前言
嗨喽,大家好呀~这里是爱看美女的小编
又到了学Python时刻~
(文末送读者福利)

我又来了!今天整个好玩的,你们肯定喜欢~
咱们上班累了,不得好好犒劳一下自己,是吧 !
于是我整了一手采集附近洗jio的店子,浴皇大帝们,冲鸭~
话不多说,冲!兄弟们,都是正规的 正规的!
使用环境
python 3.8 解释器
pycharm 编辑器
用的大多数的知识点 都是属于基础的知识点内容,以及pa chong基础入门一些知识点。
要用的模块
requests >>> pip install requests 第三方模块 需要大家去安装
csv
win + R 输入cmd 输入安装命令 pip install 模块名 (如果你觉得安装速度比较慢, 你可以切换国内镜像源)
基本思路。
数据来源分析
我们不管是采集什么,都要先找到数据来源。有来源才有下一步的行动。
确定我们要采集得数据内容是什么?
店铺基本数据信息
通过开发者工具进行抓包分析 分析数据从哪里可以获取
从第一页数据进行分析的
代码流程步骤
有了来源目标之后,再请求获取数据,解析数据,最后创建文件夹保存到Excel表格。
当然,如果想采集更多的,肯定就得实现自动翻页
发送请求, 对于店铺信息数据包url地址发送请求
获取数据, 获取服务器返回的response响应数据
解析数据, 提取我们想要的一些数据内容 (店铺信息)
保存数据, 把相应的数据内容保存csv表格里面
多页采集:多页采集数据内容
代码展示
不限正规足浴,其实想采集啥都行。
import requests
import pprint
import re
import csv
import time
f = open('按摩data.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
'店铺名称',
'人均消费',
'店铺评分',
'评论人数',
'所在商圈',
'店铺类型',
'店铺地址',
'联系方式',
'营业时间',
'详情页',
])
csv_writer.writeheader()
def get_shop_info(html_url):
headers = {
'Cookie': '',
'Host': '',
'Referer': '',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36',
}
response = requests.get(url=html_url, headers=headers)
# print(response.text)
phone = re.findall('"phone":"(.*?)"', response.text)[0]
openTime = re.findall('"openTime":"(.*?)"', response.text)[0].replace('\\n', '')
address = re.findall('"address":"(.*?)"', response.text)[0]
shop_info = [address, phone, openTime]
# print(shop_info)
return shop_info
for page in range(0, 1537, 32):
time.sleep(2)
url = ''
data = {
'uuid': '05f4abe326934bf19027.1634911815.1.0.0',
'userid': '266252179',
'limit': '32',
'offset': page,
'cateId': '-1',
'q': '按摩',
'token': 'knaBbvVTfN50cupoV5b87GJMXzkAAAAAAw8AAELrweWvhGhrM0fw6oTkLe5c6DGXJ6PCtxfyHgUPl3k-SVVR-Vs0LjzrGfewJhX8-g'
}
headers = {
'Referer': '',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url=url, params=data, headers=headers)
result = response.json()['data']['searchResult']
for index in result:
shop_id = index['id']
index_url = f'https://www..com/meishi/{shop_id}/'
shop_info = get_shop_info(index_url)
dit = {
'店铺名称': index['title'],
'人均消费': index['avgprice'],
'店铺评分': index['avgscore'],
'评论人数': index['comments'],
'所在商圈': index['areaname'],
'店铺类型': index['backCateName'],
'店铺地址': shop_info[0],
'联系方式': shop_info[1],
'营业时间': shop_info[2],
'详情页': index_url,
}
csv_writer.writerow(dit)
print(dit)
尾语 💝
今天的分享,差不多就结束了
可以先收藏 ⭐,再学习,毕竟一一下子学会,确实有点难为人~
躲起来的星星🍥也在努力发光,你也要努力加油(让我们一起努力叭)。
读者福利:知道你对Python感兴趣,便准备了这套python学习资料,
对于0基础小白入门:
如果你是零基础小白,想快速入门Python是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:Python永久使用安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习等教程。带你从零基础系统性的学好Python!
