一、持久化原理
持久化
Redis是内存数据库,数据都是存储在内存中,为了避免进程退出导致数据的永久丢失,需要定期将Redis中的数据以某种形式(数据或命令)从内存保存到硬盘;当下次Redis重启时,利用持久化文件实现数据恢复。除此之外,为了进行灾难备份,可以将持久化文件拷贝到一个远程位置
1.1、持久化流程(落盘)
既然redis的数据可以保存在磁盘上,那么这个流程是什么样的呢?
要有下面五个过程:
- 客户端向服务端发送写操作(数据在客户端的内存中)。
- 数据库服务端接收到写请求的数据(数据在服务端的内存中)。
- 服务端调用write这个系统调用,将数据往磁盘上写(数据在系统内存的缓冲区中)。
- 操作系统将缓冲区中的数据转移到磁盘控制器上(数据在磁盘缓存中)。
- 磁盘控制器将数据写到磁盘的物理介质中(数据真正落到磁盘上)。
这5个过程是在理想条件下一个正常的保存流程,但是在大多数情况下,我们的机器等等都会有各种各样的故障,这里划分了两种情况
- Redis数据库发生故障,只要在上面的第三步执行完毕,那么就可以持久化保存,剩下的两步由操作系统替我们完成。
- 操作系统发生故障,必须上面5步都完成才可以。
为应对以上5步操作,redis提供了两种不同的持久化方式:RDB(Redis DataBase)和AOF(Append OnlyFile)
1.2、RDB详解
1.2.1、介绍
RDB:在指定的时间间隔能对你的数据进行快照存储。
RDB持久化是将当前进程中的数据生成快照保存到硬盘(因此也称作快照持久化),保存的文件后缀是rdb;当Redis重新启动时,可以读取快照文件恢复数据。
在我们安装了redis之后,所有的配置都是在redis.conf文件中,里面保存了RDB和AOF两种持久化机制的各种配置。
1.2.2、触发&原理
在Redis中RDB持久化的触发分为两种:指令手动触发和 redis.conf 配置自动触发
指令手动触发
save命令和bgsave命令都可以生成RDB文件
-
save:会阻塞当前Redis服务器,直到RDB文件创建完毕为止,线上应该禁止使用。

-
bgsave:该触发方式会fork一个子进程,由子进程负责持久化过程,因此阻塞只会发生在fork子进程的时候。


自动触发
- 根据我们的 save m n 配置规则自动触发;
- 从节点全量复制时,主节点发送rdb文件给从节点完成复制操作,主节点会触发 bgsave;
- 执行 debug reload 时;
- 执行 shutdown时,如果没有开启aof,也会触发。
redis.conf:
# 时间策略
save 900 1 # 表示900 秒内如果至少有 1 个 key 的值变化,则触发RDB
save 300 10 # 表示300 秒内如果至少有 10 个 key 的值变化,则触发RDB
save 60 10000 # 表示60 秒内如果至少有 10000 个 key 的值变化,则触发RDB
# 文件名称
dbfilename dump.rdb
# 文件保存路径
dir /home/work/app/redis/data/
# 如果持久化出错,主进程是否停止写入
stop-writes-on-bgsave-error yes
# 是否压缩
rdbcompression yes
# 导入时是否检查
rdbchecksum yes
配置其实非常简单,这里说一下持久化的时间策略具体是什么意思。
- save 900 1 表示900s内如果有1条是写入命令,就触发产生一次快照,可以理解为就进行一次备份
- save 300 10 表示300s内有10条写入,就产生快照
下面的类似,那么为什么需要配置这么多条规则呢?因为Redis每个时段的读写请求肯定不是均衡的,为了平衡性能与数据安全,我们可以自由定制什么情况下触发备份。所以这里就是根据自身Redis写入情况来进行合理配置。
- stop-writes-on-bgsave-error yes 这个配置也是非常重要的一项配置,这是当备份进程出错时,主进程就停止接受新的写入操作,是为了保护持久化的数据一致性问题。 如果自己的业务有完善的监控系统,可以禁止此项配置 , 否则请开启。
- 关于压缩的配置 rdbcompression yes ,建议没有必要开启,毕竟Redis本身就属于CPU密集型服务器,再开启压缩会带来更多的CPU消耗,相比硬盘成本,CPU更值钱。
- 当然如果你想要禁用RDB配置,也是非常容易的,只需要在save的最后一行写上: save “”
1.2.3、实现
手动触发bgsave方法

自动触发

1.2.4、RDB总结
优势
- 执行效率高,适用于大规模数据的备份恢复。自动备份不会影响主线程工作。
- 备份的文件占用空间小。其备份的是数据快照,相对于AOF来说文件大小要小一些。
劣势
- 可能会造成部分数据丢失。因为是自动备份,所以如果修改的数据量不足以触发自动备份,同时发生断电等异常导致redis不能正常关闭,所以也没有触发关闭的备份,那么在上一次备份到异常宕机过程中发生的写操作就会丢失。
- 自动备份通过fork进程来执行备份操作,而fork进程会阻塞主进程。
1.3、AOF详解
1.3.1、概念
AOF(append only file):记录每次对服务器写的操作(命令),当服务器重启的时候会重新执行这些命令来恢复原始的数据。(默认不开启)
AOF特点:
- 以日志的形式来记录用户请求的写操作,读操作不会记录,因为写操作才会存储。
- 文件以追加的形式而不是修改的形式。
- redis的aof恢复其实就是把追加的文件从开始到结尾读取,执行写操作。
1.3.2、AOF 持久化的实现

