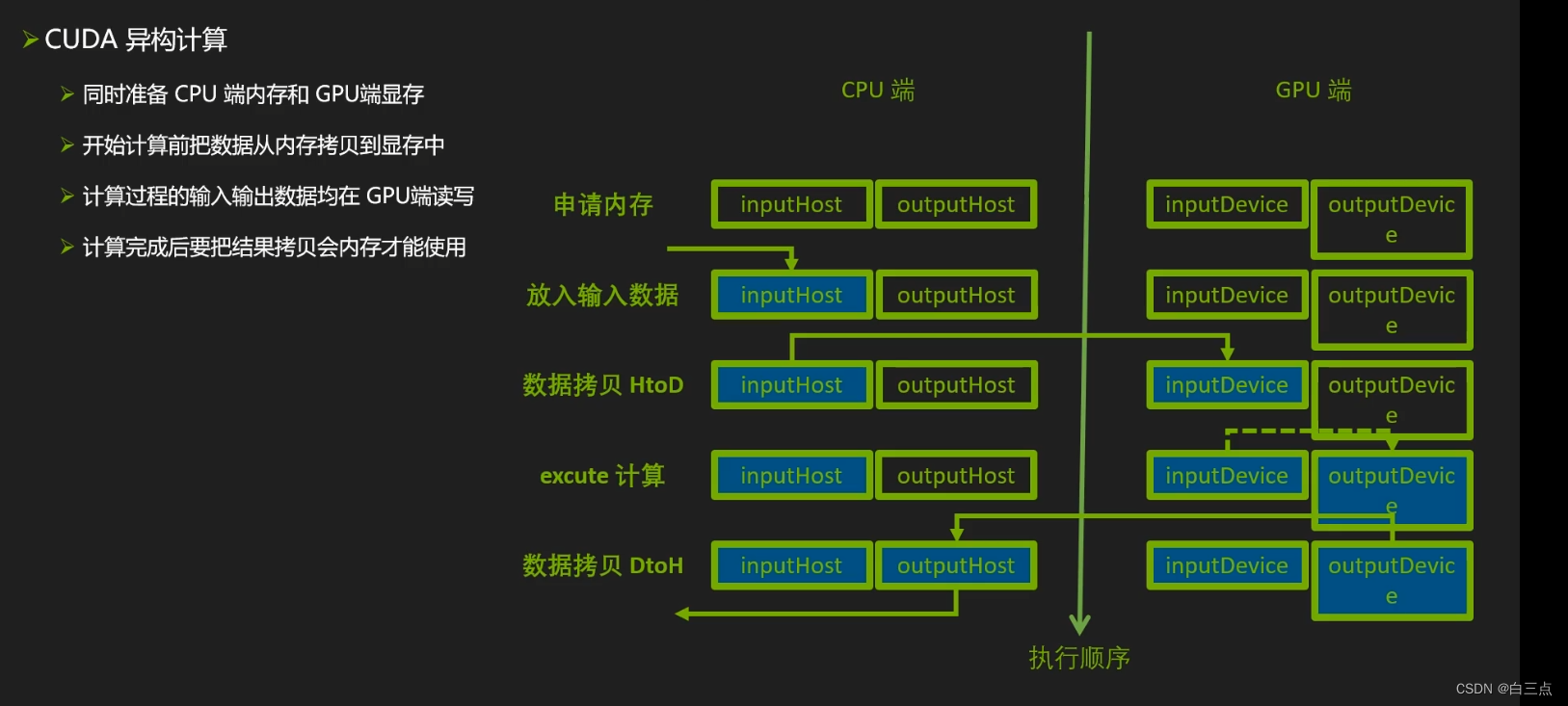
cuda异构计算:
🥓2.6 Buffer

