顺序读场景
intmain
{
charc[ 4096];
intin = -1;
in = open( "news.txt", O_RDONLY);
intindex= 0;
while(read(in, &c, 4096) == 4096)
{
printf( "index: %d,len: %ld.\n",index, strlen(c));
memset(c, 0, sizeof(c));
index++;
}数据结构
/*
* Track a single file's readahead state
*/
struct file_ra_state {
pgoff_t start; /* where readahead started */
unsigned int size; /* # of readahead pages */
unsigned int async_size; /* do asynchronous readahead when
there are only # of pages ahead */
unsigned int ra_pages; /* Maximum readahead window */
unsigned int mmap_miss; /* Cache miss stat for mmap accesses */
loff_t prev_pos; /* Cache last read() position */
};
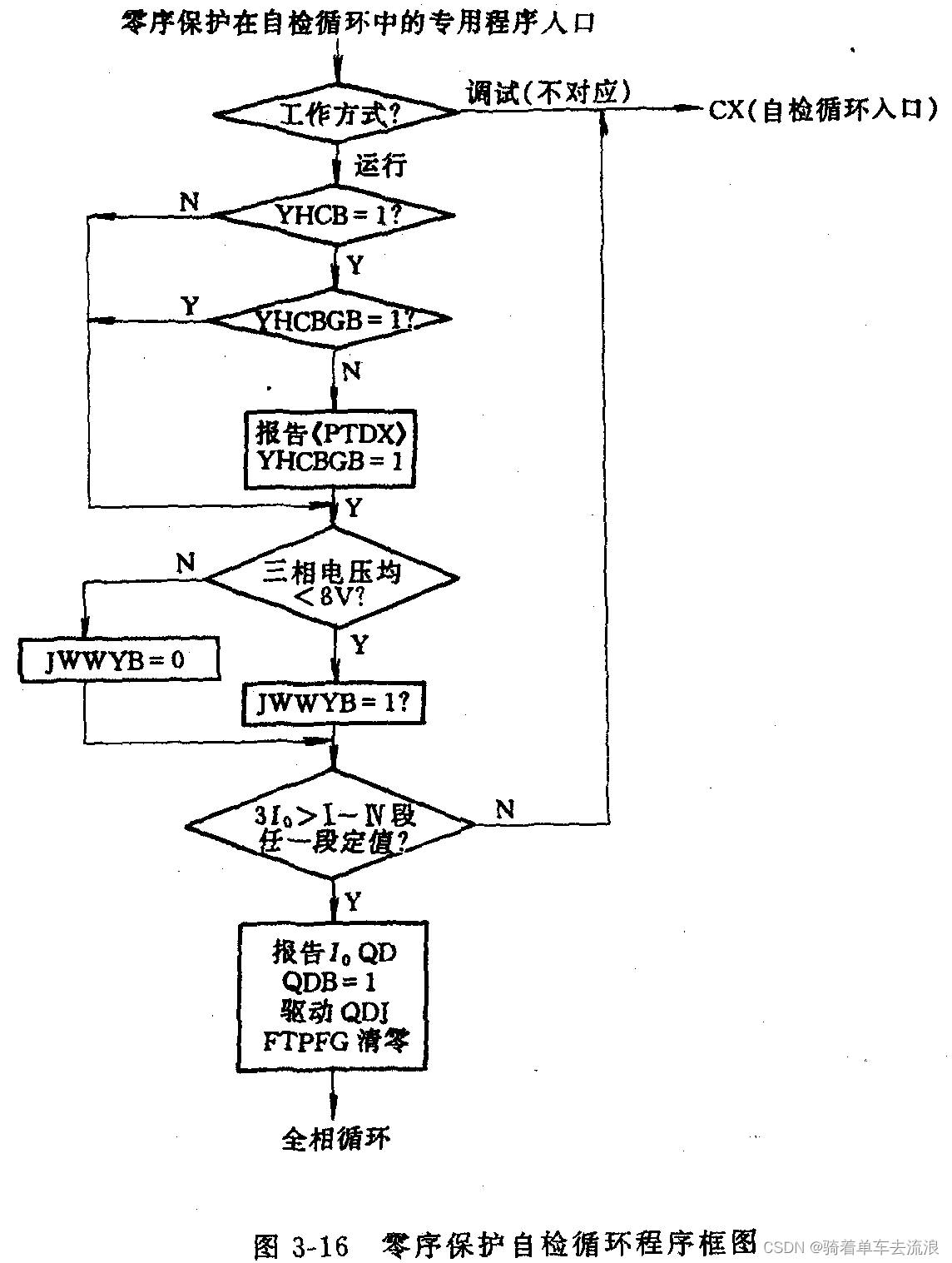
start: 开始预读的数据页索引,是指相对文件内的index。
size : 一共要预读多个少页面。
async_size: 如果当前预读的“存货”只剩async_size时,就会触发async readahead,这个值很重要,控着async readahead的时机。异步读触发时类似网络协议栈的滑动窗口,窗口会移动,也就是file_ra_state字段会更新,具体如何更新见下文。这里async readahead就是指generic_file_buffered_read函数中的:page_cache_async_readahead函数调用
Linux read的核心函数generic_file_buffered_read_nginux的博客-CSDN博客
ra_page: readahead窗口的最大值,类似网络协议栈滑动窗口,这个窗口有最大限制。
prev_pos : 上次读的postion,文件内偏移,主义单位时bytes。
注意:PageReadahead的page非常重要,因为一旦应用程序读取数据到这个page,就要触发异步预读(page_cache_async_readahead)
数据结构初始化:
代码:mm/readahead.c: ondemand_readahead(预读算法的实现函数)
/*
* A minimal readahead algorithm for trivial sequential/random reads.
*/
static void ondemand_readahead(struct address_space *mapping,
struct file_ra_state *ra, struct file *filp,
bool hit_readahead_marker, pgoff_t index,
unsigned long req_size)
{
struct backing_dev_info *bdi = inode_to_bdi(mapping->host);
unsigned long max_pages = ra->ra_pages;
unsigned long add_pages;
pgoff_t prev_index;
/*
* If the request exceeds the readahead window, allow the read to
* be up to the optimal hardware IO size
*/
if (req_size > max_pages && bdi->io_pages > max_pages)