如上图所示,AOF 持久化功能的实现可以分为命令追加( append )、文件写入( write )、文件同步(sync)、文件重写(rewrite)和重启加(load)。其流程如下:
- 所有的写命令会追加到 AOF 缓冲中。
- AOF 缓冲区根据对应的策略向硬盘进行同步操作。
- 随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。
- 当 Redis 重启时,可以加载 AOF 文件进行数据恢复。
1.3.2、开启
# 可以通过修改redis.conf配置文件中的appendonly参数开启
appendonly yes
# AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的。
dir .
# 默认的文件名是appendonly.aof,可以通过appendfilename参数修改
appendfilename appendonly.aof
1.3.4、命令追加
当 AOF 持久化功能处于打开状态时,Redis 在执行完一个写命令之后,会以协议格式(也就是RESP,即Redis 客户端和服务器交互的通信议
)将被执行的写命令追加到 Redis 服务端维护的 AOF 缓冲区末尾。
比如说 SET mykey myvalue 这条命令就以如下格式记录到 AOF 缓冲中。
1."*3\r\n$3\r\nSET\r\n$5\r\nmykey\r\n$7\r\nmyvalue\r\n"
Redis 协议格式本文不再赘述,AOF之所以直接采用文本协议格式,是因为所有写入命令都要进行追加操作,直接采用协议格式,避免了二次处理开销。
1.3.5、文件写入和同步(触发)1.3.5 文件写入和同步(触发)
Redis 每次结束一个事件循环之前,它都会调用 flushAppendOnlyFile 函数,判断是否需要将 AOF 缓存区中的内容写入和同步到 AOF
文件中。
flushAppendOnlyFile 函数的行为由 redis.conf 配置中的 appendfsync 选项的值来决定。该选项有三个可选值,分别是always 、 everysec 和 no :

always:每执行一个命令保存一次 高消耗,最安全。everysec:每一秒钟保存一次。no:只写入 不保存, AOF 或 Redis 关闭时执行,由操作系统触发刷新文件到磁盘。
写入 和保存概念
WRITE:根据条件,将 aof_buf 中的缓存写入到 AOF 文件。
SAVE:根据条件,调用 fsync 或 fdatasync 函数,将 AOF 文件保存到磁盘中。

1.3.6、AOF 数据恢复
AOF 文件里边包含了重建 Redis 数据所需的所有写命令,所以 Redis 只要读入并重新执行一遍 AOF 文件里边保存的写命令,就可以还原 Redis关闭之前的状态。

Redis 读取 AOF 文件并且还原数据库状态的详细步骤如下:
- 创建一个不带网络连接的的伪客户端( fake client),因为 Redis 的命令只能在客户端上下文中执行,而载入 AOF 文件时所使用的的命令直接来源于 AOF 文件而不是网络连接,所以服务器使用了一个没有网络连接的伪客户端来执行 AOF 文件保存的写命令,伪客户端执行命令的效果和带网络。连接的客户端执行命令的效果完全一样的。
- 从 AOF 文件中分析并取出一条写命令。
- 使用伪客户端执行被读出的写命令。
- 一直执行步骤 2 和步骤3,直到 AOF 文件中的所有写命令都被处理完毕为止。
当完成以上步骤之后,AOF 文件所保存的数据库状态就会被完整还原出来。
1.3.7、AOF “重写”
问题分析:AOF采用文件追加方式,随着Redis长时间运行,会产生什么问题?

概念:
为了解决 AOF 文件体积膨胀的问题,Redis 提供了 AOF 文件重写( rewrite) 策略

如上图所示,重写前要记录名为 list 的键的状态,AOF 文件要保存五条命令,而重写后,则只需要保存一条命令。
AOF 文件重写并不需要对现有的 AOF文件进行任何读取、分析或者写入操作,而是通过读取服务器当前的数据库状态来实现的。首先从数据库中读取键现在的值,然后用一条命令去记录键值对,代替之前记录这个键值对的多条命令,这就是AOF 重写功能的实现原理。
触发:
rewrite的触发机制主要有:
- 手动调用 bgrewriteaof 命令,如果当前有正在运行的 rewrite 子进程,则本次rewrite 会推迟执行,否则,直接触发一次 rewrite。
- 自动触发 就是根据配置规则来触发。
# 重写机制:避免文件越来越大,自动优化压缩指令,会fork一个新的进程去完成重写动作,新进程里的内存数据会被重写,此时旧的aof文件不会被读取使用
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
stat appendonly.aof 查看aof文件
1.3.8、AOF重写原理
AOF 重写函数会进行大量的写入操作,调用该函数的线程将被长时间阻塞,所以 Redis 在子进程中执行AOF 重写操作。

在整个 AOF 后台重写过程中,只有信号处理函数执行时会对 Redis 主进程造成阻塞,在其他时候,AOF后台重写都不会阻塞主进程。

1.4、持久化优先级
如果一台服务器上有既有RDB文件,又有AOF文件,该加载谁呢?

