一、前言
此示例首先展示了如何使用基于预训练的膨胀 3-D (I3D) 双流卷积神经网络的视频分类器执行活动识别,然后展示了如何使用迁移学习来训练此类视频分类器使用 RGB 和来自视频的光流数据 [1]。
基于视觉的活动识别涉及使用一组视频帧预测物体的动作,例如走路、游泳或坐着。视频活动识别有很多应用,如人机交互、机器人学习、异常检测、监控、物体检测等。例如,在线预测来自多个摄像头的传入视频的多个动作对于机器人学习非常重要。与图像分类相比,使用视频的动作识别建模具有挑战性,因为视频数据集的地面实况数据不准确,视频中的参与者可以执行的各种手势,严重类不平衡的数据集,以及从头开始训练强大的分类器所需的大量数据。深度学习技术,如I3D双流卷积网络[1],R(2+1)D [4]和SlowFast [5],已经显示出使用迁移学习和在大型视频活动识别数据集(如Kinetics-400)上预先训练的网络在较小数据集上的性能有所提高[6]。注意:此示例需要用于膨胀 3D 视频分类的计算机视觉工具箱模型。可以从加载项资源管理器安装用于膨胀 3D 视频分类的计算机视觉工具箱模型。
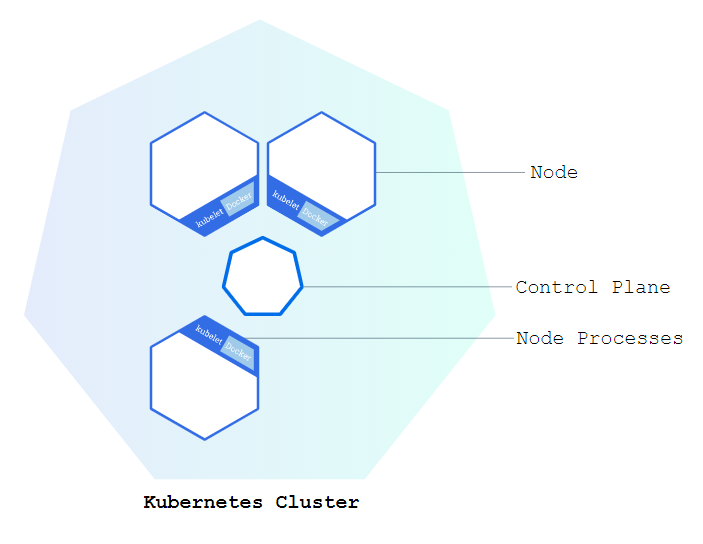
二、使用预训练的充气 3D 视频分类器执行活动识别
下载预训练的膨胀 3D 视频分类器以及要执行活动识别的视频文件。下载的zip文件的大小约为89 MB。加载预训练的充气 3D 视频分类器。
显示预训练视频分类器的类标签名称。使用 和 读取和显示视频。选择10个随机选择的视频序列对视频进行分类,以统一覆盖整个文件以找到视频中占主导地位的动作类。使用该函数对视频文件进行分类。

三、训练用于手势识别的视频分类器
示例的这一部分显示了如何使用迁移学习训练上面显示的视频分类器。将变量设置为 使用预训练的视频分类器,而无需等待训练完成。
3.1下载训练和验证数据
此示例使用 HMDB3 数据集训练膨胀 3D (I51D) 视频分类器。使用此示例末尾列出的支持函数将 HMDB51 数据集下载到名为 的文件夹中。下载完成后,将 RAR 文件解压缩到文件夹中。接下来,使用此示例末尾列出的支持函数来确认下载和提取的文件已到位。
该数据集包含大约 2 GB 的视频数据,涉及 7000 个类别的 51 个剪辑,例如喝酒、跑步和握手。每个视频帧的高度为 240 像素,最小宽度为 176 像素。帧数范围从 18 到大约 1000。
为了减少训练时间,此示例训练活动识别网络对 5 个动作类进行分类,而不是数据集中的所有 51 个类。设置为使用所有 51 个类进行训练。
将数据集拆分为用于训练分类器的训练集和用于评估分类器的测试集。将 80% 的数据用于训练集,其余数据用于测试集。使用 和 从文件夹中创建标签信息,并通过从每个标签中随机选择一定比例的文件,将基于每个标签的数据拆分为训练数据集和测试数据集。
为了规范化网络的输入数据,数据集的最小值和最大值在附加到此示例的MAT文件中提供。
3.2加载数据集
此示例使用数据存储从视频文件中读取视频场景、相应的光流数据和相应的标签。
指定每次从数据存储读取数据时应将数据存储配置为输出的视频帧数。
此处使用值 64 来平衡内存使用情况和分类时间。要考虑的常见值是 16、32、64 或 128。使用更多帧有助于捕获其他时态信息,但需要更多的内存。您可能需要降低此值,具体取决于您的系统资源。需要进行实证分析以确定最佳帧数。
接下来,指定应将数据存储配置为输出的帧的高度和宽度。数据存储会自动将原始视频帧的大小调整为指定大小,以启用多个视频序列的批处理。
值 [112 112] 用于捕获视频场景中较长的时间关系,这有助于对持续时间较长的活动进行分类。大小的常见值是 [112 112]、[224 224] 或 [256 256]。较小的尺寸允许使用更多的视频帧,但代价是内存使用量、处理时间和空间分辨率。HMDB51数据集中视频帧的最小高度和宽度分别为240和176。如果要为数据存储指定大于最小值的帧大小(如 [256, 256]),请先使用 调整帧大小。与帧数一样,需要进行实证分析以确定最佳值。imresize
