前言
前面说到了强化学习,但是仅仅是使用了一个表格,这也是属于强化学习的范畴了,毕竟强化学习属于在试错中学习的。
但是现在有一些问题,如果这个表格非常大呢?悬崖徒步仅仅是一个长12宽4,每个位置4个动作的表格而已,如果游戏是英雄联盟,那么多的位置,每个位置那么多的可能动作,画出一个表格简直是不可想象的。
但其实,如果把这个表格看作一个数学函数,他的输入是坐标,输出是一个动作(或者每个动作对应的价值):

那也就是说,只要我们有一个坐标,得到一个动作,中间什么过程是可以不用管的,还记得这篇文章中说过:神经元(函数)+神经元(函数) = 神经网络(人工神经网络),那么,中间这一块也就可以使用神经网络代替,这也就是深度强化学习。
论文(Playing Atari with Deep Reinforcement Learning)地址:https://arxiv.org/abs/1312.5602
设置环境
注意:今天的环境代码我修改过了,跟上一篇的不一样,所以大家还是要先读一下环境代码。
本次环境代码中添加了对于棋盘大小的设置,修复了一些bug。
# -*- coding: utf-8 -*-
"""
作者:CSDN,chuckiezhu
作者地址:https://blog.csdn.net/qq_38431572
本文可用作学习使用,交流代码时需要附带本出处声明
"""
import random
import numpy as np
from gym import spaces
"""
nrows
0 1 2 3 4 5 6 7 8 9 10 11 ncols
---------------------------------------
0 | | | | | | | | | | | | |
---------------------------------------
1 | | | | | | | | | | | | |
---------------------------------------
2 | | | | | | | | | | | | |
---------------------------------------
3 * | cliff | ^ |
*: start point
cliff: cliff
^: goal
"""
class CustomCliffWalking(object):
def __init__(self, stepReward: int=-1, cliffReward: int=-10, goalReward: int=10, col=12, row=4) -> None:
self.sr = stepReward
self.cr = cliffReward
self.gr = goalReward
self.col = col
self.row = row
self.action_space = spaces.Discrete(4) # 上下左右
self.reward_range = (cliffReward, goalReward)
self.pos = np.array([row-1, 0], dtype=np.int8) # agent 在3,0处出生,掉到悬崖内就会死亡,触发done和cliffReward
self.die_pos = []
for c in range(1, self.col-1):
self.die_pos.append([self.row-1, c])
print("die pos: ", self.die_pos)
print("goal pos: ", [[self.row-1, self.col-1]])
self.reset()
def reset(self, random_reset=False):
"""
初始化agent的位置
random: 是否随机出生, 如果设置random为True, 则出生点会随机产生
"""
x, y = self.row-1, 0
if random_reset:
y = random.randint(0, self.col-1)
if y == 0:
x = random.randint(0, self.row-1)
else: # 除了正常坐标之外,还有一个不正常坐标:(3, 0)
x = random.randint(0, self.row-2)
# 严格来讲,cliff和goal不算在坐标体系内
# agent 在3,0处出生,掉到悬崖内就会死亡,触发done和cliffReward
self.pos = np.array([x, y], dtype=np.int8)
# print("reset at:", self.pos)
def step(self, action: int) -> list[list, int, bool, bool, dict]:
"""
执行一个动作
action:
0: 上
1: 下
2: 左
3: 右
"""
move = [
np.array([-1, 0], dtype=np.int8), # 向上,就是x-1, y不动,
np.array([ 1, 0], dtype=np.int8), # 向下,就是x+1, y不动,
np.array([0, -1], dtype=np.int8), # 向左,就是y-1, x不动,
np.array([0, 1], dtype=np.int8), # 向右,就是y+1, x不动,
]
new_pos = self.pos + move[action]
# 上左不能小于0
new_pos[new_pos < 0] = 0 # 超界的处理,比如0, 0 处向上或者向右走,处理完还是0,0
# 上右不能超界
if new_pos[0] > self.row-1:
new_pos[0] = self.row-1 # 超界处理
if new_pos[1] > self.col-1:
new_pos[1] = self.col-1
reward = self.sr # 每走一步的奖励
die = False
win = False
info = {
"reachGoal": False,
"fallCliff": False,
}
if self.__is_pos_die(new_pos.tolist()):
die = True
info["fallCliff"] = True
reward = self.cr
elif self.__is_pos_win(new_pos.tolist()):
win = True
info["reachGoal"] = True
reward = self.gr
self.pos = new_pos # 更新坐标
return new_pos, reward, die, win, info