1.5、性能与实践
通过上面的分析,我们都知道RDB的快照、AOF的重写都需要fork,这是一个重量级操作,会对Redis造成阻塞。因此为了不影响Redis主进程响应,我们需要尽可能降低阻塞。
- 降低fork的频率,比如可以手动来触发RDB生成快照、与AOF重写;
- 控制Redis最大使用内存,防止fork耗时过长;
- 使用更牛逼的硬件;
- 合理配置Linux的内存分配策略,避免因为物理内存不足导致fork失败
线上实践经验
5. 如果Redis中的数据并不是特别敏感或者可以通过其它方式重写生成数据,可以关闭持久化,如果丢失数据可以通过其它途径补回;
6. 自己制定策略定期检查Redis的情况,然后可以手动触发备份、重写数据;
7. 可以加入主从机器,利用一台从机器进行备份处理,其它机器正常响应客户端的命令;
8. RDB持久化与AOF持久化可以同时存在,配合使用。
二、安全策略
密码认证
可以通过 redis 的配置文件设置密码参数,这样客户端连接到 redis 服务就需要密码验证,这样可以让你的 redis 服务更安全。
redis在redis.conf配置文件中,设置配置项requirepass, 开户密码认证。
打开
redis.conf,找到requirepass所在的地方,修改为指定的密码,密码应符合复杂性要求:
1、长度8位以上
2、包含以下四类字符中的三类字符:
- 英文大写字母(A 到 Z)
- 英文小写字母(a 到 z)
- 10 个基本数字(0 到 9)
- 非字母字符(例如 !、$、#、%、@、^、&)
3、避免使用已公开的弱密码,如:abcd.1234 、admin@123等,再去掉前面的#号注释符,然后重启redis。
我们可以通过以下命令查看是否设置了密码验证:
127.0.0.1:6379> CONFIG get requirepass
1) "requirepass"
2) ""
默认情况下 requirepass 参数是空的,这就意味着你无需通过密码验证就可以连接到 redis 服务。你可以通过以下命令来修改该参数:
127.0.0.1:6379> CONFIG set requirepass "zimu"
OK
127.0.0.1:6379> CONFIG get requirepass
1) "requirepass"
2) "zimu"
设置密码后,客户端连接 redis 服务就需要密码验证,否则无法执行命令。
语法
AUTH 命令基本语法格式如下:
127.0.0.1:6379> AUTH password
实例
127.0.0.1:6379> AUTH "zimu"
OK
127.0.0.1:6379> SET mykey "Test value"
OK
127.0.0.1:6379> GET mykey
"Test value"
三、过期删除策略&内存淘汰策略
3.1、问题分析:
①、如何设置Redis键的过期时间?
②、设置完一个键的过期时间后,到了这个时间,这个键还能获取到么?假如获取不到那这个键还占据着内存吗?
③、如何设置Redis的内存大小?当内存满了之后,Redis有哪些内存淘汰策略?我们又该如何选择?
3.2、设置Redis键过期时间
Redis提供了四个命令来设置过期时间(生存时间)。
①、EXPIRE :表示将键 key 的生存时间设置为 ttl 秒。
②、PEXPIRE :表示将键 key 的生存时间设置为 ttl 毫秒。
③、EXPIREAT :表示将键 key 的生存时间设置为 timestamp 所指定的秒数时间戳。
④、PEXPIREAT :表示将键 key 的生存时间设置为 timestamp 所指定的毫秒数时间戳。
PS:在Redis内部实现中,前面三个设置过期时间的命令最后都会转换成最后一个PEXPIREAT 命令来完成。
另外补充两个知识点:
-
一、移除键的过期时间
PERSIST :表示将key的过期时间移除。 -
二、返回键的剩余生存时间
TTL :以秒的单位返回键 key 的剩余生存时间。
PTTL :以毫秒的单位返回键 key 的剩余生存时间。
3.3、Redis过期时间的判定
在Redis内部,每当我们设置一个键的过期时间时,Redis就会将该键带上过期时间存放到一个 过期字典中。当我们查询一个键时,Redis便首先检查该键是否存在过期字典中,如果存在,那就获取其过期时间。然后将过期时间和当前系统时间进行比对,比系统时间大,那就没有过期;反之判定该键过期。
3.4、过期删除策略
通常删除某个key,我们有如下三种方式进行处理
-
定时删除
在设置某个key 的过期时间同时,我们创建一个定时器,让定时器在该过期时间到来时,立即执行对其进行删除的操作。 -
惰性删除
设置该key 过期时间后,我们不去管它,当需要该key时,我们在检查其是否过期,如果过期,我们就删掉它,反之返回该key。 -
定期删除
每隔一段时间,我们就对一些key进行检查,删除里面过期的key。
3.5、Redis过期删除策略
Redis的过期删除策略就是:惰性删除和定期删除两种策略配合使用
- 惰性删除 :Redis的惰性删除策略由 db.c/expireIfNeeded 函数实现,所有键读写命令执行之前都会调用expireIfNeeded 函数对其进行检查,如果过期,则删除该键,然后执行键不存在的操作;未过期则不作操作,继续执行原有的命令。
- 定期删除 :由redis.c/activeExpireCycle 函数实现,函数以一定的频率运行,每次运行时,都从一定数量的数据库中取出一定数量的随机键进行检查,并删除其中的过期键。
注意:并不是一次运行就检查所有的库,所有的键,而是随机检查一定数量的键。定期删除函数的运行频率,在Redis2.6版本中,规定每秒运行10次,大概100ms运行一次。在Redis2.8版本后,可以通过修改配置文件redis.conf的 hz 选项来调整这个次数。

算法如下:
- 采样ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP(redis参数,默认20)个数的key,并将其中过期的key全部删除;
- 如果超过25%的key过期了,则重复删除的过程,知道过期key的比例降至25%以下
思考:会不会存在某些永远使用不到的键,并且多次定期删除也没选定到进行删除的key?
3.6、内存淘汰策略
①、设置Redis最大内存
在配置文件redis.conf 中,可以通过参数 maxmemory 来设定最大内存:
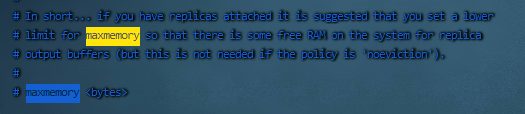
不设定该参数默认是无限制的,但是通常会设定其为物理内存的四分之三
②、设置内存淘汰方式
当现有内存大于 maxmemory 时,便会触发redis主动淘汰内存方式,通过设置 maxmemory-policy
有如下几种淘汰方式:

- volatile-lru :设置了过期时间的key使用LRU算法淘汰;
- allkeys-lru :所有key使用LRU算法淘汰;
- volatile-lfu :设置了过期时间的key使用LFU算法淘汰;
- allkeys-lfu :所有key使用LFU算法淘汰;
- volatile-random :设置了过期时间的key使用随机淘汰;
- allkeys-random :所有key使用随机淘汰;
- volatile-ttl :设置了过期时间的key根据过期时间淘汰,越早过期越早淘汰;
- noeviction :默认策略,当内存达到设置的最大值时,所有申请内存的操作都会报错(如
- set,lpush等),只读操作如get命令可以正常执行;
- LRU、LFU和volatile-ttl都是近似随机算法;
使用下面的参数maxmemory-policy配置淘汰策略:
#配置文件
maxmemory-policy noeviction
#命令行
127.0.0.1:6379> config get maxmemory-policy
1) "maxmemory-policy"
2) "noeviction"
127.0.0.1:6379> config set maxmemory-policy allkeys-random
OK
127.0.0.1:6379> config get maxmemory-policy
1) "maxmemory-policy"
2) "allkeys-random"
在缓存的内存淘汰策略中有 FIFO、LRU、LFU 三种,其中LRU和LFU是Redis在使用的。
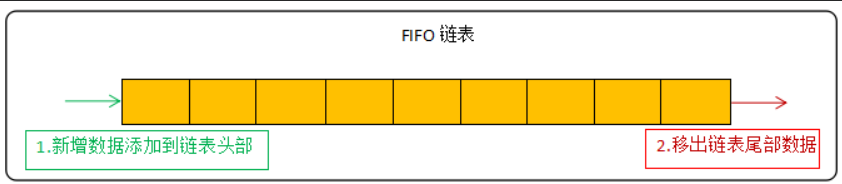
FIFO是最简单的淘汰策略,遵循着先进先出的原则,这里简单提一下:
LRU算法
LRU(Least Recently
Used)表示最近最少使用,该算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
LRU算法的常见实现方式为链表:
新数据放在链表头部 ,链表中的数据被访问就移动到链头,链表满的时候从链表尾部移出数据。