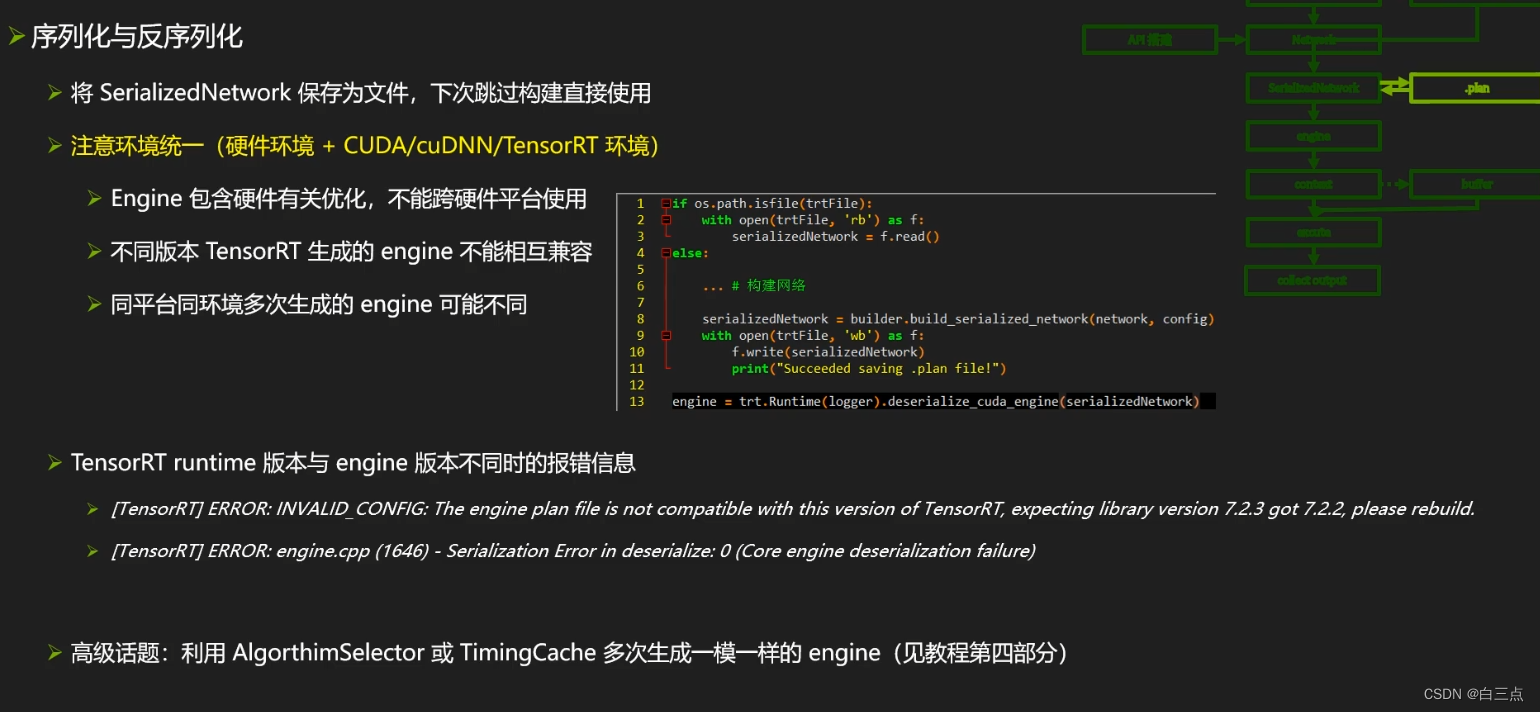
2.7 🎃 TRT文件保存
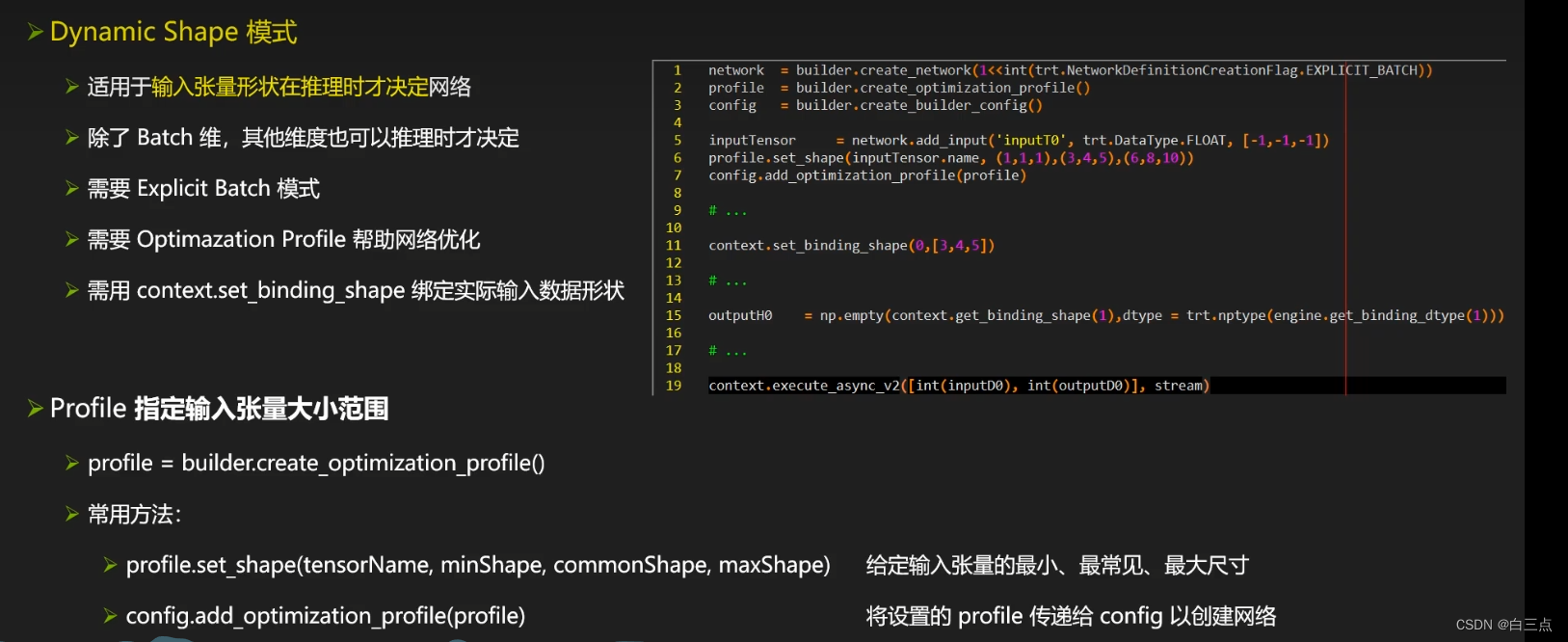