def __is_pos_die(self, pos: list[int, int]) -> bool:
"""判断自己的这个状态是不是已经结束了"""
return pos in self.die_pos
def __is_pos_win(self, pos: list[int, int]) -> bool:
"""判断自己的这个状态是不是已经结束了"""
return pos in [
[self.row-1, self.col-1],
]
至于讲解这个环境,我觉得这个注释还是比较清楚的,如果有不明白的,请评论留言告知我。
制作网络
首先,我们先把自己代入表格,如果我们站到某个坐标,那么我们应该知道四个方向上的奖励,所以,网络可以有两种方式;
方式一、
网络输入是坐标和方向,输出是对应的奖励。
方式二、
网络输入是坐标,输出是四个方向对应的奖励。
这里我要来一句场外推理:方式一真的很麻烦,并且选择动作的时候,有多少个动作需要经过多少次网络。所以方式二是比较好的选择。
class Qac(nn.Module):
def __init__(self, in_shape, out_shape) -> None:
super(Qac, self).__init__()
self.in_shape = in_shape # 就是 智能体 现在的坐标
self.action_space = out_shape # 上0下1左2右3
self.dense1 = nn.Linear(self.in_shape, self.action_space)
# 输出就是每个动作的价值
self.lrelu = nn.LeakyReLU() # 换用tanh
self.softmax = nn.Softmax(-1)
def forward(self, x) -> torch.Tensor:
x = self.dense1(x)
return x
def sample_action(self, action_value: torch.Tensor, epsilon: float):
"""从产生的动作概率中采样一个动作,利用epsilon贪心"""
if random.random() < epsilon:
# 随机选择
action = random.randint(0, self.action_space-1)
action = torch.tensor(action)
else:
action = torch.argmax(action_value)
return action
def load_model(self, modelpath):
"""加载模型"""
tmp = torch.load(modelpath)
self.load_state_dict(tmp["model"])
def save_model(self, modelpath):
"""保存模型"""
tmp = {
"model": self.state_dict(),
}
torch.save(tmp, modelpath)
细心的人可能发现了,这个网络只有一层,非常简单,好像没有所谓的“特征提取”就直接到输出层了。这里有一个小技巧,就是我手动把坐标转成了onehot向量,可以认为是手动提取了特征。
def num_to_onehot(pos: torch.Tensor) -> torch.Tensor:
"""把坐标转成one_hot向量"""
n = int((pos[0] * 12 + pos[1]).item())
return nn.functional.one_hot(torch.tensor(n), num_classes=48)
如果大家使用两层神经网络,直接输入坐标,中间层是48,然后是一个输出层,也可以, 但是我试了,训练很慢,效果不好。不如这样直接手动编码了。
训练
整个训练的代码我直接贴在这里了:
# -*- coding: utf-8 -*-
"""
利用DQN实现
"""
"""
作者:CSDN,chuckiezhu
作者地址:https://blog.csdn.net/qq_38431572
本文可用作学习使用,交流代码时需要附带本出处声明
"""
import os
import random
import torch
import numpy as np
from torch import nn
from matplotlib import pyplot as plt
from cliff_walking_env import CustomCliffWalking
nepisodes = 10000 # total 1w episodes
epsilon = 1.0 # epsilon greedy policy
epsilon_min = 0.05
epsilon_decay = 0.9975
gamma = 0.9 # discount factor
lr = 0.001
random_reset = False
seed = 42
normalization = torch.tensor([3, 11], dtype=torch.float)
sr = -1
cr = -10
gr = 10
class Qac(nn.Module):
def __init__(self, in_shape, out_shape) -> None:
super(Qac, self).__init__()
self.in_shape = in_shape # 就是智能体现在的坐标
self.action_space = out_shape # 上0下1左2右3
self.dense1 = nn.Linear(self.in_shape, self.action_space)
# 输出就是每个动作的价值
self.lrelu = nn.LeakyReLU() # 换用tanh
self.softmax = nn.Softmax(-1)
def forward(self, x) -> torch.Tensor:
x = self.dense1(x)
return x
def sample_action(self, action_value: torch.Tensor, epsilon: float):
"""从产生的动作概率中采样一个动作,利用epsilon贪心"""
if random.random() < epsilon:
# 随机选择
action = random.randint(0, self.action_space-1)
action = torch.tensor(action)
else:
action = torch.argmax(action_value)
return action
def load_model(self, modelpath):