而在Redis中使用的是近似LRU算法,为什么说是近似呢?Redis中是随机采样5个(可以修改参数maxmemory-samples配置)key,然后从中选择访问时间最早的key进行淘汰,因此当采样key的数量与Redis库中key的数量越接近,淘汰的规则就越接近LRU算法。但官方推荐5个就足够了,最多不超过10个,越大就越消耗CPU的资源。
但在LRU算法下,如果一个热点数据最近很少访问,而非热点数据近期访问了,就会误把热点数据淘汰而留下了非热点数据,因此在Redis4.x中新增了LFU算法。
在L/RU算法下,Redis会为每个key新增一个3字节的内存空间用于存储key的访问时间;
LFU算法
LFU(Least FrequentlyUsed)表示最不经常使用,它是根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
LFU算法反映了一个key的热度情况,不会因LRU算法的偶尔一次被访问被误认为是热点数据。
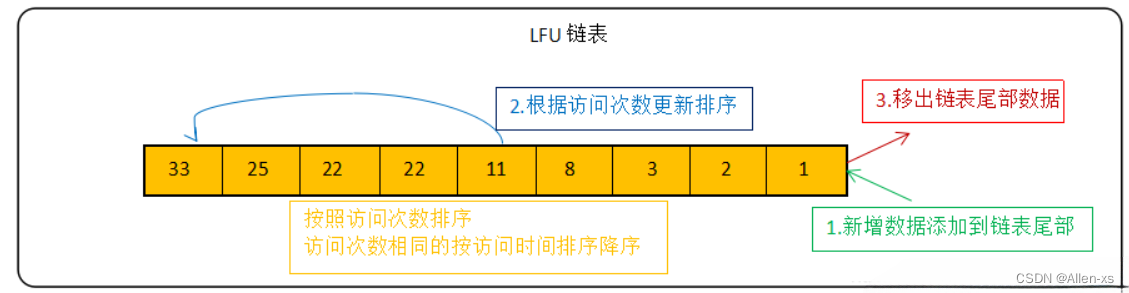
LFU算法的常见实现方式为链表:
新数据放在链表尾部 ,链表中的数据按照被访问次数降序排列,访问次数相同的按最近访问时间降序排列,链表满的时候从链表尾部移出数据。
Redis在实现LFU策略的时候,只是把原来24bit大小的LRU字段,又进一步拆分成了两部分
- Idt:lru字段的前16bit,表示数据的访问时间戳
- counter值:lru字段的后8bit,表示数据的访问次数
总结:当LFU策略筛选数据时,Redis会在候选集合中,根据数据lru字段的后8bit选择访问次数最少的数据进行淘汰。当访问次数相同时,再根据lru字段的前16bit值大小,选择访问时间最久远的数据进行淘汰
总结
Redis过期删除策略是采用惰性删除和定期删除这两种方式组合进行的,惰性删除能够保证过期的数据我们在获取时一定获取不到,而定期删除设置合适的频率,则可以保证无效的数据及时得到释放,而不会一直占用内存数据。
但是我们说Redis是部署在物理机上的,内存不可能无限扩充的,当内存达到我们设定的界限后,便自动触发Redis内存淘汰策略,而具体的策略方式要根据实际业务情况进行选取。
四、性能压测
Redis 的性能测试工具,目前主流使用的是 redis-benchmark
4.1、redis-benchmark
Redis 官方提供 redis-benchmark 的工具来模拟 N 个客户端同时发出 M 个请求,可以便捷对服务器进行读写性能压测
4.2、语法
redis 性能测试的基本命令如下:
redis-benchmark [option] [option value]
redis 性能测试工具可选参数如下所示:
| 序号 | 选项 | 描述 | 默认值 |
|---|---|---|---|
| 1 | -h | 指定服务器主机名 | 127.0.0.1 |
| 2 | -p | 指定服务器端口 | 6379 |
| 3 | -s | 指定服务器 socket | |
| 4 | -c | 指定并发连接数 | 90 |
| 5 | -n | 指定请求数 | 10000 |
| 6 | -d | 以字节的形式指定 SET/GET 值的数据大小 | 2 |
| 7 | -j | 1=keep alive 0=reconnect | 1 |
| 8 | -r | SET/GET/INCR 使用随机 key, SADD 使用随机值 | |
| 9 | -p | 通过管道传输 请求 | 1 |
| 10 | -q | 强制退出 redis。仅显示 query/sec 值 | |
| 11 | –csv | 以 CSV 格式输出 | |
| 12 | -l(L 的小写字母) | 生成循环,永久执行测试 | |
| 13 | -t | 仅运行以逗号分隔的测试命令列表。 | |
| 14 | -I(i 的大写字母) | Idle 模式。仅打开 N 个 idle 连接并等待。 |
4.3、快速测试
./redis-benchmark -a 密码
基本可以看到,常用的 GET/SET/INCR 等命令,都在 8W+ QPS 以上
4.4、精简测试
./redis-benchmark -t set,get,incr -n 1000000 -q -a 密码
- 通过 -t 参数,设置仅仅测试 SET/GET/INCR 命令
- 通过 -n 参数,设置每个测试执行 1000000 次操作。
- 通过 -q 参数,设置精简输出结果。
执行结果如下:
SET: 88059.18 requests per second, p50=0.295 msec
GET: 88472.09 requests per second, p50=0.295 msec
INCR: 87734.70 requests per second, p50=0.303 msec
# 测试脚本性能
./redis-benchmark -q -a 密码 script load "redis.call('set','foo','bar')"
script load redis.call('set','foo','bar'): 81234.77 requests per second, p50=0.287 msec
4.5、实战演练
看一个实际的案例,压测开启、关闭 aof下,redis的性能剖析
1)关掉auth认证,打开aof,策略为always,配置文件如下
#redis.conf
appendonly yes
appendfsync always
#requirepass abc #关掉auth
#kill旧进程,重启redis
[root@iZ8vb3a9qxofwannyywl6zZ aof]# pwd
/opt/redis/latest/aof
[root@iZ8vb3a9qxofwannyywl6zZ aof]# ..src/redis-server redis.conf
2)压测aof下的性能,以get,set为测试案例,将结果记录下来,留做后面对比
[root@iZ8vb3a9qxofwannyywl6zZ aof]# redis-server /usr/local/redis/redis.conf
SET: 62274.25 requests per second, p50=0.687 msec
GET: 88739.02 requests per second, p50=0.399 msec
3)将配置文件的appendonly改为no,关掉aof,重启redis,再来压测同样的指令
[root@iZ8vb3a9qxofwannyywl6zZ aof]# ..redis-6.2.4/src/redis-benchmark -t set,get
-n 1000000 -q
SET: 91575.09 requests per second, p50=0.391 msec
GET: 90950.43 requests per second, p50=0.391 msec
4)结果分析
对各种读取操作来说,性能差别不大:get、spop、队列的range等
对写操作影响比较大
5)参考价值
如果你的项目里对数据安全性要求较高,写少读多的场景,可以适当使用aof
如果追求极致的性能,只做缓存,容忍数据丢失,还是关掉aof
五、Redis高可用
5.1、主从复制
5.1.1、面临问题
Redis有 两种不同的持久化方式, Redis 服务器通过持久化,把 Redis 内存中持久化到硬盘当中,当Redis 宕机时,我们重启 Redis服务器时,可以由 RDB 文件或 AOF 文件恢复内存中的数据。

