1. SimCLR v1
论文名称: A Simple Framework for Contrastive Learning of Visual Representations
开源地址:https://github.com/google-research/simclr
大佬论文解读:https://zhuanlan.zhihu.com/p/378953015
highlight:更多的数据增强与非线性映射层
用数据增强构造正样本,batch内的其余图片为负样本
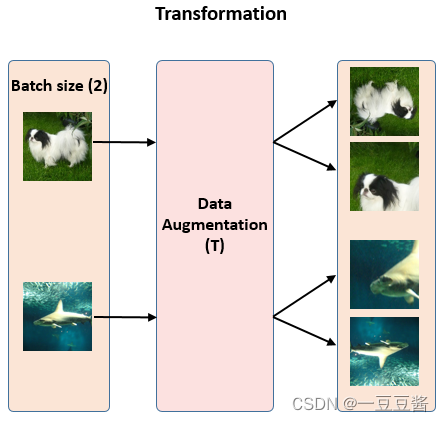
假设现在有1张任意的图片x,叫做Original Image,先对它做数据增强,得到2张增强以后的图片x1和x2。注意数据增强的方式有以下3种:
- 随机裁剪之后再resize成原来的大小 (Random cropping followed by resize back to the original size)。
- 随机色彩失真 (Random color distortions)。
- 随机高斯模糊 (Random Gaussian Deblur)。
SimCLR框架
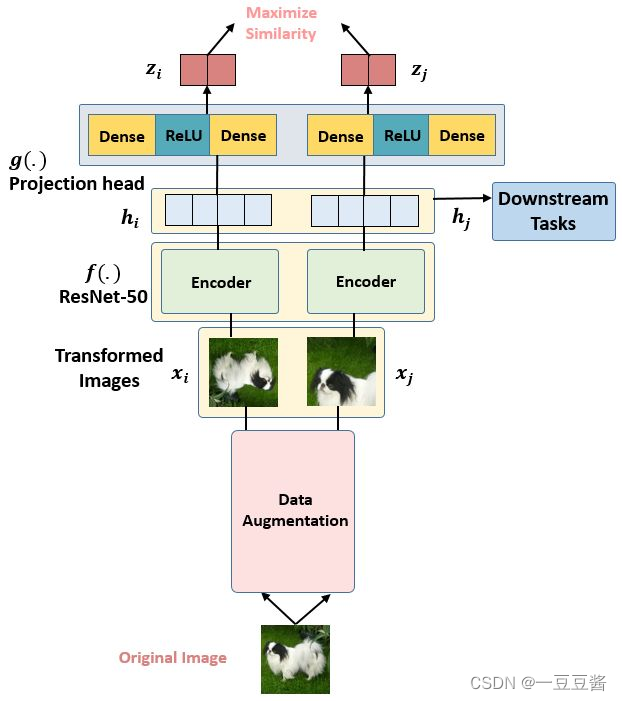
使用 Projection head 计算loss,预测头是一个2层的MLP,将2048 维的visual representation向量进一步映射到 128 维隐空间中,得到新的representation。最终使用
z
i
z_i
zi
z
j
z_j
zj去求loss 完成训练,训练完毕后扔掉预测头,保留 Encoder 用于获取 visual representation。
损失函数
NT-Xent loss (Normalized Temperature-Scaled Cross-Entropy Loss)的对比学习损失函数代码实现
import tensorflow as tf
import numpy as np
def contrastive_loss(out,out_aug,batch_size=128,hidden_norm=False,temperature=1.0):
if hidden_norm:
out=tf.nn.l2_normalize(out,-1)
out_aug=tf.nn.l2_normalize(out_aug,-1)
INF = np.inf
labels = tf.one_hot(tf.range(batch_size), batch_size * 2) #[batch_size,2*batch_size]
masks = tf.one_hot(tf.range(batch_size), batch_size) #[batch_size,batch_size]
logits_aa = tf.matmul(out, out, transpose_b=True) / temperature #[batch_size,batch_size]
logits_bb = tf.matmul(out_aug, out_aug, transpose_b=True) / temperature #[batch_size,batch_size]
logits_aa = logits_aa - masks * INF # remove the same samples in out
logits_bb = logits_bb - masks * INF # remove the same samples in out_aug
logits_ab = tf.matmul(out, out_aug, transpose_b=True) / temperature
logits_ba = tf.matmul(out_aug, out, transpose_b=True) / temperature
loss_a = tf.losses.softmax_cross_entropy(
labels, tf.concat([logits_ab, logits_aa], 1))
loss_b = tf.losses.softmax_cross_entropy(
labels, tf.concat([logits_ba, logits_bb], 1))
loss=loss_a+loss_b
return loss,logits_ab
