大家好,我是 方圆。在《数据密集型应用系统设计》这本书中关于流处理的部分提到了消息队列相关的知识,我觉得它对理解和之后使用消息队列中间件有很大的帮助,遂将其中重要的部分总结出来,但也更推荐大家去看原书,原文收录在我的 Github: enthusiasm 中,欢迎Star和获取原文。
1. 流处理
“流” 是指随着时间的推移逐渐可用的数据,所以流处理认为数据是 无界限的,它们会随着时间的推移而逐渐达到。
流处理介于在线处理和批处理(离线处理)之间,所以又被称为 准实时 或 准在线 处理。它和批处理相似:它们消费输入并产生输出(并不需要响应请求),不同的是流处理在 事件(event) 发生时会尽快处理,而批处理需要等待若干数据准备好之后,才进行处理,这种差异使流处理系统比起批处理系统具有 更低的延迟。在流处理系统中,一个事件由 生产者 生成一次,然后可能被多个 消费者 进行处理,相关的事件通常被聚合为一个主题(topic)或流(stream)。
2. 消息系统
消息系统是典型的流处理系统,它能在新事件出现时立即通知消费者,这样就能保证对新事件进行低延迟的连续处理,也因此避免了消费者通过轮询机制检查新事件产生开销。
像TCP信道这种直接通信的形式是比较简单的消息系统,它使用生产者和消费者直接进行网络通信,不过这种形式的消息系统容错程度极为有限:如果消费者宕机,即使生产者有超时重传的机制也会导致消息丢失;如果生产者宕机,那么需要它进行超时重传的消息和缓冲队列中的消息都会丢失。
为了解决容错程度较低的问题,可以采用 消息队列(message queue) 来对消息进行管理,它的本质上是一种 针对消息流而优化的数据库,生产者将消息写入消息队列,消费者从消息队列进行读取,通过将 数据持久化 转移到消息队列上,来提高生产者和消费者客户端对消息丢失的容忍程度。
3. 消息队列
消费者对消息队列中消息的消费通常是 异步 的,当生产者发送消息时,通常只会等待消息队列确认消息已经被缓存,而不会等待消费者来处理消息。消费者对消息的消费通常在几分之一秒内,如果发生消息积压的情况,会出现明显的延迟。
3.1 基于 JMS/AMQP 标准的消息队列
我们所熟悉的 RabbitMQ 就是对 JMS/AMQP 标准的实现。如果在消息处理代价比较高昂,并且希望 并行处理 以及 消息的顺序没那么重要 的情况下,这种消息队列是非常合适的选择。不过 JMS/AMQP 风格的消息队列在消费者收到消息后可能会将该消息在消息队列中移除,那么如果此时再加入新的消费者,只能接收到该消费者注册之后的消息了。为了能够消费先前的消息和获得对消息持久化的能力,便提出了基于 日志 的消息队列。
JMS 即Java消息服务(Java Message Service)应用程序接口,是一个 Java 平台中关于面向消息中间件(MOM)的 API,它是一种技术规范。用于在两个应用程序之间,或分布式系统中发送消息,进行异步通信。Java消息服务是一个与具体平台无关的 API,绝大多数 MOM提供商都对 JMS提供支持。
AMQP 的全称是 Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。
3.2 基于日志的消息队列
