前言:
本文为记录自己在Nerf学习道路的一些笔记,包括对论文以及其代码的思考内容。公众号: AI知识物语 B站讲解:出门吃三碗饭
本篇文章主要针对其数学公式来学习其内容,欢迎批评指正!!!
1:摘要
提出基于学习(learning-based)方法,使用野外照片的非结构化集合(unstructured collections of in-the-wild photographs)来合成复杂场景。之前的Nerf通过MLP的权重来模拟场景的密度、颜色。虽然在静态对象生成上比较好,但在uncontrolled images不受控的图片中,会有一些ubiquitous,real-world phenomenon,也就是可变照明或者瞬时遮光器variable illumination or transient occluders,本文基于Nerf引入了一些列扩展来解决这些问题。

下面讲按照论文章节来介绍:
2:Background
简单回顾下Nerf
Nerf使用一个连续(可导)的体积辐射场来表示场景,具体结构为MLP多层感知机,将空间位置 x=(x,y,z)以及方向位置d=(dx,dy,dz)输入,输出密度σ和颜色c = (r,g,b)。现在,为了得到多视角下场景(我们肉眼看到的图像场景由一个个像素组成),需要计算单个像素的颜色,Nerf将MLP网络输出的密度σ和颜色c = (r,g,b)作为输入,通过体渲染操作来生成像素。
补充:
(1)在场景中,把密度σ和颜色c = (r,g,b)通过积分操作,来模拟场景中的光线
(2)光线表示为r(t) = o + td ,o表示起点,td表示距离起点的某个方向间隔
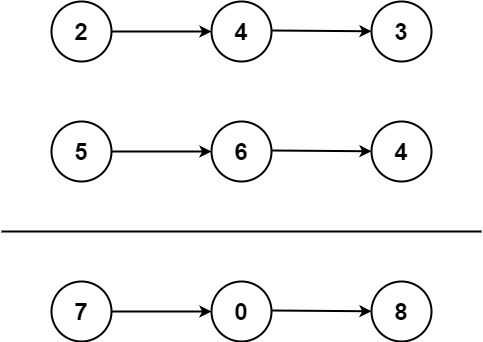
见下图公式
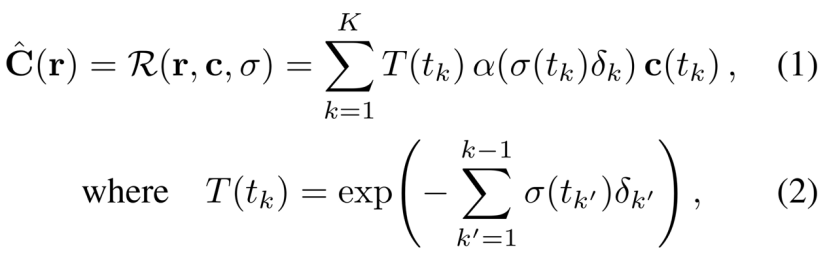
式(1) (注意这里是求和,原先的Nerf是求导)
C_^ = T * α *c
下面这个是最初的Nerf 计算体素pixel的公式

参数解释:
r(t):光线上某个采样点
c(t): MLP输出的color值,采样点t_k处的color值
σ(t):MLP输出的密度值,也就是采样点t_k处的密度值
α(σ(tk)δk):根据光线路径上的位置和密度,调整每个采样点在渲染过程中的权重。融合权重会根据光线的密度进行调整,以补偿密度对颜色估计的影响。
α(x)= 1 -exp(-x):
(理解1)一种常见的融合权重函数,一种常见的融合权重函数,
(理解2)表示采样点tk处的透射率(transmittance),透射率越小,贡献越大。举例σ(t),密度越大, exp(-x)越小,1 -exp(-x)越大,透射率越大
T(t_k):表示从第采样点t_k到光线终点的透射比
δ_k = t_k - t_k:这里是两个正交点之间的距离。(在最初的Nerf中表示为相邻采样点的距离)
分层采样用于选择t_n和t_f(摄像机的近平面和远平面)之间的正交点
{tk}K_k =1。
通过对沿着光线方向进行采样的辐射场值进行加权,根据透射率和颜色信息来估计每个像素点的颜色。这种方法能够更好地处理光线在场景中的衰减和颜色的变化,从而提高重建的视觉质量。
补充:
(1)T(tk)的计算是通过从相机位置c到采样点tk之间的路径上的密度(density)值进行累乘得到的。路径上的密度值反映了介质对光线的吸收和散射程度。因此,通过累乘路径上的密度值,可以计算出光线在路径上的衰减情况。
(2)公式2中,σ(tk)是采样点tk处的密度(density),δk是采样点之间的距离。这个公式中的积分表示对路径上的密度进行累积,从相机位置c到达采样点tk。
(3)δ_k表示两个正交点之间的距离。正交点是指在光线路径上与场景中的物体相交的点,并且与该物体的表面垂直(正交)相交。
那么,δ_k = t_k - t_k 表示相邻两个正交点之间的距离,即两个相交点在光线路径上的参数化位置之差。通过计算这个距离,我们可以获得两个正交点的位置之间的空间距离,用于光线追踪和渲染中的各种计算和操作。
(4)透射率是指光线在通过介质时被吸收或散射的程度。
它通常用一个介于0和1之间的值来表示,表示光线通过介质时保留下来的比例。
透射率与介质的吸收和散射特性有关。当光线通过介质时,部分光线会被介质吸收,使光线的强度减弱。另一部分光线会被介质中的颗粒或分子散射,导致光线的方向改变。透射率表示通过介质的光线相对于入射光线的强度比例。
(5)α(x)= 1 -exp(-x): (存疑,具体看代码解释)
当光线与场景交互的位置x较小时,表示该位置对渲染结果有较大的贡献。
当光线与场景交互的位置x较大时,表示该位置对渲染结果的贡献较小。
通过这种融合权重函数,NeRF模型可以对场景进行无缝融合,减少视角间隙和视角不连续的问题。