问题1:不过持久化后的数据仍然只在一台机器上,因此当硬件发生故障时,比如主板或CPU坏了,这时候无法重启服务器,有什么办法可以保证服务器发生故障时数据的安全性?或者可以快速恢复数据呢?
问题2:容量瓶颈
5.1.2、解决办法
针对这些问题,redis提供了复制(replication) 的功能,通过"主从(一主多从)"和"集群(多主多从)"的方式对redis的服务进行水平扩展,用多台redis服务器共同构建一个高可用的redis服务系统。
5.1.3、主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave),数据的复制是单向的,只能由主节点到从节点。
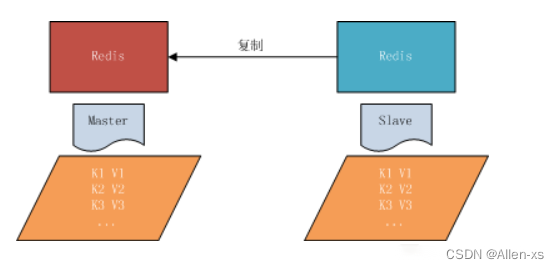
5.1.4、常用策略
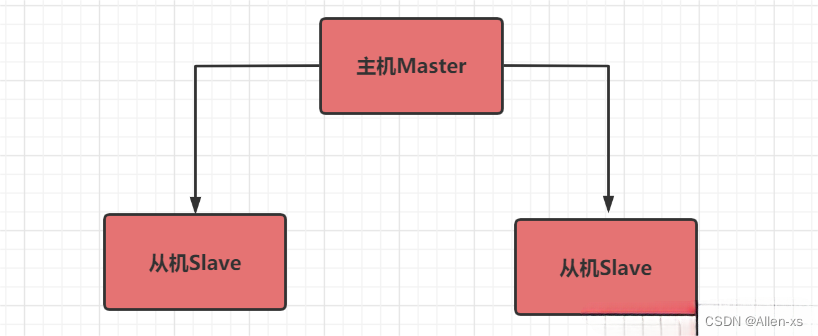
策略1 :一主多从 主机(写),从机(读)
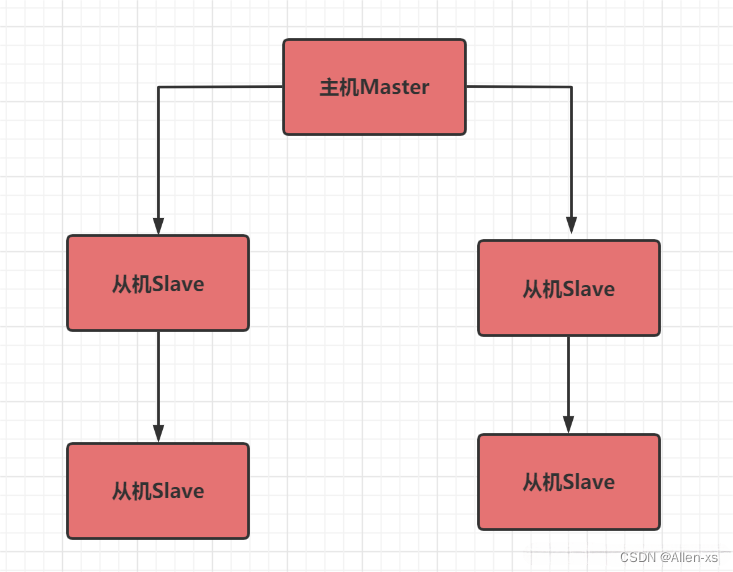
策略2:薪火相传
5.1.5、主从复制原理
Redis 的主从复制是异步复制,异步分为两个方面,一个是master 服务器在将数据同步到slave时是异步的,因此master服务器在这里仍然可以接收其他请求,一个是slave在接收同步数据也是异步的。
复制方式
redis-cli -p 6379 info | grep run
-
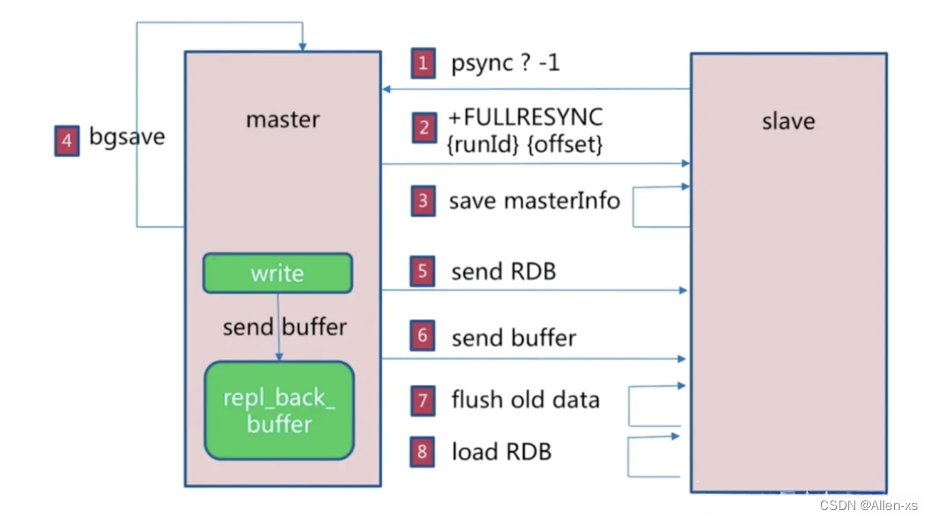
全量复制
master 服务器会将自己的rdb 文件发送给slave 服务器进行数据同步,并记录同步期间的其他写入,再发送给slave服务器,以达到完全同步的目的,这种方式称为全量复制。
-
增量复制
因为各种原因master 服务器与slave 服务器断开后, slave 服务器在重新连上master服务器时会尝试重新获取断开后未同步的数据即部分同步,或者称为部分复制。