max_pages = min(req_size, bdi->io_pages);
/*
* start of file
*/
if (!index)
goto initial_readahead;
...
initial_readahead:
ra->start = index;
//req_size是指预读请求的大小数据页数量(每个数据页4K)
ra->size = get_init_ra_size(req_size, max_pages);
ra->async_size = ra->size > req_size ? ra->size - req_size : ra->size;
...
//提交文件读取,触发io预读
ra_submit(ra, mapping, filp);
}
/*
* Set the initial window size, round to next power of 2 and square
* for small size, x 4 for medium, and x 2 for large
* for 128k (32 page) max ra
* 1-8 page = 32k initial, > 8 page = 128k initial
*/
//第一个参数:请求读取的数据页数量,比如目前场景每次读取4K字节,size = 1
static unsigned long get_init_ra_size(unsigned long size, unsigned long max)
{
unsigned long newsize = roundup_pow_of_two(size);
//每次读取小于4K bytes, 预读大小是请求大小的4被,比如read(4096), newsize = 1 * 4 = 4;
if (newsize <= max / 32)
newsize = newsize * 4;
//中等读取大小,即1pages < ra <= 8pages,预读大小设置成请求大小的2倍
//比如read(4K) newsize = 4 * 2 = 8
else if (newsize <= max / 4)
newsize = newsize * 2;
//大的读取大小,即每次读取大于8 pages,比如read(64K) newsize = max = 32 pages
else
newsize = max;
return newsize;
}根据《Linux read的核心函数generic_file_buffered_read_nginux的博客-CSDN博客》文章我们知道,顺序读取大概调用逻辑:
1. 触发同步预读(sync readahead)
2.异步异步读取(async readahead)
首次同步预读 - sync readahead
调用路径:generic_file_buffered_read
-->page_cache_sync_readahead
-->ondemand_readahead : intial_readahead
--->ra_submit 向block layer请求io预读
首次文件头读进入ondemand_readahead的initial_readahead逻辑,计算file_ra_state值:
ra->start = 0; 因为是从文件头开始读取
ra->size = 4;
ra->async_size = 3;
ra->ra_pages = 32;
ra->prev_pos = -1;
根据ondemand_readahead中initial_readahead label处逻辑看,ra->size是由get_init_ra_size函数计算,该函数第一个参数是应用read的数据页(每个数据页4K)的数量,该场景每次读取4K bytes,相当于调用get_init_ra_size(1,32)返回4。
ra_submit向block layer请求io预读
/*
* Submit IO for the read-ahead request in file_ra_state.
