目录
伙伴系统的核心数据结构
总结:
到底什么是伙伴
伙伴系统的内存分配原理
伙伴系统的内存回收原理
伙伴系统的实现
从 CPU 高速缓存列表中获取内存页
伙伴系统的核心数据结构

如上图所示,内核会为 NUMA 节点中的每个物理内存区域 zone 分配一个伙伴系统用于管理该物理内存区域 zone 里的空闲内存页。而伙伴系统的核心数据结构就封装在 struct zone 里。
struct zone {
// 被伙伴系统所管理的物理内存页个数
atomic_long_t managed_pages;
// 伙伴系统的核心数据结构
struct free_area free_area[MAX_ORDER];
}
数组 free_area[MAX_ORDER] 中的索引表示的就是分配阶 order,用于指定对应双向链表组织管理的内存块包含多少个 page。
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};struct free_area 主要描述的就是相同尺寸的内存块在伙伴系统中的组织结构, nr_free 则表示的是该尺寸的内存块在当前伙伴系统中的个数,这个值会随着内存的分配而减少,随着内存的回收而增加。
nr_free 表示的可不是空闲内存页 page 的个数,而是空闲内存块的个数,对于 0 阶的内存块来说 nr_free 确实表示的是单个内存页 page 的个数,因为 0 阶内存块是由一个 page 组成的,但是对于 1 阶内存块来说,nr_free 则表示的是 2 个 page 集合的个数,以此类推对于 n 阶内存块来说,nr_free 表示的是 2 的 n 次方 page 集合的个数
这些相同尺寸的内存块在 struct free_area 结构中是通过 struct list_head 结构类型的双向链表统一组织起来的。
按理来说,内核只需要将这些相同尺寸的内存块在 struct free_area 中用一个双向链表串联起来就行了。
但是我们从源码中却看到内核是用多个双向链表来组织这些相同尺寸的内存块的,这些双向链表组成一个数组 free_list[MIGRATE_TYPES],该数组中双向链表的个数为 MIGRATE_TYPES。
我们从 MIGRATE_TYPES 的字面意思上可以看出,内核会根据物理内存页的迁移类型将这些相同尺寸的内存块近一步通过不同的双向链表重新组织起来。
free_area 是将相同尺寸的内存块组织起来,free_list 是在 free_area 的基础上近一步根据页面的迁移类型将这些相同尺寸的内存块划分到不同的双向链表中管理
enum migratetype {
MIGRATE_UNMOVABLE, // 不可移动
MIGRATE_MOVABLE, // 可移动
MIGRATE_RECLAIMABLE, // 可回收
MIGRATE_PCPTYPES, // 属于 CPU 高速缓存中的类型,PCP 是 per_cpu_pageset 的缩写
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES, // 紧急内存
#ifdef CONFIG_CMA
MIGRATE_CMA, // 预留的连续内存 CMA
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE, /* can't allocate from here */
#endif
MIGRATE_TYPES // 不代表任何区域,只是单纯表示一共有多少个迁移类型
};总结:
struct zone {
// 被伙伴系统所管理的物理页数
atomic_long_t managed_pages;
// 伙伴系统的核心数据结构
struct free_area free_area[MAX_ORDER];
}
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};首先伙伴系统会将物理内存区域 zone 中的空闲内存页按照分配阶 order 将相同尺寸的内存块组织在 free_area[MAX_ORDER] 数组中:随后在 struct free_area 结构中伙伴系统近一步根据这些相同尺寸内存块的页面迁移类型 MIGRATE_TYPES,将相同迁移类型的物理页面组织在 free_list[MIGRATE_TYPES] 数组中,最终形成了完整的伙伴系统结构。
enum migratetype {
MIGRATE_UNMOVABLE, // 不可移动
MIGRATE_MOVABLE, // 可移动
MIGRATE_RECLAIMABLE, // 可回收
MIGRATE_PCPTYPES, // 属于 CPU 高速缓存中的类型,PCP 是 per_cpu_pageset 的缩写
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES, // 紧急内存
#ifdef CONFIG_CMA
MIGRATE_CMA, // 预留的连续内存 CMA
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE, /* can't allocate from here */
#endif
MIGRATE_TYPES // 不代表任何区域,只是单纯表示一共有多少个迁移类型
};
到底什么是伙伴
内核中的伙伴指的是大小相同并且在物理内存上是连续的两个或者多个 page。