"""加载模型"""
tmp = torch.load(modelpath)
self.load_state_dict(tmp["model"])
def save_model(self, modelpath):
"""保存模型"""
tmp = {
"model": self.state_dict(),
}
torch.save(tmp, modelpath)
def num_to_onehot(pos: torch.Tensor) -> torch.Tensor:
"""把坐标转成one_hot向量"""
n = int((pos[0] * 12 + pos[1]).item())
return nn.functional.one_hot(torch.tensor(n), num_classes=48)
def main():
global epsilon
random.seed(seed)
torch.manual_seed(seed=seed)
plt.ion()
os.makedirs("./out/ff_DQN/")
# cw = gym.make("CliffWalking-v0", render_mode="human")
cw = CustomCliffWalking(stepReward=sr, goalReward=gr, cliffReward=cr)
# 专程onehot了
Q = Qac(in_shape=48, out_shape=cw.action_space.n)
optimizer = torch.optim.Adam(Q.parameters(), lr=lr)
loss_fn = torch.nn.MSELoss()
win_1000 = [] # 记录最近一千场赢的几率
total_win = 0
for i in range(1, nepisodes+1):
cw.reset(random_reset=random_reset) # 重置环境
steps = 0
while True:
steps += 1
state_now = torch.tensor(cw.pos, dtype=torch.float)
state_now = num_to_onehot(state_now).unsqueeze_(0).to(torch.float)
action_values = Q(state_now)
action_values = action_values.squeeze()
action_now = Q.sample_action(action_value=action_values, epsilon=epsilon)
action_now_value = action_values[action_now] # 这个是采取这个动作的预测奖励
state_next, reward_now, terminated, truncated, info = cw.step(action=action_now.item()) # 执行动作
state_next = num_to_onehot(state_next).unsqueeze_(0).to(torch.float)
with torch.no_grad():
next_values = Q(state_next)
next_values = next_values.squeeze()
# 得到下一个的动作,(同一个策略下,因为这是onpolicy的sarsa
action_next = Q.sample_action(action_value=action_values, epsilon=epsilon)
action_next_value = next_values[action_next] # 计算下一个动作的预期价值
# 计算 instantR + gamma * value_next,这个是实际上这个动作带来的预期收益
discounted_reward = reward_now + gamma * action_next_value * (1 - terminated) * (1 - truncated)
# 计算误差
loss = loss_fn(action_now_value, discounted_reward)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if terminated or truncated:
if terminated:
win_1000.append(0)
if truncated:
win_1000.append(1)
total_win += 1
break
epsilon = epsilon * epsilon_decay
epsilon = max(epsilon, epsilon_min) # 衰减学习旅
win_1000 = win_1000[-1000:]
win_rate = sum(win_1000)/1000.0
print("{}/{}, 当前探索率: {}, 是否成功: {}, 千场胜率:{}.".format(i, nepisodes, epsilon, truncated, win_rate), flush=True)
if i % 10000 == 0:
Q.save_model("./out/ff_DQN/Qac_{}_{}_{}_{}.pth".format(i, gr, cr, win_rate))
print("total win: ", total_win)
# 收尾测试看看能不能通关
path = np.zeros((4, 12), dtype=np.float64)
cw.reset(random_reset=False)
steps = 0
while steps <= 48: # 走,48步走不到头就不会走到了
steps += 1
state_now = torch.tensor(cw.pos, dtype=torch.float)
state_now = num_to_onehot(state_now).unsqueeze_(0).to(torch.float)
action_values = Q(state_now).squeeze()
# 贪心算法选择动作
action_now = Q.sample_action(action_values, 0)
print(cw.pos[0], cw.pos[1], action_now)
new_pos, _, die, win, _ = cw.step(action=action_now)
if win:
print("[+] you win!")
break
if die:
print("[+] you lose!")