'''
假设batch_size=3, out 和 out_aug 分别代码 原始数据和增强数据的representation
out : [a1,a2,a3]
out_aug : [b1,b2,b3]
labels:
[batch_size,2*batch_size] batch_size=3
1 0 0 0 0 0
0 1 0 0 0 0
0 0 1 0 0 0
mask:
[batch_size,batch_size]
1 0 0
0 1 0
0 0 1
logits_aa [batch_size,batch_size]
a1*a1, a1*a2, a1*a3
a2*a1, a2*a2, a2*a3
a3*a1, a3*a2, a3*a3
logits_bb [batch_size,batch_size]
b1*b1, b1*b2, b1*b3
b2*b1, b2*b2, b2*b3
b3*b1, b3*b2, b3*b3
logits_aa - INF*mask # delete same samples
-INF, a1*a2, a1*a3
a2*a1, -INF, a2*a3
a3*a1, a3*a2, -INF
logits_bb - INF*mask # delete same samples
-INF, b1*b2, b1*b3
b2*b1, -INF, b2*b3
b3*b1, b3*b2, -INF
logits_ab [batch_size,batch_size]
a1*b1, a1*b2, a1*b3
a2*b1, a2*b2, a2*b3
a3*b1, a3*b2, a3*b3
logtis_ba [batch_size,batch_size]
b1*a1, b1*a2, b1*a3
b2*a1, b2*a2, b2*a3
b3*a1, b3*a2, b3*a3
concat[logits_ab,logits_aa]:
a1*b1, a1*b2, a1*b3, -INF, a1*a2, a1*a3
a2*b1, a2*b2, a2*b3, a2*a1, -INF, a2*a3
a3*b1, a3*b2, a3*b3, a3*a1, a3*a2, -INF
only a1*b1, a2*b2, a3*b3 are positives
concat [logits_ab,logits_bb]:
b1*a1, b1*a2, b1*a3, -INF, b1*b2, b1*b3
b2*a1, b2*a2, b2*a3, b2*b1, -INF, b2*b3
b3*a1, b3*a2, b3*a3, b3*b1, b3*b2, -INF
only b1*a1, b2*a2, b3*a3 are positives, so calculate the softmax_cross_entropy with labels
'''
(个人理解)损失函数的实现上也可以写成两个特征concate然后相乘变成一个2N*2N的大矩阵,按行计算交叉熵
与moco的对比
- 数据增强方法
simclr新增了高斯模糊 - 网络框架
moco两个encoder参数不共享,正样本encoder采用动量更新;simclr两个encoder参数共享
(同一个网络两次前向?)并且新增了非线性映射头 - 损失函数
均为infoNCE
moco中的分母为正样本和queue中的负样本
共k+1项(k为队列长度),正样本仅计算了增强前后的相似度,没有计算batch内其余样本;
simclr中的分母为两个batch(原始batch+增强batch)样本,负样本数量为(2N-2)
2. SimCLR v2
论文名称:Big Self-Supervised Models are Strong Semi-Supervised Learners
2个关键点
- 在使用无标签数据集做 Pre-train 的这一步中,模型的尺寸很重要,用 deep and wide 的模型可以帮助提升性能。
- 使用无标签数据集做 Pre-train 完以后,现在要拿着有标签的数据集 Fine-tune 了。之后再把这个 deep and wide 的模型 蒸馏成一个更小的网络。
简单概括:Unsupervised Pre-train, Supervised Fine-tune,Distillation Using Unlabeled Data.