使用ReLU的MLP网络来输出(表示)密度值σ
使用Sigmoid的MLP网络来输出(表示)color值c
参数解释:
γ_x:表示经过位置编码的空间数据 (x是空间xyz坐标向量)
γ_d:表示经过位置编码的方向数据 (d是空间dx,dy,dz方向向量)
θ1,θ2:MLP需要拟合的量,训练MLP网络,也就是在拟合其的过程
z(t):光线路径上不同位置的参数,通过对其进行编码,模型可以学习场景中不同位置的特征和颜色变化
补充:
(1)
为了拟合θ,Nerf(具体来说也就是MLP)会最小化预测生成的图像与每个(大小为HW3)target图像的损失。
(To fit parameters θ, NeRF minimizes the sum of squared reconstruction errors with respect to an RGB image collection {Ii}N
i=1, Ii ∈ [0, 1]H×W×3.)
(2)
图像集合中的每个图像都会与(提前计算好的,比如使用Colmap生成)camera参数配对;
(3)
我们提前precompute计算Image --i中的pixel(像素)–j对应的一系列光线,记为ray_ij,这里的每条光线都穿过3D场景中的点o_i(可以理解为第i张图像image的起点,3D location),并且光线方向为d_ij(第i张image中第j个pixel视角下的color)
通过上面的介绍,我们知道,体渲染操作是对光线上每个点,利用其密度和color来进行数值积分计算。为了提高对光线上采样点的效率(光线有些地方点贡献度高,有些贡献度低,具体看前几篇介绍Nerf的),本文同时优化粗coarse和细fine模型。
两个MLP网络使用以下的损失函数来进行最小值优化
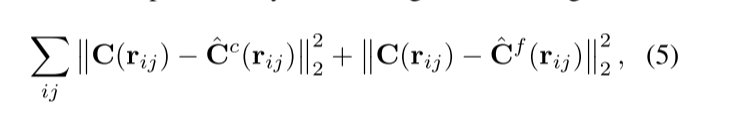
数学解释:
(1)
矩阵A=[0,1,2;2,1,3]
范数双竖线加下标: 矩阵中每个元素平方和的平方根,sqrt(sum(xi.^2)),比如A的L2范数就为19
范数学习链接
(2)
举例图中的左边式子,target,也叫真值的像素与粗网络预测的像素先后进行L2范数计算和平方计算(平方,可能是为了避免负值),右边同理
在摘要里,我们刚刚看到了,户外场景wild environment中,同一地点、角度的拍摄会受 光度变化以及瞬时物体变化的影响。
光度变化:一天中的时间和大气条件直接影响场景中物体的照明(以及因此产生的辐射),可能导致额外的光度不一致additional photometric inconsistencies。
瞬时物体:现实世界的地标很少被孤立地捕捉,它们周围没有移动的物体或遮挡物。地标的旅游照片尤其具有挑战性,因为它们通常包含摆拍的人类主体和其他行人。
针对上述问题,该论文扩展了NeRF,以允许图像相关的外观和光照变化image- dependent appearance and illumination variations ,从而可以显式地模拟图像之间的光度差异,允许瞬时物体被联合估计并从3D世界的静态表示中分离出来