*/
static inline void ra_submit(struct file_ra_state *ra,
struct address_space *mapping, struct file *filp)
{
__do_page_cache_readahead(mapping, filp,
ra->start, ra->size, ra->async_size);
}
/*
* __do_page_cache_readahead() actually reads a chunk of disk. It allocates
* the pages first, then submits them for I/O. This avoids the very bad
* behaviour which would occur if page allocations are causing VM writeback.
* We really don't want to intermingle reads and writes like that.
*/
void __do_page_cache_readahead(struct address_space *mapping,
struct file *file, pgoff_t index, unsigned long nr_to_read,
unsigned long lookahead_size)
{
struct inode *inode = mapping->host;
loff_t isize = i_size_read(inode);
pgoff_t end_index; /* The last page we want to read */
if (isize == 0)
return;
end_index = (isize - 1) >> PAGE_SHIFT;
if (index > end_index)
return;
/* Don't read past the page containing the last byte of the file */
if (nr_to_read > end_index - index)
nr_to_read = end_index - index + 1;
page_cache_readahead_unbounded(mapping, file, index, nr_to_read,
lookahead_size);
}
static inline gfp_t readahead_gfp_mask(struct address_space *x)
{
return mapping_gfp_mask(x) | __GFP_NORETRY | __GFP_NOWARN;
}
/**
* page_cache_readahead_unbounded - Start unchecked readahead.
* @mapping: File address space.
* @file: This instance of the open file; used for authentication.
* @index: First page index to read.
* @nr_to_read: The number of pages to read.
* @lookahead_size: Where to start the next readahead.
*
* This function is for filesystems to call when they want to start
* readahead beyond a file's stated i_size. This is almost certainly
* not the function you want to call. Use page_cache_async_readahead()
* or page_cache_sync_readahead() instead.
*
* Context: File is referenced by caller. Mutexes may be held by caller.
* May sleep, but will not reenter filesystem to reclaim memory.
*/
void page_cache_readahead_unbounded(struct address_space *mapping,
struct file *file, pgoff_t index, unsigned long nr_to_read,
unsigned long lookahead_size)
{
LIST_HEAD(page_pool);
//注意这里添加了__GFP_NORETRY | __GFP_NOWARN,page内存申请不会进入慢路径
gfp_t gfp_mask = readahead_gfp_mask(mapping);
struct readahead_control rac = {
.mapping = mapping,
.file = file,
._index = index,
};
unsigned long i;
/*
* Partway through the readahead operation, we will have added
* locked pages to the page cache, but will not yet have submitted
* them for I/O. Adding another page may need to allocate memory,
* which can trigger memory reclaim. Telling the VM we're in
* the middle of a filesystem operation will cause it to not
* touch file-backed pages, preventing a deadlock. Most (all?)
* filesystems already specify __GFP_NOFS in their mapping's
* gfp_mask, but let's be explicit here.
*/
unsigned int nofs = memalloc_nofs_save();
/*
* Preallocate as many pages as we will need.
