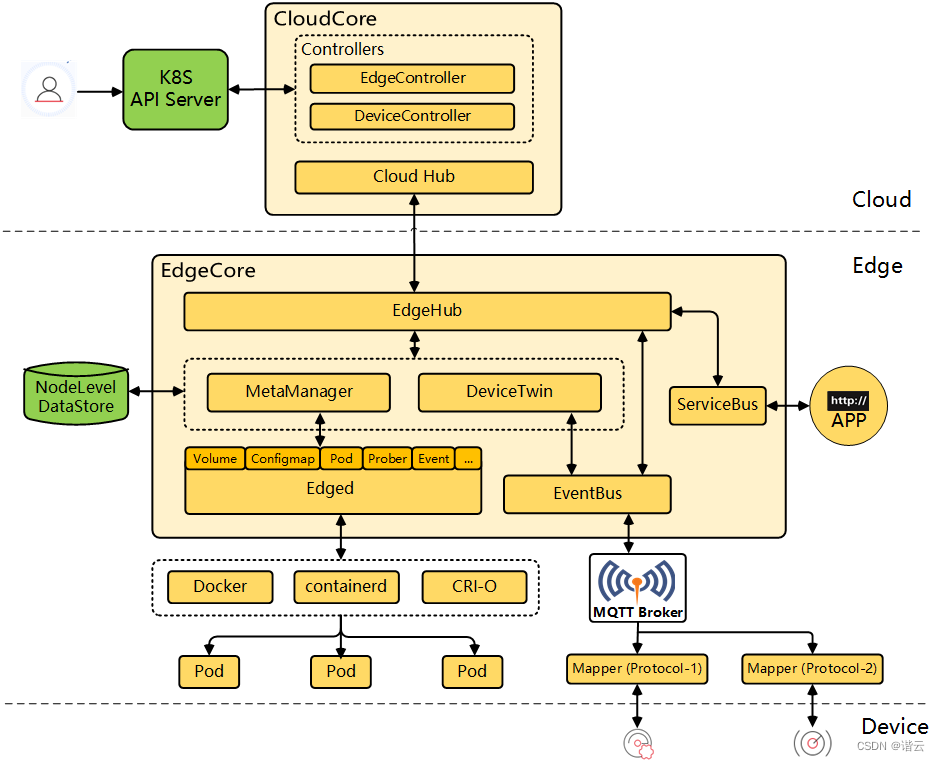
每个文件(不管是一般文件还是目录文件)都会占用一个 inode , 且可依据文件内容的大小来分配多个 block 给该文件使用。道目录的内容在记录文件名, 一般文件才是实际记录数据内容的地方。
目录
当我们在 Linux 下的文件系统创建一个目录时,文件系统会分配一个 inode 与至少一块 block给该目录。其中,inode 记录该目录的相关权限与属性,并可记录分配到的那块 block 号码;而 block 则是记录在这个目录下的文件名与该文件名占用的 inode 号码数据。也就是说目录所占用的 block 内容在记录如下的信息:

图7.1.5、记载于目录所属的 block 内的文件名与 inode 号码对应示意图
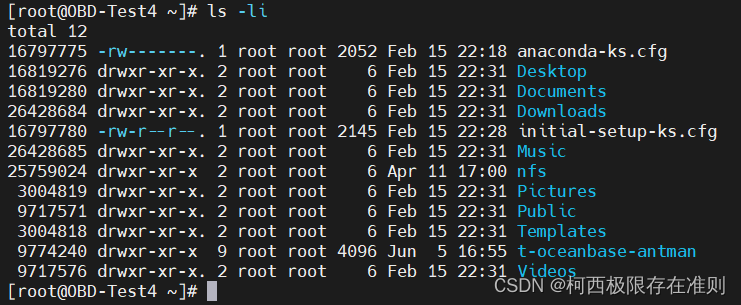
如果想要实际观察 root 主文件夹内的文件所占用的 inode 号码时,可以使用 ls -i 这个选项来处理:
道目录并不只会占用一个 block 而已,也就是说: 在目录下面的文件数如果太多而导致一个 block 无法容纳的下所有的文件名与 inode 对照表时,Linux 会给予该目录多一个 block 来继续记录相关的数据;
文件:
当我们在 Linux 下的 ext2 创建一个一般文件时, ext2 会分配一个 inode 与相对于该文件大小的 block 数量给该文件。例如:假设我的一个 block 为 4 KBytes ,而我要创建一个 100KBytes 的文件,那么 linux 将分配一个 inode 与 25 个 block 来储存该文件! 但同时请注意,由于 inode 仅有 12 个直接指向,因此还要多一个 block 来作为区块号码的记录。
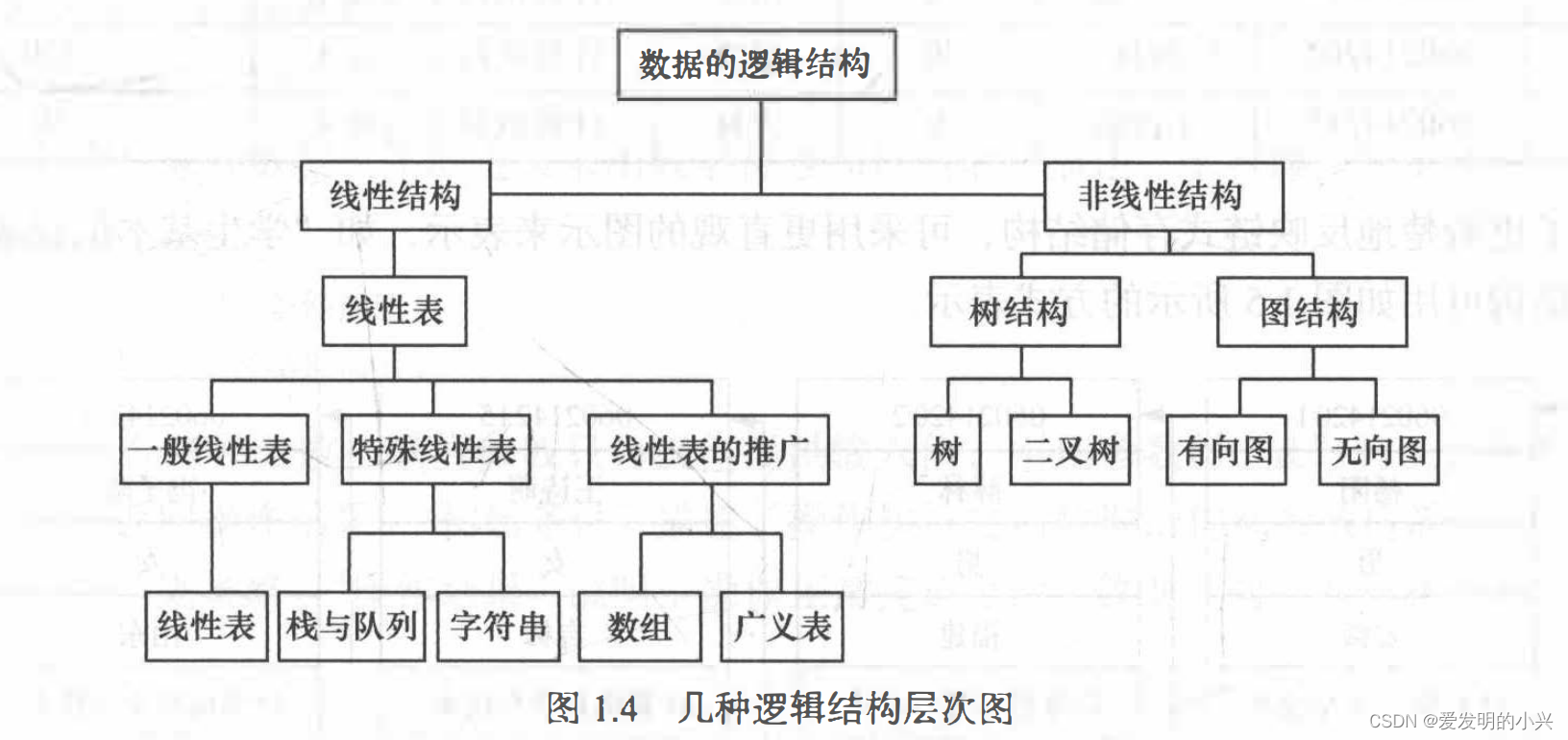
目录树读取:
inode 本身并不记录文件名,文件名的记录是在目录的 block 当中。
因为文件名是记录在目录的 block 当中, 因此当我们要读取某个文件时,就务必会经过目录的 inode 与 block ,然后才能够找到那个待读取文件的 inode 号码, 最终才会读到正确的文件的 block 内的数据。