上图中的 page0 和 page 1 是伙伴,page2 到 page 5 是伙伴,page6 和 page7 又是伙伴。但是 page0 和 page2 就不能成为伙伴,因为它们的物理内存是不连续的。同时 (page0 到 page3) 和 (page4 到 page7) 所组成的两个内存块又能构成一个伙伴。伙伴必须是大小相同并且在物理内存上是连续的两个或者多个 page。
伙伴系统的内存分配原理
如下四个内存分配的接口,内核可以通过这些接口向伙伴系统申请内存:
struct page *alloc_pages(gfp_t gfp, unsigned int order)
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
unsigned long get_zeroed_page(gfp_t gfp_mask)
unsigned long __get_dma_pages(gfp_t gfp_mask, unsigned int order)
首先我们可以根据内存分配接口函数中的 gfp_t gfp_mask ,找到内存分配指定的 NUMA 节点和物理内存区域 zone ,然后找到物理内存区域 zone 对应的伙伴系统。
随后内核通过接口中指定的分配阶 order,可以定位到伙伴系统的 free_area[order] 数组,其中存放的就是分配阶为 order 的全部内存块。
最后内核进一步通过 gfp_t gfp_mask 掩码中指定的页面迁移类型 MIGRATE_TYPE,定位到 free_list[MIGRATE_TYPE],这里存放的就是符合内存分配要求的所有内存块。通过遍历这个双向链表就可以轻松获得要分配的内存。
举个例子