*/
for (i = 0; i < nr_to_read; i++) {
struct page *page = xa_load(&mapping->i_pages, index + i);
BUG_ON(index + i != rac._index + rac._nr_pages);
if (page && !xa_is_value(page)) {
/*
* Page already present? Kick off the current batch
* of contiguous pages before continuing with the
* next batch. This page may be the one we would
* have intended to mark as Readahead, but we don't
* have a stable reference to this page, and it's
* not worth getting one just for that.
*/
read_pages(&rac, &page_pool, true);
continue;
}
page = __page_cache_alloc(gfp_mask);
if (!page)
break;
if (mapping->a_ops->readpages) {
page->index = index + i;
list_add(&page->lru, &page_pool);
} else if (add_to_page_cache_lru(page, mapping, index + i,
gfp_mask) < 0) {
put_page(page);
read_pages(&rac, &page_pool, true);
continue;
}
//设置PageReadahead标志,非常重要
if (i == nr_to_read - lookahead_size)
SetPageReadahead(page);
rac._nr_pages++;
}
/*
* Now start the IO. We ignore I/O errors - if the page is not
* uptodate then the caller will launch readpage again, and
* will then handle the error.
*/
read_pages(&rac, &page_pool, false);
memalloc_nofs_restore(nofs);
}上面由于预读了4个页面,所以下次generic_file_buffered_read for(;;)循环中find_get_page会找到cache page(因为被预读进cache中了),循环继续,每次循环增加index值,由于index增加,就会触发PageReadahead(page),进而调用page_cache_async_readahead:
这种设计是因为不能一直预读,因为预读失败会受到惩罚(浪费内存),而是要根据应用顺序读取到一定程度才进行新的预读,这个时机就是应用读取到PageReadahead(page)对应的page。page_cache_async_readahead-->ondemand_readahead触发新的“异步”预读:
/*
* A minimal readahead algorithm for trivial sequential/random reads.
*/
static void ondemand_readahead(struct address_space *mapping,
struct file_ra_state *ra, struct file *filp,
bool hit_readahead_marker, pgoff_t index,
unsigned long req_size)
{
struct backing_dev_info *bdi = inode_to_bdi(mapping->host);
unsigned long max_pages = ra->ra_pages;
unsigned long add_pages;
pgoff_t prev_index;
/*
* If the request exceeds the readahead window, allow the read to
* be up to the optimal hardware IO size
*/
if (req_size > max_pages && bdi->io_pages > max_pages)
max_pages = min(req_size, bdi->io_pages);
/*
* start of file
*/
if (!index)
goto initial_readahead;
/*
* It's the expected callback index, assume sequential access.
* Ramp up sizes, and push forward the readahead window.
*/
//@1
if ((index == (ra->start + ra->size - ra->async_size) ||
index == (ra->start + ra->size))) {
ra->start += ra->size;
ra->size = get_next_ra_size(ra, max_pages);
ra->async_size = ra->size;
goto readit;
}
/*
* Hit a marked page without valid readahead state.
* E.g. interleaved reads.
* Query the pagecache for async_size, which normally equals to
* readahead size. Ramp it up and use it as the new readahead size.
*/
//@2 没有命中@1,比如没有完整顺序读的情况,刚好跳过了@1中的条件
if (hit_readahead_marker) {
pgoff_t start;
rcu_read_lock();
start = page_cache_next_miss(mapping, index + 1, max_pages);
rcu_read_unlock();
if (!start || start - index > max_pages)
return;
ra->start = start;
ra->size = start - index; /* old async_size */
ra->size += req_size;
ra->size = get_next_ra_size(ra, max_pages);
ra->async_size = ra->size;
goto readit;
}
/*
* oversize read
*/
if (req_size > max_pages)
goto initial_readahead;
/*
* sequential cache miss
* trivial case: (index - prev_index) == 1
* unaligned reads: (index - prev_index) == 0
*/
prev_index = (unsigned long long)ra->prev_pos >> PAGE_SHIFT;
if (index - prev_index <= 1UL)
goto initial_readahead;
/*
* Query the page cache and look for the traces(cached history pages)
* that a sequential stream would leave behind.
