累了,没写完
面试完了再来写
参考教程:
swin-transformer/model.py
文章目录
- 概述
- transformer blocks
- window_partion
- W-MSA
- window-reverse
- Patch Merging
概述
在前面介绍了vision transformer的原理,加入transformer的结构后,这种网络在多种图像任务中都取得了不错的结果。但是它也存在一些问题。
第一个问题就是上一章提过的粗粒度问题,patch的大小比较大时,一个patch内可能有多个相似特征。
第二个问题就是当你想获得更多的特征时,就必须使用很长的序列。这里的序列长度指的是N*D中的N。想要获得更多的N,patch的大小就需要变小,也就是更加细粒度。但是这种情况下,在计算内积的时候就效率很低,尤其考虑到encoder的block要反复做很多次,速度就更慢了。
swin-transformer使用窗口和分层的方式。为了把结果做的比较好,第一层用很细的token,在后面的层里为了提高效率,开始进行token的合并。经过每一层合并,token会越来越小。
token数量逐渐降低,就像卷积网络中feature map逐渐减小的过程。swin-transformer其实就是模拟了CNN的过程,随着层次的加深,token的数量降低,但是embedding_dim按层翻倍。
看整个流程,本质上还是一样的。首先对输入的图像进行编码。这里使用的是patch partition, 获得H/4*W/4个embedding,embedding_dim = 4*4*3 = 48。
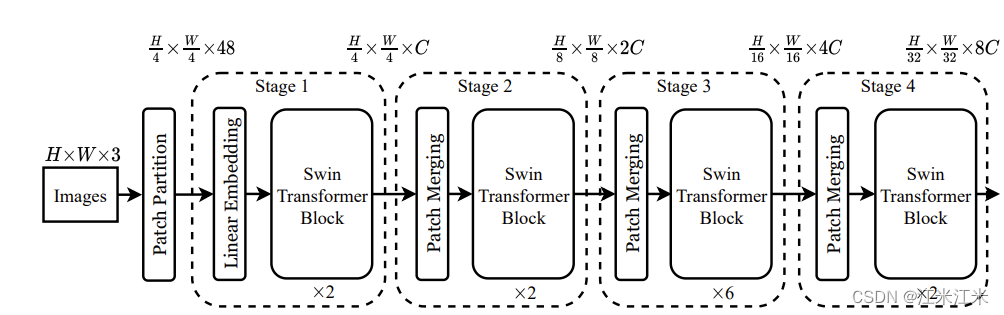
之后开始在网络中进行一层一层的forward。并且隔几个block进行一次patch merging。patch merging的作用就是将patch合并在一起,减少patch的数量。
综合来说,它的整体架构还是可以分成两部分:
- 得到pacth。
- 分层计算attention
transformer blocks
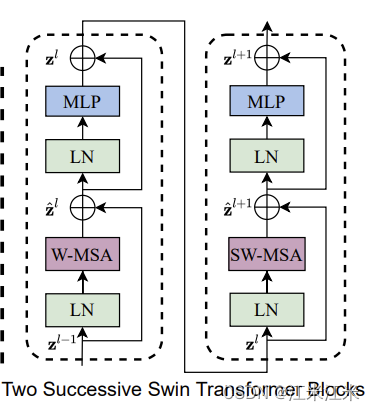
在swin-transformer中,一个block里面包括了两个sub-block。
第一个sub-block是W-MSA + MLP。
第二个sub-block是SW-MSA + MLP。
两个subblock连在一起才是完整的结构。
从源码上看在进入和离开窗口时,embedding都会有形状的改变,分别为window_partition,作用是把大小为B*N*D的输入转成窗口的格式。在经过attention计算后,再使用window_reverse转回去。
整个block的计算公式可以写为:

window_partion
window-MSA:基于窗口的注意力计算。
比如说我们的输入是一个224*224*3的图像,在经过patch embedding后得到56*56*96的结果。也就是说我们的图像被分成了56*56个4x4的小patch,每个4*4的小patch在处理后得到长度为96的embedding。
那么为了使用window-MSA,我们需要将这个patch_embedding再次变成一个窗口一个窗口的形状。假设我们的窗口大小为7。那么我们就可以得到8*8*7*7*96大小的embedding。前面的8*8代表你的window的个数,7*7是你的window的大小,96是每个位置的embedding的长度。
W-MSA
window-MAS就是在window范围内进行的自注意力计算。一个窗口的大小是7*7,也就是说每个窗口内有49个元素,我们要求这49个元素互相的关注度。
因为只在窗口内进行计算,所以可以理解成 8*8 = 64是你的batch_size, batch中的每个特征是不会互相影响的。7*7 = 64是你的word_number,96是你的word的embedding。这其实是和普通的MSA计算过程是一样的。
现在我们使用多头MSA对我们的64*49*96的输入进行计算。我们可以得到:
S
i
z
e
O
f
(
Q
/
K
/
V
)
=
64
×
3
×
49
×
(
96
/
3
)
SizeOf(Q/K/V) = 64 \times 3\times 49\times (96/3)
SizeOf(Q/K/V)=64×3×49×(96/3)
Q和K进行内积,得到的关注度大小为64*3*49*49。
然后再和V加权求和,得到最终输出的token大小为64*3*49*(96/3)。
window-reverse
我们的token在进入block时进行了partion,再出去时我们希望得到的结果能保持和输入的token一样的大小。
对上面的结果直接进行reshape,就可以从64*49*96变回56*56*96。
Patch Merging
patch merging在这里就相当于一个下采样操作。
并且它采用的方法在之前也很常见,具体可以参考yolov2的passthrough,yolov5的FOCUS模块。本质上就是从一个feature map上间隔挑选,挑出4个大小为 h/2, w/2的新feature,并concat到一起,那么它的通道数其实是变成了4倍。
所以在后面又添加一个卷积层,进行降维操作。从而达成一次下采样,维度翻一倍的经典类卷积网络结构。