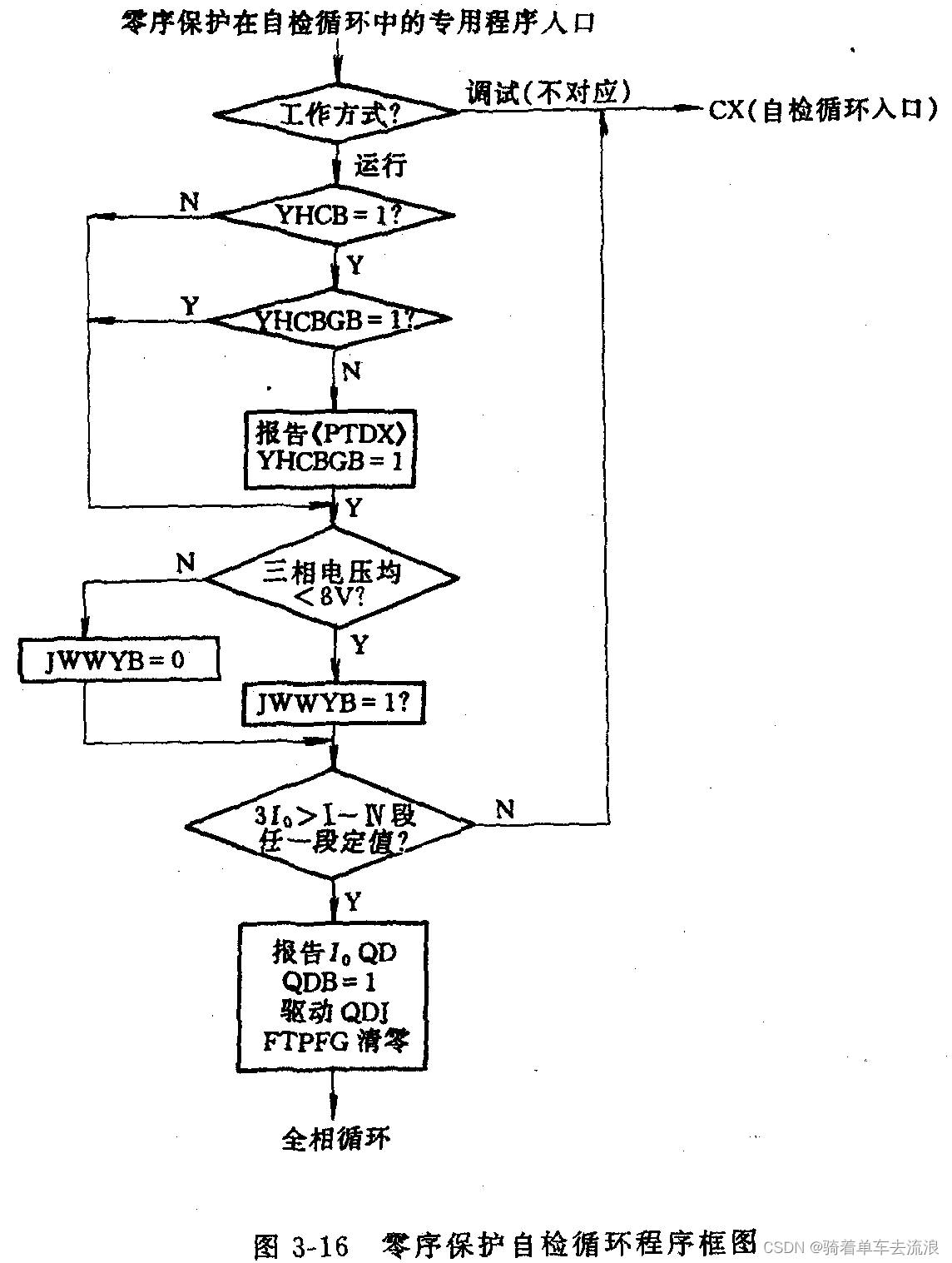
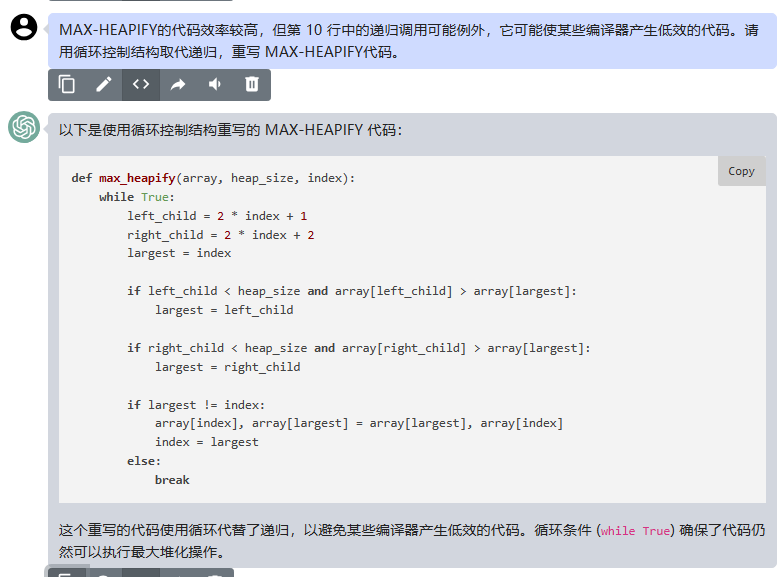
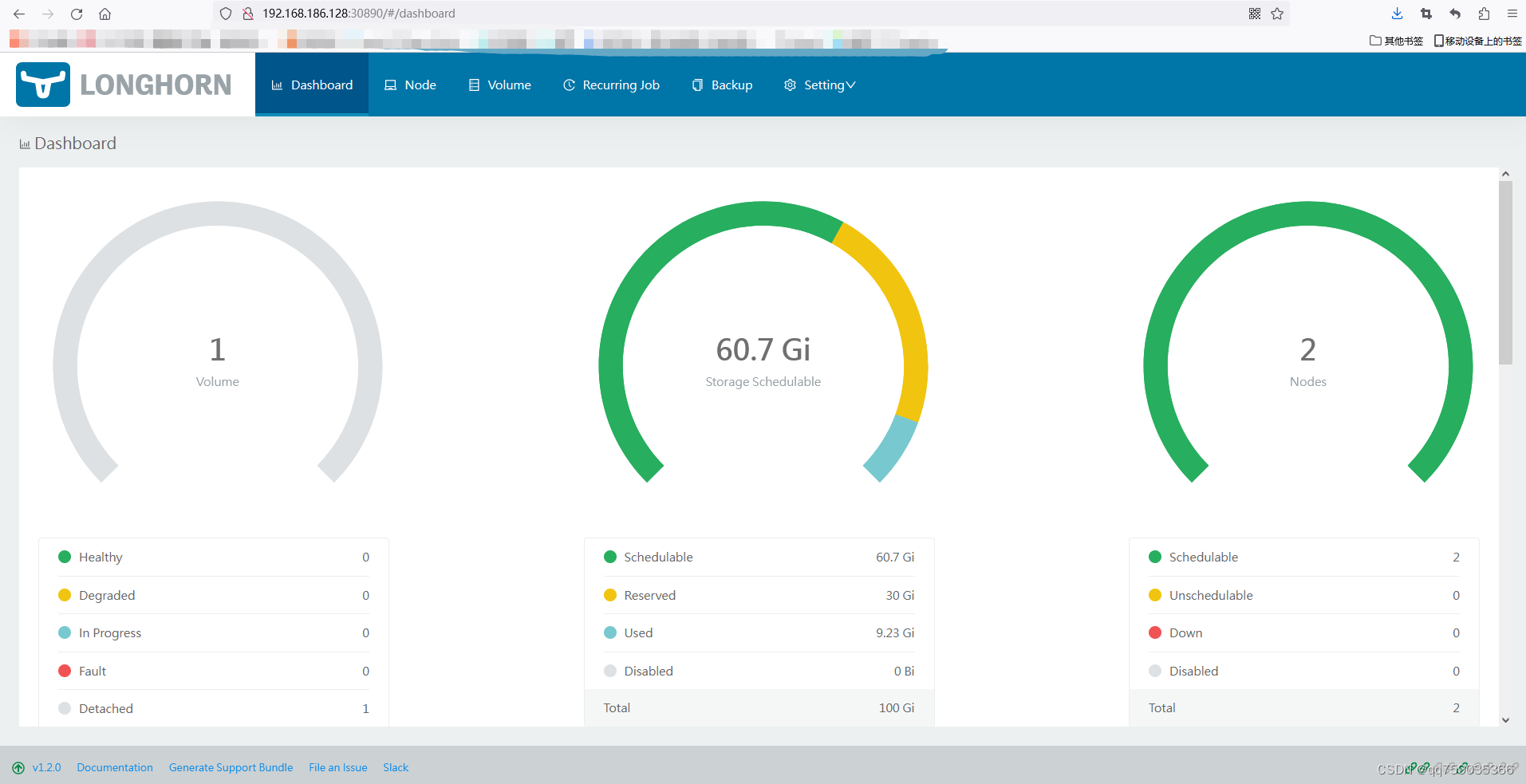
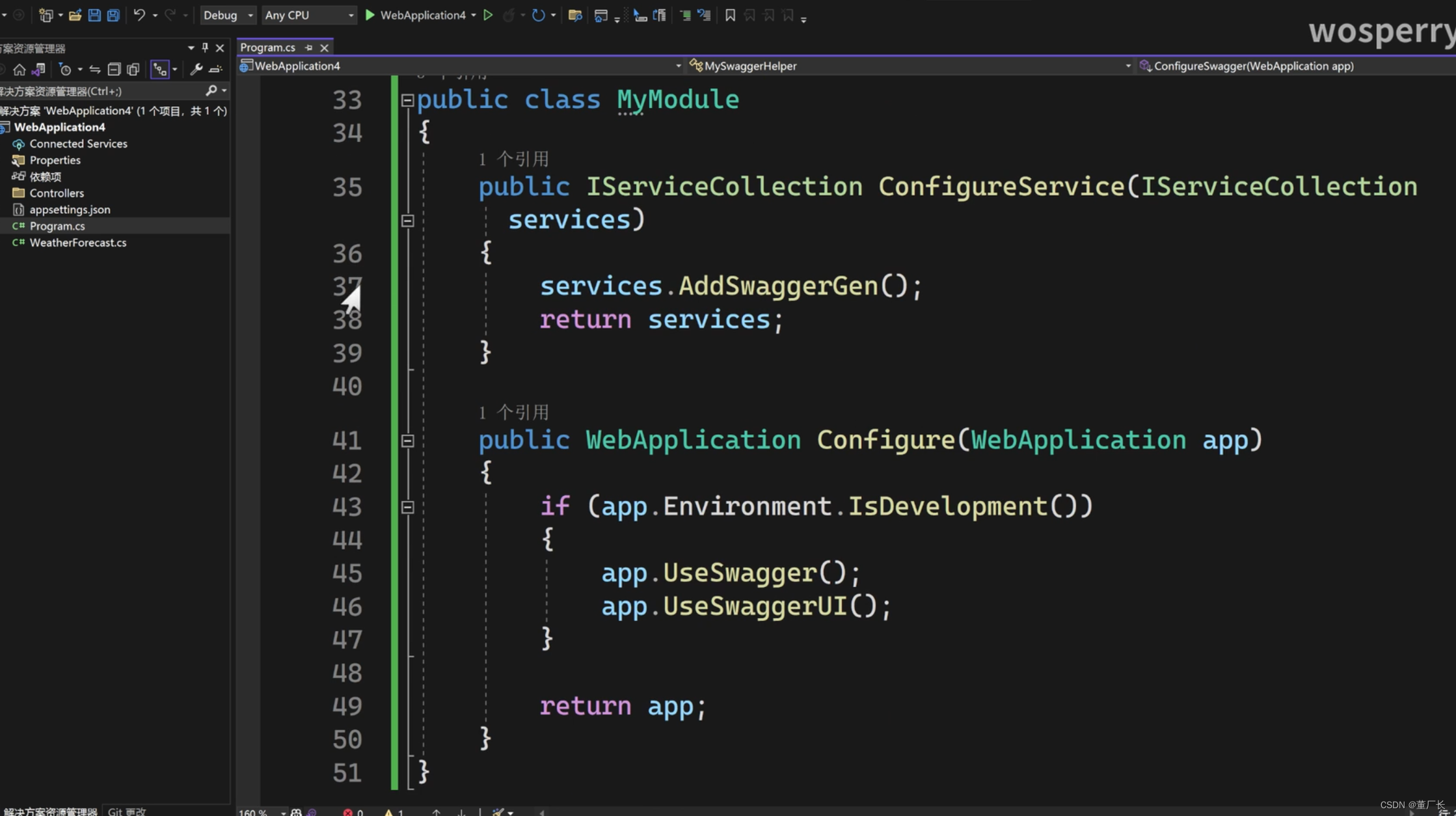
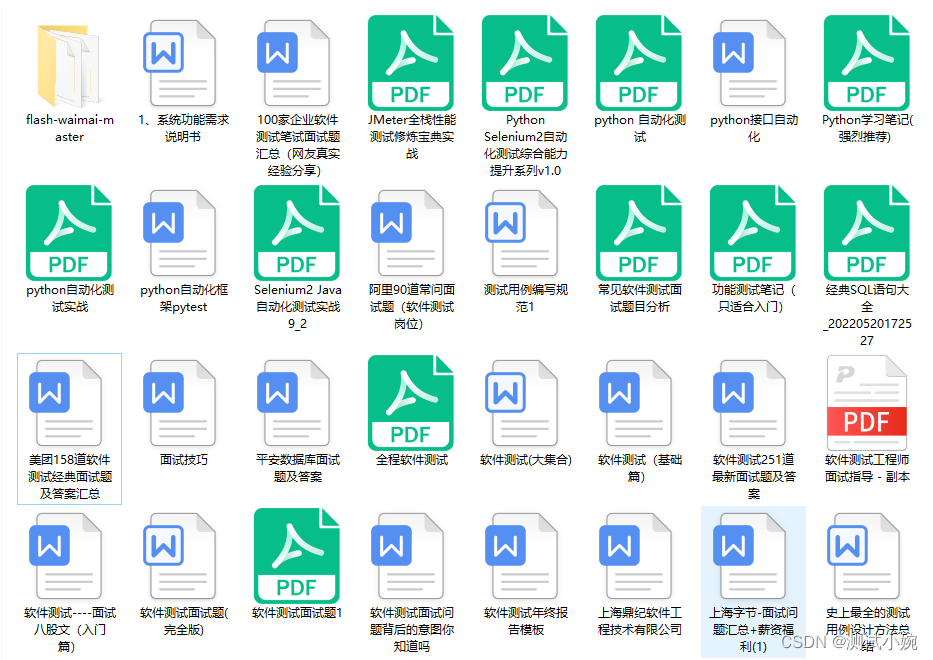
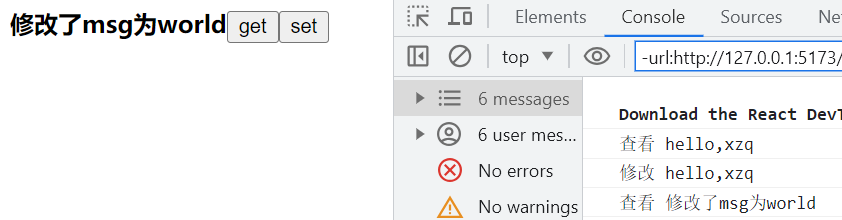
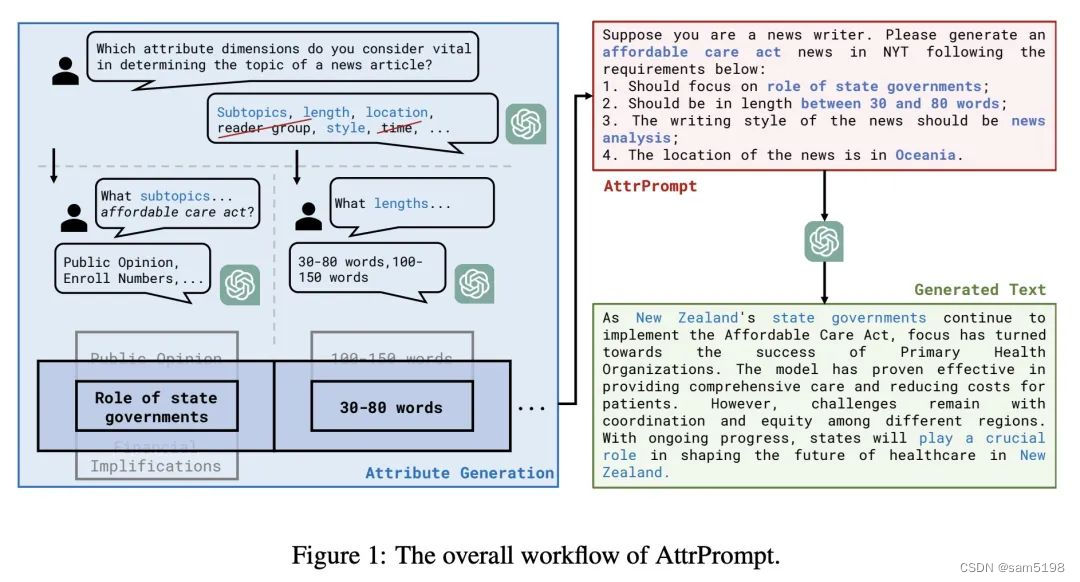