工作原理
master 服务器会记录一个replicationId 的伪随机字符串,用于标识当前的数据集版本,还会记录一个当数据集的偏移量offset,不管maste是否有配置slave 服务器,replicationId和offset会一直记录并成对存在,我们可以通过以下命令查看replication Id和offset:
> info repliaction
通过redis-cli在master或slave服务器执行该命令会打印类似以下信息(不同服务器数据不同,打印信息不同):
connected_slaves:1
slave0:ip=127.0.0.1,port=6380,state=online,offset=9472,lag=1
master_replid:2cbd65f847c0acd608c69f93010dcaa6dd551cee
master_repl_offset:9472
当master与slave正常连接时,slave使用PSYNC命令向master发送自己记录的旧master的replicationid和offset,而master会计算与slave之间的数据偏移量,并将缓冲区中的偏移数量同步到slave,此时master和slave的数据一致。
而如果slave引用的replication太旧了,master与slave之间的数据差异太大,则master与slave之间会使用全量复制的进行数据同步(repl_backlog_size值调大可以尽量避免)。
5.1.6、配置主从复制
注:主从复制的开启,完全是在从节点发起的;不需要我们在主节点做任何事情。
从节点开启主从复制,有3种方式:
(1)配置文件:在从服务器的配置文件中加入:slaveof <masterip> <masterport>
(2)redis-server启动命令后加入 --slaveof <masterip> <masterport>
(3)Redis服务器启动后,直接通过客户端执行命令:slaveof <masterip> <masterport>,则该Redis实例成为从节点 详细步骤参考:https://blog.csdn.net/qq_37242720/article/details/121010207
5.2、sentinel哨兵模式
通过前面的配置,主节点Master 只有一个,一旦主节点挂掉之后,从节点没法担起主节点的任务,那么整个系统也无法运行。
如果主节点挂掉之后,从节点能够自动变成主节点,那么问题就解决了,于是哨兵模式诞生了。
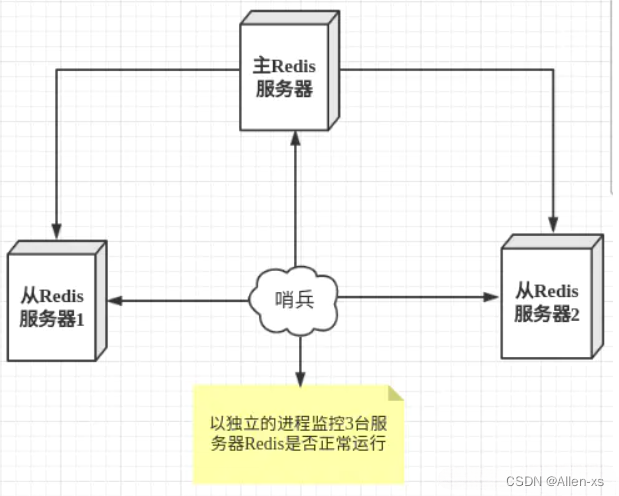
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例 。
哨兵模式搭建步骤:https://blog.csdn.net/qq_37242720/article/details/121010207
六、Redis Cluster