✨3 模式选择
为什么选择Explicit Batch模式,而不选择Implicit Batch模式:
✨ 4 精度
4.1 🍟 FP16

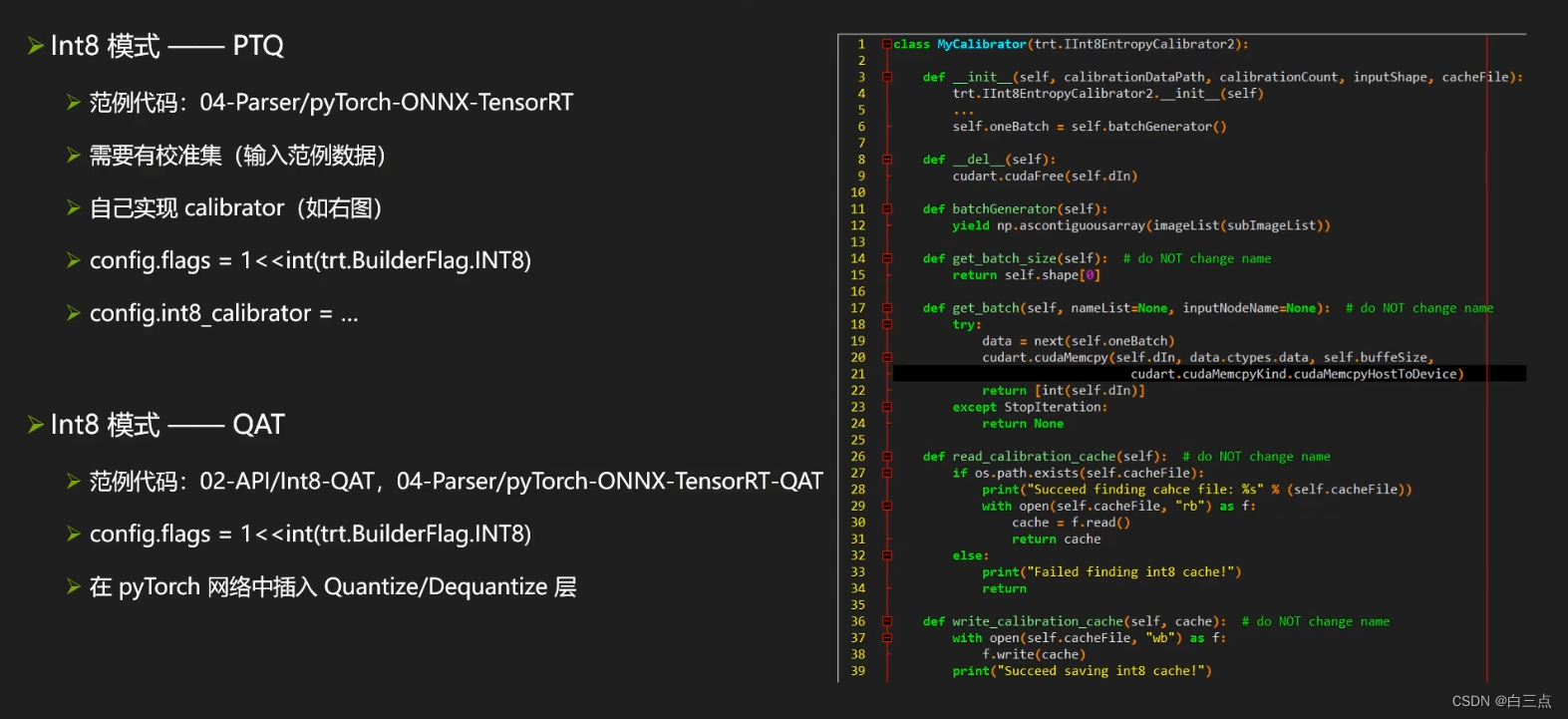
✨5 Parser
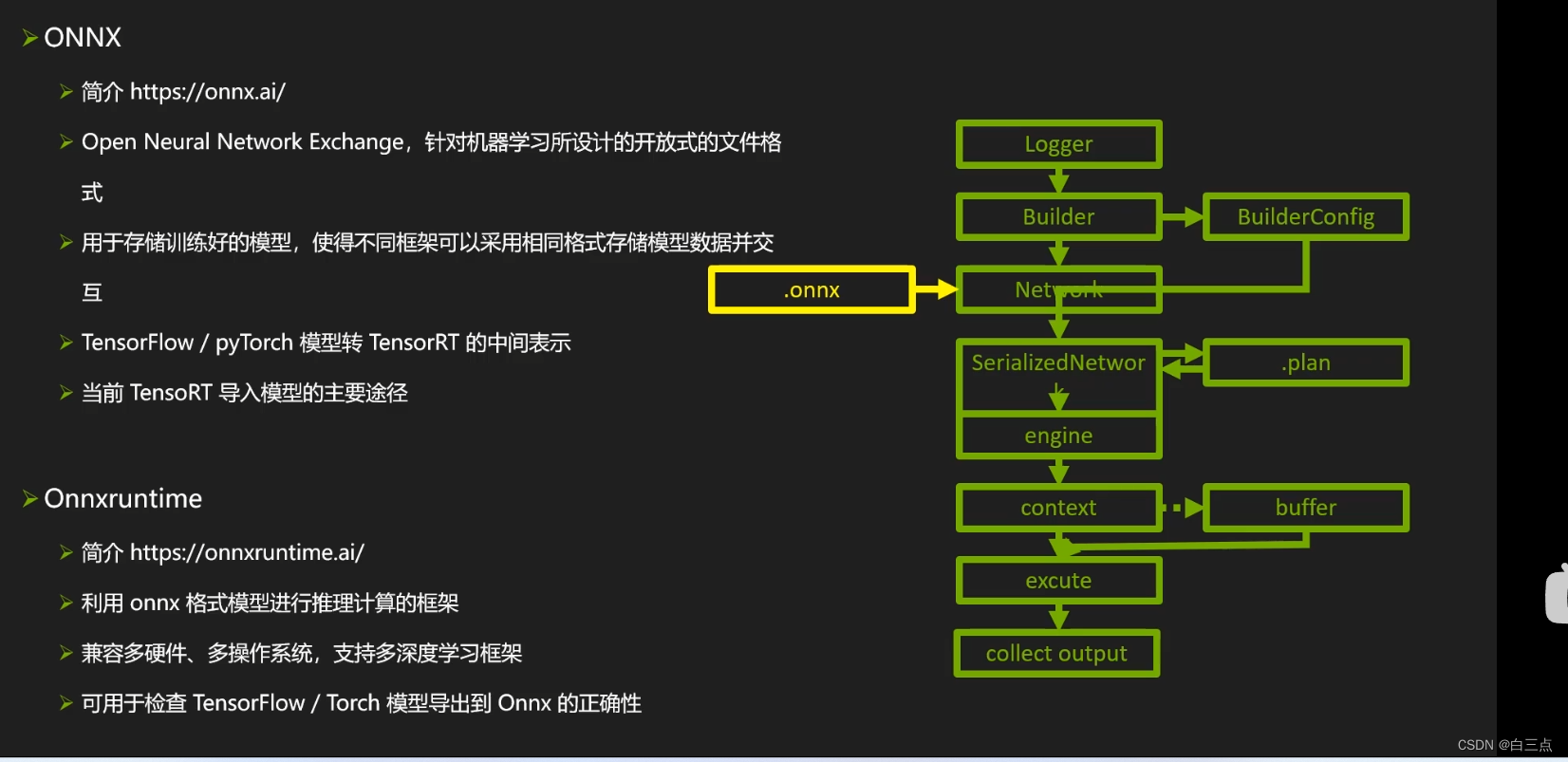