*/
if (try_context_readahead(mapping, ra, index, req_size, max_pages))
goto readit;
/*
* standalone, small random read
* Read as is, and do not pollute the readahead state.
*/
//@3随机读取,倒数第二个参数代表只读取用户要求数量的page数量,最后一个参数0代表不进行
//预读
__do_page_cache_readahead(mapping, filp, index, req_size, 0);
return;
initial_readahead:
ra->start = index;
ra->size = get_init_ra_size(req_size, max_pages);
ra->async_size = ra->size > req_size ? ra->size - req_size : ra->size;
readit:
/*
* Will this read hit the readahead marker made by itself?
* If so, trigger the readahead marker hit now, and merge
* the resulted next readahead window into the current one.
* Take care of maximum IO pages as above.
*/
if (index == ra->start && ra->size == ra->async_size) {
add_pages = get_next_ra_size(ra, max_pages);
if (ra->size + add_pages <= max_pages) {
ra->async_size = add_pages;
ra->size += add_pages;
} else {
ra->size = max_pages;
ra->async_size = max_pages >> 1;
}
}
ra_submit(ra, mapping, filp);
}@1:对应顺序读取命中预读,比如我们当前场景预读了4个page,当读取到index = 1第二个page的时候就会命中该逻辑,会将“预读窗口”向前移动。
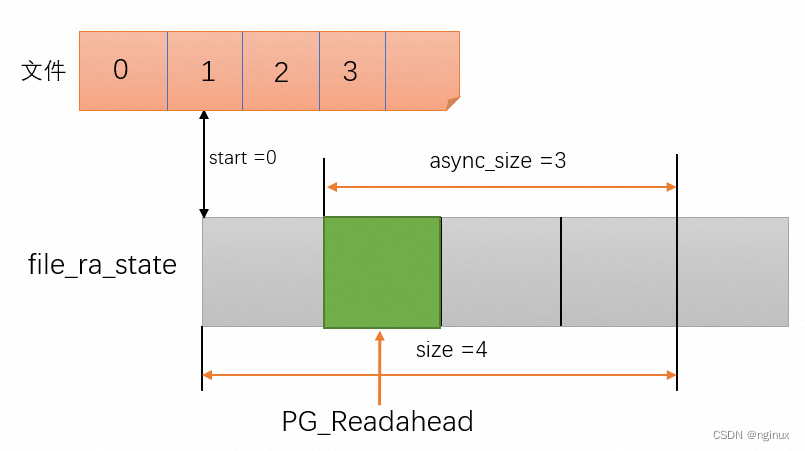
满足index == (ra->start + ra->size - ra->async_size)条件,所以向前移动预读窗口:
//start = 4
ra->start += ra->size;
//根据get_next_ra_size函数,其中cur = ra->size = 4,所以return max =32,直接将预读窗口放大到了最大32
ra->size = get_next_ra_size(ra, max_pages);
//async_size = ra->size
ra->async_size = ra->size;
/*
* Get the previous window size, ramp it up, and
* return it as the new window size.
*/
static unsigned long get_next_ra_size(struct file_ra_state *ra,
unsigned long max)
{
unsigned long cur = ra->size;
if (cur < max / 16)
return 4 * cur;
if (cur <= max / 2)
return 2 * cur;
return max;
}@2:没有触发1,但是触发异步readahead逻辑,同样继续新的预读逻辑,这里考虑到了多线程同时读一个文件的情况,ra结构体要在多线程之间完成状态切换,可看参考文章《Linux文件预读三》
参考文章:
Linux文件系统预读(一) - 知乎
Linux文件系统预读(二) - 知乎
Linux文件预读(三) - 知乎
深入分析Linux内核File cache机制(上篇) - 知乎





![[RISC-V]Milk-V开发板 i2c测试oled及波形输出](https://img-blog.csdnimg.cn/041b873d9a2c415a99d21a57dfdbc327.png)