Apache Kafka 是基于日志的消息队列。日志仅是在磁盘上简单地追加记录消息序列,生产者通过将消息追加到日志末尾来对消息进行持久化,而消费者则通过依次读取日志来接收消息,当消费者读取到日志末尾时,则会等待新消息追加的通知。
为了提高单个磁盘的吞吐量,可以进行分区处理,如下图所示:
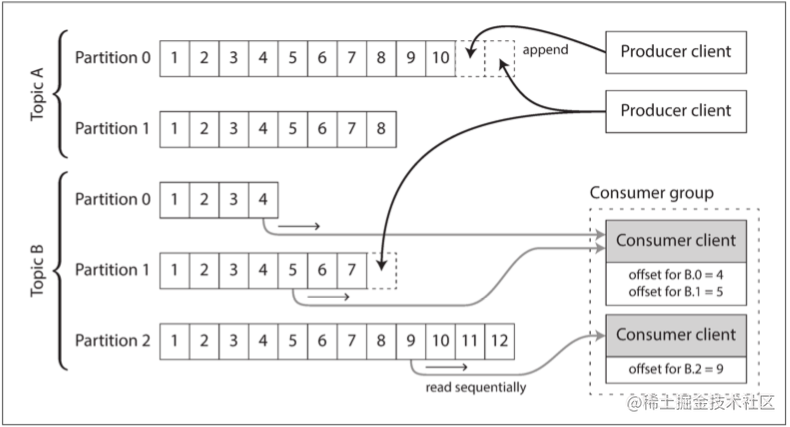
这些分区对应的主题可以理解为携带了一组相同类型消息的分区,不同的分区可以托管在不同的服务器上,这样就使得每个分区都有一份能独立于其他分区进行读写的日志,从而提高吞吐量。
在每个分区中,消息队列为每条消息都会分配一个单调递增的 偏移量,以此来保证消息在分区内的有序,但是并不支持跨分区的顺序保证。消息队列为每个消费者维护一个偏移量即可记录消费者的消费进度,而无需跟踪每一条消息,如果消费者节点失效,则消费者的分区将指派给其他消费者节点,并从最后记录的偏移量开始消费;消费者也可以通过指定偏移量来对先前的消息进行消费,不过如果消费者已经处理了后续的消息,但还没记录它们的偏移量,那么消费者节点发生失效重启后,这些消息将被消费两次。
在消息吞吐量很高,消息能被迅速处理 且 顺序很重要 的情况下,基于日志的消息队列是合适的选择。
3.3 消息的传递模式
当多个消费者从同一主题读取消息时,有两种主要的消息传递模式,如下图所示:

-
负载均衡(load balancing):每个消息只被传递给 消费者之一,所以处理该主题下的消息能被消费者共享。代理可以为消费者任意分配消息,当在处理消息代价比较高昂时,希望能并行处理消息时,此模式非常有用
-
扇出(fan-out):每条消息都被传递给 所有消费者
以上两种模式可以组合使用:两个独立的消费者组可以订阅同一主题,每一组都共同收到所有消息,而在每一组内,只由单个节点来处理消息。
如果采用的是消息队列向消费者 推送 消息的模式,为了确保消息被消费,消费者在消费完消息时需要向消息队列发送确认(ACK),供消息队列判断是否需要超时重传。
当发生消息积压时(生产者发送消息的速率大于消费者消费消息的速率),可以采用如下三种方式解决:
-
丢弃消息
-
为积压的消息创建缓冲区
-
降低生产者发送消息的速率(流量控制)
3.4 消息队列与数据库的差异
我们在前文说过:消息队列是一种 针对消息流而优化的数据库,那么它与数据库又有什么区别呢?
-
在数据的保存机制上:数据库通常保留数据直至显式删除;基于 JMS/AMQP 标准的消息队列在消息成功发送给消费者时会自动删除消息,基于日志的消息队列会在磁盘中以日志的形式对消息做持久化处理
-
数据搜索方式上:数据库通常支持次级索引和各种搜索数据的方式;消息队列通常支持按照某种模式匹配主题,订阅其子集。虽然机制并不一样,但对于客户端来说都是选择想要了解数据的一部分
-
查询结果的时效上:查询数据库时,结果通常基于某个时间点的数据快照,如果另一个客户端随后向数据库写入一些改变了查询结果的内容,则第一个客户端不会发现其先前结果现已过期(快照隔离);消息队列不支持任意查询,当数据发生变化时(即新消息可用时),它们会通知客户端
巨人的肩膀
- 《数据密集型应用系统设计》:第十一章 流处理