零基础Python学习资源介绍
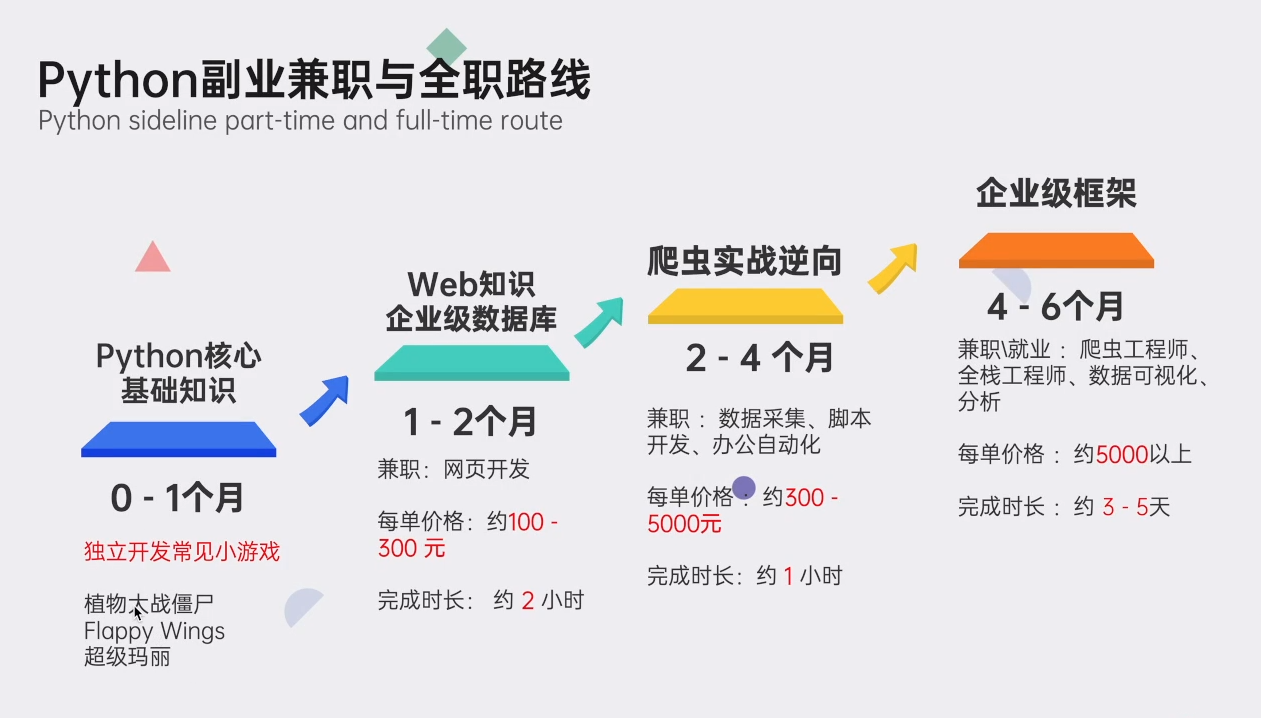
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(学习教程文末领取哈)

👉Python必备开发工具👈
温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉100道Python练习题👈