指定 RGB 视频子网和 I3D 视频分类器的光流子网的通道数。
使用帮助程序函数 配置两个用于加载数据的对象,一个用于训练,另一个用于验证。此示例末尾列出了帮助程序函数。每个数据存储读取一个视频文件以提供 RGB 数据和相应的标签信息。
3.3定义网络架构
I3D 网络
使用 3-D CNN 是从视频中提取时空特征的自然方法。您可以通过扩展二维过滤器并将内核池化为 3-D,从预先训练的 2-D 图像分类网络(如 Inception v1 或 ResNet-50)创建 I2D 网络。此过程重用从图像分类任务中学习的权重来引导视频识别任务。
下图是一个示例,显示了如何将 2-D 卷积层膨胀为 3-D 卷积层。膨胀涉及通过添加第三个维度(时间维度)来扩展滤波器大小、权重和偏差。

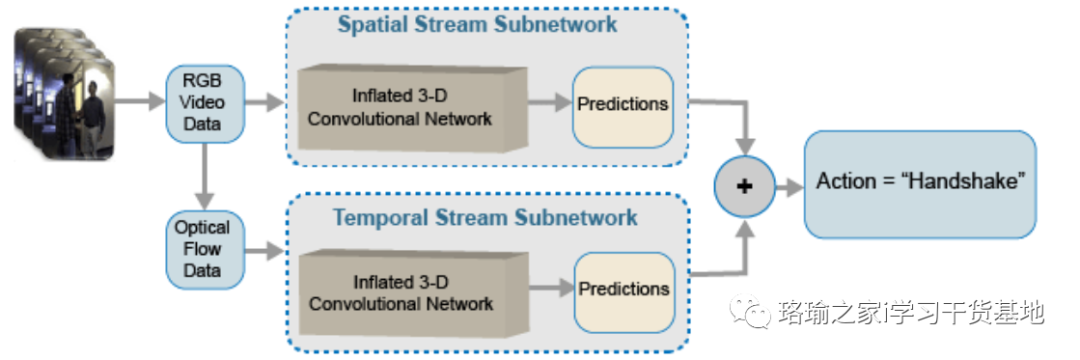
双流 I3D 网络
视频数据可以认为分为两部分:空间分量和时间分量。
-
空间组件包含有关视频中对象的形状、纹理和颜色的信息。RGB 数据包含此信息。
-
时间分量包括有关对象在帧中的运动的信息,并描绘了摄像机和场景中对象之间的重要运动。计算光流是从视频中提取时间信息的常用技术。
双流 CNN 包含一个空间子网和一个时间子网 [2]。与原始堆叠 RGB 帧相比,在密集光流和视频数据流上训练的卷积神经网络可以在有限的训练数据下获得更好的性能。下图显示了典型的双流 I3D 网络。
3.5 配置膨胀 3D (I3D) 视频分类器以进行迁移学习
在此示例中,您将创建一个基于 GoogLeNet 架构的 I3D 视频分类器,这是一个在 Kinetics-3 数据集上预训练的 400D 卷积神经网络视频分类器。
指定 GoogLeNet 作为 I3D 视频分类器的骨干卷积神经网络体系结构,该分类器包含两个子网,一个用于视频数据,另一个用于光流数据。
指定膨胀 3D 视频分类器的输入大小。从文件加载的结构中获取 RGB 和光流数据的最小值和最大值。需要这些值来规范化输入数据。使用该函数创建 I3D 视频分类器。指定视频分类器的模型名称。
3.6 扩充和预处理训练数据
数据增强提供了一种使用有限数据集进行训练的方法。对于基于网络输入大小的帧集合(即视频序列),视频数据的增强必须相同。细微的更改(例如翻译、裁剪或转换图像)可提供新的、独特的和独特的图像,您可以使用这些图像来训练强大的视频分类器。数据存储是读取和扩充数据集合的便捷方式。使用此示例末尾定义的支持函数扩充训练视频数据。
使用此示例末尾定义的 ,预处理训练视频数据以调整为膨胀的 3D 视频分类器输入大小。将视频分类器的属性和预处理函数的输入大小指定为结构中的字段值。该属性用于在 -1 和 1 之间重新缩放视频帧和光流数据。输入大小用于根据结构中的值调整视频帧的大小。或者,您可以使用 或 将输入数据随机裁剪或居中裁剪为视频分类器的输入大小。请注意,数据增强不适用于测试和验证数据。理想情况下,测试和验证数据应代表原始数据,并且不加修改以进行无偏评估。
创建本示例末尾列出的支持函数。该函数将 I3D 视频分类器、一小批输入数据和 以及一小批地面实况标签数据作为输入。该函数返回训练损失值、相对于分类器可学习参数的损失梯度以及分类器的小批量精度。
损失是通过计算来自每个子网的预测的交叉熵损失的平均值来计算的。网络的输出预测是每个类的 0 到 1 之间的概率。
3.7 训练 I3D 视频分类器
使用 RGB 视频数据和光流数据训练 I3D 视频分类器。
对于每个纪元:
-
在循环访问小批量数据之前随机排列数据。
-
用于循环访问小批量。本示例末尾列出的支持函数使用给定的训练数据存储来创建 .
