CACD是Cant assign, Cache Dirty的缩写,DELL EMC的专业术语。
在开始之前,先介绍下cache dirty的概念,朴素的语言就是有了脏数据,脏数据当然就是不能使用的数据了。为什么数据会脏呢?先从存储的基本概念聊起来。
为了加快主机的IO响应速度,所有的企业级存储都有read cache和write cache的概念,write cache就是内存中分出一部分空间,所有的写操作,其实都是写到了写cache中,而不是直接写到了后端的磁盘中,当然如果write cache被disable了,数据就直接落盘了,但这样性能会很差。cache中的数据按照一定的算法定期批量写入磁盘中。这就是说,如果存储系统在正常工作中,就总是有从主机写入的说数据保存在cache内存中。如果一旦这部分数据出问题了,也就是说从主机端来看他已经把数据写入到了存储,但是实际真正存储物理数据的磁盘并没有写入这些数据,而这些数据是在cache中由于各种原因被破坏了。这就导致物理磁盘上的数据一致性出现问题。这些cache中的数据也就称之为dirty脏数据了,由于这些数据写入到后端的存储磁盘中,数据完整性不对,存储也不容许这些数据写入。
如果出现了dirty cache,会有什么后果呢? 最直接的后果就是客户的业务数据一致性没有了,数据不完整了,如果继续要使用这些数据,就必须做完整性检查,也就是我们常说的fsck了。其实,从存储的定义来看,就是已经丢数据了,发生了data lost,只不过是丢失的数据量的多少而已。
我们回到本文的主题,EMC的Clariion存储系统,就是CX,VNX和Unity这个系列的存储,如果发生了dirty cache事件,存储的表现是什么?下面的讨论重点用VNX来举例,CX和Unity的类似,但是处理方法是不同的。根据dirty的数据在存储中的分布,如果客户存储上有几个不同的pool,则发生dirty的pool中的LUN和POOL都会offline,当然业务也就挂了。如下图所示:

有些LUN是offline,而有些lun是ready的,就是这个原因。
与这些LUN对应的POOL也是offline的状态。如果出现cache dirty,业务肯定是挂了,就是所谓的DU了,data unavailable了。
下面是重点了,敲黑板了。为什么会导致cache dirty,怎么避免这种情况的发生?最常见的是下面几种情况:
- 客户关机误操作。
经常遇到cache dirty的case是在过节后的上班第一天,为什么这样了,有些客户由于要过节,把存储关了,然后等上班以后,第一件事情就是开机,开机后说业务连不上了。这种情况,不看日志,猜测极大的概率就是cache dirty了。还有就是机房搬迁,搬迁前都是OK的,但是搬迁到新机房,开机就不行了。这种情况十有八九也是cache dirty了。
为什么关机操作容易造成cache dirty呢?我们来看看VNX的电源连线方法,下图是VNX5300的电源连线图。
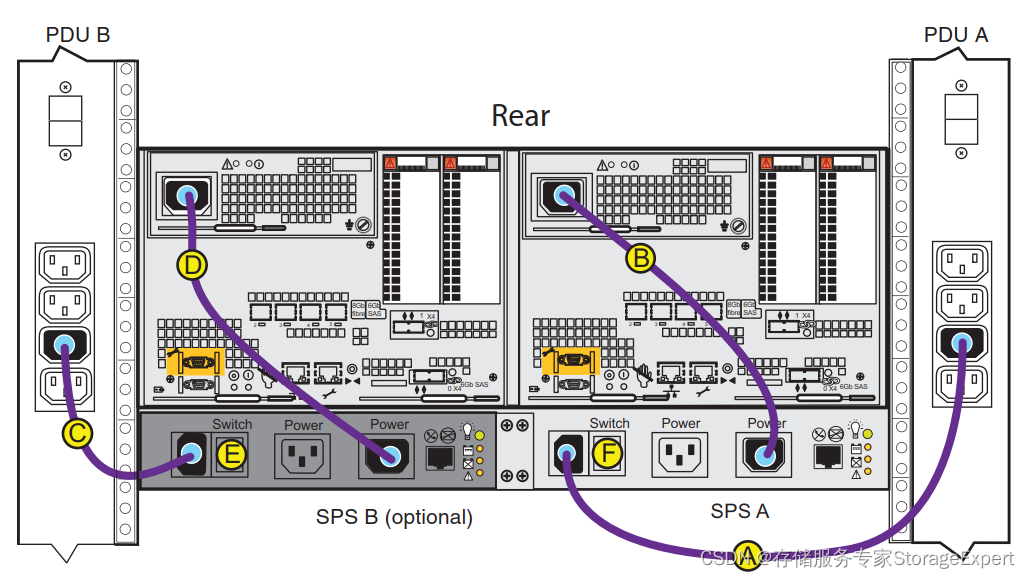
PDU的直接连接到了SPS就是电池,然后从电池的OUT出来到了控制器的电源输入。
由于早期的VNX图形界面上没有一个关机按钮,关机就只能直接拔电了。然后悲催的是现场搬迁的技术人员属于无知无畏的工程师。既然叫直接拔电,那就拔了,直接把上图中的ABCD四条线同时拔掉,这就悲催了。内存中的数据由于没有了sps的支撑,数据直接丢失。正确的关机拔电顺序应该是先拔掉A和C,这时候SPS还继续给两个控制器提供电源保护,系统启动vault,内存中的数据写入后端存储或者vault区。
- SPS或者BBU电池故障,没有引起重视。
还有一类就是对于SPS的工作原理不知,总是认为这个固件故障了没有关系,不影响系统正常运行,所以即使有一个SPS电池坏了,不更换,反正还有一个SPS是正常的,而且也没有导致业务出现问题。
有些情况下,如果一个SPS出现明显故障,另外一个SPS也有告警,但还没有故障,即使按照正常的顺序开关机,也会导致cache lost,丢失数据。
- 处理SP故障时的误操作
这种情况也是很常见,本来客户坏了一个控制器,然后服务商就去给客户维修。更换的过程中,遇到 一些麻烦,新更换的控制器无法正常启动。这种情况应该是检查为什么不能正常启动,但很多工程师没有这个能力去检查,就采用了3R大法(Reseat插拔,Reboot重启和Reinstall重装),对整个机器做重启,由于VNX控制器的重启一般需要10-15分钟,甚至更长时间。现场工程师看到挺长时间还没有起来,认为有问题,就再重启依次,其实是在重启过程中,这样来回折腾几次,基本上cache dirty的概率就很高了。到最后,整个系统都挂了。看日志,cache lost都是发生在几次重启之间。