大型语言模型作为属性化训练数据生成器,提出一种使用多样化属性提示的数据生成方法,可以生成具有多样性和属性的训练数据,从而提高了模型的性能和数据生成的效率。
动机:大型语言模型(LLM)最近被用作各种自然语言处理(NLP)任务的训练数据生成器。然而,其通常依赖于简单的类条件提示,这可能限制了生成数据的多样性并继承了LLM的系统偏差。因此,本文研究了使用多样化属性提示(例如,指定长度和风格等属性)进行训练数据生成,有可能产生多样化和具有属性的生成数据。
方法:提出一种使用多样化属性提示的数据生成方法。对于给定的分类任务,首先通过LLM的帮助,以交互式、半自动化的方式识别属性维度及其对应的属性值。然后,通过随机组合属性来生成多样化的提示,替换了通常用于从LLM查询数据的简单类条件提示。
优势:在四个分类任务上,通过测量使用两种情况下训练的模型的性能来实证评估生成的数据集:1)仅在生成的数据集上,和2)在包含真实训练集和生成集的合并数据集上。在这两种情况下,使用AttrPrompt生成的数据集明显优于使用SimPrompt生成的数据集。此外,还展示了AttrPrompt在数据/预算效率和与不同模型大小/各种LLM作为训练数据生成器方法的兼容性方面优于SimPrompt的优势。
去年 2 月份,DeepMind 发布了编程辅助利器 AlphaCode。它使用人工智能技术来帮助程序员更快地编写代码,可以自动完成代码、提供代码建议并检查错误,从而提高编程效率。AlphaCode 的问世意味着 AI 在解决现实世界问题的道路上又迈出了一大步。