参数解释:
输入:appearance embedding外观 + 视角方向 + 三维位置 + 瞬时transient embedding
输出:静态static和瞬态transient的颜色和密度
4.1 Latent Appearance Modeling
为了让Nerf能够更好地处理光照变化variable lighting以及 photometric post-processing问题,采用了GLO方法(Generative Latent Optimization)。
具体来说就是(1)给每个图片分配了一个长为n的嵌入向量(embedding vector)l (2)用c_i(t)代替上面方程(1)中的c(t),引入的量他可以引入图像image_i对近似像素颜色C的依赖
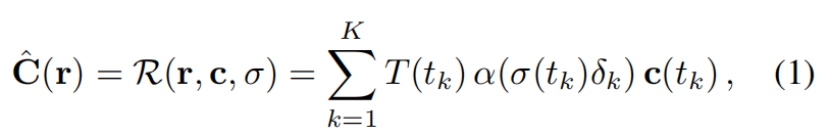
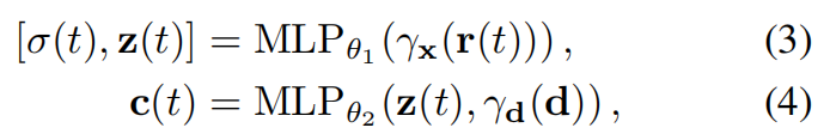
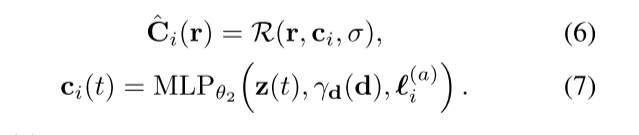
方程解释:
(6)左边是第i张图预测的像素值,右边是体渲染render函数,其输入为ray,c(color)和密度
(7)左边是本文引入的c_i(t),理解为第i张image,光线位置t处的点的color,右边是输出color的MLP网络,其输入是z(t),位置编码过后的方向向量,以及外观嵌入向量l (appearance embedding vector)
补充:
1:这里重在区别方程(6)和(1)中的 c_i参数,是不同的,前者引入了外观嵌入向量。
2:这里引入的外观嵌入向量也会随着MLP网络中θ2被优化而优化
4.1 Transient Objects
为了解决瞬态现象transient phenomena问题
(1)把输出color的MLP网络指定为static head静态头部,并额外添加瞬态头部additional transient head,其输出color颜色和密度,并允许密度值在不同的训练图像间变化,该方法使得Nerf-W可以重建包含遮光器的图像
(2)不是假设所有观察到的像素颜色都同样可靠,而是允许我们的瞬态头部发射不确定场emit a field of uncertainty(很像我们现有的颜色和密度场),这允许我们的模型调整其重建损失adapt its reconstruction loss,以忽略不可靠的像素和可能包含遮光物的3D位置。
我们将每个像素的颜色建模为各向同性的正态分布isotropic normal distribution,我们将最大化其可能性likelihood,并且我们使用与NeRF使用的相同的体绘制方法来“绘制”该分布的方差。这两个模型组件允许NeRF-W在没有明确监督的情况下理清disentangle静态和瞬态现象。
为了建立自己的 transient head瞬态头部,该论文基于体渲染方程6,增加了静态密度σ和radiance辐射c_i,及其对应的瞬态密度σ_T_i和辐射 c_T_i
具体方程如下:
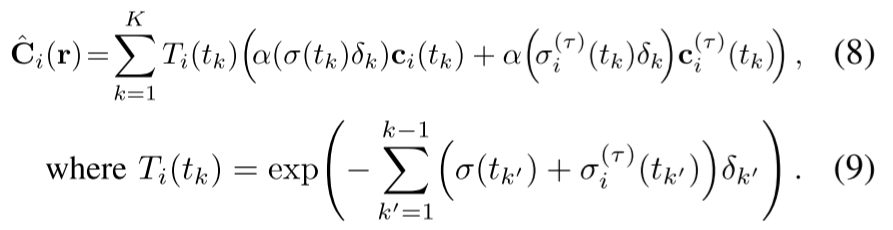
这是原来的方程:

参数解释:
r(t):光线上某个采样点
c(t): MLP输出的color值,采样点t_k处的color值
σ(t):MLP输出的密度值,也就是采样点t_k处的密度值
α(x)= 1 -exp(-x):
(理解1)一种常见的融合权重函数,一种常见的融合权重函数,
(理解2)表示采样点tk处的透射率(transmittance),透射率越小,贡献越大。举例σ(t),密度越大, exp(-x)越小,1 -exp(-x)越大,透射率越大
T(t_k):表示从第采样点t_k到光线终点的透射比
δ_k = t_k - t_k:这里是两个正交点之间的距离。(在最初的Nerf中表示为相邻采样点的距离)
分层采样用于选择t_n和t_f(摄像机的近平面和远平面)之间的正交点
{tk}K_k =1。
方程(8)(9)与(1)区别注意:
(8)在(1)的基础上添加了transient head,左边是static静态部分,右边动态部分transient head
同时(9)中也根据对应static静态部分添加了瞬态部分transient head
论文采用采用Kendall等人[15]的贝叶斯学习框架Bayesian learning framework来模拟观察到的颜色的不确定性。我们假设观察到的像素强度pixel intensities是固有的噪声(任意的)inherently noisy (aleatoric),并且进一步假设这种噪声是依赖于输入的(异质的)input-dependent (het- eroscedastic)。我们用各向同性正态分布isotropic normal distribution 对观察到的颜色C_i 建模,该正态分布具有依赖于图像和光线的方差β_i ^2和平均值c_i。