break
x = new_pos[0]
y = new_pos[1]
if x >= 0 and x <= 3 and y >= 0 and y <= 11:
path[x, y] = 1.0
plt.imshow(path)
plt.colorbar()
plt.savefig("./out/ff_DQN/path_sarsa_"+str(sr)+"_"+str(gr)+"_"+str(cr)+".png")
if __name__ == "__main__":
main()上面的代码我测试没问题,如果不修改直接使用是完全可以的,目录结构是这样的:
那两个文件夹都是自动生成的,不需要手动建立。
网络结构分析
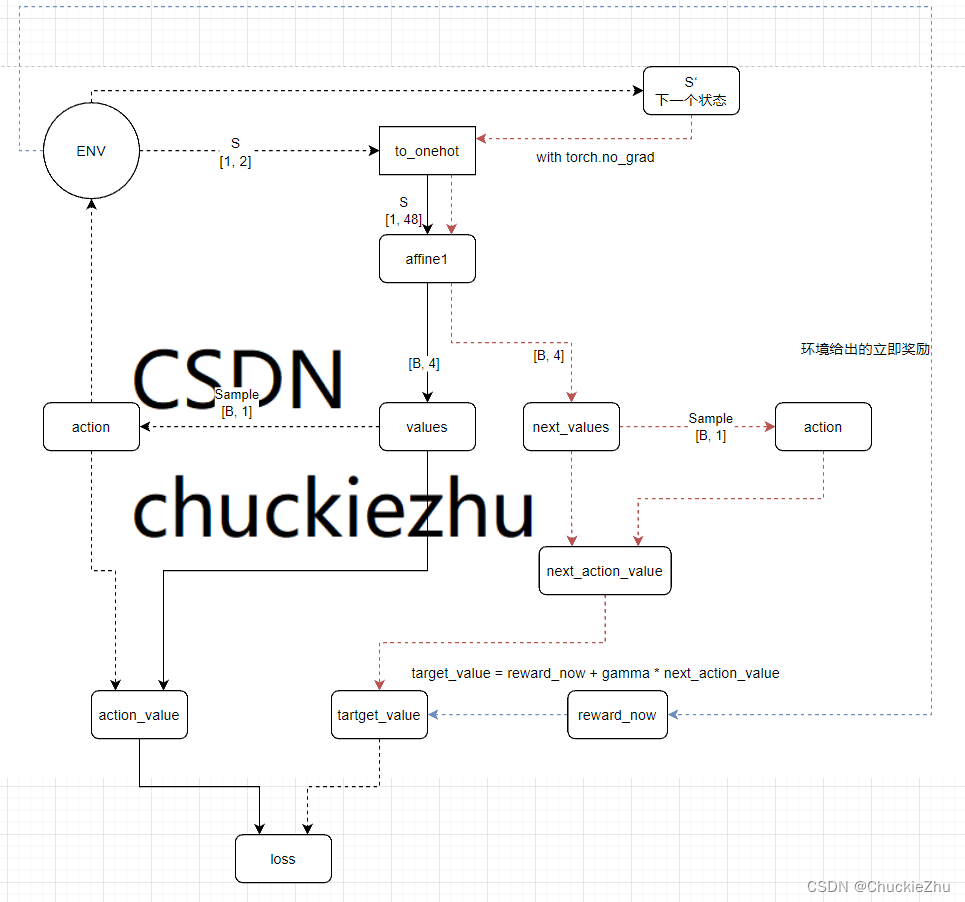
这是上面代码的网络结构和更新流程。注意:实线代表有梯度,虚线代表无梯度。
每次由环境产生一个状态,先转成一个one_hot向量,作为网络的输入,得到四个动作分别价值多少。然后采样到的动作得到当前的Q(s, a)值,也就是action_value。
另一方面,采样得到的动作送入环境,环境给出下一个状态和立即奖励。下一个状态送入网络(没有梯度的计算),同样得到四个动作的价值。由于代码使用的是SARSA算法,所以需要按照同样的策略采样一个动作,同时得到动作的价值。也就是next_action_value。
这个时候,就可以根据环境的立即奖励reward_now和下一个状态的动作的价值next_action_value得到一个ground truth,而action_value作为网络的预测值,这两个可以用于计算损失。
损失的反向传播就是沿着实现传递到顶。实现网络的更新。