巧合的是,在同一天,OpenAI 也展示了一项重要成果:他们开发的神经定理证明器成功解出了两道国际奥数题。这一成果是在微软打磨了多年的数学 AI——Lean 的基础上完成的。Lean 于 2013 年推出,数学家可以把数学公式转换成代码,再输入到 Lean 中,让程序来验证定理是否正确。OpenAI 的成功表明,AI 不仅可以用于解决编程等应用学科的问题,还能用来攻克数学等自然学科。
值得注意的是,这并不是 AI 研究者的「一厢情愿」。就像快速接受 AlphaCode 的软件工程师一样,数学家也在越来越频繁地使用 AI,比如获得过菲尔茨奖的陶哲轩。他甚至预言,到 2026 年,AI 将成为数学研究领域可信赖的合著者(co-author)。
与此同时,主攻数学问题的 AI 也在不断发展壮大:一个名为 LeanDojo 的开放平台提供了一套基于大型语言模型的开源定理证明器,消除了在机器学习方法用于定理证明时存在的私有代码、数据和大量计算需求等障碍,为机器学习方法在定理证明领域的研究提供了便利。
「我相信,数学将成为第一门通过人工智能实现重大突破的学科。」在看到这些进展之后,英伟达高级 AI 研究科学家 Jim Fan 在一篇推特中预言说。

![[RISC-V]Milk-V开发板 i2c测试oled及波形输出](https://img-blog.csdnimg.cn/041b873d9a2c415a99d21a57dfdbc327.png)