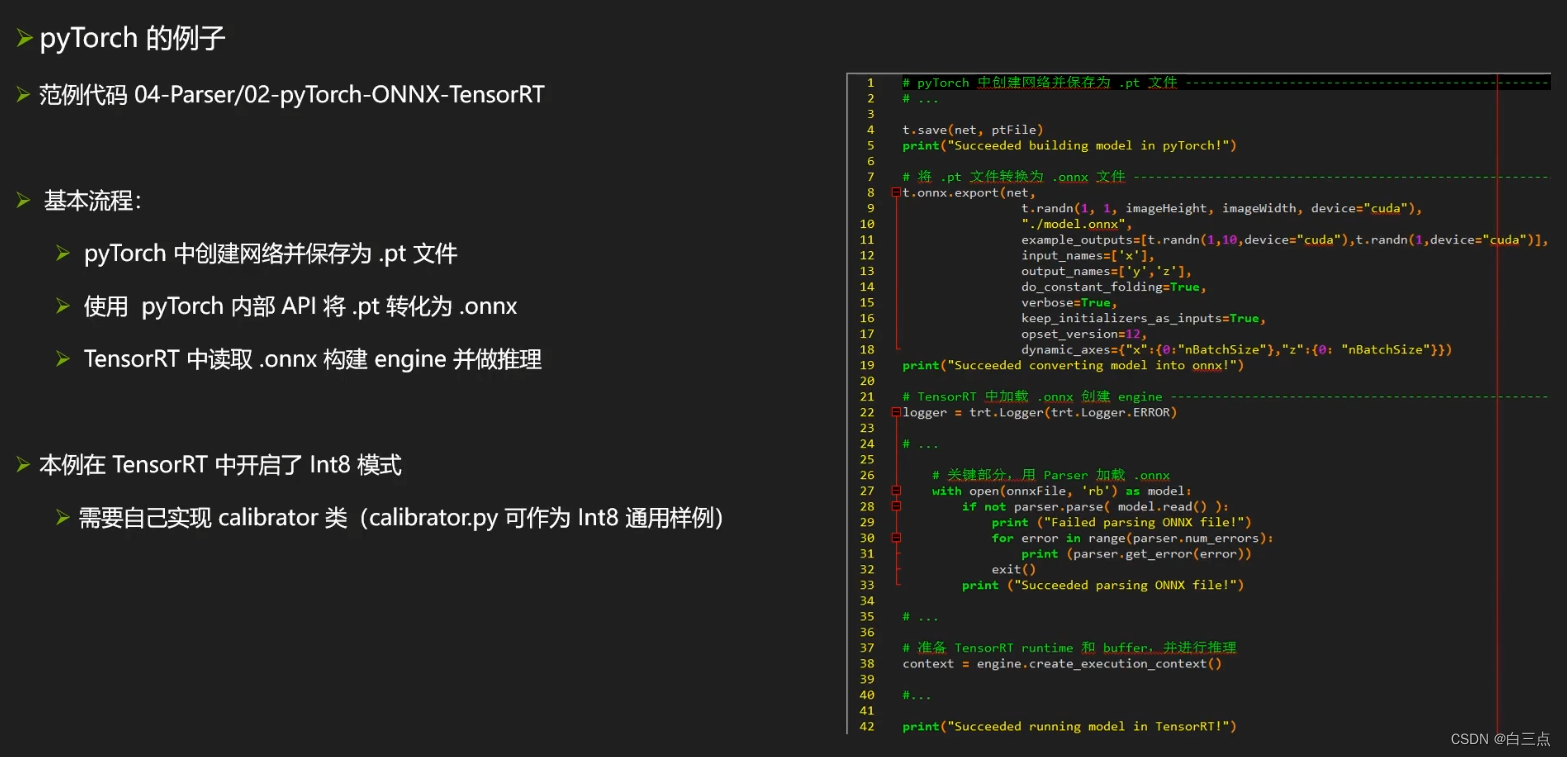

✨ 6 使用框架内的接口

1