检查学习结果。
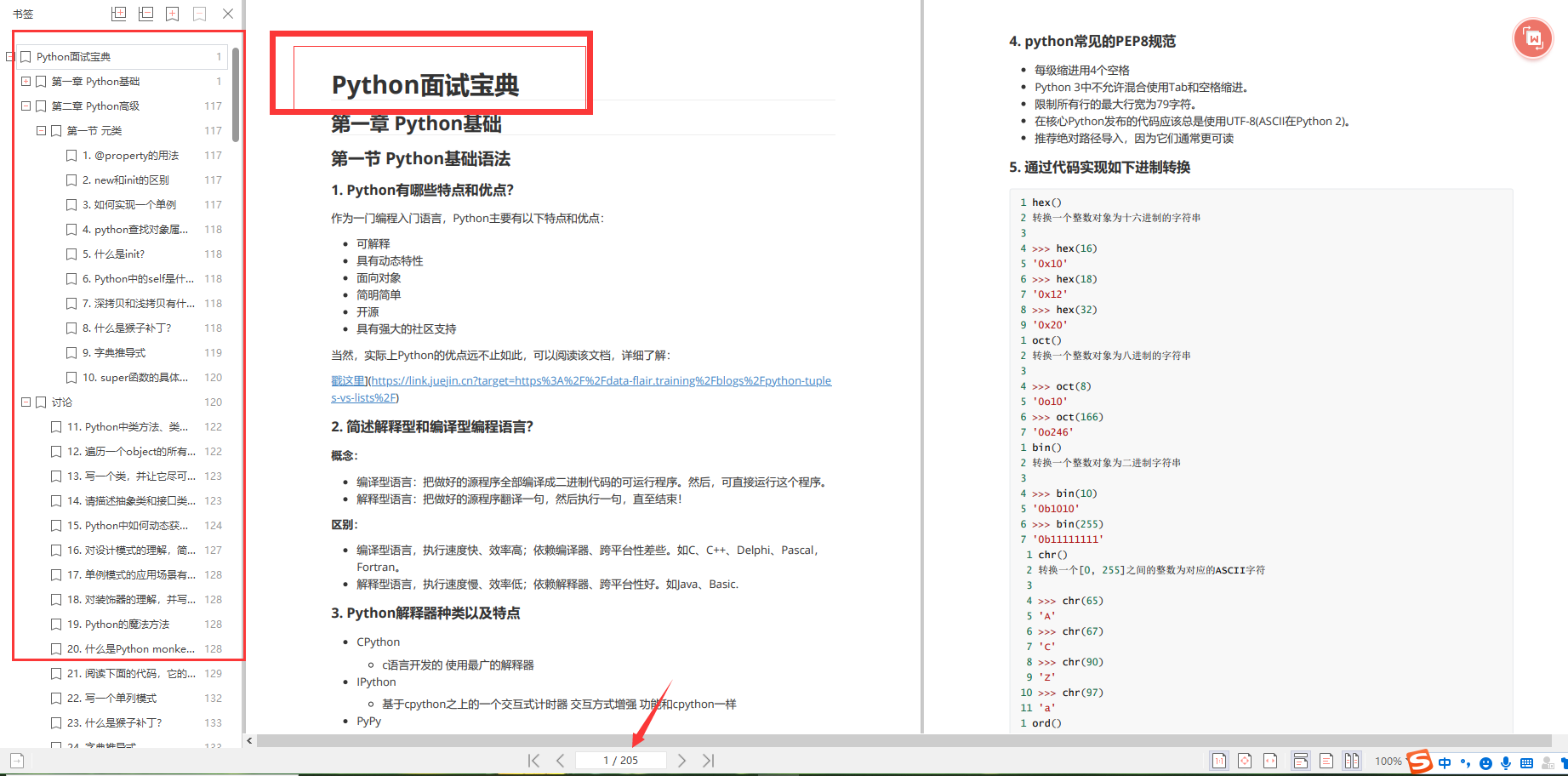
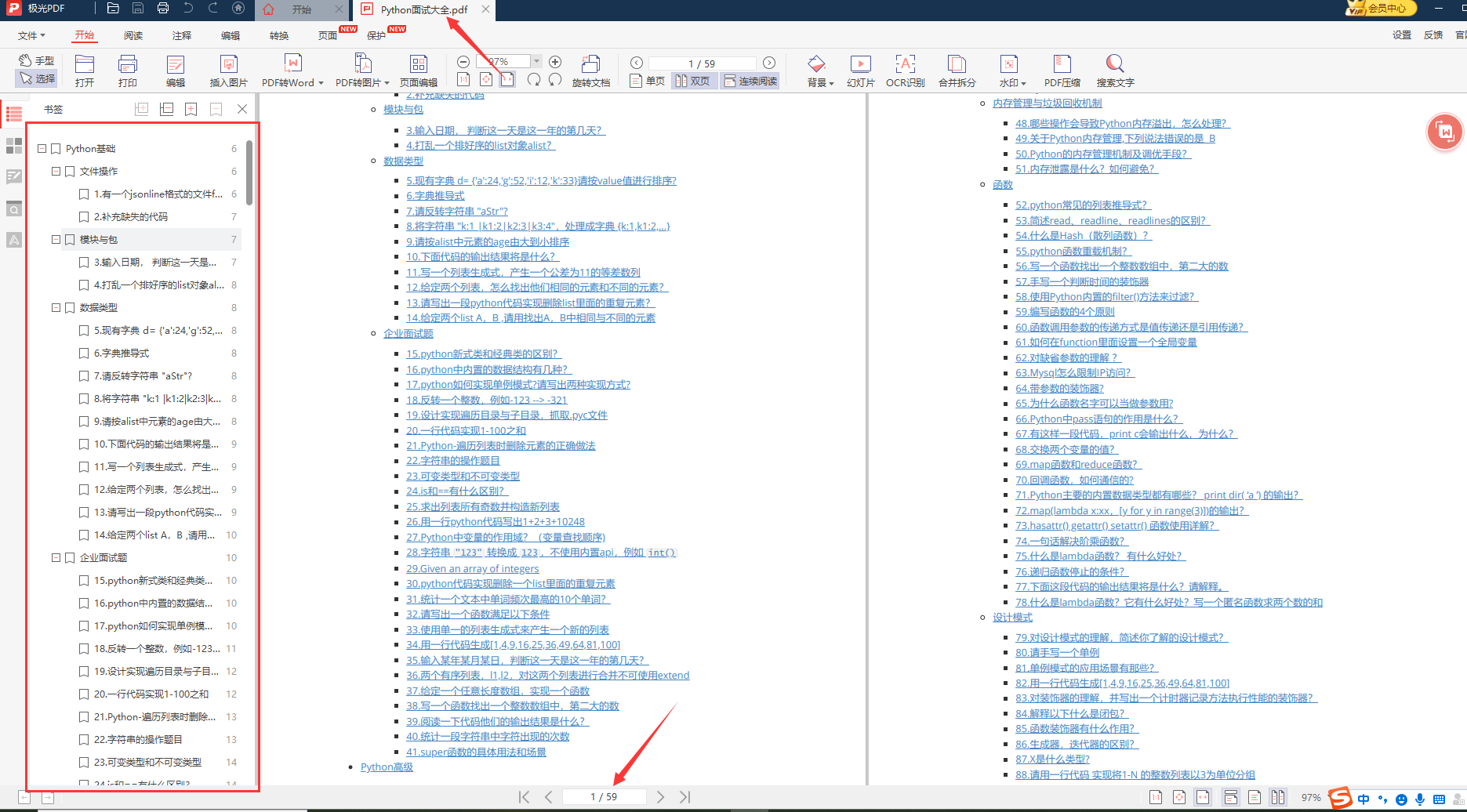
👉面试刷题👈
资料领取
这份完整版的Python全套学习资料已为大家备好,朋友们如果需要可以微信扫描下方二维码添加,输入"领取资料" 可免费领取全套资料【有什么需要协作的还可以随时联系我】朋友圈也会不定时的更新最前言python知识。

好文推荐
了解python的前景: https://blog.csdn.net/weixin_49892805/article/details/127196159
了解python的副业: https://blog.csdn.net/weixin_49892805/article/details/127214402