contribution
- 对于半监督学习来讲,在标签量极少的情况下,模型越大,获益就越多。这很不符合直觉,常识是标签这么少了,模型变大会过拟合。
- 即使模型越大能够学到越 general 的 representations,但是这是在不涉及下游任务的task-agnostic 的情况下。一旦确定了下游任务,就不再需要大模型了,可以蒸馏成一个小模型。
- Projection head 很重要,更深的 Projection head 可以学习到更好的representation,在下游任务做 Fine-tune 之后也更好。
具体步骤
- Unsupervised Pre-train:使用无标签数据以一种 Task-agnostic 的方式预训练Encoder,得到比较 general 的 Representations。
- Supervised Fine-tune:使用有标签数据以一种 Task-specific 的方式 Fine-tune Encoder。
- Distillation Using Unlabeled Data:使用无标签数据以一种 Task-specific 的方式蒸馏 Encoder,得到更小的Encoder。
⭐ 预训练中SimCLR v2 相比于v1的不同:
1)Encoder 变长变大:SimCLR v2 用了更大的ResNet架构,把原来的 ResNet-50 (4×) 拓展成了 ResNet-152 (3×) 和 selective kernels (SK),记为 ResNet-152 (3×+SK),变成这样以后,把这个预训练模型用 1%的 ImageNet的标签给 Fine-tune 一下,借助这一点点的有监督信息,获得了29个点的提升。
2)Projection head 变深:原来的结构是2个FC层+一个激活函数构成。现在是3个FC层,并且在Fine-tune的时候要从第1层开始。变成这样以后,把这个预训练模型用 1%的 ImageNet的标签给 Fine-tune 一下,借助这一点点的有监督信息,获得了14个点的提升。
3)加入了MoCo 的内存机制:因为 SimCLR 本身就能通过数据增强得到很多的负样本,所以说这步只获得了1个点的提升。
⭐ 预训练模型finetune
在 SimCLR 中,Projection head 在预训练完以后会被扔掉,不做Fine-tune,只保留Encoder 加一个FC层去做Fine-tune。
而在 SimCLR v2 中,Projection head 在预训练完以后不会被完全扔掉,而是扔掉一半,保留一半做Fine-tune。注意如果只保留一层,那就和 SimCLR 加一个FC层的做法实质上一样了。
⭐蒸馏
teacher net 输出数据的类别概率,student net 也输出类别概率,两个概率之间计算loss
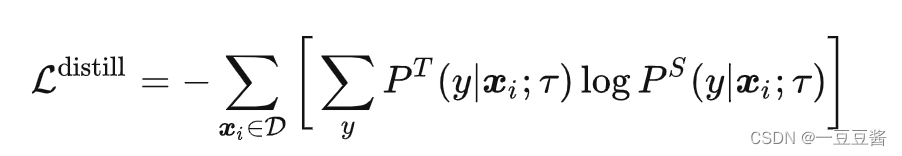
如果使用有标签的数据,也可以再添加一项有标签的损失函数
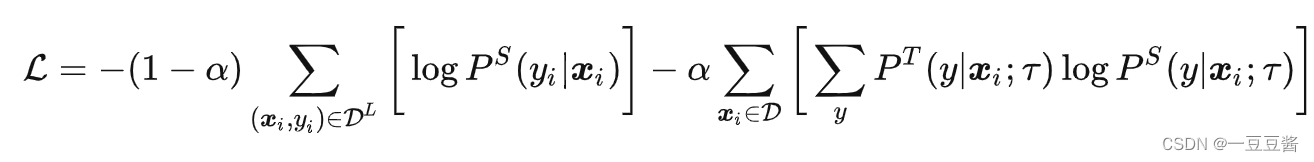
其实主要还是机子够多,batchsize够大,batch内除了positive以外的都当negatives就已经足够了。


![[Eigen中文文档] 在 BLAS/LAPACK 、英特尔® MKL 和 CUDA 中使用 Eigen](https://img-blog.csdnimg.cn/358fbb477d3443c9abc1a775be3f46a6.png#pic_center)