minibatchqueuecreateMiniBatchQueueminibatchqueue -
使用验证数据验证网络。
dsVal -
使用本示例末尾列出的支持函数显示每个时期的损失和精度结果。
displayVerboseOutputEveryEpoch
对于每个小批量:
-
将视频数据或光流数据和标签转换为具有底层类型单一的对象。
dlarray -
要使用 I3D 视频分类器处理视频数据的时间维度,请指定时态序列维度。为视频数据和标签数据指定维度标签(空间、空间、通道、时间、批次)。
"T""SSCTB""CB"
该对象使用此示例末尾列出的支持函数对 RGB 视频和光流数据进行批处理。
四、评估训练的网络
使用测试数据集评估经过训练的视频分类器的准确性。
加载训练期间保存的最佳模型或使用预训练模型。创建一个对象以加载测试数据的批次。对于每批测试数据,使用 RGB 和光流网络进行预测,取预测的平均值,并使用混淆矩阵计算预测精度。计算已训练网络的平均分类精度。显示混淆矩阵。
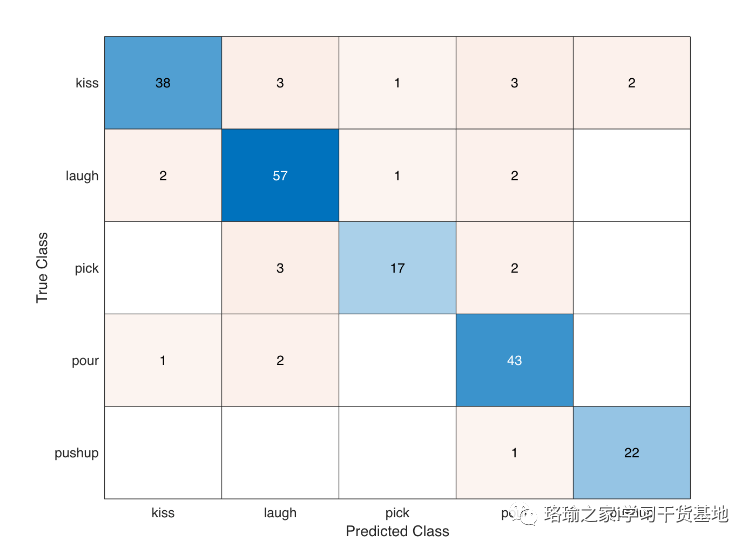
在 Kinetics-3 数据集上预训练的 Inflated-400D 视频分类器为迁移学习中的人类活动识别提供了更好的性能。上述训练在 24GB Titan-X GPU 上运行了大约 100 分钟。在小型活动识别视频数据集上从头开始训练时,训练时间和收敛时间比预训练视频分类器花费的时间要长得多。使用 Kinetics-400 预训练的 Inflated-3D 视频分类器的 Transer 学习还可以避免在运行大量 epoch 时过度拟合分类器。但是,与膨胀的 2D 视频分类器相比,在 Kinetics-1 数据集上预训练的 SlowFast 视频分类器和 R(400+3)D 视频分类器在训练期间提供了更好的性能和更快的收敛。
五、程序
使用Matlab R2022b版本,点击打开。(版本过低,运行该程序可能会报错)
程序下载:基于matlab基于预训练的膨胀双流卷积神经网络的视频分类器执行活动识别资源-CSDN文库
![数据结构07:查找[C++][红黑二叉排序树RBT]](https://img-blog.csdnimg.cn/9ff79cfb24c24e3ab0cb282e6b1574fd.png)