(1)在主从 + 哨兵模式中,仍然只有一个Master节点。当并发写请求较大时,哨兵模式并不能缓解写压力
(2) 在Redis Sentinel模式中,每个节点需要保存全量数据,冗余比较多
6.2、Cluster概念
从3.0版本之后,官方推出了Redis Cluster,它的主要用途是实现数据分片(Data
Sharding),不过同样可以实现HA,是官方当前推荐的方案。
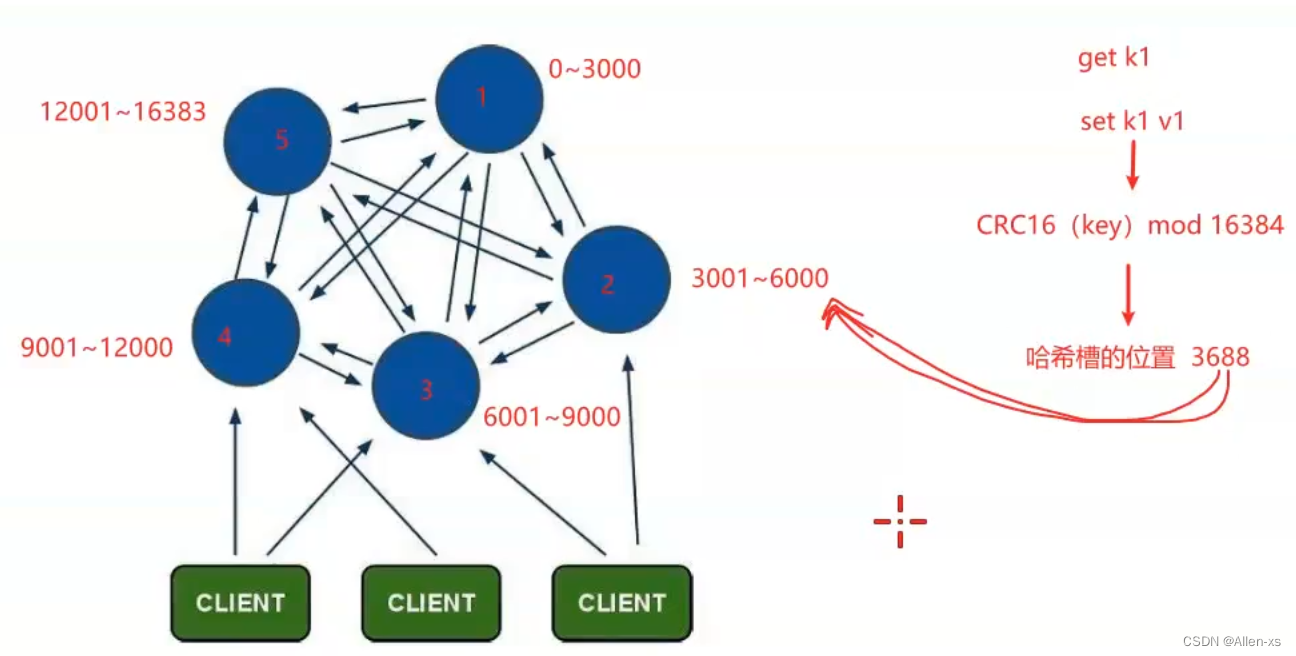
- Redis-Cluster采用无中心结构
- 只有当集群中的大多数节点同时fail整个集群才fail。
- 整个集群有16384个slot,当需要在 Redis 集群中放置一个 key-value 时,根据 CRC16(key) mod 16384的值,决定将一个key放到哪个桶中。读取一个key时也是相同的算法。
- 当主节点fail时从节点会升级为主节点,fail的主节点online之后自动变成了从节点
6.3、故障转移
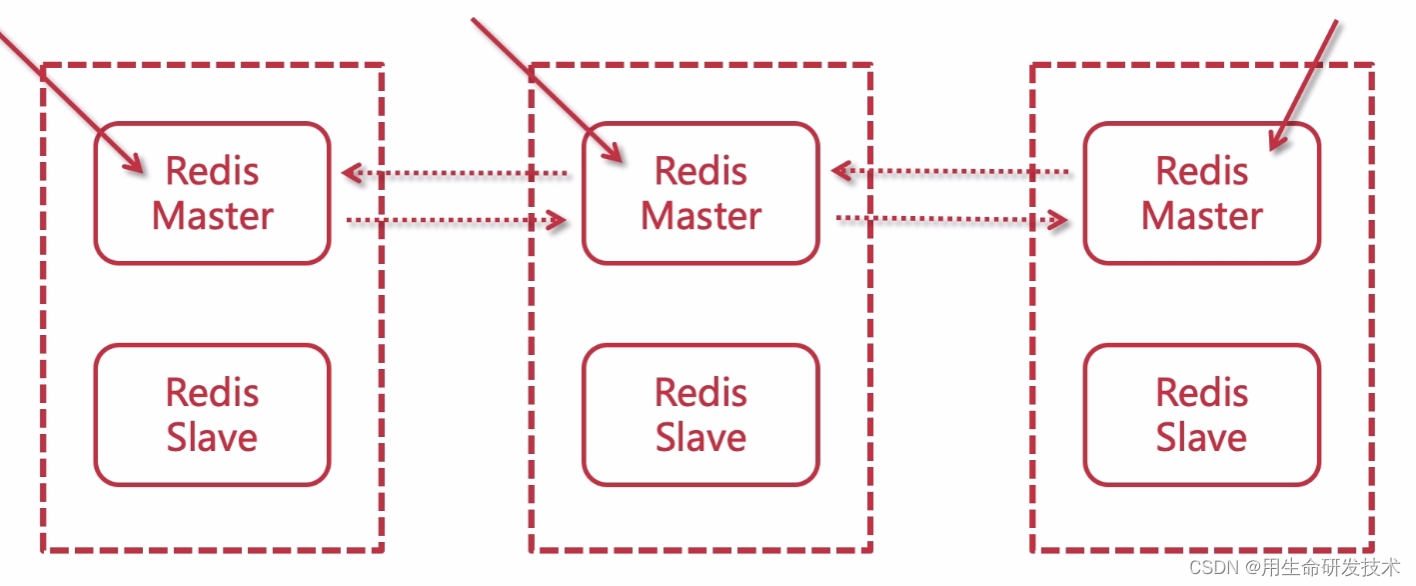
Redis集群的主节点内置了类似Redis Sentinel的节点故障检测和自动故障转移功能,当集群中的某个主节点下线时,集群中的其他在线主节点会注意到这一点,并对已下线的主节点进行故障转移。
6.4、集群分片策略
Redis-cluster分片策略,是用来解决key存储位置的。
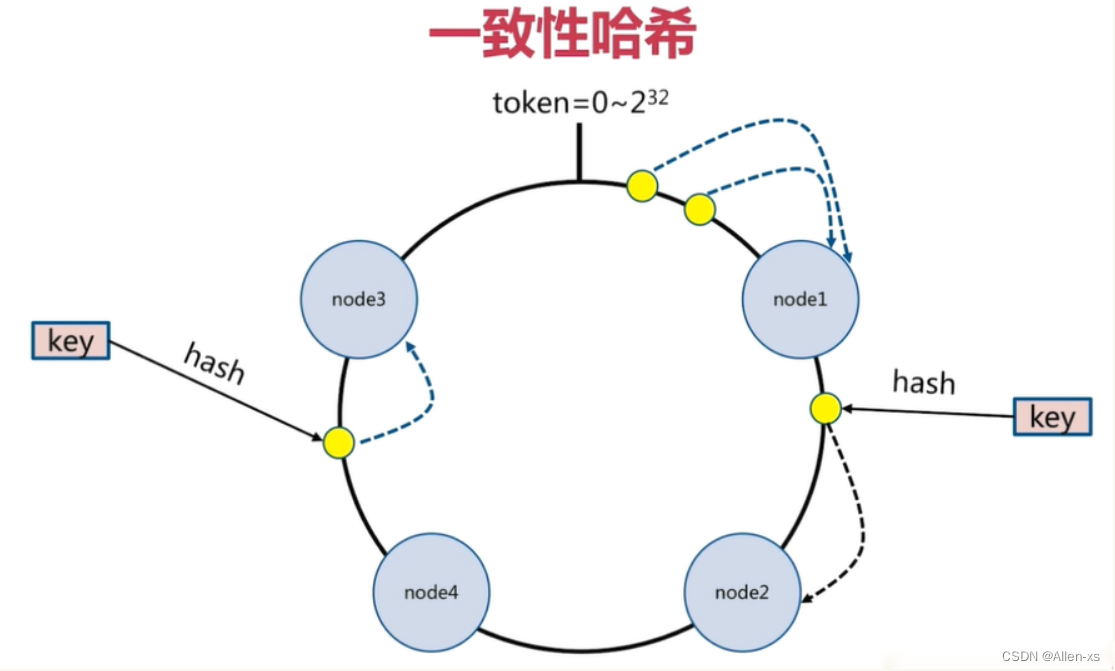
常见的数据分布的方式:顺序分布、哈希分布、节点取余哈希、一致性哈希…
6.5、Redis 集群的数据分片
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念.
预设虚拟槽,每个槽就相当于一个数字,有一定范围
Redis Cluster中预设虚拟槽的范围为0到16383
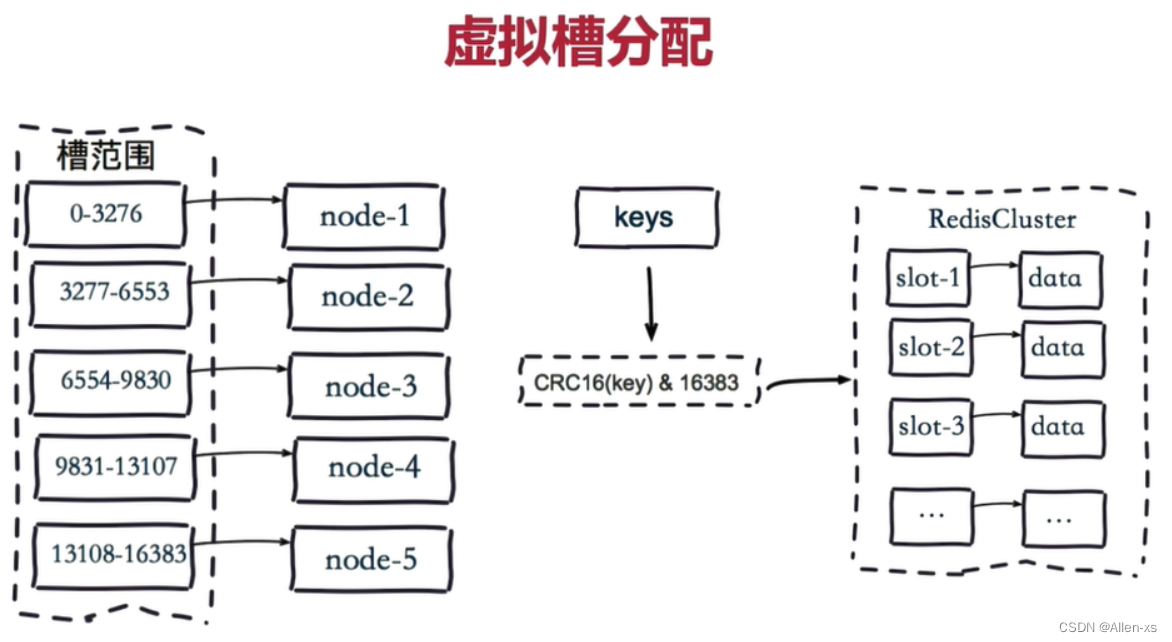
步骤:
- 把16384槽按照节点数量进行平均分配,由节点进行管理。
- 对每个key按照CRC16规则进行hash运算。
- 把hash结果对16383进行取余。
- 把余数发送给Redis节点。
- 节点接收到数据,验证是否在自己管理的槽编号的范围。
* 如果在自己管理的槽编号范围内,则把数据保存到数据槽中,然后返回执行结果。
* 如果在自己管理的槽编号范围外,则会把数据发送给正确的节点,由正确的节点来把数据保存在对应的槽中。
需要注意的是:Redis Cluster的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽
虚拟槽分布方式中,由于每个节点管理一部分数据槽,数据保存到数据槽中。当节点扩容或者缩容时,对数据槽进行重新分配迁移即可,数据不会丢失。
6.6、搭建Redis Cluster
步骤分析:
- 启动节点:将节点以集群方式启动,此时节点是独立的。
- 节点握手:将独立的节点连成网络。
- 槽指派:将16384个槽位分配给主节点,以达到分片保存数据库键值对的效果。
- 主从复制:为从节点指定主节点。
具体搭建教程参考:https://blog.csdn.net/qq_37242720/article/details/121010207
6.7、扩容
重新分片
redis-cli --cluster reshard 127.0.0.1:9001
redis-cli --cluster reshard 127.0.0.1:9001 --cluster-from
10ac7df576168e7f6ec86b20b249e02b1fc13a25,43284b05c5a359b28507b49c29a49637f1f6312b,02a79c59682b7c05f13d41e46e814fc792fa2c50 --cluster-to 07e3416aba80cfb8a8ef81d27228559e5a9d6415 --cluster-slots 1024
#根据提示一步步进行,再次查看node分片,可以了!
127.0.0.1:8081> cluster nodes
eb49056da71858d58801f0f28b3d4a7b354956bc 127.0.0.1:9004@18084 master - 0 1602666306047 4 connected 0-332 5461-5794 10923-11255
16a3f8a4be9863e8c57d1bf5b3906444c1fe2578 127.0.0.1:9003@18082 master - 0 1602666305045 2 connected 5795-10922
214e4ca7ece0ceb08ad2566d84ff655fb4447e19 127.0.0.1:9002@18083 master - 0 1602666305000 3 connected 11256-16383
864c3f763ab7264ef0db8765997be0acf428cd60 127.0.0.1:9001@18081 myself,master - 0 1602666303000 1 connected 333-5460
平衡哈希槽,为了保证redis哈希槽的在每一个节点的均衡,需要对哈希槽进行均衡
redis-cli --cluster rebalance 127.0.0.1:9001