我们假设当前伙伴系统中只有 order = 3 的空闲链表 free_area[3],其余剩下的分配阶 order 对应的空闲链表中均是空的。 free_area[3] 中仅有一个空闲的内存块,其中包含了连续的 8 个 page。
现在我们向伙伴系统申请一个 page 大小的内存(对应的分配阶 order = 0),那么内核会在伙伴系统中首先查看 order = 0 对应的空闲链表 free_area[0] 中是否有空闲内存块可供分配。
随后内核会根据前边介绍的内存分配逻辑,继续升级到 free_area[1] , free_area[2] 链表中寻找空闲内存块,直到查找到 free_area[3] 发现有一个可供分配的内存块。这个内存块中包含了 8 个 连续的空闲 page,但是我们只要一个 page 就够了,那该怎么办呢?
于是内核先将 free_area[3] 中的这个空闲内存块从链表中摘下,然后减半分裂成两个内存块,分裂出来的这两个内存块分别包含 4 个 page(分配阶 order = 2)。
现在我们加上了内存 MIGRATE_TYPES 的组织结构,其实分配流程还是和核心流程一样的,只不过上面提到的那些高阶 order 的减半分裂情形都发生在各个 free_area[order] 中固定的 free_list[MIGRATE_TYPE] 里罢了。
比如我们要求分配的内存迁移属性要求是 MIGRATE_MOVABLE 类型,那么减半分裂流程分别发生在 free_area[2] ,free_area[1] ,free_area[0] 对应的 free_list[MIGRATE_MOVABLE] 中,多了一个 free_list 的维度,仅此而已。
不过笔者这里想重点着墨的地方是内存分配的一种异常情形,比如我们想要分配特定迁移类型的内存,但是当前伙伴系统所有 free_area[order] 里对应的 free_list[MIGRATE_TYPE] 均无法满足内存分配的需求(没有足够特定迁移类型的空闲内存块)。那么这种场景下内核会怎么处理呢?
当时笔者介绍内存 NUMA 架构的时候提到,如果当前 NUMA 节点无法满足内存分配时,内核会跨越 NUMA 节点从其他节点上分配内存。
typedef struct pglist_data {
// NUMA 节点中的物理内存区域个数
int nr_zones;
// NUMA 节点中的物理内存区域
struct zone node_zones[MAX_NR_ZONES];
// NUMA 节点的备用列表
struct zonelist node_zonelists[MAX_ZONELISTS];
} pg_data_t;每个 NUMA 节点的 struct pglist_data 结构中都会包含一个 node_zonelists,其中包含了当前NUMA 节点以及备用 NUMA 节点的所有内存区域以及对应的伙伴系统,当前 NUMA 节点内存不足时,内核会从 node_zonelists 中的备用 NUMA 节点中分配内存。
正常的分配流程先是从低阶到高阶依次查找空闲内存块,然后将高阶中的内存块依次减半分裂到低阶 free_list 链表中。
内存分配 fallback 流程(从其他节点分配内存)则刚好是相反的,它是先从备用 fallback 类型的迁移列表中的最高阶开始查找,找到一块空闲内存块之后,先迁移到最初指定的 free_list[MIGRATE_TYPE] 链表中,然后在指定的 free_list[MIGRATE_TYPE] 链表执行减半分裂。
内核这里的 fallback 策略是:如果无法避免分配迁移类型不同的内存块,那么就分配一个尽可能大的内存块(从最高阶开始查找),避免向其他链表引入内存碎片。
当我们向伙伴系统申请 MIGRATE_UNMOVABLE 迁移类型的内存时,假设内核在伙伴系统中的 free_area[0] 到 free_area[10] 中的所有 free_list[MIGRATE_UNMOVABLE] 链表中均无法找到一个空闲的内存块。
那么就会 fallback 到 MIGRATE_RECLAIMABLE 类型,从最高阶 free_area[10] 中的 free_list[MIGRATE_RECLAIMABLE] 链表开始查找,如果找到一个空闲的内存块,则首先会迁移到对应的 order 的 free_list[MIGRATE_UNMOVABLE] 链表,然后流程继续回到核心流程,在各个 free_area[order] 对应的 free_list[MIGRATE_UNMOVABLE] 链表中执行减半分裂。
伙伴系统的内存回收原理
伙伴系统中的内存回收刚好和内存分配的过程相反,核心则是从低阶 free_list 中寻找释放内存块的伙伴,如果没有伙伴则将要释放的内存块插入到对应分配阶 order 的 free_list中。如果存在伙伴,则将释放内存块与它的伙伴合并,作为一个新的内存块继续到更高阶的 free_list 中循环重复上述过程,直到不能合并为止
内存分配是从高阶先查找到空闲内存块,然后依次减半分裂,将分裂后的内存块插入到低阶的 free_list 中,将最后分裂出来的内存块分配给进程。
内存释放是先从低阶开始查找释放内存块的伙伴,如果找到,则两两合并成一个新的内存块,随后继续到高阶中去查找新内存块的伙伴,直到没有伙伴可以合并。
举个例子:
最初的伙伴系统视角:

物理页视角:

有了这些基本概念之后,我回过头来在看 page10 释放回伙伴系统的整个过程:

由于我们要释放的内存块只包含了一个物理内存页 page10,所以它的分配阶 order = 0,首先内核需要在伙伴系统 free_area[0] 中查找与 page10 大小相等并且连续的内存块(伙伴)。
从物理内存的真实视图中我们可以看到 page11 是 page10 的伙伴,于是将 page11 从 free_area[0] 上摘下并与 page10 合并组成一个新的内存块(分配阶 order = 1)。随后内核会在 free_area[1] 中查找新内存块的伙伴:

我们继续对比物理内存页的真实视图,发现在 free_area[1] 中 page8 和 page9 组成的内存块与 page10 和 page11 组成的内存块是伙伴,于是继续将这两个内存块(分配阶 order = 1)继续合并成一个新的内存块(分配阶 order = 2)。随后内核会在 free_area[2] 中查找新内存块的伙伴:

继续对比物理内存页的真实视图,发现在 free_area[2] 中 page12,page13,page14,page15 组成的内存块与 page8,page9,page10,page11 组成的新内存块是伙伴,于是将它们从 free_area[2] 上摘下继续合并成一个新的内存块(分配阶 order = 3),随后内核会在 free_area[3] 中查找新内存块的伙伴:

最后:

内存分配是从高阶先查找到空闲内存块,然后依次减半分裂,将分裂后的内存块插入到低阶的 free_list 中,将最后分裂出来的内存块分配给进程。
内存释放是先从低阶开始查找释放内存块的伙伴,如果找到,则两两合并成一个新的内存块,随后继续到高阶中去查找新内存块的伙伴,直到没有伙伴可以合并。
伙伴系统的实现

现在内核通过前边介绍的 get_page_from_freelist 函数,循环遍历 zonelist 终于找到了符合内存分配条件的物理内存区域 zone。接下来就会通过 rmqueue 函数进入到该物理内存区域 zone 对应的伙伴系统中实际分配物理内存。
从 CPU 高速缓存列表中获取内存页
内核对只分配一页物理内存的情况做了特殊处理,当只请求一页内存时,内核会借助 CPU 高速缓存冷热页列表 pcplist 加速内存分配的处理,此时分配的内存页将来自于 pcplist 而不是伙伴系统。pcp 是 per_cpu_pageset 的缩写,内核会为每个 CPU 分配一个高速缓存列表。
在 NUMA 内存架构下,每个物理内存区域都归属于一个特定的 NUMA 节点,NUMA 节点中包含了一个或者多个 CPU,NUMA 节点中的每个内存区域会关联到一个特定的 CPU 上.
而每个 CPU 都有自己独立的高速缓存,所以每个 CPU 对应一个 per_cpu_pageset 结构,用于管理这个 CPU 高速缓存中的冷热页。
所谓的热页就是已经加载进 CPU 高速缓存中的物理内存页,所谓的冷页就是还未加载进 CPU 高速缓存中的物理内存页,冷页是热页的后备选项