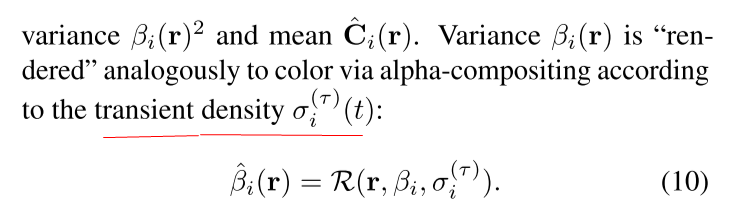
方差β_i (r)通过瞬时密度σ(t),通过α(alpha-compositing)透明度来渲染颜色
为了使瞬态变量可以跨图像变化,论文给训练的每个图像image_i分配了第二个embed-ding I 量(类似于appearance embedding),其作为瞬态变量输入MLP

Relu + sigmoid激活函数用在瞬态下的密度和color值,
softplus(x)=log(1+exp(x))
β_min作为一个超参数,其可以确保每条射线被分配了最小的重要性

前两项是Ci®的(移过的)负对数似然,符合均值Ci®和方差βi®2的正态分布。较大的βi®值会减弱分配给像素的重要性,假设它属于某个瞬态对象。第一项被第二项平衡(当Bi过于大的时候,第1项接近0,第2项就会平衡,使其不那么靠近0),它对应于正态分布的对数配分函数,并且排除了βi® =∞处的平凡最小值。第三项是在(非负)瞬态密度σ(τ)上具有乘法器λu的L1正则化器。这阻碍了模型使用瞬态密度来解释静态现象。
在测试时,我们忽略瞬态场和不确定场;只表示σ(t)和c(t)图4给出了一个示例

4.3. Optimization
与NeRF一样,我们同时优化了两个MLP:一个使用上述模型和损失loss的精细模型,一个只使用潜在外观建模组件的粗糙模型。除了参数θ,我们优化每幅图像的外观嵌入{I(a)}N 和瞬态嵌入 i=1,{(τ) }N
则NeRF-W的损失函数为:

对于测试集可视化,我们选择来最佳拟合目标图像(例如图8)或者将其设置为任意值。

Result:

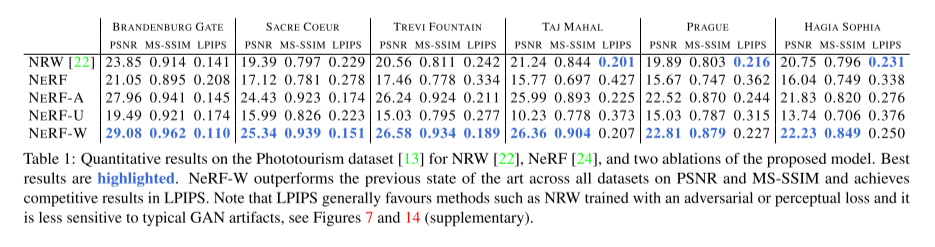
表1:NRW[22]、NeRF[24]和所提出模型的两次缩减在摄影旅游数据集[13]上的定量结果。最好的结果会被突出显示。NeRF-W在PSNR和MS-SSIM的所有数据集上都优于以前的技术水平,并在LPIPS中取得了具有竞争力的结果。请注意,LPIPS通常倾向于使用NRW等训练具有对抗性或感知损失的方法对典型的GAN伪影不太敏感,参见图7和14(补充)。
Limitations:虽然 NeRF-W 能够从非结构化照片生成逼真且时间一致的渲染,但在训练图像中很少观察到的场景区域或仅在非常倾斜的角度(例如地面)观察到的场景区域中,渲染质量会下降,如图所示 如图 10 所示。与 NeRF 类似,NeRF-W 对相机校准误差也很敏感,这可能会导致场景中已成像的部分重建模糊。相机校准不正确。
Conclusion:我们提出了 NeRF-W,这是一种基于 NeRF 构建的非结构化互联网照片集对复杂环境进行 3D 场景重建的新颖方法。 我们学习每个图像的潜在嵌入,捕获野外数据中经常出现的光度外观变化,并将场景分解为图像相关和共享的组件,以允许我们的模型从静态场景中分离瞬态元素。 对真实世界(和合成)数据的实验评估表明,与之前的状态相比,在定性和定量上有了显着的改进最先进的方法。