还有一种情况就是更换控制器中某个部件,常见的是内存条和IO module,base module等,这些FRU部件是需要将控制器shutdown下来再更换的,我们比较简单的工程师,就直接把控制器从正常加电运行的状态下拽了下来,然后更换故障备件,然后再插入重启。以前遇到过类似的,给他指出问题,还振振有词的说,我每次都这样操作也没有出过事情。好吧,你NB。正常的工作流程应该是先暂时关闭write cache,然后再使用naviseccli命令来shutdown这个SP,最后完成更换。如果命令不会用,最起码的要disable了write cache再做操作。
怎么判断存储是遇到了cache dirty 而不是其他故障导致的pool和LUN的offline?对于Unity和VNXe就是两个控制器都到了service mode。
最简单的就是查看sp的event log,看到有类似de "Can't Assign - Cache dirty "就是100%的有cache dirty了。在spcollect日志中是下面的样子:
A 06/27/23 15:41:37 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
A 06/27/23 15:41:38 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
A 06/27/23 15:41:38 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
A 06/27/23 15:41:38 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
A 06/27/23 15:41:38 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
A 06/27/23 15:41:38 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
A 06/27/23 15:41:39 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
A 06/27/23 15:41:39 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
A 06/27/23 15:41:39 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
A 06/27/23 15:41:39 Bus1 Enc2 Dsk9 90a Can't Assign - Cache Dirty [ALU 4007] 0 770052 fa70045
[ 9896 lines deleted ]
B 06/27/23 22:30:38 Bus1 Enc2 Dsk5 90a Can't Assign - Cache Dirty [ALU 3905] 0 6f00b9 f410041
B 06/27/23 22:30:38 Bus1 Enc3 Dsk3 90a Can't Assign - Cache Dirty [ALU 3924] 0 7000a6 f54004e
B 06/27/23 22:30:43 Bus1 Enc2 Dsk5 90a Can't Assign - Cache Dirty [ALU 3905] 0 6f00b9 f410041
B 06/27/23 22:30:43 Bus1 Enc3 Dsk3 90a Can't Assign - Cache Dirty [ALU 3924] 0 7000a6 f54004e
最后一个问题就是怎么处理?这个问题比较难回答,具体可以add wechat at StorageExpert来讨论。EMC的Clarrion系统分了很多不同的产品,版本号也很多,从最早的CX的R29,30到VNX1代的R31,R32,然后到VNX2代的R33,以及VNXe和Unity。OS版本不同,客户cache lost的场景不同,处理方法也是不同的。我们给一些客户擦过屁股就是有些工程师知道了一种clear cache的方法,认为所有的情况都是这样处理,最严重的是把fast cache给彻底清除了。这样啥数据也捞不回来了,总会只能宣布无法恢复数据,客户数据全部丢失。
最后再敲依次黑板,遇到涉及和数据有关的严重问题,如果没有明确的日志支撑下的方案,千万不要各种没有任何根据的尝试,这样只能让事情与来越糟糕,柳暗花明的情况是少之又少。