在 Linux 内核中,系统会经常请求和释放单个页面。如果针对每个 CPU,都为其预先分配一个用于缓存单个内存页面的高速缓存页列表,用于满足本地 CPU 发出的单页内存请求,就能提升系统的性能
当内核尝试从 pcplist 中获取一个物理内存页时,会首先获取运行当前进程的 CPU 对应的高速缓存列表 pcplist。然后根据指定的具体页面迁移类型 migratetype 获取对应迁移类型的 pcplist。
pcplist 中缓存的内存页面其实全部来自于伙伴系统,当 pcplist 中的页面数量 count 为 0 (表示此时 pcplist 里没有缓存的页面)时,内核会调用 rmqueue_bulk 从伙伴系统中获取 batch 个物理页面添加到 pcplist,从伙伴系统中获取页面的过程参照本文 "3. 伙伴系统的内存分配原理" 小节中的内容。
随后内核会将 pcplist 中的第一个物理内存页从链表中摘下返回,count 计数减一。
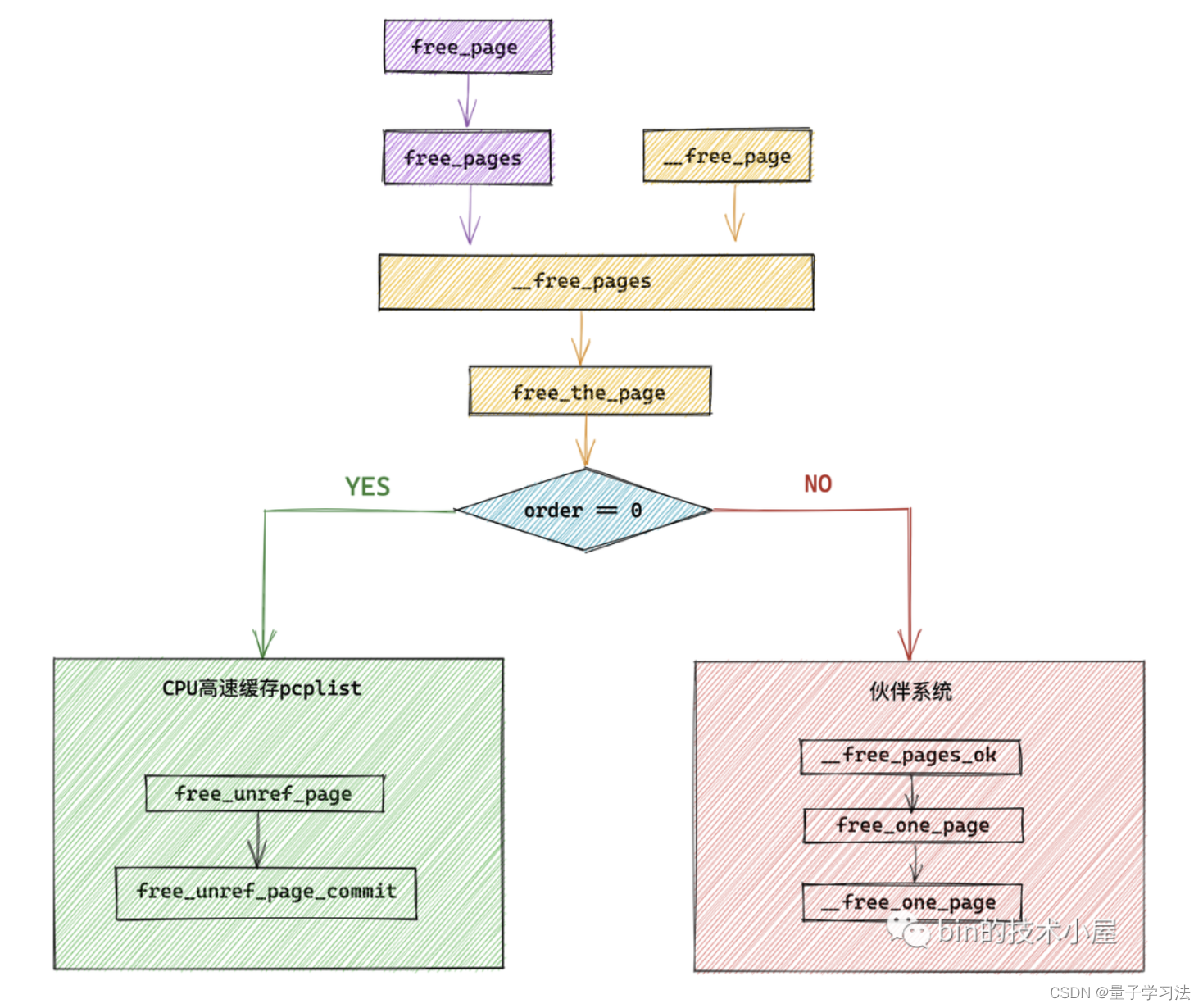
从这里我们看到伙伴系统回收内存的流程和伙伴系统分配内存的流程是一样的,在最开始首先都会检查本次释放或者分配的是否只是一个物理内存页(order = 0),如果是则直接释放到 CPU 高速缓存列表 pcplist 中。如果不是则将内存释放回伙伴系统中。
这里笔者需要强调的是,内核只会将 UNMOVABLE,MOVABLE,RECLAIMABLE 这三种页面迁移类型放入 CPU 高速缓存列表 pcplist 中,其余的迁移类型均需释放回伙伴系统。
如果当前 pcplist 中的页面数量 count 超过了规定的水位线 high 的值,说明现在 pcplist 中的页面太多了,需要从 pcplist 中释放 batch 个物理页面到伙伴系统中。这个过程称之为惰性合并。

![[RISC-V]Milk-V开发板 i2c测试oled及波形输出](https://img-blog.csdnimg.cn/041b873d9a2c415a99d21a57dfdbc327.png)