目录树是由根目录开始读起,因此系统通过挂载的信息可以找到挂载点的 inode 号码,此时就能够得到根目录的 inode 内容,并依据该 inode 读取根目录的 block 内的文件名数据,再一层一层的往下读到正确的文件名。举例来说,如果我想要读取 /etc/passwd 这个文件时,系统是如何读取的呢?

/ 的 inode: 通过挂载点的信息找到 inode 号码为 128 的根目录 inode,且 inode 规范的权限让我们可以读取该 block 的内容(有 r 与 x) ;
/ 的 block: 经过上个步骤取得 block 的号码,并找到该内容有 etc/ 目录的 inode 号码(33595521);
etc/ 的 inode: 读取 33595521 号 inode 得知 dmtsai 具有 r 与 x 的权限,因此可以读取etc/ 的 block 内容;
etc/ 的 block: 经过上个步骤取得 block 号码,并找到该内容有 passwd 文件的 inode 号码 (36628004);
passwd 的 inode: 读取 36628004 号 inode 得知 dmtsai 具有 r 的权限,因此可以读取passwd 的 block 内容;
passwd 的 block: 最后将该 block 内容的数据读出来。
filesystem 大小与磁盘读取性能:
关于文件系统的使用效率上,当你的一个文件系统规划的很大时,例如 100GB 这么大时, 由于磁盘上面的数据总是来来去去的,所以,整个文件系统上面的文件通常无法连续写在一起(block 号码不会连续的意思), 而是填入式的将数据填入没有被使用的 block 当中。如果文件写入的 block 真的分的很散, 此时就会有所谓的文件数据离散的问题发生了。
ext2 在 inode 处已经将该文件所记录的 block 号码都记上了, 所以数据可以一次性读取,但是如果文件真的太过离散,确实还是会发生读取效率低落的问题。 因为磁头还是得要在整个文件系统中来来去去的频繁读取! 果真如此,那么可以将整个filesystme 内的数据全部复制出来,将该 filesystem 重新格式化, 再将数据给他复制回去即可解决这个问题。
此外,如果 filesystem 真的太大了,那么当一个文件分别记录在这个文件系统的最前面与最后面的 block 号码中, 此时会造成磁盘的机械手臂移动幅度过大,也会造成数据读取性能的低落。而且磁头在搜寻整个 filesystem 时, 也会花费比较多的时间去搜寻。因此partition要针对主机用途来进行规划。